- The paper introduces PAD, a pose-aware diffusion model that generates 3D objects directly in the observation space, bypassing canonical coordinate transformations.
- The method leverages latent geometric conditioning from monocular depth estimates to enforce strict spatial alignment and preserve fine-grained details.
- Empirical results demonstrate that PAD outperforms state-of-the-art baselines on metrics like Chamfer distance, F-score, and bounding box IoU in single-object and scene generation.
Pose-Aware Diffusion (PAD): End-to-End 3D Generation in Observation Space
Single-image 3D asset generation is central for downstream domains including VR, simulation, and graphics. However, existing feed-forward and diffusion-based 3D generative models typically synthesize objects in normalized canonical coordinate spaces, necessitating post-hoc pose estimation or optimization for spatial alignment. This canonical-then-rotate paradigm introduces fundamental limitations: spatial misalignments from decoupled geometry and pose, ambiguity—especially for symmetric objects—and loss of fine-grained details due to lack of direct spatial correspondence with the input image.
PAD addresses these challenges by fundamentally rethinking 3D shape generation: the framework abandons the canonical-space assumption and synthesizes geometry natively within the observation space defined by the input image. The key insight is to leverage partial 3D geometric information, unprojected from monocular depth predictions, as an explicit anchor to enforce strict pose correspondence during generative modeling. The PAD methodology thus resolves transformation ambiguities and enables direct, pose-aware synthesis without post-alignment.
Methodology
PAD builds on a DiT-based flow matching diffusion backbone, initialized from the large-scale Hunyuan3D-2.1. To bridge from canonical training to observation-space modeling, PAD introduces a compact latent geometric conditioning mechanism: monocular depth is estimated from the input image and unprojected to a partial point cloud, which is then encoded by a permutation-invariant vecset VAE into a geometric latent. This latent is concatenated to the diffusion tokens, establishing a robust, spatially consistent constraint that enforces geometric generation in the camera coordinate system.
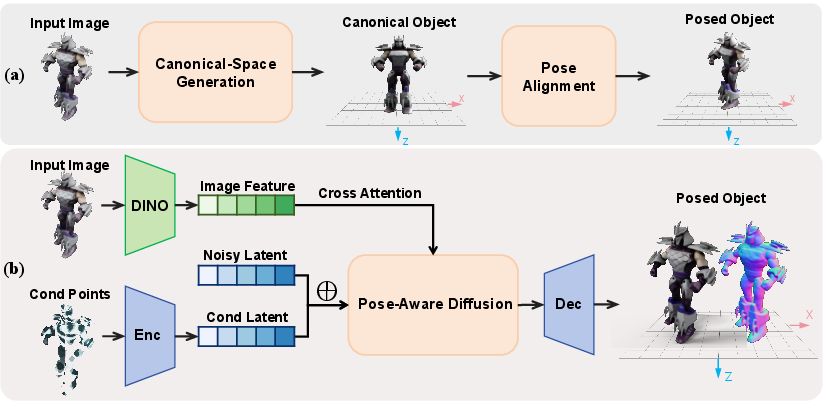
Figure 1: PAD generates pose-aligned geometry in the observation space by conditioning on encoded partial point clouds, in contrast to the canonical-then-rotate baselines.
To enhance generalization and robustness, the training pipeline corrupts the geometric condition with both genuine depth estimator noise and synthetic perturbations (depth noise augmentation). This breaks over-reliance on perfect partial geometry (which would constitute trivial autoencoding) and forces the model to learn to hallucinate occluded and unobserved regions robustly. PAD's training protocol is staged: single-object learning with curated, watertight samples (from Objaverse and 3D-Front), then progressive incorporation of occlusions and complex compositional layouts to handle scene-level object decomposition and geometric ambiguity.
The observation-space generative paradigm directly generalizes to compositional 3D scene generation. The scene is segmented, and for each object, a localized partial point cloud and corresponding image crop are extracted. PAD then synthesizes watertight assets in global pose, and the final scene is assembled by a straightforward union, eliminating multi-view optimization and manual pose alignment.
Empirical Results
Extensive evaluation demonstrates that PAD sets a new quantitative and qualitative standard for both single-object pose-aligned mesh generation and compositional 3D scene generation.
PAD outperforms state-of-the-art baselines (DreamGaussian, InstantMesh, MIDI, SceneGen, SAM-3D, ShapeR) by significant margins on Chamfer distance, F-score, bounding box IoU, and semantic similarity metrics (Uni3D, ULIP). For single-object tasks, PAD achieves a Chamfer distance of 48.76×10−3, F-Score of 0.204, and bounding box IoU of 0.863, consistently surpassing all competitors.

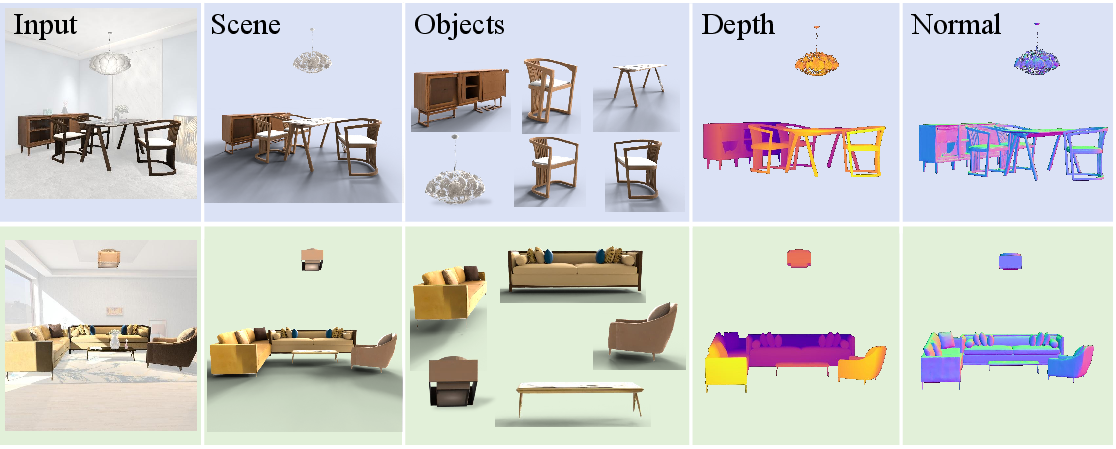
Figure 2: PAD preserves high-fidelity geometric details and strict spatial alignment across diverse object categories—from a single image input.
Qualitative assessments show robust preservation of intricate shape details and exact input pose, while canonical/rotate-based baselines frequently yield misalignments, structural artifacts, or loss of detail.
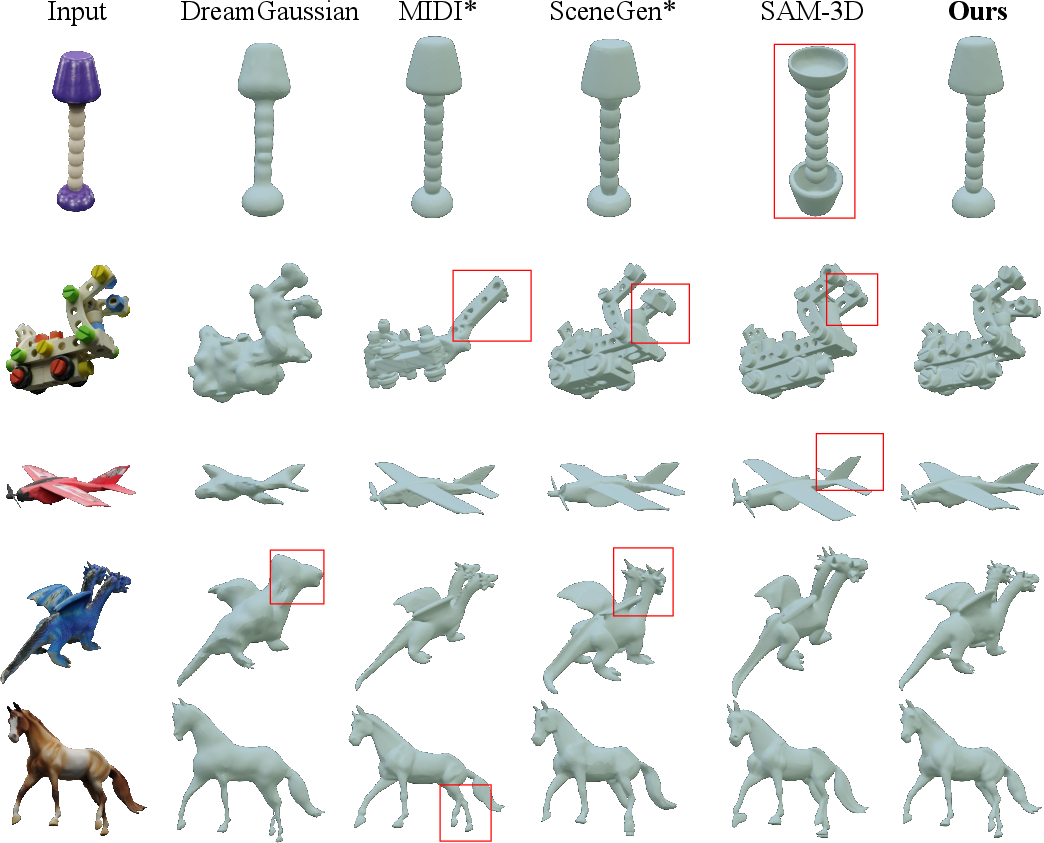
Figure 3: On single-image pose-aligned object generation, PAD delivers geometrically and semantically faithful meshes. Red boxes highlight misalignments in baselines.
In compositional scene synthesis (evaluated on 3D-FUTURE scenes), PAD maintains precise relative layout and scale fidelity, outperforming scene-level diffusion baselines, which often suffer floating, overlapping, or poorly aligned assets.
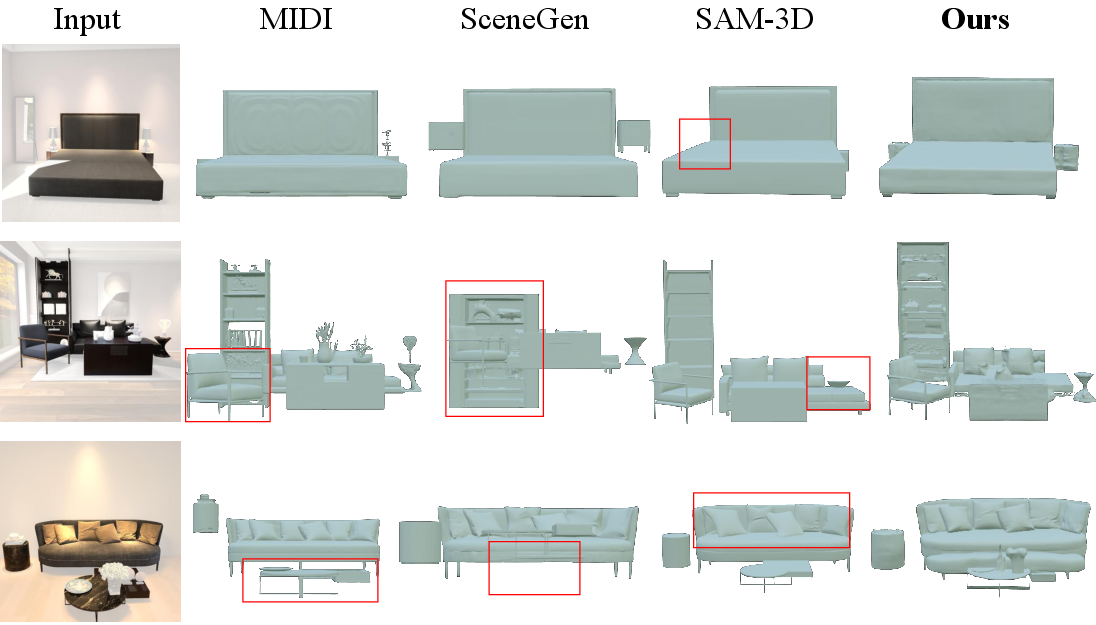
Figure 4: PAD reconstructs complex multi-object scenes with spatially coherent compositional layouts and superior structure compared to baselines.
Ablation demonstrates that 3D latent conditioning is critical: removing point conditioning or substituting with 2D depth maps significantly degrades both alignment and fidelity. Depth noise augmentation is essential for robust inference under real-world depth estimation imperfections.
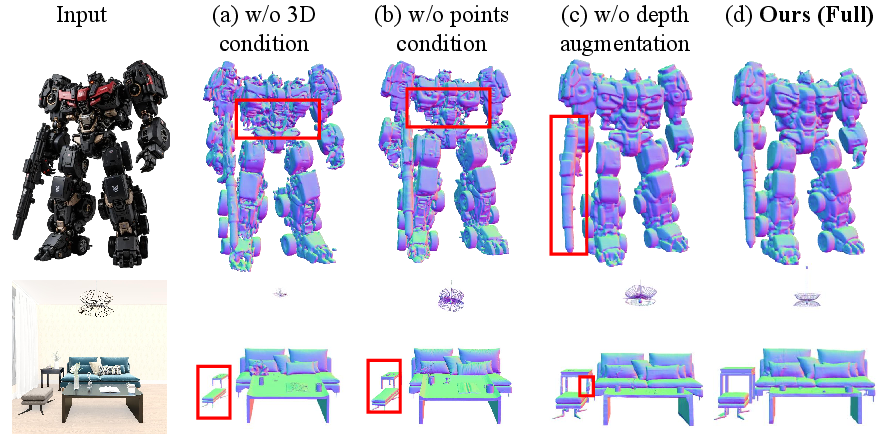
Figure 5: Component ablation confirms PAD's architectural choices: both 3D geometric conditioning and depth noise augmentation are crucial for spatial alignment and artifact-free generation.
Theoretical and Practical Implications
PAD's direct observation-space synthesis constitutes a crucial advance in closing the gap between learned generative priors and practical requirements for scene composition. The method provides a unified, scalable solution—handling both single-object and multi-object 3D reconstruction seamlessly from monocular imagery. The explicit geometric conditioning paradigm is both theoretically sound and empirically robust, supporting end-to-end differentiable reconstruction pipelines readily deployable for VR content creation, robotic perception, or physical simulation.
Notably, PAD contrasts with iterative inpainting or video-based approaches that accumulate spatial drift or require complex pose optimization post-generation. By anchoring generation at the earliest stage and eschewing canonical transformations, PAD eliminates the compounded ambiguities prevalent in prior pipelines.
Limitations and Outlook
PAD's spatial fidelity is fundamentally tethered to the accuracy of monocular depth estimation and input masks—therefore, errors in upstream estimation propagate into mesh reconstruction. While depth noise augmentation substantially mitigates this effect, resolving the ill-posed nature of occluded or ambiguous input views remains a challenge, particularly in heavily cluttered or textureless environments.
Future directions include integrating more sophisticated uncertainty modeling for the geometric prior, leveraging multi-view observations at inference, or incorporating explicit reasoning about unobserved geometry under strong priors. Furthermore, systematic advances in monocular depth estimation and object segmentation will directly translate into further improvements in PAD-based pipelines.
Conclusion
PAD establishes a scalable, robust method for single-image, pose-aligned 3D asset and scene generation by discarding canonical assumptions and anchoring generation inside the observation space. The direct latent geometric conditioning paradigm delivers strong numerical accuracy, superior qualitative fidelity, and seamless scalability to complex scene composition. PAD's framework sets a new state-of-the-art for practical 3D generation, offering a highly promising basis for future research in controllable, spatially-grounded asset creation.

Figure 6: Additional qualitative samples: PAD generates diverse, high-fidelity objects in correct pose from single images.

Figure 7: Additional multi-object scene generations, illustrating PAD's compositional layout consistency and geometry quality.