- The paper introduces CUPID, a unified framework that jointly models canonical 3D shape, texture, and camera pose to achieve robust single-image 3D reconstruction.
- It employs a two-stage cascaded flow matching pipeline—first generating occupancy and UV cubes, then refining geometry with pose-aligned, locally-attended features.
- Experimental results demonstrate significant improvements in Chamfer Distance, PSNR, SSIM, and semantic consistency, outperforming state-of-the-art baselines.
CUPID: Pose-Grounded Generative 3D Reconstruction from a Single Image
Introduction and Motivation
The paper introduces CUPID, a generative framework for single-image 3D reconstruction that explicitly grounds the generation process in both object-centric canonical 3D space and the input camera pose. Unlike prior approaches that either regress view-centric 3D geometry or synthesize canonical 3D objects without pose estimation, CUPID unifies these objectives by jointly modeling 3D shape, texture, and dense 2D–3D correspondences. This enables robust pose estimation and high-fidelity 3D reconstruction from a single image, addressing a key gap in the integration of generative modeling and geometric reasoning for embodied AI and robotics.
Methodology
CUPID frames the task as conditional generative modeling of the joint posterior p(O,π∣I), where O is the canonical 3D object, π is the object-centric camera pose, and I is the observed image. The model is trained to sample from the distribution of plausible 3D objects and their corresponding poses that explain the input image.
Representation
- 3D Object: Represented as a sparse set of active voxels {xi,fi}i=1L, where xi∈R3 are voxel coordinates and fi are features derived from multi-view DINOv2 aggregation, compressed via a 3D VAE.
- Camera Pose: Parameterized as a dense set of 3D–2D correspondences {xi,ui}i=1L, with ui being normalized 2D pixel coordinates for each voxel, enabling robust pose recovery via a PnP solver.
Two-Stage Cascaded Flow Matching
CUPID employs a two-stage conditional flow matching pipeline:
- Coarse Stage: Generates an occupancy cube and a UV cube (encoding 3D–2D correspondences) in canonical space. The UV cube is compressed via a 3D VAE for computational efficiency. The camera pose is recovered by solving a least-squares PnP problem using the generated correspondences.
- Refinement Stage: Conditioned on the recovered pose, the model injects pose-aligned, locally-attended image features into the voxel grid. This is achieved by back-projecting DINOv2 and low-level convolutional features from the input image to each voxel, significantly improving geometric and appearance fidelity.
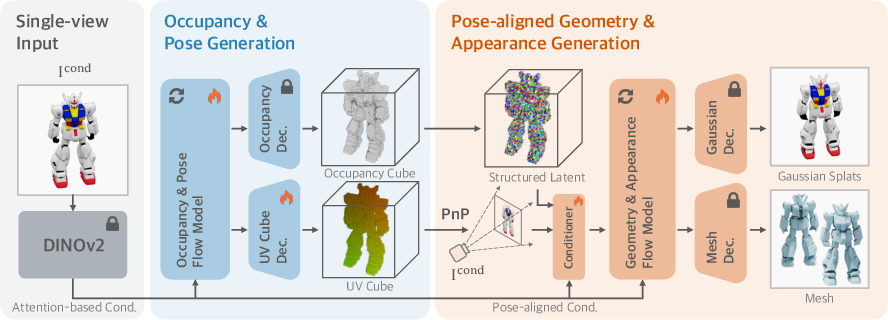
Figure 1: Overview of CUPID. From a single input image, CUPID generates occupancy and UV cubes, recovers camera pose via PnP, and refines geometry and appearance using pose-aligned features.
Component-Aligned Scene Reconstruction
CUPID extends to multi-object scenes by leveraging foundation models for object segmentation. Each object is reconstructed independently with occlusion-aware conditioning (random masking during training), and then composed into a global scene via 3D–3D similarity transformation using MoGe-predicted pointmaps and Umeyama alignment.

Figure 2: Component-aligned scene reconstruction. Each object is rebuilt independently and recomposed into the scene via 3D–3D similarity transformation.
Experimental Results
Quantitative Evaluation
CUPID is evaluated on Toys4K and GSO datasets, outperforming state-of-the-art baselines across monocular geometry accuracy, input-view consistency, and full 3D semantic alignment:
- Monocular Geometry: Achieves over 10% reduction in Chamfer Distance and matches or exceeds point-map regression methods (VGGT, MoGe) that only reconstruct visible geometry.
- Input-View Consistency: Delivers over 3 dB PSNR gain and substantial improvements in SSIM and LPIPS compared to LRM, LaRa, and OnePoseGen, indicating superior alignment of geometry and appearance to the input image.
- Full 3D Evaluation: Outperforms all baselines in CLIP-based semantic similarity of novel views, indicating high-fidelity and semantically consistent 3D reconstructions.
















Figure 3: Results for pose-grounded generative 3D reconstruction from a single test image. CUPID estimates camera pose and reconstructs a 3D model robust to scale, placement, and lighting, preserving fine details.





Figure 4: Comparison of generative reconstruction from a single image. CUPID produces the highest-fidelity geometry and appearance; LRM hallucinates details, LaRa is blurry, and OnePoseGen fails to register pose reliably.
Ablation Studies
Ablations on pose-aligned conditioning demonstrate that injecting locally-attended visual features (from both DINOv2 and low-level convolutional heads) yields the best performance in both PSNR and perceptual metrics. The model is robust to occlusion and maintains high quality even with sampled geometry and pose.
Multi-View Conditioning
CUPID supports multi-view input by fusing shared object latents across flow paths, enabling further refinement of geometry and appearance with additional views, analogous to MultiDiffusion in the image domain.


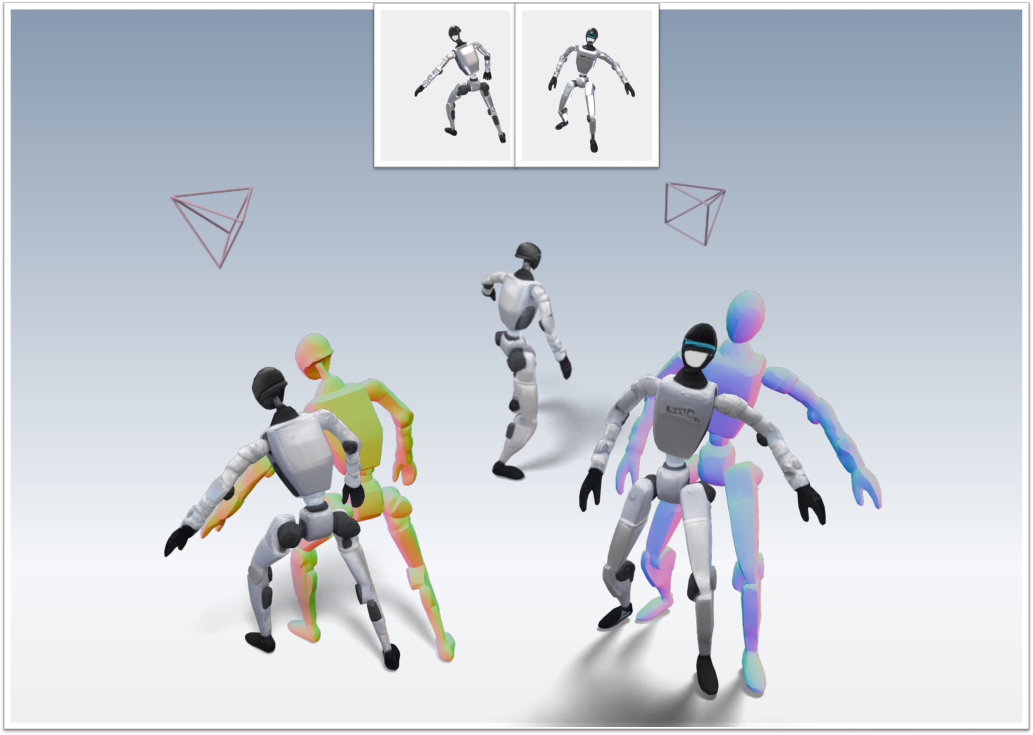
Figure 5: Multi-view conditioning. Fusing shared object latents across multiple input views enables refinement of camera, geometry, and texture.
Implementation Details
- Training Data: 260K 3D assets from ABO, HSSD, 3D-FUTURE, and Objaverse-XL, rendered from 24 random viewpoints per asset.
- Architecture: Two-stage flow transformer initialized from TRELLIS, with classifier-free guidance and AdamW optimization.
- Inference: 25 sampling steps, feed-forward sampling produces results in seconds.
- Resource Requirements: Training on 32 GPUs for approximately one week; inference is efficient and suitable for interactive applications.
Limitations
- Object Mask Dependency: Requires accurate object masks; boundary errors degrade quality.
- Lighting Entanglement: Some lighting is baked into textures; further work is needed for material–light disentanglement.
- Dataset Bias: Synthetic training data is mostly centered; off-centered objects are more challenging.
Implications and Future Directions
CUPID's explicit pose grounding and joint modeling of 3D structure and pose represent a significant advance in bridging generative modeling and geometric reasoning. The framework enables:
- High-fidelity, object-centric 3D asset creation from a single image, facilitating content creation for AR/VR, robotics, and digital twins.
- Component-aligned scene reconstruction for complex, occluded scenes, supporting compositional reasoning and manipulation.
- Test-time multi-view fusion for further refinement, suggesting a path toward efficient, feed-forward SfM-like systems.
- Bidirectional capabilities: Given a 3D object, CUPID can estimate pose from images, or generate images from known poses, supporting applications in pose estimation, simulation, and embodied AI.
Future work should address mask-free reconstruction, improved disentanglement of appearance and illumination, and more robust handling of real-world, in-the-wild images with diverse object placements and lighting.
Conclusion
CUPID presents a unified, pose-grounded generative approach to single-image 3D reconstruction, achieving state-of-the-art results in both geometric and appearance fidelity. By explicitly modeling dense 2D–3D correspondences and leveraging pose-aligned feature injection, CUPID closes the gap between generative 3D modeling and robust, observation-consistent reconstruction. The framework is extensible to multi-object and multi-view scenarios, with broad implications for 3D perception, content creation, and embodied AI.