- The paper introduces a unified two-stage framework that integrates feed-forward geometric anchoring with 3D diffusion generation to enhance reconstruction fidelity.
- The architecture employs branch-repurposing canonicalization and latent-augmented conditioning to ensure precise alignment and detailed mesh completion.
- Evaluations on multiple benchmarks show improved camera pose, depth estimation, and mesh quality over state-of-the-art methods.
UniRecGen: Unifying Multi-View 3D Reconstruction and Generation
Introduction
The challenge of high-fidelity 3D object modeling from sparse, unposed multi-view observations remains fundamental in computer vision and graphics, particularly balancing reconstruction fidelity against the ability to synthesize plausible and complete geometric structures. Contemporary approaches have traditionally bifurcated into feed-forward reconstruction systems—which offer input alignment but struggle with missing regions and global priors—and stochastic generative paradigms, such as diffusion models, which excel at producing detailed and diverse shapes but lack view consistency and fine alignment to real observations. "UniRecGen: Unifying Multi-View 3D Reconstruction and Generation" (2604.01479) presents a cohesive architecture that reconciles these paradigms, leveraging their complementary strengths through a modular, canonical-space unification. UniRecGen simultaneously addresses the disparate learning dynamics and coordinate incompatibilities that have previously hindered joint training and deployment of reconstruction and generation modules, yielding a system that sets new standards for sparse-view 3D shape modeling fidelity, generalization, and consistency.
Architecture Overview
UniRecGen’s core system adopts a two-stage modular pipeline. The first module is a feed-forward multi-view geometric predictor, adapted using a branch-repurposing strategy to provide explicit geometric "anchors" in a canonical, object-centric coordinate frame. This ensures its outputs align not only structurally but also semantically with a downstream 3D generator. Canonicalization is critical—without it, the inherent misalignments between scene-centric reconstructors and object-centric generators lead to propagation of geometric inconsistencies.
After canonicalization, the second stage is a controllable 3D diffusion-based generator, conditioned directly on the canonicalized point cloud, dense multi-view image features, and latent geometric features. The generator’s design enables comprehensive context integration, leveraging both explicit geometry and dense semantic priors to produce high-fidelity meshes faithful to visible evidence while plausibly completing occluded or unseen regions. The pipeline achieves modular extensibility, interpretability, and robust convergence by decoupling the (deterministic) geometric anchoring from the (stochastic) generative refinement.
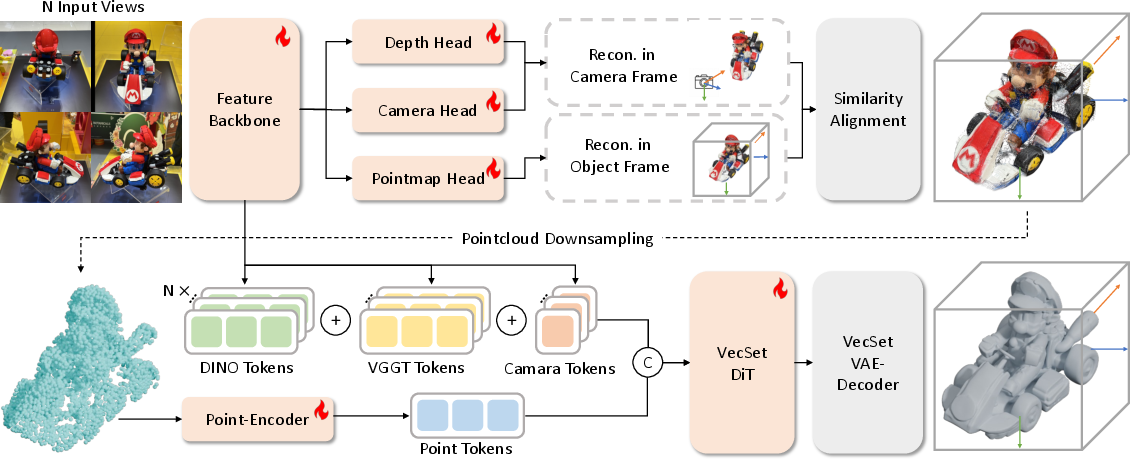
Figure 1: Overview of the UniRecGen pipeline. Stage 1 canonicalizes multi-view geometry into a point cloud; Stage 2 uses this as conditional input for high-fidelity 3D generation.
Canonicalization and Cooperative Learning
A central design innovation is the branch-repurposing canonicalization, in which the feed-forward 3D backbone (VGGT) produces per-view geometry and camera poses in the observed reference frame, but repurposes the point-map head to directly regress object instance geometry in the canonical frame. This is augmented by a robust similarity alignment (Procrustes analysis) to reconcile depth predictions for improved completeness and surface adaptation.
Three canonicalization strategies are compared: direct supervision on the canonical frame, explicit transformation regression, and branch repurposing. Comprehensive evaluation demonstrates that branch repurposing achieves a superior balance—preserving prior statistical regularities of the geometric backbone and enabling dense, gradient-rich adaptation for canonical shape prediction, resulting in strong accuracy for both camera alignment and surface reconstruction.

Figure 2: Qualitative comparison of canonical alignment; branch repurposing produces higher geometric quality and superior canonical alignment.
Multi-View Conditioning for Generative Refinement
The 3D generator ("Hunyuan3D-Omni") requires rich, controllable conditioning to accurately complete partial reconstructions. UniRecGen explores two multi-view conditioning paradigms: point-guided feature sampling and latent-augmented view conditioning. While the former sparsifies attention by linking multi-view DINO tokens only via anchor points, latent-augmented conditioning directly enriches the dense DINO tokens per view with geometric context via learnable projections of geometric and camera latents.
Empirical ablations confirm latent-augmented conditioning as optimal: it preserves full spatial context and endows the generator with global, multi-scale geometric coherence, mitigating view inconsistency and enabling superior mesh fidelity.
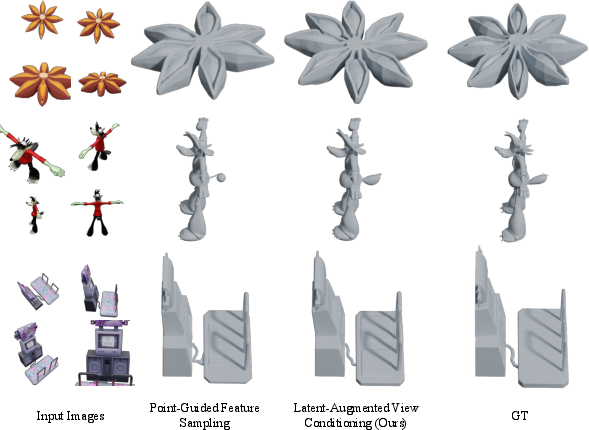
Figure 3: Our latent-augmented conditioning (right) maintains richer multi-view context and better alignment than point-guided sampling (left).
Extensive experiments on Toys4K and Google Scanned Objects benchmarks reveal that UniRecGen outperforms state-of-the-art baselines—including both strong generative models (e.g., TRELLIS, Hunyuan3D-MV) and feed-forward reconstructors (e.g., VGGT, LucidFusion, ReconViaGen)—on all major geometric and pose estimation metrics. In particular, the approach reduces Chamfer-L2 distance and improves both precision and recall across datasets. Performance in camera pose prediction (ATE, RPE) and depth estimation (AbsRel, RMSE) are also improved compared to prior work, an important consideration for downstream applications requiring accurate object localization and metric geometry.
Qualitatively, UniRecGen's outputs exhibit improved surface continuity, fewer artifacts in unseen or occluded regions, and enhanced multi-view consistency, substantiating the effectiveness of explicit geometric conditioning and cooperative training.

Figure 4: On Toys4K and GSO, UniRecGen generates meshes with higher structural and view-consistency fidelity than prior SOTA baselines given sparse-view input.
Robustness and Generalization
A notable property of the UniRecGen framework is its strong generalization to real-world, unposed sparse-view input. Robustness analyses indicate that the method maintains high reconstruction accuracy despite significant pose perturbations and limited image overlap, a regime where previous approaches degrade sharply.

Figure 5: UniRecGen generalizes to real-world scenarios, maintaining structural fidelity across diverse and challenging input conditions.
Additional Qualitative Results
Multiple qualitative modeling scenarios further corroborate the model’s ability to recover fine object details, precise alignment, and visually plausible completions over a wide distribution of shapes and categories.

Figure 6: Six multi-view reconstruction examples—each displays input, mesh overlay, model mesh, and ground-truth mesh per view—demonstrating accuracy and consistency.
Implications and Future Directions
The UniRecGen framework advances the agenda for tightly unified 3D vision pipelines, offering a paradigm where feed-forward geometric priors and high-capacity generative mechanisms interact natively in canonical 3D space. The decoupled, cooperative architecture allows for progressive module improvement, interpretability, and plug-and-play functionality, which is critical as both reconstruction foundations and generative lenses evolve rapidly.
Practically, UniRecGen’s performance suggests strong applicability for asset generation, digital twin construction, robotics, and AR/VR content pipelines where dense, high-fidelity meshes must be generated from unstructured, minimal supervision. Theoretically, it closes critical gaps in geometric representation learning and may catalyze further exploration into scene-level canonicalization, joint texture synthesis, and cross-modal generative integration.
The paper indicates future directions, such as extending to holistic scene generation and textured asset synthesis, which would require addressing issues of global context modeling, material property prediction, and possibly temporal or interaction-aware reasoning.
Conclusion
UniRecGen establishes a principled, modular approach to unifying sparse-view 3D reconstruction and high-fidelity generation, resolving longstanding challenges in coordinate alignment and learning synergy between deterministic and stochastic modules. By constructing a robust canonical bridge and leveraging disentangled cooperative learning, it provides strictly improved performance across all essential geometric benchmarks and demonstrates potential for substantial future extensions in both academic research and practical deployment (2604.01479).

