- The paper introduces LightMamba, an FPGA-accelerated framework for optimizing Mamba state-space models using advanced quantization techniques.
- It details a novel rotation-assisted post-training and power-of-two quantization strategy to mitigate scattered activation outliers.
- The FPGA accelerator achieves up to 6x energy efficiency improvement and 93 tokens/s throughput, highlighting practical gains for real-time inference.
LightMamba: Efficient Mamba Acceleration on FPGA with Quantization and Hardware Co-design
Introduction
The paper, "LightMamba: Efficient Mamba Acceleration on FPGA with Quantization and Hardware Co-design" (2502.15260) presents an approach to enhancing the efficiency of Mamba state space models (SSMs) via FPGA acceleration. Unlike Transformer-based LLMs, Mamba models are characterized by their linear computation complexity relative to sequence length. However, the complexity of computations and scattered activation outliers pose challenges in effectively accelerating these models. This work introduces LightMamba, an FPGA-oriented co-design embracing quantization algorithms and architectural innovations to optimize Mamba inference.
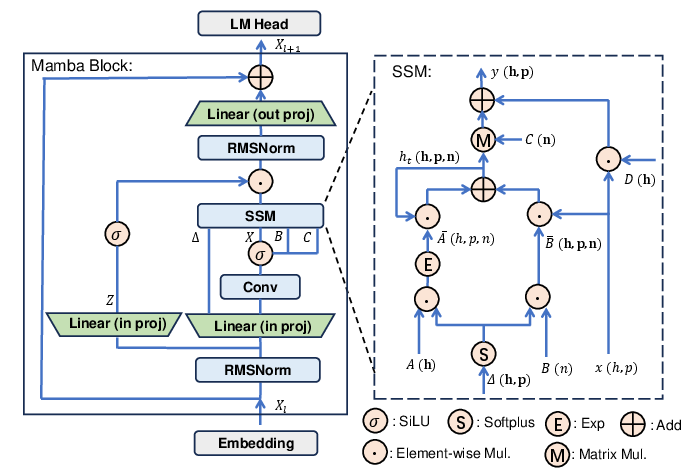
Figure 1: The model architecture of Mamba2 and the detailed computation graph of the SSM layer.
Challenges and Solutions
Low-bit Precision Quantization
Mamba's architecture with scattered activation outliers poses challenges for applying low-bit precision quantization. Unlike Transformers, Mamba exhibits activation outliers across random channels, complicating existing quantization strategies [<cite>xiao2023smoothquant</cite>, <cite>wei2023outlier</cite>]. The paper proposes a rotation-assisted post-training quantization (PTQ) technique, which, when integrated with FPGA-friendly power-of-two (PoT) quantization, effectively reduces quantization error while minimizing reliance on high-bit-precision computation (Figure 2).
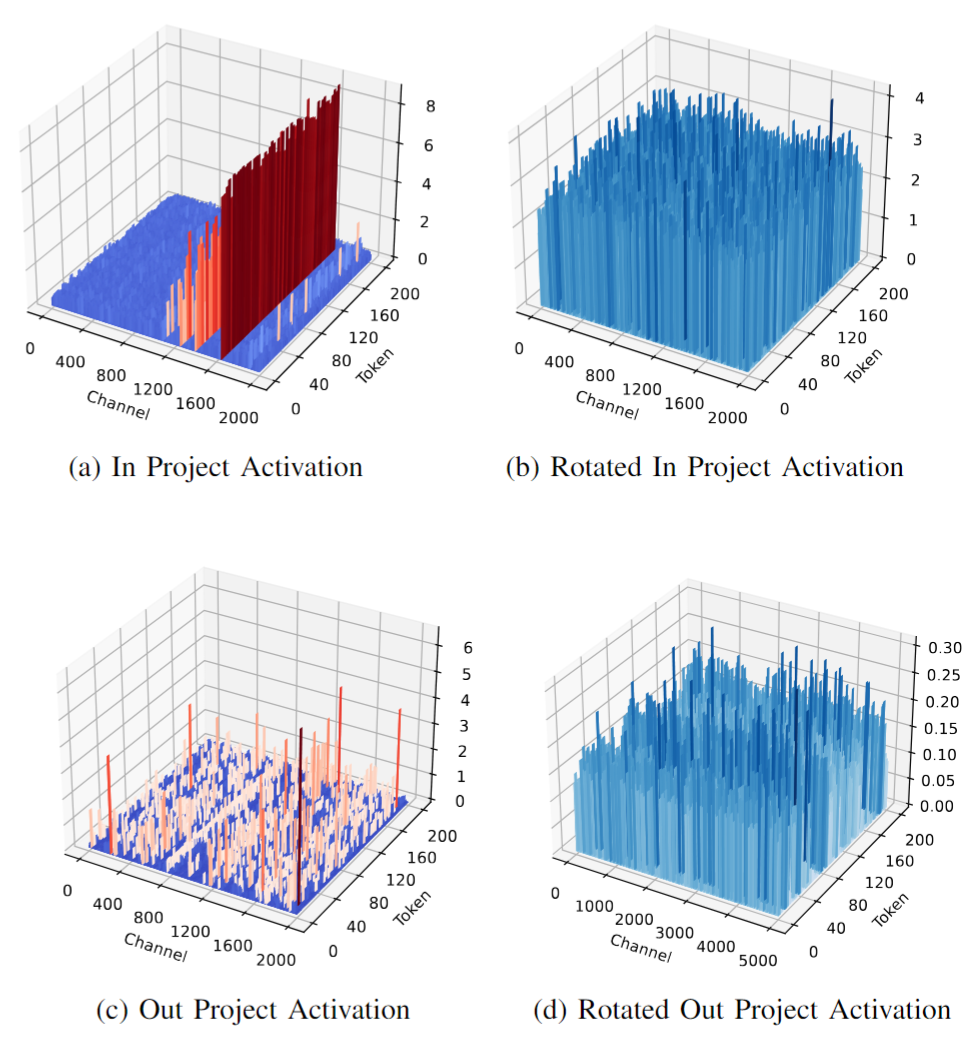
Figure 2: Activation distribution in Mamba2-2.7B before and after rotation.
SSM Layer Quantization
Quantizing the SSM layers is essential to circumvent the excessive hardware costs associated with FP operations. The PoT quantization is employed here, focusing on enabling efficient re-quantization via simple shifts rather than computationally intensive multiplications. This approach mitigates the re-quantization overhead typically seen with low-bit quantization, further optimizing computational efficiency (Figure 3).
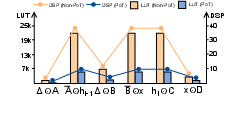
Figure 3: The hardware cost of different operations in the SSM layer with naive Non-PoT quantization and PoT quantization.
Co-designed FPGA Accelerator
The FPGA accelerator design embeds customized hardware components, including dedicated modules like the Hadamard Transform Unit (HTU), devised to support the rotation-assisted quantization. This customization is pivotal for seamlessly orchestrating operations while addressing the non-trivial data dependencies of the SSM computations (Figure 4).
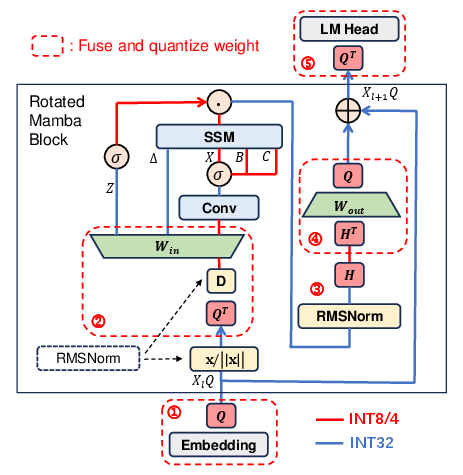
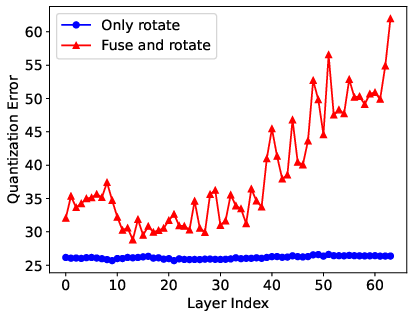
Figure 4: (a) The proposed rotation-assisted quantization algorithm. Both Q and H are Hadamard matrices to ensure computation correctness. (b) Quantization error of the output projection weight after only rotation or fusion and rotation.
Another key innovation lies in computation reordering and fine-grained computation pipelining to enhance hardware utilization. By restructuring data production sequences, LightMamba achieves optimal execution overlaps between input projections and SSM layers (Figure 5).
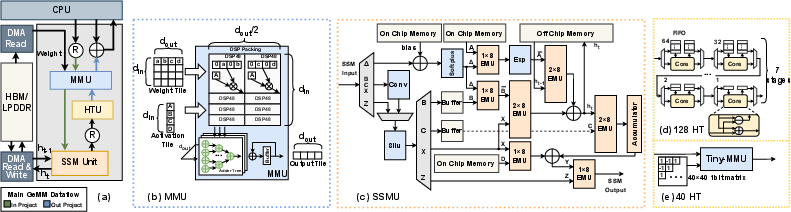
Figure 5: Diagram of (a) the overall architecture, (b) SSMU, (c) MMU, (d) 128-point HTU, and (e) 40-point HTU.
Implementing LightMamba on the Xilinx Versal VCK190 FPGA yielded 4.65 to 6.06 times better energy efficiency compared to GPU baselines, and a throughput of 93 tokens/s on the Alveo U280 FPGA. These metrics underscore the efficacy of combining PTQ, PoT quantization, and meticulous hardware-software co-design in FSM acceleration.
LightMamba presents a pioneering framework in optimizing FPGAs for SSMs, with implications that extend into future state space model applications, particularly in domains demanding energy-efficient real-time inference. The inferences drawn from this research could direct future work towards further bridging the gap between model accuracy and computational frugality.
Conclusion
LightMamba constitutes a comprehensive framework for energizing the acceleration of Mamba architectures on FPGAs through adept quantization algorithms and system-level co-design. This synergistic approach demonstrates both substantial computational efficiency and minimized power consumption, setting a precedent for further endeavors in efficient AI model deployment.

