- The paper introduces a multi-stage training framework (CPT, PSFT, HIPO) to boost legal reasoning and political task performance.
- It leverages 140B tokens and 1.8M annotated samples to address challenges like hallucinated citations and outdated statutory data.
- Results show PoliLegalLM-30B-A3B outperforms similar-scale models in structured legal inference and real-world evaluation benchmarks.
PoliLegalLM: A Domain-Specific LLM for Political and Legal Affairs
Motivation and Domain-Specific Challenges
While foundation LLMs have achieved high performance across general NLP tasks, their application to the legal domain presents persistent challenges: hallucinated legal citations, incomplete or outdated statutory knowledge, and fragile structured reasoning degrade their reliability in practical judicial and governance scenarios. Generic fine-tuning on modest legal datasets with standard SFT does not sufficiently bridge these domain-specific deficits, especially with respect to statutory coverage, interdependent legal concepts, and robustness to complex real-world cases. The paper "PoliLegalLM: A Technical Report on a LLM for Political and Legal Affairs" (2604.17543) proposes a unified, multi-stage domain adaptation scheme specifically designed to satisfy the formal, factual, and logical requirements for legal and political task settings.
Corpus Construction and Data Engineering
PoliLegalLM is grounded in massive, carefully engineered data. The continued pretraining (CPT) corpus contains 140B tokens, meticulously filtered and scored using a hybrid of LLM-based semantic quality solvers and lightweight scorers bootstrapped from Qwen3-0.6B. Legal domain data is accentuated using multi-dimensional legal knowledge frameworks and semi-automatic annotation pipelines, incorporating real-world judgments, statutes, academic papers, and governance logs. Statutory texts are enriched via structured annotation capturing normative rules, legal elements, conceptual boundaries, and inter-article relations. The total instruction dataset for post-training comprises over 1.8M samples, with ~30% specifically legal/governance-oriented, and significant involvement of domain experts during both annotation and format standardization.
Unified Multi-Stage Training Framework
PoliLegalLM employs a hybrid pipeline of CPT, Progressive Supervised Fine-Tuning (PSFT), and Hard Sample-aware Iterative Direct Preference Optimization (HIPO):
- CPT is executed in two phases: first on 8K tokens to efficiently inject scale, followed by long-context adaptation on 16K tokens, targeting lengthy judgments and statutes.
- PSFT institutes curriculum-based SFT, initially training for legal judgment prediction (charge, statute, penalty detection), producing a core model Mcore. Progressive adaptation is applied to downstream reasoning, QA, and generation tasks, controlled by a batch mixing anti-forgetting mechanism maintaining 20% core samples to mitigate catastrophic forgetting of core legal mappings.
- HIPO implements iterative DPO (Direct Preference Optimization) on batches of high-difficulty queries. At each iteration, only unresolved or underperforming samples are retained. Preference pairs are formed using human- or LLM-annotated gold responses versus model outputs, augmented with an explicit auxiliary NLL target for stability and factual retention, enhancing factual consistency and structured inference in hard scenarios.
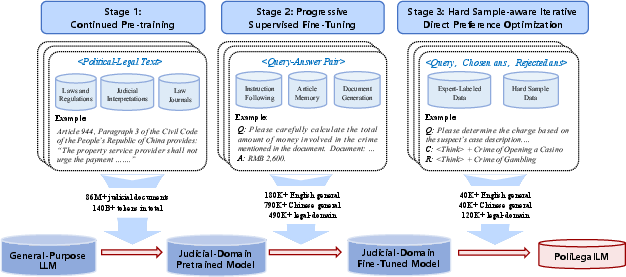
Figure 1: Multi-stage training pipeline of PoliLegalLM: continued pretraining, curriculum-style supervised fine-tuning, and hard-sample-aware preference optimization enable robust domain-specific adaptation.
Evaluation Methodology and Benchmarks
Three complementary benchmarks are used: LawBench (20 tasks for legal cognition, recall, reasoning), LexEval (23 tasks for multi-level legal cognition and ethics in Chinese), and PoliLegal (2000 real-world system queries). Tasks cover knowledge, application, logical inference, information extraction, and scenario-based risk assessment. Evaluation metrics include accuracy, F1, NLD, ROUGE-L, and soft-F1 per benchmark specifications. Baselines span both open-source and proprietary models across scales up to ultra-large mixture-of-experts systems (e.g., Qwen3-235B-A22B, GLM-5, GPT-5).
Results and Comparative Analysis
PoliLegalLM-30B-A3B consistently achieves top scores across LawBench, LexEval, and real-world PoliLegal tasks, surpassing competitor models of equivalent or much larger scales. Notably, it establishes strong generalization and application performance on key legal reasoning benchmarks, with pronounced lead margins on real-world tasks.
- On LawBench, PoliLegalLM-30B-A3B attains an average score of 60.95, outperforming all similarly-sized baselines (e.g., ChatLaw-33B, Qwen3-30B-A3B, Qwen3.5-35B).
- In LexEval, it reaches 62.15, closely following or surpassing much larger models (GLM-5: 65.14) and excelling in logical inference and discrimination metrics.
- In the real-world PoliLegal assessment, the model achieves 87.35, with the next best at 81.25 (+6 point delta).
Notably, the model demonstrates superior breakdown on Understanding, Application, and Logical Inference tasks, reflecting enhanced competence in both factual and reasoning-intensive tasks, not merely memorization or surface patterning.
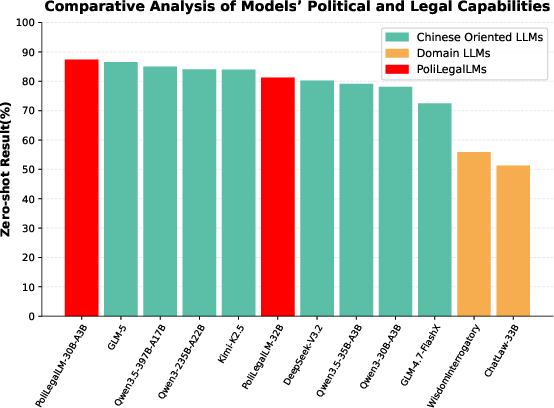
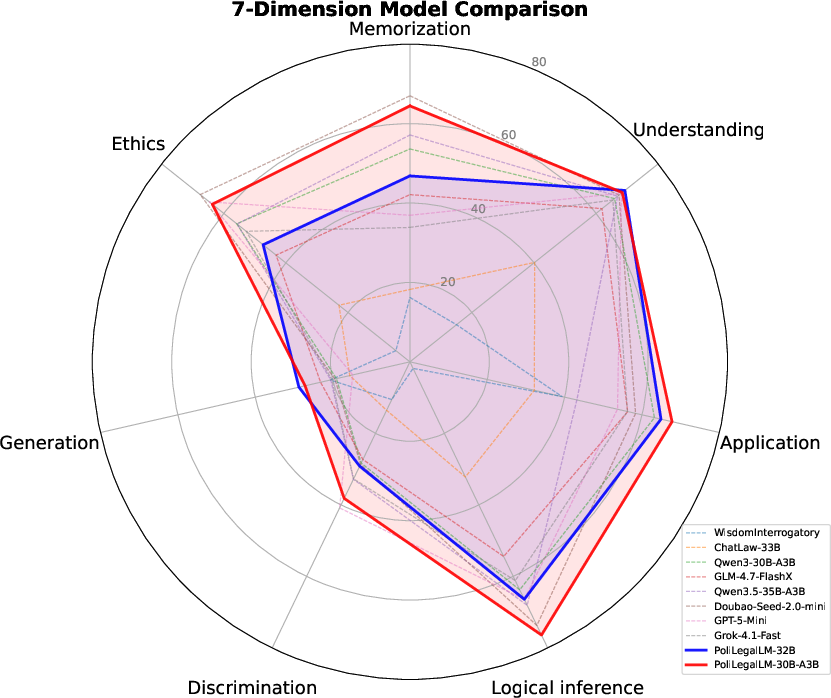
Figure 2: (a) PoliLegal-30B-A3B significantly outperforms a spectrum of open-source models in political and legal evaluations; (b) Among peer models, PoliLegalLM achieves leading scores in Understanding, Application, and Logical Inference capabilities.
Ablation: Contribution of Each Pipeline Stage
Ablation studies show monotonic gains from SFT, CPT, and RL stages. SFT brings immediate improvements due to explicit legal knowledge alignment; CPT further empowers reasoning-heavy tasks and boosts real-world transfer; RL/HIPO provides the largest additional increment in reasoning, discrimination, and ethical compliance dimensions, especially evident in LexEval and PoliLegal. Every stage is empirically indispensable for the observed state-of-the-art results.
Implications and Future Research Directions
The results establish that domain-specific LLMs, when grounded in high-coverage, structured legal corpora and subjected to hybrid anti-forgetting/progressive/task-centric preference optimization, can rival or outperform models several times their parameter count on complex, real-world legal scenarios. Importantly, this demonstrates that scale alone is not sufficient for robust domain reasoning; the synergy of targeted data curation and curriculum/reinforcement optimization is critical.
Despite these achievements, key limitations remain: persistent factuality and robustness challenges in rare or adversarial legal instances, the need for improved output verifiability and interpretability for high-stakes deployment, and difficulties in dynamic statutory updates or multi-agent legal reasoning. Extending the framework to include algorithmic verification, retrieval-augmented reasoning, and agentic frameworks are promising directions for further research.
Conclusion
PoliLegalLM represents a substantive advance in domain-specific large language modeling for legal and governance tasks. Through integrated corpus engineering, curriculum-aligned SFT, and robust hard-sample preference learning, it exhibits strong and consistent superiority across legal knowledge, structured reasoning, and real-world deployment dimensions. The architecture substantiates the viability of mid-size, robustly adapted LLMs for critical legal-AI workflows and sets a precedent for subsequent efforts in both methodology and evaluation for high-assurance domain-specific LLMs.