- The paper introduces CLaw, a benchmark that evaluates LLMs’ ability to precisely recall and interpret Chinese statutes and apply legal reasoning.
- It constructs a comprehensive, subparagraph-level corpus of 306 statutes (64,849 entries) and assesses both ID and content retrieval using hierarchical metrics.
- Empirical findings show Chinese LLMs excel at surface recall yet struggle with deep legal reasoning and precise temporal citation.
CLaw: A Fine-Grained Benchmark for Chinese Legal Knowledge and Reasoning in LLMs
Motivation and Benchmark Design
The CLaw benchmark addresses a critical gap in the evaluation of LLMs for the legal domain, particularly within the context of Chinese law. Existing benchmarks for legal AI often lack the granularity and temporal precision required for real-world legal practice, where accurate citation of statutes—including historical versions and subparagraph-level references—is essential. CLaw introduces a two-pronged evaluation framework: (1) a comprehensive, subparagraph-level, temporally versioned statutory corpus covering all 306 Chinese national statutes (64,849 entries), and (2) a challenging set of 254 case-based reasoning tasks derived from Supreme People’s Court Guiding Cases.
This design enables the dissection of LLM capabilities into two orthogonal axes: (a) knowledge mastery—precise recall and localization of statutory provisions, and (b) reasoning application—the ability to apply legal knowledge to complex, real-world case scenarios. The benchmark’s structure is motivated by the observation that general pre-training on legal texts is insufficient for reliable legal reasoning, as it does not guarantee mastery of the fine-grained, temporally sensitive knowledge required in legal adjudication.

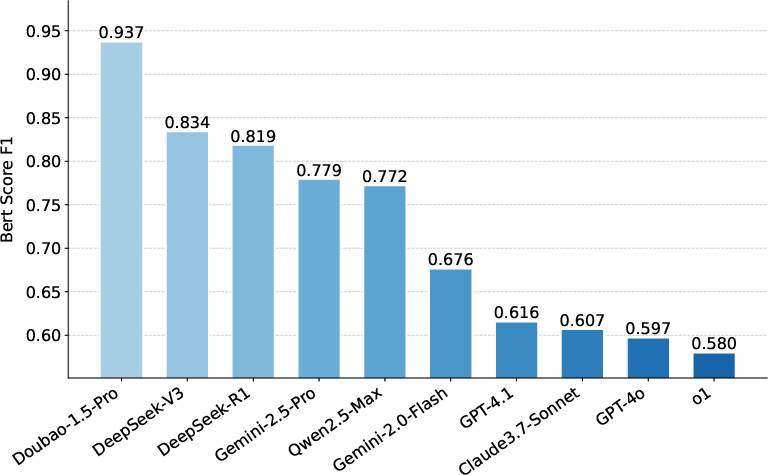
Figure 1: CLaw queries are more precise and temporally grounded than those in prior benchmarks; BERTScore recitation results for the Civil Code highlight significant performance gaps among LLMs.
Statutory Knowledge Recall: Corpus Construction and Evaluation
The CLaw statutory corpus is constructed by crawling all national statutes from the official Chinese legal database, segmenting each statute to the subparagraph level, and tracking all historical revisions. Each entry is indexed by law name, version date, article, paragraph, and subparagraph, enabling temporally precise queries that mirror judicial citation practices.
Two primary tasks are defined:
- ID Retrieval: Given a statute and its version, the model must identify the correct article, paragraph, and subparagraph indices for a given legal text.
- Content Retrieval: Given a statute index, the model must recite the exact content of the provision.
Hierarchical accuracy metrics are used for ID Retrieval (article, paragraph, subparagraph), and lexical/semantic similarity metrics (ROUGE, BLEU, Edit Distance, BERTScore) for Content Retrieval.
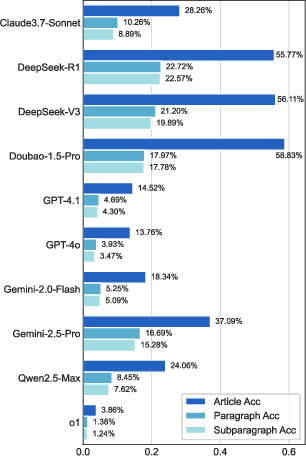
Figure 2: Hierarchical accuracy for ID Retrieval shows a steep drop from article to subparagraph granularity, indicating the challenge of fine-grained legal recall.
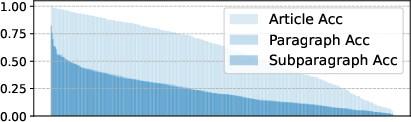
Figure 3: Per-statute best-LLM ID-retrieval accuracy; performance collapses at paragraph and subparagraph levels for most statutes.
Empirical Findings: Knowledge Recall
Evaluation of ten leading LLMs (including Chinese and global models) reveals several key findings:
- Granularity Challenge: Even the best model (Doubao-1.5-Pro) achieves only 58.8% article-level accuracy; paragraph and subparagraph accuracies are typically less than one-third of article-level, with many statutes exhibiting <50% accuracy at fine granularity.
- Chinese LLMs Lead, but with Trade-offs: Chinese-origin models (Doubao-1.5-Pro, DeepSeek-V3, DeepSeek-R1, Qwen-2.5-Max) outperform global models at article-level recall. However, DeepSeek-R1 surpasses Doubao at paragraph/subparagraph levels, indicating a trade-off between surface memorization and structural localization.
- Global LLMs Underperform: GPT-4.1, GPT-4o, and o1 lag significantly, often refusing to answer or providing disclaimers. Gemini-2.5-Pro and Claude-3.7-Sonnet are the most competitive non-Chinese models but still trail the top Chinese LLMs.
- Error Patterns: Common errors include hallucination (fabricated or irrelevant content), incorrect versioning (retrieving outdated or wrong articles), and refusal to answer. These errors are systemic and not limited to a single model.
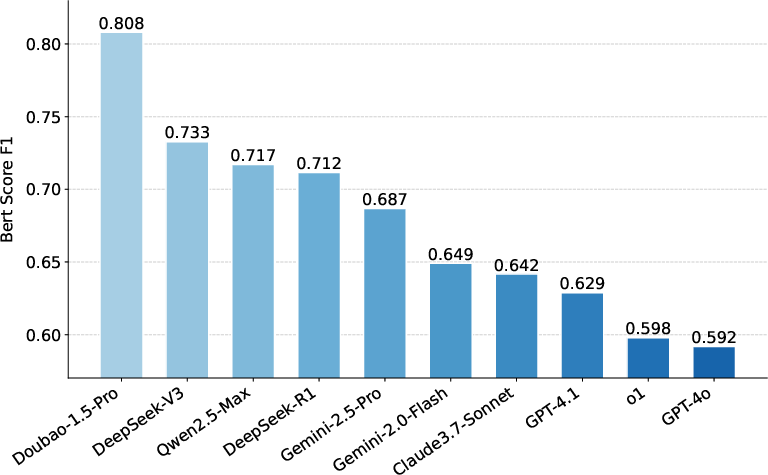
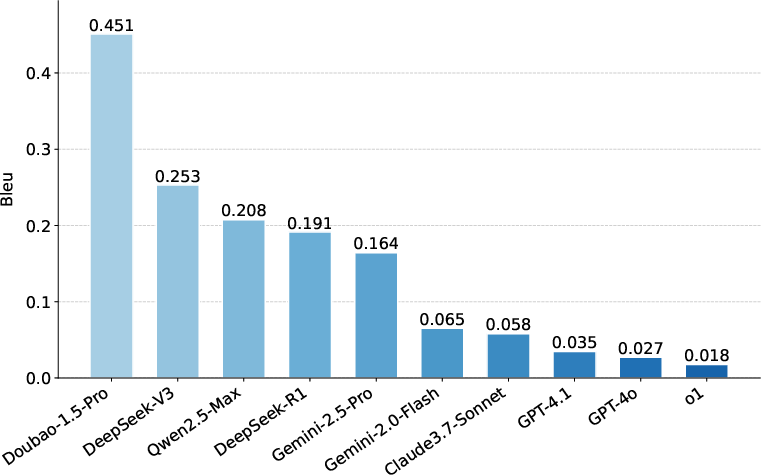
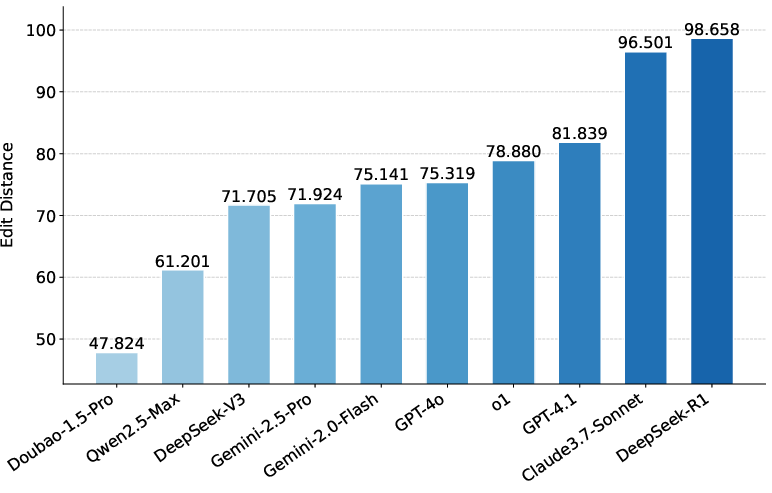
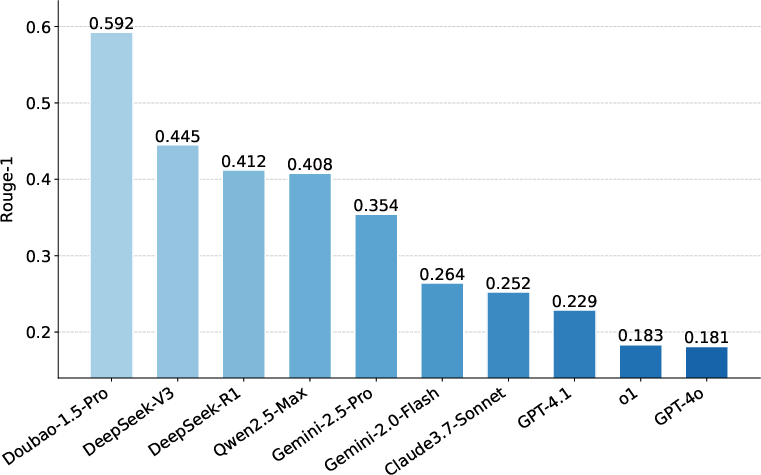
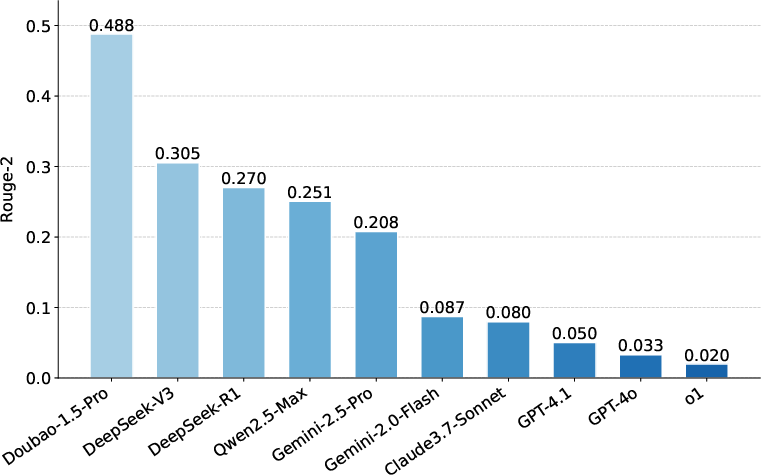
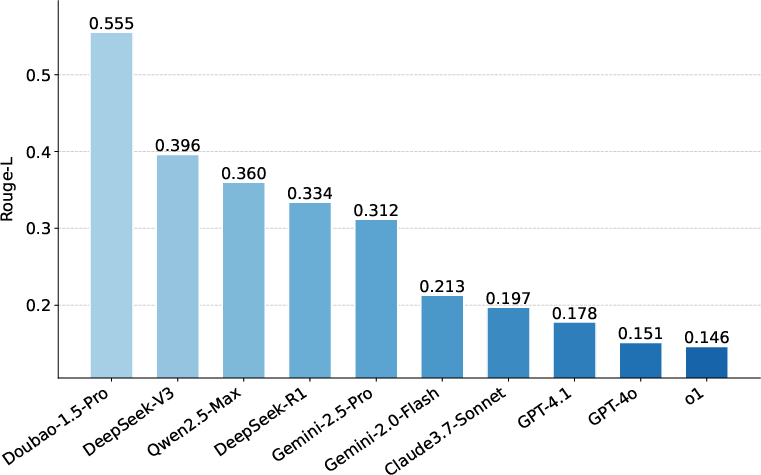
Figure 4: BERTScore for Content Retrieval; Doubao-1.5-Pro achieves the highest semantic similarity, but even the best models fall short of verbatim recitation.
Case-Based Legal Reasoning: Task and Results
The case-based reasoning task leverages 254 Supreme People’s Court Guiding Cases, each structured with factual background, adjudication outcome, focus of dispute, judicial reasoning, and relevant legal articles. The evaluation employs an LLM-as-a-judge pipeline, using a rubric covering reasoning rigor, knowledge accuracy, logical structure, clarity, and conciseness. Automated LLM judging is validated against human expert ratings (Pearson r=0.82).
Key results:
- Top Performers: Gemini-2.5-Pro and DeepSeek-R1 achieve the highest overall ratings (84.8 and 83.3, respectively), with a clear margin over the next tier (GPT-4.1, Qwen-2.5-Max, Claude-3.7-Sonnet).
- Dimension Analysis: Reasoning rigor and knowledge accuracy are the most discriminative aspects. Presentational aspects (structure, clarity, conciseness) are generally strong across models.
- Knowledge-Reasoning Synergy: There is a strong correlation between statutory recall accuracy and reasoning performance, especially at the paragraph level (r=0.70). However, knowledge mastery alone is insufficient; robust general reasoning is also required. For example, Doubao-1.5-Pro, despite strong recall, underperforms in reasoning application.
Analysis of Retrieval-Augmented Generation (RAG) and SFT
Preliminary experiments with search-based RAG systems (Doubao-1.5-Pro, DeepSeek-R1) demonstrate that current retrieval methods are inadequate for legal tasks. Failures include:
- Inability to resolve article renumbering and temporal versioning.
- Over-reliance on shallow similarity and outdated sources.
- Lack of precise mapping between user queries and statute structure.
These findings suggest that neither pure memorization (SFT) nor naive RAG is sufficient. Effective legal AI requires high-quality, temporally versioned corpora (as provided by CLaw) and advanced retrieval mechanisms that understand legal document structure and legislative evolution.
Implications and Future Directions
The CLaw benchmark exposes fundamental limitations in current LLMs for legal applications:
- Precision and Temporal Awareness: Accurate legal reasoning demands subparagraph-level and temporally precise knowledge. Standard pre-training is inadequate; explicit modeling of document structure and versioning is required.
- Evaluation Methodology: Automated LLM-as-a-judge pipelines, when carefully designed and validated, can scale the evaluation of complex legal reasoning tasks.
- Knowledge Integration: Future RAG systems must incorporate legal citation structure, temporal validity, and hierarchical document understanding. SFT on curated, versioned corpora can improve internal knowledge, but must be complemented by robust retrieval and verification.
- Benchmarking and Specialization: Domain-specific benchmarks like CLaw are essential for progress in legal AI. Broader task coverage (e.g., legal drafting, dispute identification, predictive judgment) is needed to reflect the full spectrum of legal reasoning.
Conclusion
CLaw provides a rigorous, fine-grained, and temporally aware benchmark for evaluating Chinese legal knowledge and reasoning in LLMs. Empirical results demonstrate that even state-of-the-art models exhibit significant deficiencies in statutory recall and case-based reasoning, particularly at the granularity and temporal precision required for legal practice. The findings underscore that trustworthy legal AI requires a synergistic combination of deep, accurate domain knowledge and robust general reasoning. Current LLMs are not yet suitable for autonomous deployment in high-stakes legal applications without substantial augmentation. CLaw offers a critical resource for diagnosing weaknesses, benchmarking progress, and guiding the development of more reliable, legally competent LLMs.

