- The paper introduces an RL-driven, unified approach that replaces modular steps with a single-agent framework for memory management.
- It employs a synthetic data synthesis pipeline and a memory-based Levenshtein reward to optimize trajectory-level memory updates.
- Empirical results show enhanced semantic fidelity, reduced retrieval redundancy, and state-of-the-art performance on multiple benchmarks.
DeltaMem: End-to-End Agentic Memory Management via Reinforcement Learning
Introduction and Motivation
Persistent persona memory remains a bottleneck for effective long-term interaction in LLM-based agentic systems. Existing paradigms predominantly leverage modular, multi-agent approaches, dividing the memory management task into extraction, retrieval, and update phases, often employing atomic CRUD operations. While straightforward, such modularity enforces lossy message-passing and sharpens the effects of session-level fragmentation, causing contextual dependencies to erode across protracted interactions. Empirical evidence from large-scale multi-agent analyses confirms the fragility and inefficiency of these pipelines.
DeltaMem redefines this space, formulating persona-centric memory management as an end-to-end, single-agent sequence decision process. By subsuming memory extraction and retrieval within a unified reasoning-and-act (ReAct) framework, it eliminates lossy inter-module handoff, supports dynamic context focus, and directly optimizes across full memory trajectories. This agentic stance drastically curtails information loss due to segmentation and enables seamless adaptation across long-horizon, fragmented dialogue streams.
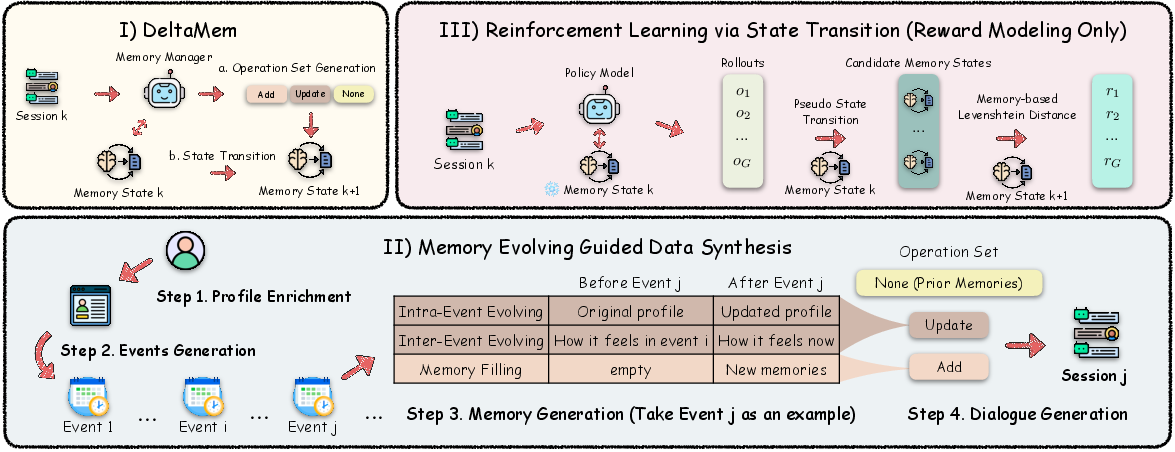
Figure 1: DeltaMem framework: agentic memory state evolution, data-synthesis pipeline for memory updates, and RL-driven reward modeling.
Methodological Contributions
DeltaMem Architecture and Execution
DeltaMem represents the memory bank as a finite mapping from unique IDs to timestamped atomic factual tuples, encapsulating memory state as an explicit function St. Each user session triggers a reasoning-augmented state transition operation f(St,dt+1)→St+1, producing a set of low-level operations (add, update) without reliance on rigid modular boundaries. Retrieval is dynamically invoked only as necessary, leading to substantial reductions in redundant memory queries.
This single-agent formulation allows DeltaMem to optimize for global state utility, eschewing the piecemeal, context-destructive intermediaries characteristic of prior systems.
Memory-Evolving Guided Data Synthesis
DeltaMem's reinforcement learning demands fine-grained, operation-labeled data to support trajectory-level optimization. To address data scarcity and annotation cost, the authors propose a synthetic data generation pipeline inspired by the temporal evolution of human memory. This involves:
- Profile Enrichment: Construction of detailed persona seeds and initial states.
- Chronological Event Generation: Synthesis of temporally-ordered events reflecting diverse memory-affecting domains.
- Memory Operation Generation: For each event, produce labeled add/update/none operations with keywords, reflecting intra- and inter-event evolution.
- Dialogue Synthesis: Grounded conversations paired precisely with corresponding state changes.
This approach enables both precise supervision and robust evaluation, covering a spectrum of memory updates and contextual shifts.
Reinforcement Learning with Memory-based Levenshtein Reward
Classic RL rewards for memory tasks use downstream accuracy or question-answering metrics—signals that are both sparse and loosely coupled to the memory policy itself. DeltaMem circumvents this by introducing a memory-based Levenshtein Distance (MLD) as a semantically grounded, trajectory-level reward:
- Detects and penalizes semantic divergence between predicted and target memory states by optimal matching via OT alignment.
- Incorporates a local lexical fidelity term for fine-grained factual consistency, using per-entry keyword recall.
- Normalizes soft precision and recall for the memory update trajectory and combines them to produce a balanced, strictly memory-anchored F1 reward.
This design tightly couples policy improvement to explicit memory dynamics, supporting efficient RL optimization and robust out-of-distribution generalization.
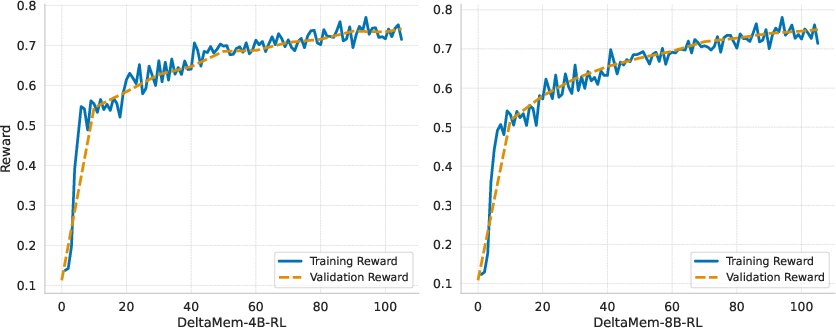
Figure 2: Reward dynamics for DeltaMem RL training, highlighting rapid convergence and high validation stability for both 4B and 8B scales.
Experimental Validation
Benchmarks, Baselines, and Metrics
DeltaMem was extensively evaluated on LoCoMo, HaluMem, and PersonaMem—benchmarks that measure long-range factual consistency, hallucination resistance, and persona-tracking in dynamic, evolving dialogue contexts. Comparisons include training-free multi-agent (Mem0, LightMem, Zep, Memobase, Supermemory) and RL-trained counterparts (Memory-R1).
Principal Results
- LoCoMo: RL-trained DeltaMem-8B-RL achieved state-of-the-art LLM-as-a-Judge score (75.13), outperforming LightMem and Zep by wide margins. The RL phase delivered a tangible 4.1-point gain in semantic fidelity, particularly excelling at reasoning- and temporally-intensive categories.
- HaluMem: DeltaMem-8B-RL outperformed all baselines in extraction and downstream question-answering, achieving 80.65 and 66.43, respectively. Strong updating combined with non-hallucinatory retrieval translates to stable response accuracy as the number of user sessions increases.
- PersonaMem: The RL-trained variant set the top overall score (63.61), showing strongest improvements in novel idea generation and fact recall, directly attributable to tighter memory-state alignment and better handling of evolving preference streams.
DeltaMem reduces mean queries per memory by over 98%, alleviating the heavy retrieval cost seen in modular systems, while improving factual precision.
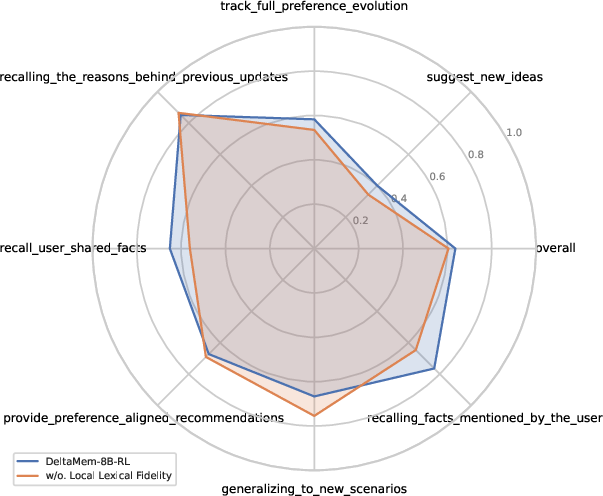
Figure 3: Ablation study on local lexical fidelity: inclusion yields pronounced improvements in fact recall, especially under recall-centric benchmarks.
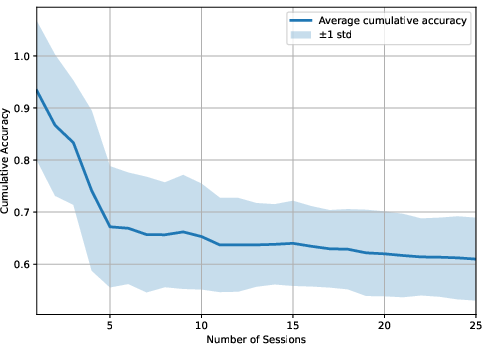
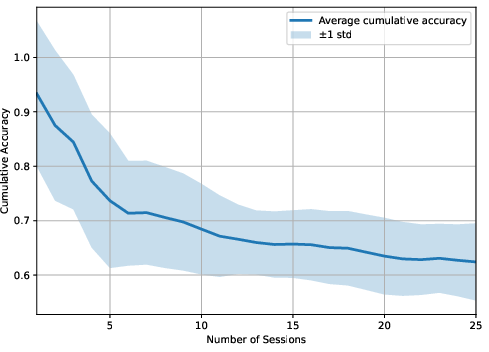
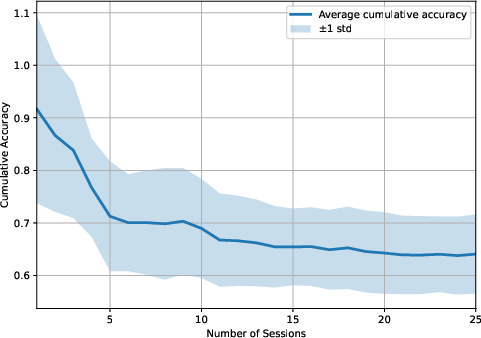
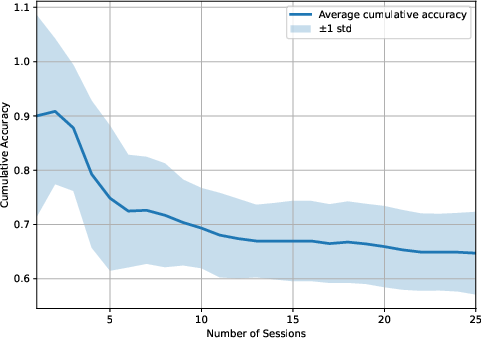
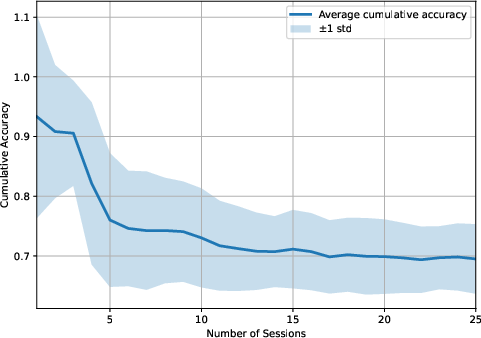
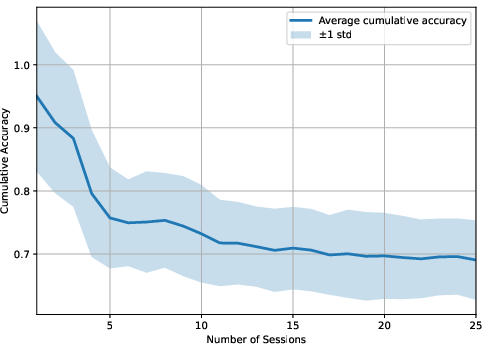
Figure 4: LightMem-4o baseline: highlighted lack of robust updating yields lower temporal accuracy and increased information loss.

Figure 5: Case study: DeltaMem maintains accurate and contextually relevant persona state through sequential, dynamic dialogue sessions.
Theoretical Implications and Design Insights
DeltaMem demonstrates that persona-centric, operation-level RL in a single-agent framework is viable and markedly superior to modular multi-agent architectures, especially in long-horizon, fragmented, high-variance interaction settings. The memory-based Levenshtein reward is a theoretically well-founded, semantically consistent alternative to sparse downstream metrics, yielding demonstrably faster and more robust RL convergence.
Empirically, lexical fidelity and optimal semantic assignment combine to maximize both recall and precision, supporting stable memory evolution and mitigating hallucinations.
Practical Impact and Future Directions
Practically, DeltaMem eliminates the overhead and brittleness of multi-agent systems, achieves better data and compute efficiency, and supports stable, real-world deployment in long-lived personal assistants, recommendation systems, and any agent that must track evolving, user-specific contexts. The framework's robust synthetic data pipeline and memory-grounded rewards decouple training from strictly human-annotated data and allow for controlled, high-quality, and scalable evaluation and improvement cycles.
Future directions include extension to heterogeneous multi-modal memory, adaptive context-length reasoning, further generalization to multi-user scenarios, and integration with privacy-preserving memory systems.
Conclusion
DeltaMem sets a strong precedent for end-to-end, RL-driven persona memory management. By unifying operation synthesis, robust reward modeling, and synthetic trajectory generation—all within a single-agent ReAct framework—it achieves state-of-the-art results across extraction, updating, and personalized response benchmarks, while simultaneously reducing compute and retrieval redundancy. This architecture establishes a new baseline for scalable, agentic, and adaptive memory-augmented AI systems (2604.01560).

