- The paper introduces an integrated memory architecture that combines selective filtering, dual-layer compression, and provenance-enriched graph construction for enhanced conversational recall.
- The framework employs Dynamic Weighted PageRank to achieve query-adaptive subgraph retrieval, significantly improving recall metrics on benchmarks like LongMemEval-s and LOCOMO-10.
- The system is designed for scalability and robustness, supporting incremental updates and transparent provenance tracking for long-term, personalized AI dialogue management.
MemORAI: Adaptive Memory Organization and Retrieval for Long-Horizon LLM Agents
Motivation and Limitations of Existing Conversational Memory Architectures
Despite recent advances in LLM reasoning and generation, effective long-term memory for conversational agents remains a core unsolved problem. Existing approaches—including flat-context memory, vector-based retrieval-augmented generation (RAG), and hierarchical/graph-based systems—exhibit fundamental limitations: coarse-grain session-based aggregation introduces noise; flat turn-level chunking causes context fragmentation; shallow graphs lacking provenance tracking and selective filtering suffer from information dilution, structural bias, and poor recall for user-persona-relevant content. Moreover, uniform edge propagation and post hoc semantic reranking fail to fully resolve relevance misalignment and the loss of factual traceability. Robust, fine-grained and context-adaptive memory retention and query-driven retrieval are not jointly optimized in current frameworks.
MemORAI Framework: Pipeline Overview
MemORAI introduces a principled, fully integrated architecture addressing the above challenges via three compositional innovations: (1) selective memory filtering and dual-layer compression, (2) provenance-enriched heterogeneous knowledge graph construction, and (3) query-adaptive subgraph retrieval with Dynamic Weighted PageRank (DW-PR). The pipeline is visualized in Figure 1.
Figure 1: MemORAI's pipeline: (1) Session segmentation and selective user-relevant utterance compression; (2) Heterogeneous knowledge graph with turn-level provenance; (3) Query-adaptive retrieval and DW-PR ranking for personalized response generation.
Selective Memory Filtering and Topic Segmentation
The first pipeline stage addresses information overload and irrelevant context by segmenting multi-session dialogues into semantically coherent units using prompt-based LLM topic segmentation. A dual-layer memory gate retains only those utterances containing user-persona-relevant content—facts, preferences, goals, commitments—while summarizing discarded generic discourse at the segment level. Both filtered memory units and global segment summaries are preserved for downstream graph extraction. This mechanism significantly reduces storage overhead, denoises the conversational history, and ensures all subsequent processing operates on distilled, high-utility signals.
Ablation results demonstrate removing topic segmentation catastrophically degrades both session- and turn-level recall (up to −67.77 on turn-level metrics for LongMemEval-s); dropping selective filtering reduces recall but with lower impact, indicating that hierarchical structure is paramount for scalable memory [(2605.01386), Table: ablation_segment].
Provenance-Enriched Multi-Relational Graph Construction
From selectively retained memory, MemORAI constructs a heterogeneous knowledge graph encompassing three node types: entities (with description embeddings and provenance), dialogue turns (text, segment and turn indices), and dialogue segments (summaries and segment ids). Edge types encode entity–entity relations (with relation type and source turns for provenance), entity–turn mentions, and turn–segment hierarchy. Knowledge extraction—including factual triplets, descriptions, and linking—is performed by LLMs with strict turn-level citation. Unlike previous graph-based memory (e.g., Mem0g, HippoRAG 2), MemORAI's graph explicitly encodes factual origin at fine granularity, supporting transparent auditing and multi-hop provenance-sensitive retrieval.
Graph complexity analysis reveals that the full pipeline produces a significantly more compact and less noisy structure than ablation variants, resulting in improved retrieval efficiency and less spurious connectivity.
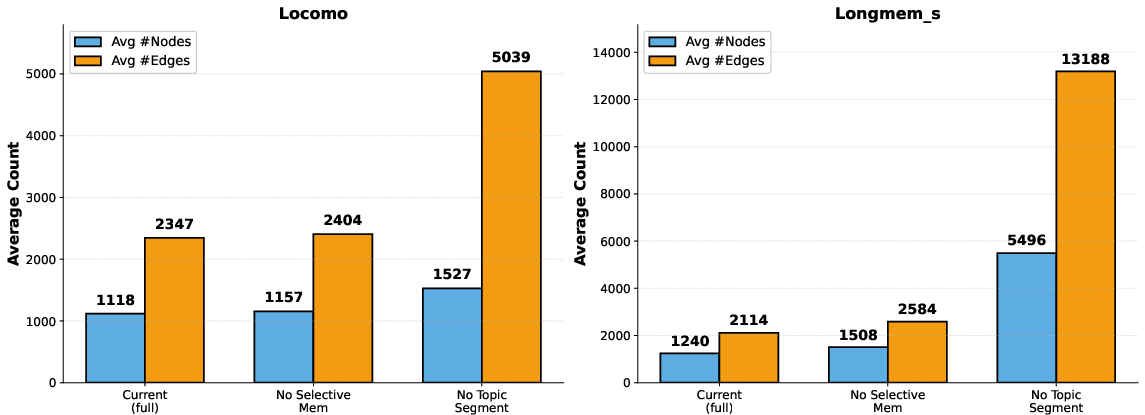
Figure 2: Ablation variants without topic segmentation or selective filtering yield substantially denser and less informative graph structures.
Upon receiving a query, MemORAI restricts attention to a sparse, query-focused subgraph seeded using multi-aspect dense retrieval (summary, entity, and relation triplet embeddings). This avoids ranking the entire memory graph, suppresses irrelevant nodes, and ensures focus on the semantically salient region. Over the subgraph, MemORAI departs from uniform Personalized PageRank (as in HippoRAG 2). Instead, DW-PR modulates edge scores with query-conditioned semantic relevance: propagation at each step is weighted by contextual similarity between the query and node (entity, relation, or summary) embeddings. This biases ranking toward nodes that have high semantic alignment with the query independent of raw node degree, ameliorating the “hub node” structural bias of previous methods.
Compared to traditional approaches, DW-PR yields consistent, stable improvements: on LongMemEval-s, turn-level Recall@10 increases from 89.75 to 91.63; on LOCOMO-10, from 62.01 to 64.68 ((2605.01386), Table: ablation_weight).
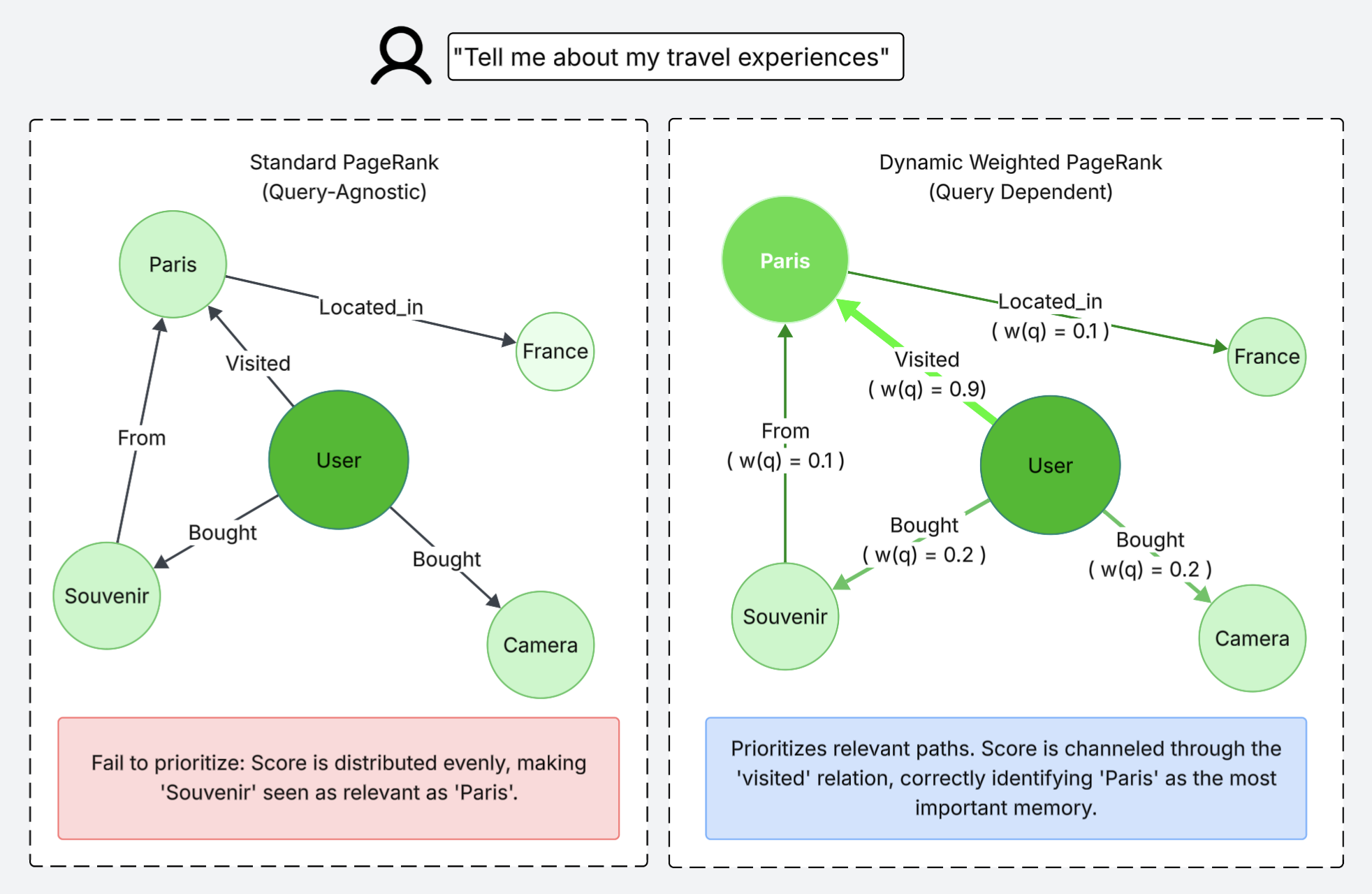
Figure 3: Visual comparison of uniform versus dynamic edge-weighted PageRank: query-conditioned propagation enables relevance-sensitive ranking, overcoming degree bias.
End-to-End Evaluation
Evaluations on LongMemEval-s and LOCOMO-10 utilize controlled conditions—Contriever-based embeddings, openai/gpt-oss-20b LLM for all modules—to isolate architectural effects. Compared to methods spanning dense retrieval (MPNet, Contriever, BGE-M3), dialogue summarization (LLM-RSum), memory-centric filtering (MPC, SeCom, MemGAS), and graph-structured RAG (HippoRAG 2, Mem0g, RAPTOR), MemORAI achieves substantial improvements across all standard metrics.
- On LongMemEval-s: MemORAI delivers 75.55% GPT-4o-J accuracy (+15.35 over previous best), F1 of 45.99, and BERTScore of 90.37. Turn-level Recall@3 and @10 reach 71.13 and 91.63, surpassing all baselines including those using stronger embeddings (e.g., BGE-M3).
- On LOCOMO-10: The pipeline achieves 60.22% GPT-4o-J, 56.71 F1, Recall@3/10 of 42.63/64.68 at the turn level—gains exceeding +12.91 in Recall@10 versus full-graph traversal, and +8.45 in judge accuracy from triplet-enriched response generation.
Ablation confirms:
- Topic segmentation is central for managing history scale.
- Query-bounded subgraph retrieval increases recall and reduces latency by up to 4 ms.
- Triplet enrichment yields dramatic BLEU improvements (e.g., 13.58→33.00 on LOCOMO-10).
Robustness, Scalability, and Cost
MemORAI's improvements are robust across LLM backbones (Qwen3-8B, GPT-OSS-20B, Qwen3-30B-A3B); retrieval and generation scores increase monotonically with model scale and context capacity. Structured extraction errors are rare (≤3.7%), outperforming alternatives (>70% error in A-Mem). While the indexing phase incurs higher offline token cost, the system maintains inference efficiency comparable to baseline graph RAG and supports fully incremental, non-reconstructive updates for lifelong operation—even as history grows unboundedly.
Theoretical and Practical Implications
MemORAI demonstrates that scalable, auditable, and high-precision conversational memory is possible when selective, user-centric retention is jointly optimized with heterogeneous, provenance-rich representation and query-adaptive cascade retrieval. Practically, the design supports continual, real-world deployment for assistant agents managing months-long user interactions, and the design space enables distillation into small models for more accessible compute environments ((2605.01386), Limitations).
Theoretically, the results highlight the necessity of simultaneous optimization over memory granularity, semantic provenance, and query-adaptive retrieval to close the gap between fact-recall and personalized generation. As benchmarks evolve to include more dynamic, ambiguous, or multi-participant settings, future extensions may require adaptive entity linking, lifelong knowledge base merging, and hybrid external-knowledge fusion—research avenues opened by the modular graph and pipeline design established here.
Conclusion
MemORAI advances the state-of-the-art in long-horizon conversational memory by unifying selective filtering, heterogeneous provenance-aware graph construction, and dynamic query-adaptive ranking. Across tasks and metrics, it outperforms both embedding-heavy and prior structured RAG baselines, establishing that fine-grained, context-sensitive memory retrieval is essential for the next generation of persistent, reliable LLM agents.