- The paper introduces 3D-Fixer, an in-place completion framework that recovers full 3D assets from a single image without explicit pose alignment.
- It employs a progressive coarse-to-fine strategy and dual-branch conditioning to refine object geometry and texture while effectively addressing occlusion challenges.
- Experimental results using the ARSG-110K dataset demonstrate significant improvements in geometric accuracy and scene coherence over prior methods.
3D-Fixer: Coarse-to-Fine In-place Completion for 3D Scenes from a Single Image
Introduction
The paper presents "3D-Fixer" (2604.04406), a compositional 3D scene generation framework designed to recover complete 3D assets from a single RGB image using an in-place completion paradigm. The method addresses the limitations of previous approaches in single-view 3D scene reconstruction, which are typically either fast but poorly generalizing or robust but inefficient due to optimization bottlenecks. 3D-Fixer combines the strengths of pre-trained object-level generative priors and geometric foundation models by employing progressive completion, a dual-branch conditioning network, and occlusion-robust feature alignment. Furthermore, the authors introduce ARSG-110K, a procedurally generated dataset comprising 110K scenes and 3M annotated images, to support large-scale training for compositional scene synthesis.
Methodology
In-place Completion Paradigm
Traditional divide-and-conquer approaches perform per-instance 3D generation and subsequent pose alignment, producing accumulated errors and inefficiency, especially in occluded scenes. 3D-Fixer circumvents explicit pose alignment by leveraging the output of geometry estimation methods (fragmented instance-level point clouds) as spatial anchors. Each partial asset is completed in situ, directly within the estimated scene layout.
The in-place completion workflow (Figure 1):
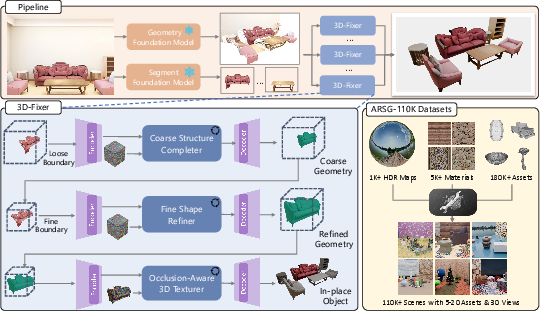
Figure 1: Overall architecture of the 3D-Fixer pipeline: scene decomposition extracts instance-level partial geometry; progressive completion (coarse-to-fine) generates complete and textured assets using instance-wise spatial anchors; ARSG-110K provides large-scale training data.
The pipeline decomposes an image into instance masks and partial geometry, then applies a progressive completion module to reconstruct complete assets conditioned on the fragmented geometry and global scene cues.
Progressive Coarse-to-Fine Generation
3D-Fixer employs a three-stage completion strategy:
- Coarse Structure Completion: Given fragmented geometry extracted from geometric estimation models (e.g., MoGe v2, VGGT), the method expands the visible bounding box to a conservative estimate that encloses the plausible ground-truth asset. Within this space, it hallucinates the overall topology, reducing boundary ambiguity from occlusion.
- Fine Shape Refinement: With a predicted object boundary, a higher-resolution representation is synthesized to sharpen geometry and recover subtle details.
- Occlusion-Aware 3D Texturing: Textures are rendered via contextually-aligned features projected from the input image, conditioned both globally and locally to resolve occlusion artifacts.
This progressive, decoupled approach enhances both structural fidelity of each asset and global scene consistency. The dual-branch framework—one for scene-level context and one for object-level priors—enables effective fusion of global and local cues.
Dual-Branch Contextual Conditioning and ORFA
The network uses a dual-branch conditioning scheme that explicitly injects both instance-specific geometry (visible fragmented point clouds) and global scene context (high-res image features projected onto the 3D surface). The geometry-aware feature projection (GAFP) enables precise spatial correspondence between image features and 3D locations for robust inpainting and texturing.
To address the one-to-many mapping ambiguity caused by severe occlusion, 3D-Fixer introduces an Occlusion-Robust Feature Alignment (ORFA) strategy. ORFA leverages layer-wise alignment loss against a frozen teacher (the base object-level prior, TRELLIS) to regularize the model, maintaining plausible asset synthesis under ambiguous conditions.
Large-Scale Training Dataset: ARSG-110K
ARSG-110K, the new dataset, comprises 110K procedurally generated scenes, each containing 5–20 assets sampled from a repository of over 180K 3D models, diversified materials, and HDR environmental maps. Each scene is rendered from 30 random viewpoints with dense annotations: camera, instance masks, and 6DoF-aligned ground-truth geometry. The dataset's scale and fidelity unlock robust supervised learning for open-set, complex scene reconstruction.
Experimental Results
Quantitative and qualitative experiments demonstrate that 3D-Fixer achieves superior performance across synthetic and real-world benchmarks versus prior art including MIDI, Gen3DSR, and per-instance optimization methods. The method exceeds baselines in geometric accuracy (Chamfer Distance, F-score) and layout alignment (IoU), while maintaining feed-forward inference efficiency.
Notable results:
- On the MIDI testset, 3D-Fixer achieves a scene-level F-score of 78.67 and object-level F-score of 94.39, outperforming MIDI (scene: 50.19, object: 53.58) and Gen3DSR (scene: 40.07, object: 38.11).
- On real-world ScanNet scenes, it yields the lowest Chamfer Distance (0.130) and highest F-score (61.58), illustrating strong generalization to complex domains.
Visual comparisons confirm superior fidelity and alignment (Figure 2):
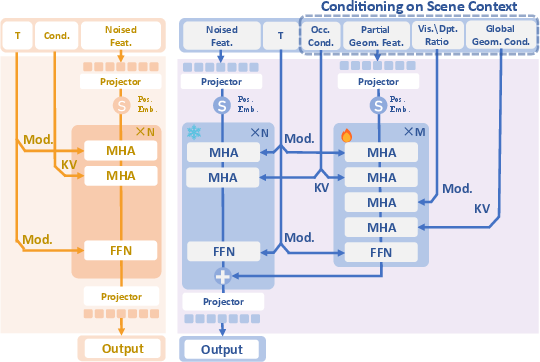
Figure 2: 3D-Fixer extends the diffusion transformer with dual-branch conditioning for robust alignment between occluded scene context and object generative priors.
3D-Fixer consistently produces scene-coherent, high-quality asset geometry and texture, accurately recovering object arrangement and inter-instance relationships, unlike MIDI (which struggles with complex compositions) and Gen3DSR (which yields blurred or misaligned assets).
Ablation studies validate the necessity of coarse-to-fine progressive completion, alignment loss, and contextual feature conditioning. Removing any of these components degrades geometric completeness and overall scene accuracy.
Discussion and Broader Implications
3D-Fixer demonstrates the efficacy of fusing geometric estimation with generative diffusion priors for compositional 3D scene generation. The in-place completion paradigm, free from explicit pose alignment, scales robustly to complex real-world layouts with severe occlusion. Methodological advances—coarse-to-fine progression, context-aware feature fusion, and regularization via ORFA—collectively mitigate layout ambiguity and enhance domain generalization.
Practically, this framework enables efficient, high-fidelity 3D scene synthesis from single images, paving the way for applications in AR/VR, robotics, and digital twin generation where only sparse supervision (e.g., one photo) is available. The ARSG-110K dataset sets a new benchmark for data-driven 3D scene generation research, potentially catalyzing further development of unified scene understanding and generation frameworks.
Theoretically, the success of dual-branch conditioning and in-place completion underscores the importance of spatial anchoring and fine-grained local-global context integration for robust visual reasoning. Tackling the remaining dependence on geometry estimation quality—especially in extreme occlusion scenarios—suggests that joint, unified models for geometry estimation and generative completion may be an important future direction.
Conclusion
3D-Fixer (2604.04406) introduces a unified in-place completion paradigm that transfers object-level 3D diffusion priors to the scene generation setting, anchored by geometry estimation and enhanced by context-aware conditioning. Comprehensive experiments validate its state-of-the-art performance and generalizability. The publicly released ARSG-110K dataset constitutes a substantial contribution, facilitating future research on single-image 3D scene generation. The methodology establishes a blueprint for scalable, robust, and high-fidelity indoor and outdoor 3D asset synthesis from monocular input.

