- The paper presents SGMem, a novel framework that segments dialogue into sentences and constructs a graph for precise memory management.
- It utilizes Sentence-BERT embeddings and a multi-hop retrieval strategy to effectively index and access dialogue segments, outperforming traditional methods on benchmarks.
- The framework is lightweight and scalable, mitigating memory fragmentation and enabling coherent, context-aware responses in real-time multi-turn conversations.
SGMem: Sentence Graph Memory for Long-Term Conversational Agents
This paper, titled "SGMem: Sentence Graph Memory for Long-Term Conversational Agents," introduces a memory management framework specifically designed to address the challenges faced by long-term conversational agents. The proposed framework, Sentence Graph Memory (SGMem), organizes dialogue at the sentence level to effectively manage and retrieve memory across multi-turn conversations.
Introduction
Long-term conversational agents often grapple with the challenge of memory overload, as the dialogue history accumulates beyond the context window size of LLMs. Existing memory management methods focus on reducing redundancy through summarization or fact extraction but often fail to organize or retrieve information in a coherent manner across different dialogue granularities. SGMem addresses these limitations by representing dialogue as sentence-level graphs, enabling more precise retrieval of relevant memory segments.
Methodology
SGMem consists of two primary components: SGMem Construction {content} Management and SGMem Usage.
- SGMem Construction {content} Management: This component involves segmenting dialogue into sentences and constructing a memory graph with sentences as nodes. Sentence vectors are indexed using embeddings from models like Sentence-BERT. Edges in the graph are defined based on sentence similarity and chunk membership, allowing for efficient retrieval.
- SGMem Usage: In this phase, memory and sentences relevant to the input query are retrieved from the indexed graph. A multi-hop retrieval strategy refines the selection of memory chunks, integrating sentence-level context with generated memory (i.e., summaries, facts, insights). This enriches the response generation process by providing a coherent dialogue history.
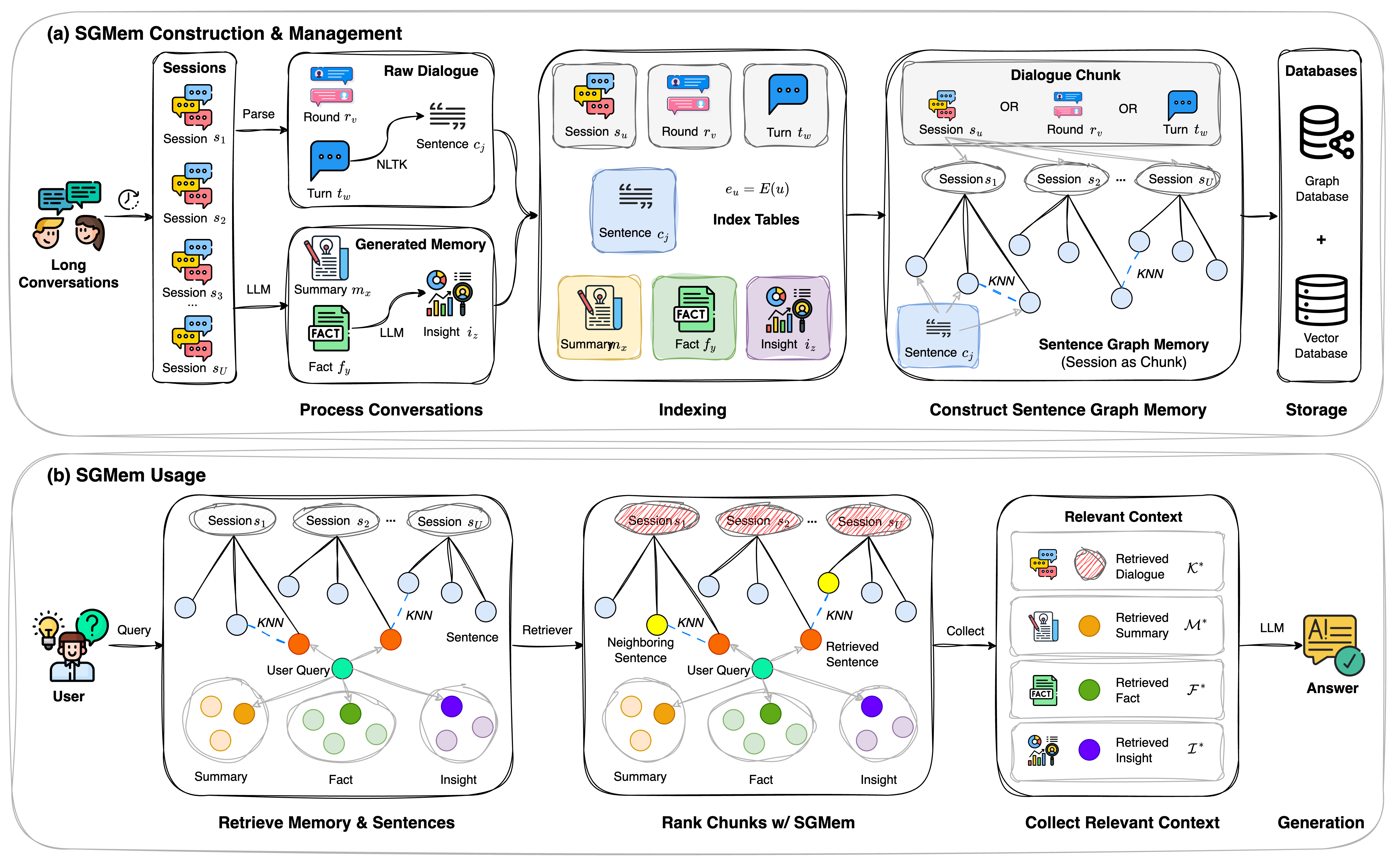
Figure 1: Overview of the proposed Sentence Graph Memory (SGMem) framework, consisting of (a) SGMem Construction {content} Management for building sentence-level memory graphs and (b) SGMem Usage for retrieving relevant memory in long-term conversational QA.
Experimental Results
SGMem was evaluated on LongMemEval and LoCoMo datasets, specifically designed to benchmark long-term conversational agents. The SGMem variants consistently outperformed existing RAG implementations and memory management methods across diverse query types.
In particular, SGMem achieved superior accuracy in multi-session and temporally dynamic settings, demonstrating its capacity to mitigate memory fragmentation and enhance retrieval efficacy.
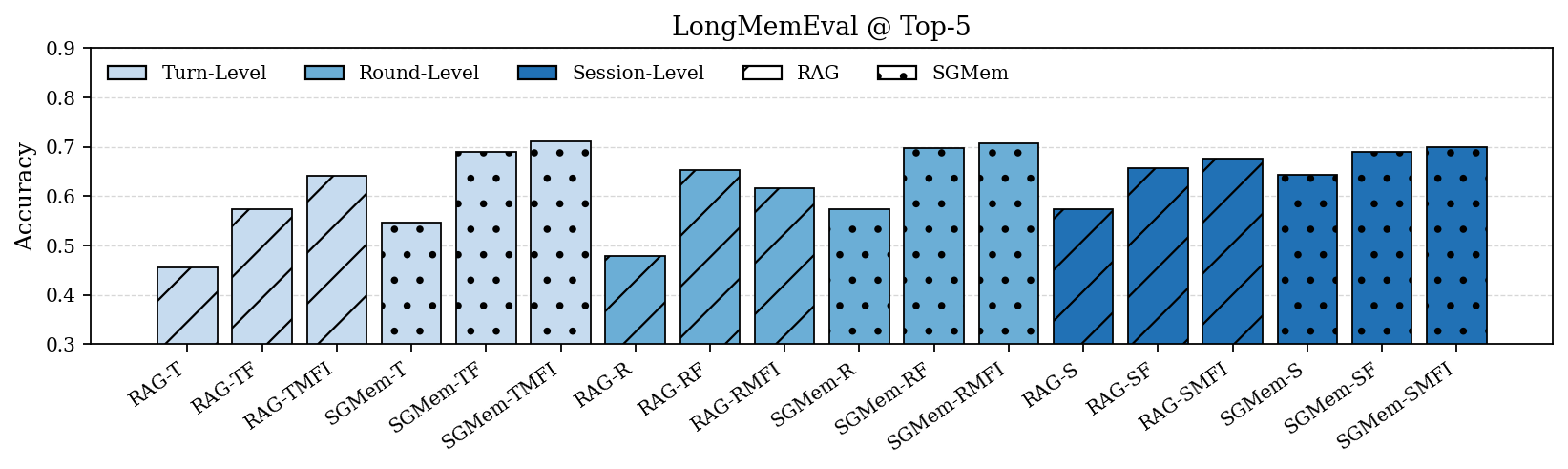
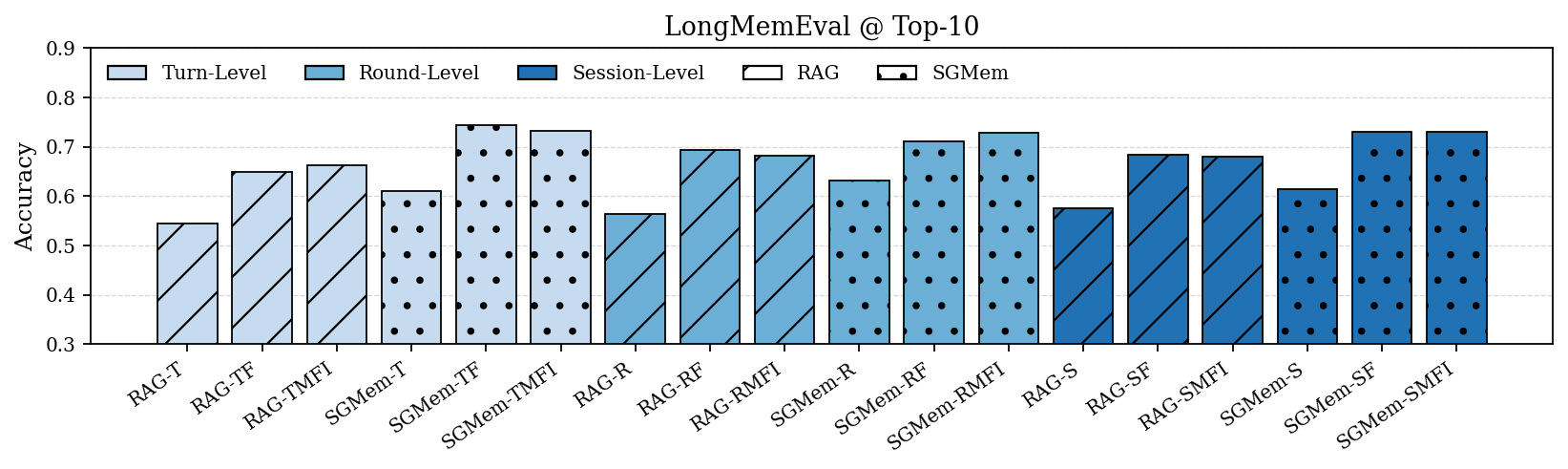
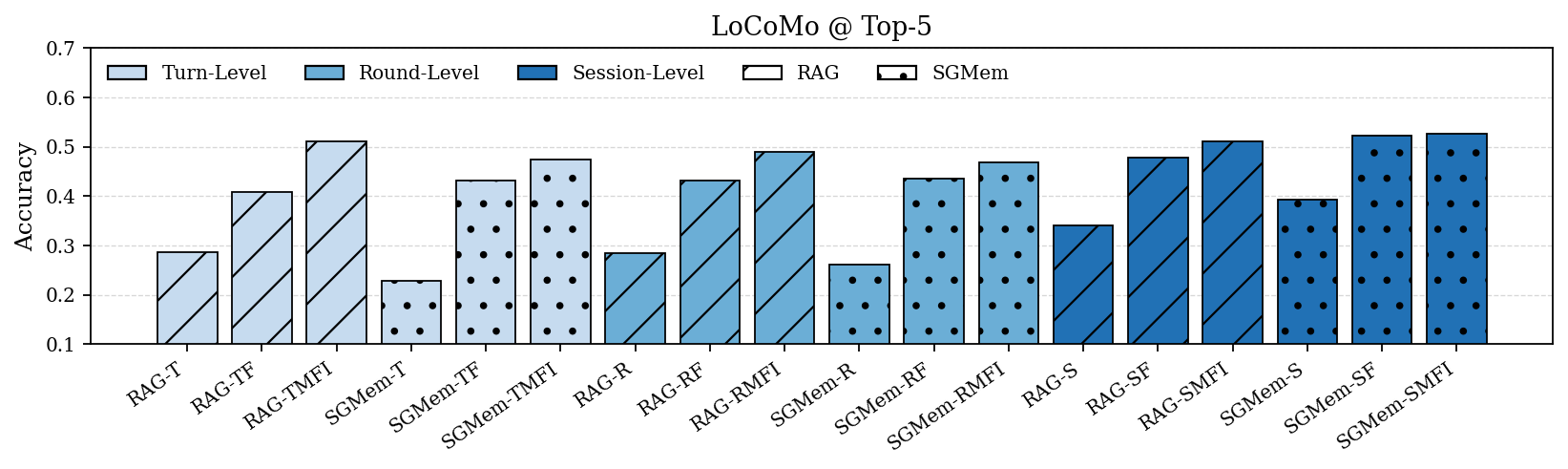
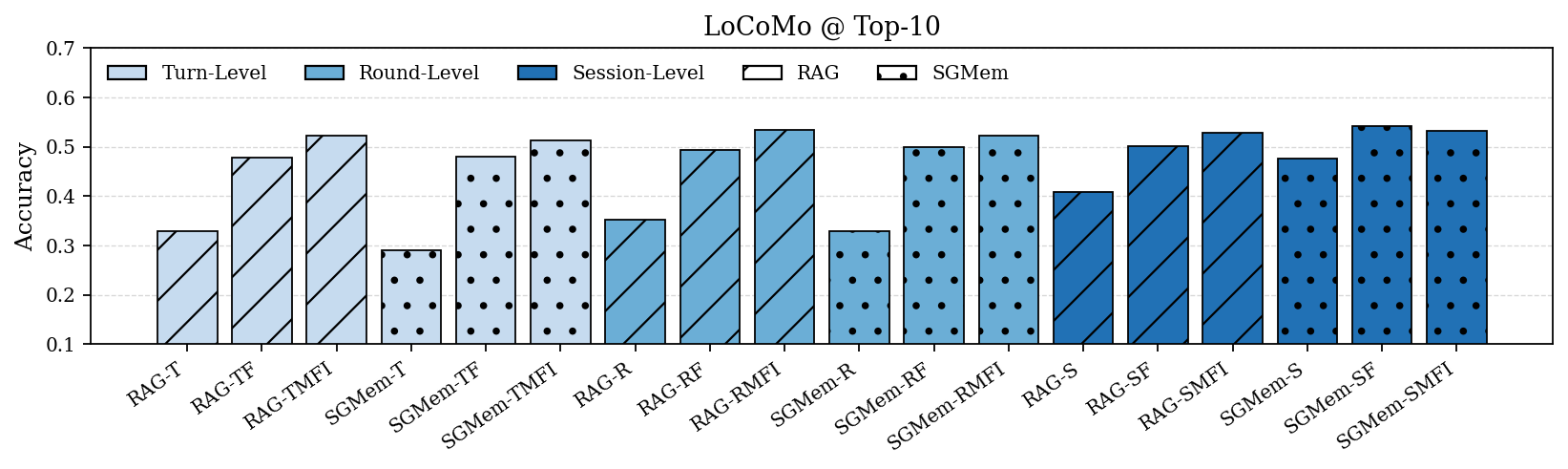
Figure 2: Performance comparison of RAG and SGMem variants on LongMemEval and LoCoMo under Top-5 and Top-10 settings. Turn-, round-, and session-level denote raw dialogue units; M, F, I denote summary, fact, and insight, respectively.
Discussion
The SGMem framework offers several advantages over traditional methods by maintaining a detailed and fine-grained memory representation. The granularity allows for more accurate information retrieval and subsequently more accurate and contextually appropriate responses from conversational agents. One key benefit of SGMem is that it does not require complex LLM-based extractions, making it lightweight and scalable for real-time deployment.
Conclusion
SGMem represents a significant advancement in memory management for long-term conversational agents. By adopting a sentence-level graph-based approach, SGMem overcomes issues of memory fragmentation and aligns raw dialogue history with generated memory to provide coherent conversational context. The improvements observed across various query types underline the practical value of this framework in enhancing conversational agents' accuracy and coherence. Further work could involve optimizing graph construction and exploring broader memory types for more complex conversational scenarios.
In summary, SGMem introduces a practical and efficient strategy for organizing and utilizing conversational memory, with promising implications for the future design of intelligent conversational systems.