DeonticBench: A Benchmark for Reasoning over Rules
Abstract: Reasoning with complex, context-specific rules remains challenging for LLMs. In legal and policy settings, this manifests as deontic reasoning: reasoning about obligations, permissions, and prohibitions under explicit rules. While many recent benchmarks emphasize short-context mathematical reasoning, fewer focus on long-context, high-stakes deontic reasoning. To address this gap, we introduce DEONTICBENCH, a benchmark of 6,232 tasks across U.S. federal taxes, airline baggage policies, U.S. immigration administration, and U.S. state housing law. These tasks can be approached in multiple ways, including direct reasoning in language or with the aid of symbolic computation. Besides free-form chain-of-thought reasoning, DEONTICBENCH enables an optional solver-based workflow in which models translate statutes and case facts into executable Prolog, leading to formal problem interpretations and an explicit program trace. We release reference Prolog programs for all instances. Across frontier LLMs and coding models, best hard-subset performance reaches only 44.4% on SARA Numeric and 46.6 macro-F1 on Housing. We further study training with supervised fine-tuning and reinforcement learning for symbolic program generation. Although training improves Prolog generation quality, current RL methods still fail to solve these tasks reliably. Overall, DEONTICBENCH provides a benchmark for studying context-grounded rule reasoning in real-world domains under both symbolic and non-symbolic settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeonticBench, a big collection of tricky, real-world “rules problems” for testing AI. “Deontic” means rules about what you must do, may do, or must not do—like laws and policies. The benchmark has 6,232 tasks that make AI read long, detailed rules (like tax laws or airline policies) and decide what the rules say in specific situations. It tests two ways for AI to solve problems:
- Think in plain language (like explaining your steps).
- Translate the rules into a rules programming language called Prolog and let a “rules engine” run them.
The main point: even very advanced AI models still struggle to follow complex, real-world rules reliably, especially when the rule text is long and the stakes are high.
What questions are the authors trying to answer?
The paper looks at simple versions of big questions:
- Can today’s AI follow complicated, real-world rules correctly?
- Does it help to turn rules into code (Prolog) and let a rules engine check the answer?
- Which parts of rule-following are hardest for AI: finding the right rule, reading the facts correctly, doing the math, or writing correct code?
- Can training methods (like fine-tuning or reinforcement learning) make AIs better at this?
How did they study it?
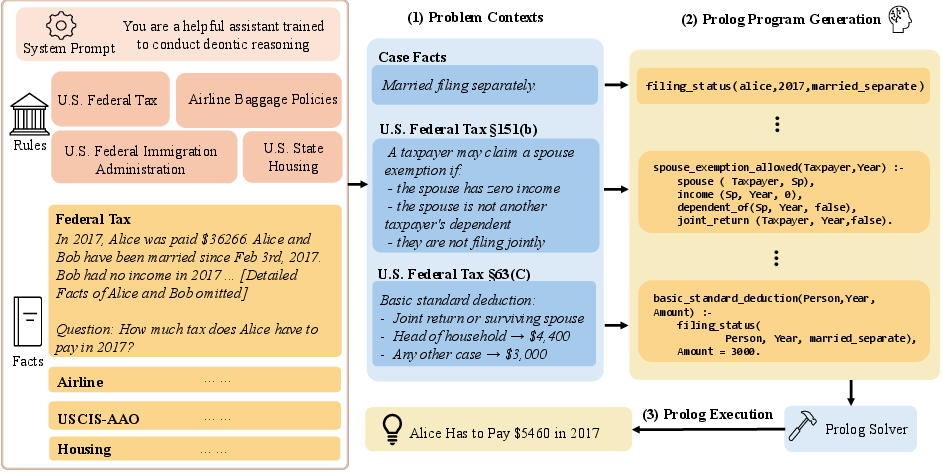
They built a benchmark (a large test set) across four rule-heavy areas. Each task gives the rule text and the case facts needed to answer, so the AI can’t rely on memory—it has to read and apply the given rules.
Here are the four areas:
- U.S. federal taxes (SARA): compute someone’s tax or check if a statement about taxes is true.
- Airline baggage policies (Airline): calculate baggage fees based on ticket type, bag size/weight, and airline rules.
- U.S. state housing law (Housing): answer yes/no legal questions grounded in state statutes.
- U.S. immigration appeals (USCIS-AAO): decide if an appeal is accepted or dismissed following legal criteria.
They also made a special “hard set,” a smaller, carefully chosen group of the most challenging problems. You can think of these as “boss levels” that test deeper skills without needing to run thousands of cases.
Two solving styles were tested:
- Direct (language-only): The model reads the rules and facts and answers directly.
- Symbolic (via Prolog): The model rewrites the rules and facts as Prolog code (a language good at representing rules like “if X and Y, then Z”). Then a Prolog solver runs the code to get the answer. This creates an auditable “paper trail” of how the decision was made.
They tried different prompting styles (Direct, Zero-shot, Few-shot) and evaluated many strong AI models. They also trained one open model further using:
- Supervised Fine-Tuning (SFT): learning from examples.
- DPO and GRPO (types of reinforcement learning): learning from preferences and reward signals to favor better, more rule-correct code.
What did they find, and why does it matter?
Big picture: Reasoning over long, precise rules is still hard for AI.
Key findings explained simply:
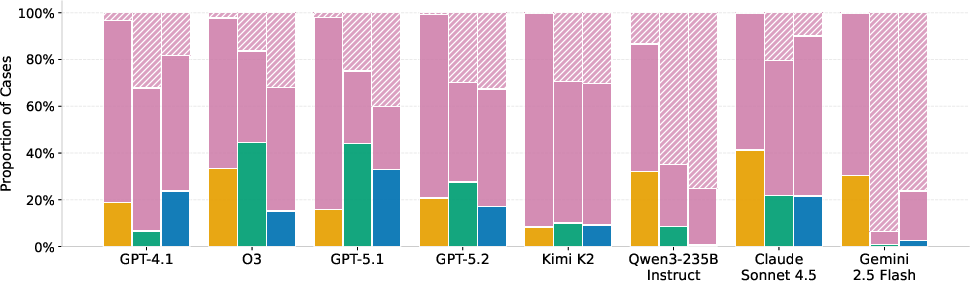
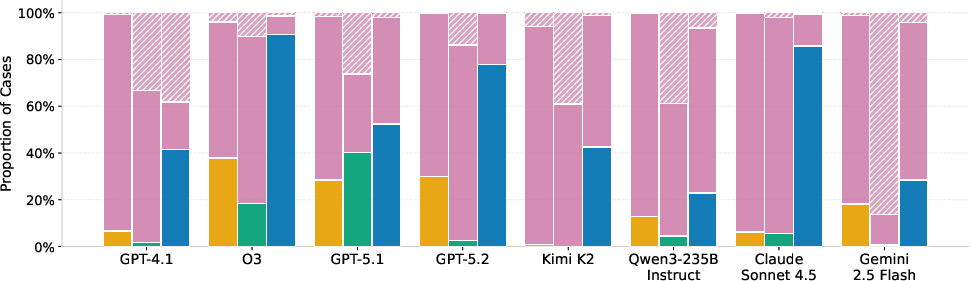
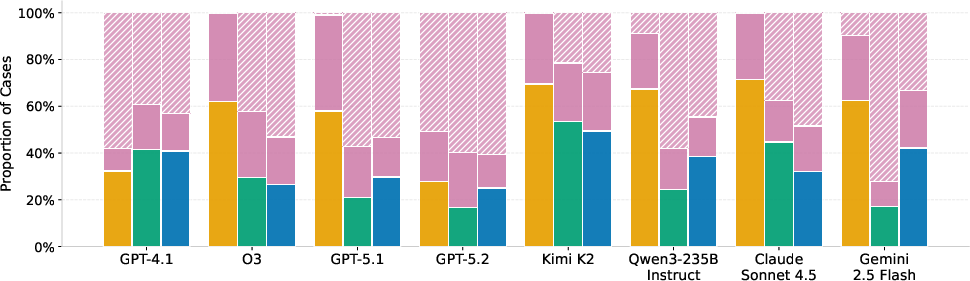
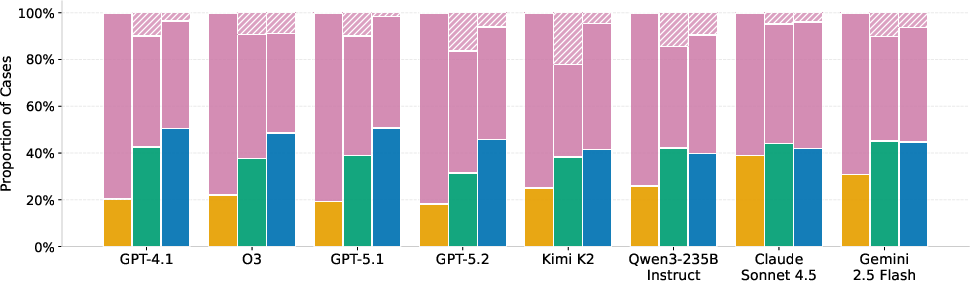
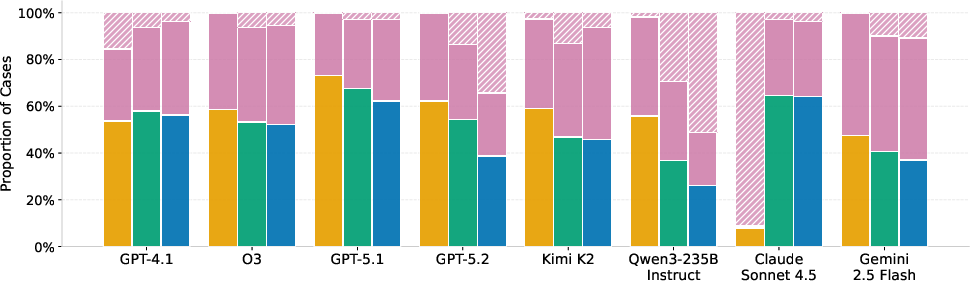
- On the hardest parts, even top AI models often got only around half right. For example, best hard-set scores were about 44% on a tax calculation set and ~47% on Housing (macro-F1, a fairness-aware score for yes/no tasks).
- No single model or prompting trick worked best everywhere. Sometimes giving examples (few-shot) helped a lot (like with airline fees), but not always (like with some tax problems).
- The “symbolic” way (writing Prolog) produced clearer, checkable steps but also led to more “abstentions” (failures to produce runnable code). The “direct” way had fewer abstentions but more wrong answers. In short: clearer reasoning vs. more complete coverage—there’s a trade-off.
- Training helps, but not enough. Extra training made the AI better at some yes/no tasks, but it didn’t fix the biggest weaknesses—especially exact numeric reasoning in taxes. Current reinforcement learning methods improved code quality somewhat but didn’t make the model reliably correct.
- Different domains fail in different ways:
- Legal questions (Housing, immigration): models often picked the wrong rule or subsection.
- Structured tasks (taxes): models misread facts (like filing status or dependencies) even when they knew the right rule.
- Number-heavy tasks (taxes, baggage fees): models messed up math and thresholds (like phaseouts or fee calculations).
- Code generation: some failures were just programming errors in Prolog (syntax/logic bugs).
Why this matters: If we want AI to be trustworthy for real-world decisions (law, taxes, policies, safety), it must follow rules faithfully and show its work. DeonticBench reveals where today’s systems fall short and gives a way to measure improvements.
How does the approach work (in everyday terms)?
Think of it like learning to play four complicated board games (tax law, airline policies, housing law, immigration appeals). Each problem gives:
- The rulebook (statute/policy text),
- The situation (the player’s move or facts),
- A question to answer (what the rulebook says should happen).
Two ways to solve:
- Language-only: the AI reads the rulebook and explains “because of rule X, the answer is Y.”
- Symbolic: the AI rewrites the rulebook in a structured language (Prolog), like turning it into precise “if-then” instructions, and then a rule-checking engine executes those instructions to give an answer. This is like encoding the board game’s rules so a referee program can make the call.
“Long context” means the rulebooks can be long—thousands of tokens—so the AI needs to keep many details in mind.
What could this change in the future?
- Better testing for rule-following AI: DeonticBench offers realistic, high-stakes tasks with long rules, so researchers can check if their models really follow rules, not just guess.
- More faithful, auditable AI: The Prolog route creates a clear trail of how the rules were applied, which is important for trust and accountability.
- Clear next steps for improvement:
- Rule grounding: getting the exact right rule or subsection.
- Fact extraction: pulling details (like names, statuses, dates, counts) correctly from the scenario.
- Reliable math: handling calculations and thresholds precisely.
- Confidence-aware systems: knowing when to “pass” a tough case to a stronger model or a human expert.
- Responsible use: Because these are legal/policy topics, the authors stress that AI should not be used without human oversight. The benchmark is for research and evaluation, not for giving legal or tax advice.
In short, this paper gives the community a tough, realistic test for rule-based reasoning and shows that current AI has a long way to go to be reliable in high-stakes, rule-heavy situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be directly actionable for future research.
- Dataset coverage and scope
- Expand beyond four domains to assess generality (e.g., criminal law, healthcare compliance, privacy, procurement, environmental regulations).
- Mitigate strong U.S./English-centric focus by adding non-U.S. jurisdictions, multilingual statutes, and cross-lingual deontic reasoning tasks.
- Introduce tasks requiring cross-statute/authority integration (e.g., federal vs. state conflicts, policy + contract + statute interactions) and explicit precedence/conflict resolution.
- Incorporate deliberately ambiguous, defeasible, or conflicting rules (exceptions, unless-clauses, retroactivity) to probe non-monotonic and normative-conflict reasoning.
- Ground-truth quality and validation
- Quantify and report the extent of human validation of the released “reference Prolog” and the procedures/guidelines used to ensure statutory faithfulness.
- Measure inter-annotator agreement on statute-to-Prolog mappings and on “facts-only” USCIS narratives to estimate label and formalization reliability.
- Audit the fidelity of Prolog formalizations to legal text (e.g., systematic gaps like missing cross-references or definitional sections).
- Provide provenance/versioning of statutes used and a change log to assess how often legal updates would invalidate ground-truth programs.
- Dataset construction biases and selection effects
- Report how many instances were discarded by the on-the-fly Prolog generation pipeline (two-attempt policy) and analyze the resulting selection bias.
- Characterize which statute-question pairs are systematically filtered out by compile-time constraints (e.g., complex syntax, recursion), and how this shapes task difficulty distribution.
- Evaluate whether the curated “hard” subsets over-represent particular failure modes or surface forms, risking overfitting to idiosyncratic patterns.
- Task design and realism
- Add retrieval-required variants where the statute is not pre-provided, to study end-to-end retrieval + reasoning under real-world conditions.
- Create dynamic/temporal variants where statutes or fee schedules change over time, to test temporal generalization and update-awareness.
- Introduce multi-document and multi-hop legal reasoning setups (e.g., reading definitions, exceptions, and cross-referenced sections across separate documents).
- Evaluation methodology and metrics
- Go beyond final-answer metrics to evaluate interpretation fidelity (e.g., alignment between generated and reference Prolog rules/facts, AST-level similarity).
- Include human or expert baselines for context (difficulty calibration), and compare against deterministic rule-based baselines where applicable.
- Calibrate and measure uncertainty: develop and benchmark confidence-aware inference or abstention-calibration methods rather than treating all abstentions equally.
- Analyze latency/cost and solver timeouts as part of the evaluation to inform practicality of solver-assisted pipelines.
- Revisit numeric scoring (e.g., $1 tolerance) to distinguish rounding/threshold errors from material computation errors; report error magnitudes and categories.
- Symbolic pipeline assumptions and alternatives
- Compare the chosen “per-instance on-the-fly” statute module generation with a “precompiled statute library” approach in controlled experiments (accuracy, robustness, maintainability).
- Benchmark alternative symbolic backends (e.g., ASP, Datalog, SMT/Z3, probabilistic logic) to assess sensitivity to the choice of formalism.
- Investigate solver-in-the-loop search (e.g., execution-guided decoding, iterative repair) and AST-constrained decoding to reduce implementation bugs.
- Long-context handling and robustness
- Systematically vary and ablate context lengths to quantify degradation and the effectiveness of chunking/summarization strategies.
- Test robustness to noisy or adversarial statutory inputs (prompt injection, misleading cross-references, formatting perturbations).
- Add controlled paraphrases of statutes/facts to assess brittleness to surface-form variation.
- Learning methods and supervision signals
- Explore richer rewards beyond pass/fail for RL (e.g., stepwise semantic rewards, unit tests for predicates, coverage of rule clauses).
- Evaluate program-level supervision strategies (e.g., contrastive learning with counterfactual statutes/facts, weak supervision from traces).
- Compare diverse planning/tool-use strategies (planner–solver decomposition, tool routing between arithmetic libraries and logic engines).
- Error analysis depth
- Quantify how often errors stem from mis-grounded facts vs. rule selection vs. arithmetic across all domains, and report correlation with context length and statute complexity.
- Provide fine-grained mapping from specific statutory constructs (e.g., nested exceptions, phaseouts, thresholds) to observed failure rates to target model development.
- Generalization and transfer
- Evaluate cross-domain transfer (train on one domain’s statutes, test on another) to measure whether models learn reusable deontic reasoning abstractions.
- Test out-of-distribution generalization with previously unseen statutes and synthetic-but-legalistic rule schemas.
- Study temporal generalization (train on pre-2024 statutes, test on 2025+ changes) to assess update robustness.
- Interpretability and user-facing auditability
- Measure the consistency and readability of generated Prolog traces for human auditors; run user studies to evaluate audit burden and error detectability.
- Develop diagnostics that localize errors to statute selection, fact extraction, or arithmetic, and measure their usefulness for practitioners.
- Ethical and societal considerations
- Assess domain-specific harms and fairness concerns (e.g., disparate error rates across protected classes in housing/immigration scenarios) and include fairness-aware metrics.
- Provide guidance on safe deployment protocols (e.g., thresholds for human-in-the-loop escalation based on calibrated confidence).
- Reproducibility and release details
- Release all prompts, seeds, multiple stochastic generations, and solver versions to enable robust replication; report sensitivity analyses across seeds and decoding parameters.
- Provide standardized train/dev/test splits that remain stable across future benchmark revisions, plus a protocol for legally-driven updates without data leakage.
These gaps collectively point to needs for broader coverage, deeper validation of formalizations, richer evaluation protocols (including calibration and interpretability), more robust symbolic–neural integrations, and stronger generalization testing under realistic, evolving legal conditions.
Practical Applications
Based on the paper’s methods (LLM-to-Prolog solver workflow, long-context deontic tasks, hard-set curation, error taxonomy) and empirical findings (current models struggle; rule-selection and fact-extraction errors dominate; abstention vs incorrect trade-off; SFT/RL provide limited gains), the following applications emerge.
Immediate Applications
The items below can be deployed now in limited or human-in-the-loop settings; each lists target sectors, potential tools/workflows, and key assumptions.
- Pre-deployment red-teaming and certification for rule-grounded AI
- Sectors: finance, healthcare, legal-tech, insurance, government IT
- What: Use DeonticBench as a standardized test harness to stress-test AI assistants on long-context, statute-grounded tasks before production; produce model scorecards and error profiles (e.g., wrong-rule vs fact-extraction vs numerical errors).
- Tools/Workflows: Benchmark pipeline with SWI-Prolog execution, abstention logging, hard-set scoring and bootstrap CIs; dashboards for error taxonomy coverage.
- Assumptions/Dependencies: Access to the released dataset and code; organizational appetite for model audit; awareness of low performance on hard subsets (risk controls required).
- Compliance guardrails for enterprise assistants with auditable traces
- Sectors: finance (KYC/AML), insurance underwriting, HR policy, procurement
- What: Wrap LLM answers with a Prolog-based “policy-checker” that generates an executable rule interpretation and a solver trace; return result + trace to auditors and users.
- Tools/Workflows: LLM-to-Prolog translation; SWI-Prolog execution; auto-generated evidence packages (code, inputs, execution logs).
- Assumptions/Dependencies: Policies must be available in text form and narrow in scope; human review for low-confidence cases; trace storage integrated with governance tools.
- Internal policy-to-Prolog regression testing in CI/CD
- Sectors: software/platform engineering, IT governance
- What: Convert corporate policies (e.g., expense policies, access controls) into Prolog modules and run unit tests whenever policies or assistants change; compile-check and solver-verify behavior.
- Tools/Workflows: Policy-to-Prolog codegen; unit tests from curated examples; CI gates on compile/solve success.
- Assumptions/Dependencies: Relatively stable policy text; engineering team to review autoformalizations; SWI-Prolog in build pipeline.
- Airline baggage fee calculators with solver-backed auditability (narrow scope)
- Sectors: travel, airlines, OTAs/customer support
- What: Deploy baggage-fee calculators that use explicit rule modules with solver verification; surface fee breakdowns and rule justifications to customers or agents.
- Tools/Workflows: Curated Prolog rule libraries; LLM-assisted updates when policies change; solver execution for every query.
- Assumptions/Dependencies: Limit to curated carriers/policies; treat LLM program generation as assistive, not authoritative; manual validation for updates.
- Housing-law Q&A for property managers and tenants (human-in-the-loop)
- Sectors: real estate, proptech, legal aid
- What: Narrow-jurisdiction yes/no rights checks with linked statutory support and solver trace; escalate ambiguous cases to professionals.
- Tools/Workflows: Retrieval of labeled statutes; LLM-to-Prolog module generation; trace display; escalation workflow.
- Assumptions/Dependencies: Jurisdictional scoping; explicit disclaimers; professional oversight.
- Immigration case triage support for legal operations
- Sectors: legal services, immigration clinics
- What: Facts-only extraction and rule-criteria mapping to flag likely accepted/dismissed patterns and missing evidence, with an explicit logic program for attorney review.
- Tools/Workflows: Facts extraction prompts; rule encoding modules; program execution and trace for review.
- Assumptions/Dependencies: Strict human review; secure handling of sensitive data; acceptance of solver traces as internal artifacts only.
- Model-risk management and procurement screening for AI tools
- Sectors: finance (SR 11-7), healthcare (clinical AI governance), public sector procurement
- What: Require vendors to report DeonticBench scores and error breakdowns; use abstention/error profiles to set deployment guardrails and escalation policies.
- Tools/Workflows: Evaluation templates; contract clauses referencing benchmark performance and evidence logging; acceptance thresholds with confidence routing.
- Assumptions/Dependencies: Agreement on thresholds and interpretations; updates as statutes/policies evolve.
- Confidence-aware routing and escalation policies
- Sectors: contact centers, fintech/insurtech apps, gov services
- What: Implement abstention-aware workflows that route high-uncertainty cases to stronger models or humans; focus LLMs on high-confidence slices.
- Tools/Workflows: Calibrated abstention detectors; multi-model routers; human-in-the-loop queues; logging for post-incident analysis.
- Assumptions/Dependencies: Calibration requires additional telemetry; organizational processes for escalations.
- Research and education modules on interpretable, rule-grounded AI
- Sectors: academia, professional training, internal L&D
- What: Use DeonticBench tasks to teach logic programming, autoformalization, and trust in AI; compare chain-of-thought vs. solver-based reasoning with graded assignments.
- Tools/Workflows: Course labs with SWI-Prolog; notebooks demonstrating failure modes; student projects on rule selection and fact extraction.
- Assumptions/Dependencies: Instructor familiarity with Prolog; compute suitable for long-context prompts.
- Error-driven dataset augmentation and fine-tuning for domain assistants
- Sectors: legal-tech startups, internal AI teams
- What: Mine wrong-rule, fact, and arithmetic errors to generate targeted training examples or few-shot demonstrations; iteratively raise performance in a bounded domain.
- Tools/Workflows: Error taxonomy dashboards; auto-curation scripts; SFT/DPO/GRPO pipelines seeded by reference Prolog.
- Assumptions/Dependencies: Gains may be domain-specific; RL improvements were limited in the paper—expect diminishing returns without new techniques.
Long-Term Applications
These require advances in autoformalization, reliability, scaling, or standardization before wide deployment.
- End-to-end statutory reasoning services (tax, benefits, licensing)
- Sectors: consumer tax, social services, corporate compliance
- What: Robust assistants that autoformalize statutes on-the-fly, execute rules, and deliver decisions with auditable traces across jurisdictions.
- Dependencies: Substantially higher accuracy on hard subsets; automated rule selection and fact extraction; regularly updated, machine-readable statutes.
- Machine-readable statute and policy repositories
- Sectors: government, standards bodies, regtech
- What: Official publication of statutes/regulations in executable form (e.g., Prolog/PDDL) alongside natural language; versioned, testable rule libraries.
- Dependencies: Legislative/policy process changes; interoperability standards; governance for ambiguity and updates.
- Confidence-calibrated orchestration frameworks for high-stakes AI
- Sectors: healthcare, finance, public benefits
- What: Frameworks that quantify uncertainty, invoke solvers for verification, and enforce escalation and risk thresholds at runtime.
- Dependencies: Reliable confidence estimation for program synthesis and reasoning; policy-aligned risk scoring.
- Neuro-symbolic training methods that reliably generate correct executable programs
- Sectors: AI tooling vendors, research labs
- What: New RL/objectives and data curricula that increase exact-program correctness and reduce abstentions without sacrificing coverage.
- Dependencies: Better rewards beyond current RLHF/GRPO; large-scale gold program corpora; improved compilers/lints.
- Domain-general deontic reasoners for enterprise policy governance
- Sectors: large enterprises with complex policy stacks
- What: Agents that learn and maintain thousands of interlocking policies (conflicts, hierarchies, exceptions) with solver-backed validation and change-impact analysis.
- Dependencies: Scalable rule-knowledge graphs; conflict detection; governance UX for policy owners.
- Clinical guideline enforcement with auditable logic
- Sectors: healthcare delivery, payers
- What: Encode obligations/permissions/contraindications from clinical guidelines to check orders, prior auth, and care plans with traceability.
- Dependencies: Acceptance by regulators and clinicians; mapping unstructured EHR data to facts; stringent safety validation.
- Automated regulatory compliance for energy and environmental rules
- Sectors: energy, utilities, manufacturing
- What: Check projects and operations against permitting/emissions/interconnect rules with solver proofs; produce audit-ready reports.
- Dependencies: Codified rule corpora; accurate extraction from technical documents; cross-jurisdiction harmonization.
- Robotics and agentic systems with rule-constrained planning
- Sectors: robotics, autonomous systems, warehouse automation
- What: Use deontic constraints (prohibitions/permissions) in planners; verify plans with symbolic solvers before execution.
- Dependencies: Real-time autoformalization of safety/policy constraints; integration with motion/task planners.
- Financial-crime and risk decisioning with executable policy traces
- Sectors: banking, payments, fintech
- What: KYC/AML and credit-rule engines that combine learned risk signals with explicit rule proofs for every decision, enabling regulatory explainability.
- Dependencies: High-precision fact extraction from documents and transactions; regulator acceptance; low false-positive rates.
- Cross-lingual, cross-jurisdiction legal assistance
- Sectors: global enterprises, NGOs
- What: Deontic reasoning across multiple legal systems and languages with consistent audit trails.
- Dependencies: Multilingual rule corpora; localization of rule hierarchies; jurisdiction-aware retrieval and normalization.
- Tooling ecosystem: policy-to-code IDEs and “linting” for rules
- Sectors: software tooling, legal informatics
- What: IDE extensions that assist drafters in writing policies and simultaneously generate/validate executable rule modules with test suites.
- Dependencies: Authoring standards; usability research with policy owners; better static analysis for logic programs.
Notes on feasibility across all items:
- Today’s models underperform on hard, high-stakes rule tasks; all production uses must include human oversight, narrow scope, curated rules, and clear disclaimers.
- Reliable deployment hinges on accurate rule retrieval/selection, structured fact extraction, and numerical precision—identified by the paper as dominant failure modes.
- SWI-Prolog or equivalent solvers, versioned rule libraries, and governance processes are core infrastructure dependencies.
- Prompt sensitivity and variability persist; evaluation and monitoring must be continuous as statutes and models change.
Glossary
- Ablations: Targeted experimental variations used to assess the impact of specific components or settings. "reasoning-effort ablations are detailed in the appendix"
- Abstention calibration: Techniques to align when a model should abstain from answering with its confidence, to reduce risky outputs. "With fine-grained abstention calibration, a smaller model can handle high-confidence cases"
- Abstentions: Cases where the model does not produce a scorable answer (e.g., invalid program or unparsable output). "abstentions (non-executable Prolog or unparsable direct outputs)"
- Administrative Appeals Office (AAO): A USCIS body that adjudicates immigration-related appeals. "Administrative Appeals Office (AAO) non-precedent decisions."
- Autoformalization: Converting natural-language problems into formal, machine-executable representations. "often referred to as autoformalization"
- Bootstrap confidence intervals: Nonparametric intervals computed via resampling to quantify uncertainty in performance estimates. "95% bootstrap confidence intervals."
- Chain-of-thought (CoT): A prompting technique eliciting step-by-step reasoning in LLMs. "free-form chain-of-thought reasoning"
- Compile-checks: Automatic compilation attempts to verify that generated code is syntactically valid before execution. "compile-checks them in SWI-Prolog solver"
- Confidence-aware inference: Inference strategies that incorporate model confidence to decide when to answer or defer. "confidence-aware inference."
- Defeasible reasoning: Logical reasoning that allows conclusions to be reversed when new information arises. "negation, implication, and defeasible reasoning"
- Deontic reasoning: Reasoning about normative concepts like obligations, permissions, and prohibitions under formal rules. "deontic reasoning: reasoning about obligations, permissions, and prohibitions under explicit rules."
- Direct Preference Optimization (DPO): An RLHF-style training method that optimizes models directly from preference data without explicit reward models. "Direct Preference Optimization (DPO)"
- Dr. GRPO: A variant of GRPO incorporating domain-specific reward shaping (here, predicate-aware). "Dr. GRPO, a variant of Group Relative Policy Optimization (GRPO)"
- Few-shot prompting: Providing in-context exemplars to guide model outputs on new tasks. "Few-shot prompting uses the same program-synthesis format with in-context exemplars."
- First-order logic (FOL): A formal logic with quantifiers and predicates used for precise reasoning. "synthetic first-order-logic reasoning"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes policies relative to group-based baselines. "Group Relative Policy Optimization (GRPO)"
- Hard subsets: Curated, challenging portions of a benchmark designed to stress models and expose failure modes. "all models struggle on the hard subsets of the benchmark"
- Logical entailment: Determining whether a conclusion necessarily follows from given premises or rules. "logical entailment, and multi-factor legal decision-making."
- Macro-F1: The unweighted mean F1 score across classes, treating each class equally. "46.6 macro-F1 on Housing."
- Non-precedent decisions: Case decisions that do not establish binding precedent for future cases. "non-precedent decisions."
- Off-policy reinforcement learning: RL where the learning policy differs from the behavior policy that generated data. "on-policy and off-policy reinforcement learning"
- On-policy reinforcement learning: RL where the learning policy is the same as the behavior policy used to generate data. "on-policy and off-policy reinforcement learning"
- PDDL (Planning Domain Definition Language): A formal language for describing planning problems and domains. "formalisms such as PDDL and Prolog"
- Phaseout computation: Tax-specific arithmetic calculating benefit reductions as income exceeds thresholds. "phaseout computation"
- Predicate-aware reward: A reward design that considers logical predicates or structured targets during RL training. "a predicate-aware reward function"
- Prolog: A logic programming language used to express rules and facts and execute symbolic reasoning. "translate statutes and case facts into executable Prolog"
- Program trace: The explicit, step-by-step execution record of a program, useful for auditing reasoning. "an explicit program trace"
- Remand: Sending a case back to a lower authority for further action or reconsideration. "remanded for further revision"
- Retrieval-Augmented Generation (RAG): A method that augments generation with retrieved documents for grounding. "a legal retrieval setting using RAG"
- Solver-assisted workflow: A pipeline where models produce executable code that an external solver runs to obtain answers. "we include a solver-assisted workflow"
- Statute: A written law or policy text forming the authoritative rules to be applied. "from the statute and case context"
- Statutory reasoning: Applying statutory text to case facts to derive legally grounded conclusions. "prior work on statutory reasoning with symbolic solvers"
- SWI-Prolog solver: A widely used Prolog system employed here to execute generated logic programs. "SWI-Prolog solver"
- Zero-shot prompting: Generating solutions without in-context examples, typically guided by instructions and constraints. "Zero-shot prompting generates a complete executable Prolog program"
Collections
Sign up for free to add this paper to one or more collections.