- The paper introduces a benchmark using 236 U.S. Supreme Court case pairs to evaluate LLMs on detecting overruling relationships.
- It reveals that LLMs exhibit era sensitivity and rely on shallow heuristics, resulting in significant performance drops on historical cases.
- The study highlights context-dependent reasoning failures, urging improvements in LLM architectures for nuanced legal analysis.
Analysis of "Do LLMs Truly Understand When a Precedent Is Overruled?" (2510.20941)
Introduction
The paper "Do LLMs Truly Understand When a Precedent Is Overruled?" addresses the capability of LLMs, which have been extended with larger context windows, to engage in complex legal reasoning—specifically the identification of overruling relationships in U.S. Supreme Court cases. This evaluation focuses on developing a benchmark that encapsulates the intricacies of legal document comprehension and assesses the models' understanding using a dataset of 236 case pairs. This study identifies three significant limitations in current LLMs: era sensitivity, reliance on shallow reasoning techniques, and failures in context-dependent reasoning.
Research Motivation and Context
The enhancement of LLMs to process larger context windows theoretically positions them for more effective application in domains demanding the comprehension of voluminous, complex documents, such as legal texts. The paper situates itself against the backdrop of existing benchmarks that often oversimplify long-context tasks, highlighting the legal domain's potential as an ideal testbed for realistic evaluation of document understanding capabilities. U.S. law, with its tradition of case law and precedents, provides suitable candidates for analysis given the critical role of understanding overruling relationships for legal professionals.
Methodology
The authors introduce a dataset comprising 236 U.S. Supreme Court case pairs, selected through a rigorous process ensuring that each case was explicitly overruled. This dataset is used to evaluate five state-of-the-art LLMs on tasks designed to probe their comprehension of legal overruling dynamics:
- Task 1: Open-Ended Identification — Required models to identify overruled cases from a given overruling decision text.
- Task 2: Closed-Ended Verification — Asked whether a specified relationship between two cases was an overruling, demanding a "true," "false," or "unknown" response.
- Task 3: Reversed Closed-Ended Verification — Presented logically impossible queries to test models' basic temporal reasoning.
The evaluation metrics focused on measuring accuracy across tasks and intervals, offering a nuanced view of models' performance over varying historical contexts.
Results and Key Findings
The results reveal significant challenges for LLMs in the field of legal reasoning:
- Era Sensitivity: Models exhibit reduced performance when analyzing older cases, highlighting a temporal bias. The accuracy drop for earlier periods demonstrates the difficulties models face with the historical evolution of legal language and reasoning (Table 1).
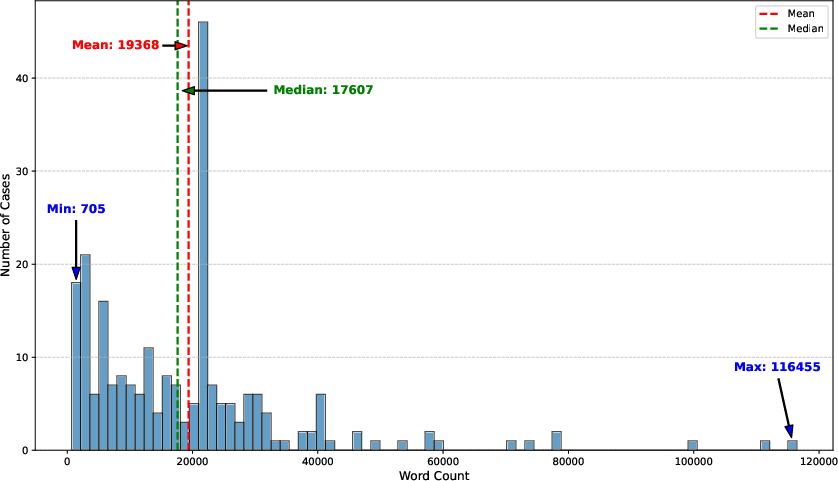
Figure 1: Word Count Distribution of 236 Overruling Cases in Our Dataset.
- Shallow Reasoning: Models frequently resort to superficial heuristics rather than deep comprehension. This is evident in tasks where temporal reasoning suffices (Task 3), contrasting starkly with tasks requiring substantive legal understanding (Task 1).
- Context-Dependent Reasoning Failures: Errors in Task 1 reveal the creation of temporally impossible relationships, indicating insufficient integration of temporal logic and complex legal narratives.
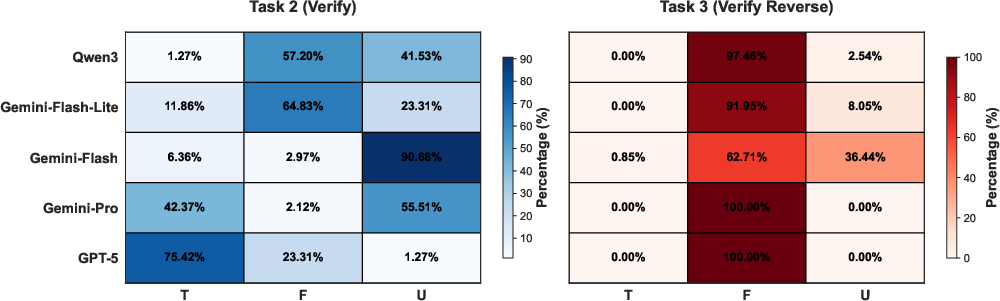
Figure 2: Confusion Matrix for Verification Tasks. T, F, and U stand for True, False, and Unknown respectively.
Discussion and Implications
The performance disparities across epochs underline the necessity for LLMs to integrate historical legal language and reasoning patterns. The models' reliance on shallow reasoning signifies a critical gap in their training, suggesting a need for approaches that better simulate legal comprehension. The high performance on temporally straightforward tasks relative to complex logical reasoning tasks (Task 2 vs. Task 3) suggests that improvements in uncertainty assessment are vital for reliable legal AI systems. The empirical insights underscore the pressing requirement for benchmarks that reflect the genuine complexities of legal reasoning, encouraging further research into LLM architectures and training paradigms that better accommodate the demands of historical depth and reasoning complexity in law.
Limitations and Future Directions
The study acknowledges its limitations, including the geographical focus on U.S. Supreme Court cases and the reliance on existing LLMs at a specific technological juncture. Future work is recommended to expand datasets to cover international cases, explore nuanced legal topic variations beyond explicit overruling, and employ more sophisticated evaluation frameworks. Investigating RAG systems and legal domain-specific model pre-training could facilitate enhanced context comprehension for LLMs.
Conclusion
The paper provides a critical evaluation of leading LLMs on the complex task of understanding legal overruling relationships, revealing substantial room for improvement. The insights derived point to potential pathways for the refinement of LLMs in legal contexts, ultimately striving for models that can reliably undertake detailed and temporally aware legal reasoning. This endeavor lays a foundation for informed experiments in designing AI capable of navigating the sophisticated landscape of legal analysis.

