- The paper introduces a safety-gated MCP architecture implementing feedback normalization and delayed reward linkage to improve RL coding agent reliability.
- It employs a deterministic ranker combined with a shadow contextual-bandit to log policy actions and ensure controlled, auditable updates.
- Empirical evaluation reveals robust decision accuracy (0.800) and perfect hard-negative suppression (1.000), albeit with increased operational latencies.
Feedback-Normalized Developer Memory for RL Coding Agents: A Safety-Gated MCP Architecture
Motivation and Problem Scope
Agentic LLM-based coding systems now orchestrate complex, multi-turn software-engineering workflows, where persistent, context-sensitive memory is essential for performance and reliability. In RL-coded environments, subtle implementation variations compound the risk of propagating incorrect inferences, as memory retrieval events may deeply impact algorithmic invariants and code correctness. The standard approaches of expanding context windows or generic RAG integration are manifestly inadequate due to their lack of grounded feedback assimilation, delayed reward linking, or governance over memory influence on RL/control processes. This motivates a principled architecture for developer memory—specifically, one that treats every retrieval action as a logged, feedback-normalizable, delayed-reward-aware contextual decision.
System Architecture
The RL Developer Memory system is implemented as a local-first MCP server mediating between agentic code execution and the underlying developer-memory store. Its architectural core consists of a deterministic ranker (deployed as the live baseline) and a contextual-bandit residual policy that operates in shadow mode. This residual learner, gated by conservative OPE, may only be activated in controlled low-risk canaries (Figure 1).
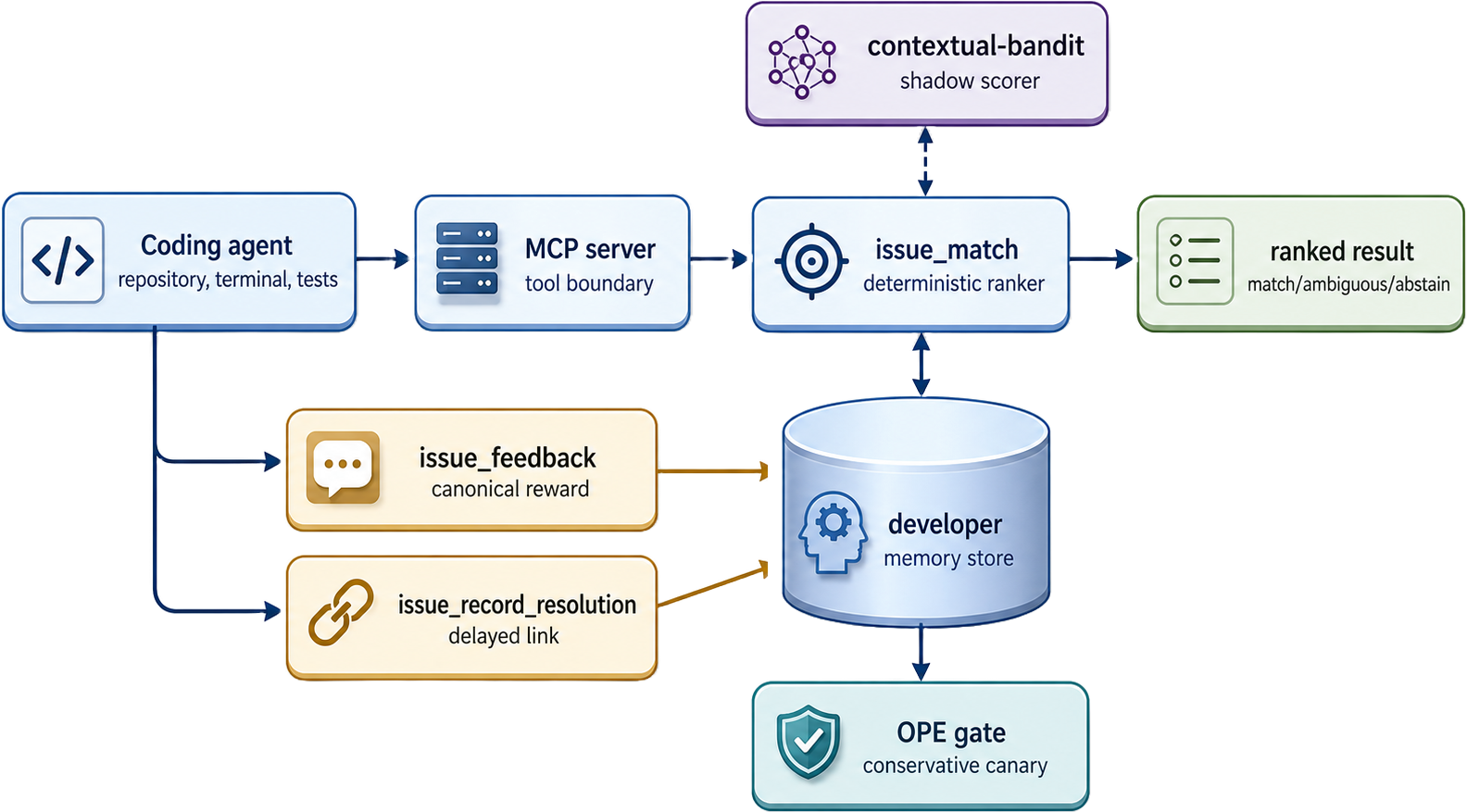
Figure 1: System architecture. The deterministic ranker remains the deployed baseline; the contextual bandit runs in shadow mode and only supplies logged propensities and bounded residual scores unless the OPE gate authorizes a conservative low-risk canary.
Key architectural features:
- Feedback normalization contract transforms raw heterogeneous developer signals into a bounded canonical reward set, facilitating updates, auditability, and diagnostic consistency.
- Delayed reward linkage ties later verified resolutions to specific prior memory retrieval actions, enabling credit assignment critical for RL.
- Shadow bandit instrumentation logs residual policy propensities and scores alongside execution trajectories for robust off-policy evaluation.
- OPE-gated activation blocks live override of the deterministic baseline absent strong empirical lower-bounds on policy value and support in logged feedback.
- Theory-to-code-traceable governance ensures that RL/control-specific retrievals and updates explicitly encode algorithmic obligations, validation-tier status, and review state.
The system further supports real-time tool surface interaction through MCP, featuring methods for memory matching, feedback normalization, and resolution recording.
Decision Process and Governance Mechanisms
The memory-match problem is cast as a contextual decision process. At each retrieval, a structured context is derived from error state, query, project scope, code path, and RL/control hints, subsequently matched against the developer memory bank with candidate-specific features (e.g., lexical, exception, project, feedback-derived quality, algorithm family).
The deterministic ranker applies conservative margin and specificity predicates in decision selection, thereby suppressing hard negatives and false positives—even for semantically similar yet contextually dangerous retrieval targets (e.g., patching a DQN terminal-mask bug with a superficially related fix for PPO clipping).
Feedback events and delayed resolutions are mapped to a canonical set
({candidate_accepted,candidate_rejected,fix_verified,false_positive,…})
with calibrated numeric rewards (e.g., fix_verified: $1$, false_positive: −1), critical for stability and observability in RL training updates. The system enforces idempotence and auditability via tuple keys on retrieval-feedback-resolve chains, further supporting external governance and review.
Crucially, RL/control memories encode explicit theory-to-code metadata and must pass review-gated promotion, blocking the propagation of retrievals that—while syntactically plausible—violate crucial algorithmic constraints or validation-tier obligations.
Empirical Evaluation and Results
The evaluation employs a deterministic 200-case RL developer-memory benchmark spanning DQN, PPO, SAC, TD3, A2C, GAE, V-trace, and 40 non-RL developer-memory cases—emphasizing the generality of the developer-memory architecture, not just its capacity as an RL-bug classifier (Figure 2).
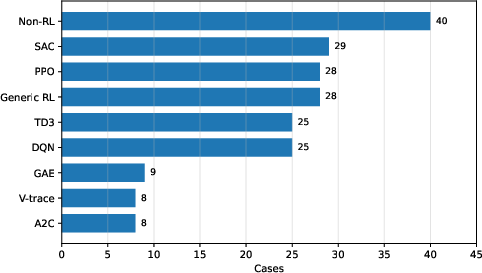
Figure 2: Benchmark composition by algorithm family. The 40 non-RL cases are retained because the system is a developer-memory architecture, not only an RL-bug classifier.
Two evidence layers are separated:
- Same-commit deterministic control vs. full configuration: Both configurations achieve $0.800$ expected-decision accuracy and $1.000$ hard-negative suppression. The full configuration adds contextual-statistics telemetry (with $0.605$ update rate) and OPE instrumentation but does not demonstrate statistically significant accuracy gains (Figure 3).
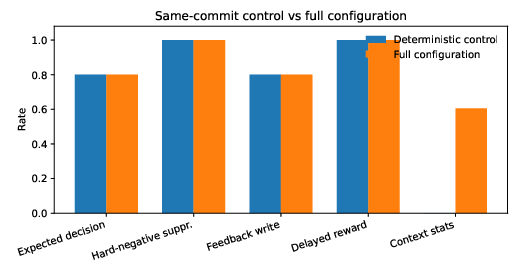
Figure 3: Same-commit deterministic control versus full configuration. Decision metrics are unchanged, while the full configuration writes contextual-statistics telemetry.
- Patch-replay raw delta audit: Favorable but unconfirmed raw improvements in pass rate, hard-negative suppression, and recall-delta metrics are recorded (e.g., offline pass rate increases from 71.5% to 80.0%), but these are not accepted as evidence of method superiority due to lack of controlled ablation (Figure 4).
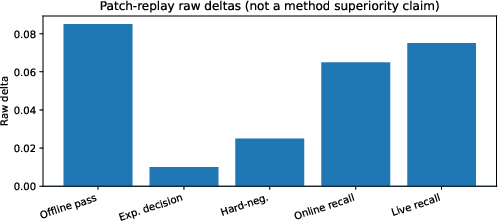
Figure 4: Patch-replay raw deltas. These deltas are retained for engineering transparency but are not treated as controlled ablation evidence.
Latency is the main operational cost: live tool p95 latency increases (from $65.9$ ms to $67.4$ ms for issue-match, total-case p95 increasing from $1$0 ms to $1$1 ms), driven primarily by metrics and reporting overheads rather than memory-matching itself (Figure 5).
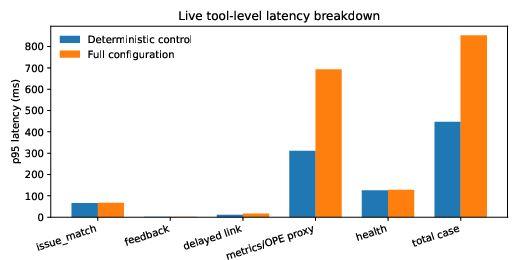
Figure 5: Live tool-level p95 latency. The largest full-configuration increase is in metrics/reporting and total-case time, while issue-match p95 increases modestly.
All 40 residual failures in the revised system are confined to non-RL, low-risk developer-memory families (path handling, alias canonicalization, scope, and command/path mismatches), indicating strong coverage for RL/control cases but incomplete general-purpose developer-memory normalization.
No ablation evidence on static RAG and isolated feedback/delayed-link/theory-metadata variants is available; these are marked as evidence gaps.
Theoretical and Practical Implications
This architecture operationalizes developer memory as a first-class, auditable, and safety-gated decision process, integrating best practices from shadow-bandit learning, OPE, and RL reward normalization. Its design strictly separates memory retrieval from unconstrained policy learning, imposing governance via metadata-enriched matching and review-tiered promotion to curtail unsound propagation of fixes in RL/control pipelines.
Strong claims and results:
- Component-level support: Deterministic matching, feedback normalization, and contextual learning are auditable and functionally realized.
- No statistical evidence for superiority over baselines in accuracy or recall.
- Latency and operational overheads are distinctly measurable and non-negligible.
- Residual errors in non-RL paths highlight current limitations for broader deployment.
Contrasts with prior/related systems:
- Unlike RAG or long-context-only approaches, retrieval utility here is explicitly grounded in delayed developer feedback and can be selectively learned, audited, and governed.
- More stringent than self-corrective or reflexive agents—retrieval influence cannot override code correctness requirements or governance state, and learnable policies remain shadow-gated.
- Exceeds memory-augmented bandits in domain specificity, supporting theory-to-code traceability and reviewable audit trails for RL/control interventions.
Future Directions
Key open challenges highlighted include:
- Robust ablation of static RAG and isolated feedback/delayed-link/theory-metadata contributions.
- Scaling real-developer interaction traces and executing full official-client MCP interoperability testing.
- Targeted expansion of path, scope, and alias normalization to reduce developer memory abstentions in non-RL domains.
- OPE-supported canary deployments for low-risk learned-policy rollouts.
- Direct evaluation of memory-controlled agents on multi-turn, repository-level tasks (e.g., via LoCoBench-Agent [qiu2025locobenchagent]) to establish downstream coding impact beyond component-level diagnostics.
- Further research on memory poisoning and privacy leakage mitigation, given the demonstrated attack surface in persistent code memories [alkaswan2024traces].
Conclusion
RL Developer Memory establishes a rigorous, feedback-normalized, and auditable developer-memory layer for RL coding agents, achieving explicit separation of control between deterministic baseline operation and shadow-learned policy updates. While latency regressions and gaps in non-RL path/alias coverage persist, and no broad coding performance improvements are currently claimed, the work sharply defines the boundaries of evidence and claim in memory-controlled agent design. This architecture forms a foundation for future robust, reviewable memory use in agentic software engineering, particularly in safety- and reproducibility-critical RL pipelines.
Reference:
"Feedback-Normalized Developer Memory for Reinforcement-Learning Coding Agents: A Safety-Gated MCP Architecture" (2605.01567)