- The paper presents a novel accelerator architecture integrating a Systolic Scan Array based on the Kogge-Stone algorithm to handle sequential SSM operations on edge devices.
- It employs a hybrid quantization method using tensor- and channel-granularity techniques to minimize memory usage while maintaining model accuracy.
- Extensive evaluations show an 11.6× speedup, 11.5× energy efficiency improvement, and 601× performance per unit area, ideal for resource-constrained environments.
Mamba-X: An End-to-End Vision Mamba Accelerator for Edge Computing Devices
Introduction
The paper "Mamba-X: An End-to-End Vision Mamba Accelerator for Edge Computing Devices" presents a specialized accelerator designed to improve the efficiency of Vision Mamba models on resource-constrained edge devices. Vision Mamba leverages State Space Models (SSMs) for computer vision tasks, offering a compelling alternative to transformers by reducing latency and memory consumption. However, deploying Vision Mamba on edge devices is challenging due to the inherent sequential nature of SSM operations, which leads to inefficient GPU utilization.
Mamba-X Architecture
Key Features
Mamba-X introduces an integrated architecture that includes a Systolic Scan Array (SSA) and a novel quantization scheme. The SSA is designed based on the Kogge-Stone algorithm, enabling parallelism in scan operations and reducing memory overhead. This architecture shifts from GPU-based execution to a more efficient, low-latency pipeline suited for edge environments.
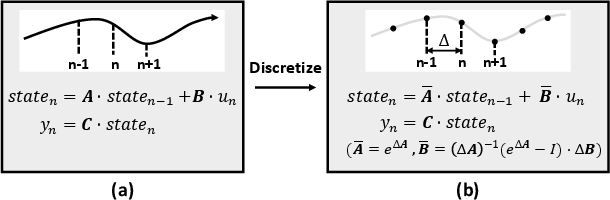
Figure 1: SSM in (a) continuous and (b) discrete time domain.
Systolic Scan Array (SSA)
The SSA takes advantage of the Kogge-Stone algorithm to execute selective scan operations efficiently. Its structure minimizes off-chip memory access by facilitating direct data communication between processing elements, drastically cutting down the need for intermediate storage. This architectural choice allows the SSA to manage dependencies and perform computations more efficiently than traditional GPU-based implementations.
Quantization Approach
Mamba-X employs a hybrid quantization method to maintain model accuracy while optimizing memory usage. This involves tensor-granularity quantization for linear layer weights and channel-granularity quantization for activations within SSM blocks. The quantization technique is tailored to the data distribution of Vision Mamba to ensure minimal accuracy loss.
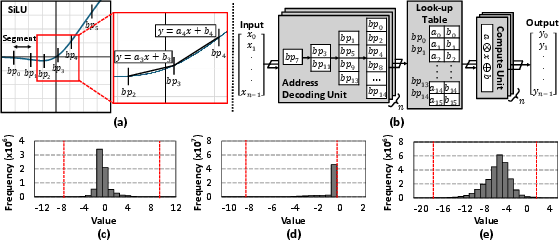
Figure 2: (a) Example of how SiLU function can be approximated using linear interpolation. (b) Mamba-X's profile-guided SFU with a 16-entry LUT. The SFU locates the segment in which each value in the input vector x is located, fetches the relevant coefficients from the LUT, and performs linear interpolation. (c), (d), and (e) show the input distributions for SiLU, exponential, and softplus functions, respectively, during Vision Mamba inference. Each graph has two red dashed lines, within which 99.9\% of the input data falls.
A specialized special function unit (SFU) leverages lookup tables (LUT) to approximate non-linear functions (e.g., SiLU, exponential) with high accuracy, utilizing profile-guided refinement to build efficient LUTs.
Speedup and Energy Efficiency
Mamba-X demonstrates a substantial improvement over edge GPUs, achieving an average 11.6× speedup in selective scan throughput. This performance enhancement is coupled with an 11.5× improvement in energy efficiency, highlighting Mamba-X's suitability for edge computing environments where power is a critical constraint.
Area Efficiency
Remarkably, Mamba-X achieves these performance gains while occupying significantly less silicon area, just 0.4% of that used by a typical Jetson AGX Xavier GPU. This area efficiency translates into an impressive 601× increase in performance per unit area.
Model Accuracy
Despite the aggressive quantization and optimization strategies, Mamba-X maintains robust model accuracy, with a top-1 accuracy reduction of less than 1\%p compared to FP16 baselines using Vision Mamba models. The SFU's LUT-based approach effectively balances accuracy and hardware cost, adapting the complexity based on the function and input distribution characteristics.
Conclusion
Mamba-X successfully addresses the computational and memory challenges faced by Vision Mamba on edge environments through innovative architectural and quantization strategies. By enhancing selective scan throughput, reducing power consumption, and maintaining accuracy, Mamba-X paves the way for deploying efficient high-resolution vision models in real-time applications on resource-limited devices.