- The paper presents a modular LLM orchestration pipeline that integrates specialized agents to achieve scalable, high-confidence vulnerability discovery with 203 confirmed zero-day vulnerabilities.
- It details a four-stage methodology—including matching, filtering, inspection, and adaptation—that significantly reduces false positives while maintaining robust recall and precision.
- Practical impact is demonstrated by assigning 118 CVEs across 127,000 OSS repositories, showcasing the effectiveness of cost-aware optimization and domain adaptation in real-world security scenarios.
TitanCA: Orchestrating LLM Agents for Scalable Vulnerability Discovery
Motivation and Context
Automated vulnerability detection remains a critical challenge in contemporary software engineering, particularly as the complexity and volume of codebases expand. Conventional static application security testing (SAST) tools, while pervasive in CI/CD pipelines, suffer from substantial false-positive rates, resulting in alert fatigue and undermining developer trust. Recent advances in LLMs, which excel at code understanding and semantic reasoning, motivate new approaches, but their practical deployment in security workflows is fraught with issues related to hallucinations, distribution shift, and lack of domain adaptation.
TitanCA presents a solution by orchestrating multiple LLM-powered agents, rather than relying on monolithic models. This approach achieves scalable, high-confidence vulnerability discovery in production environments, as demonstrated by its discovery and remediation of 203 confirmed zero-day vulnerabilities and the assignment of 118 CVEs across over 127,000 OSS repositories.
Modular Architecture
TitanCA implements a four-stage pipeline with modules specifically designed to maximize precision and maintain recall while optimizing computational resources. Each module targets distinct failure modes of LLM-based detection.
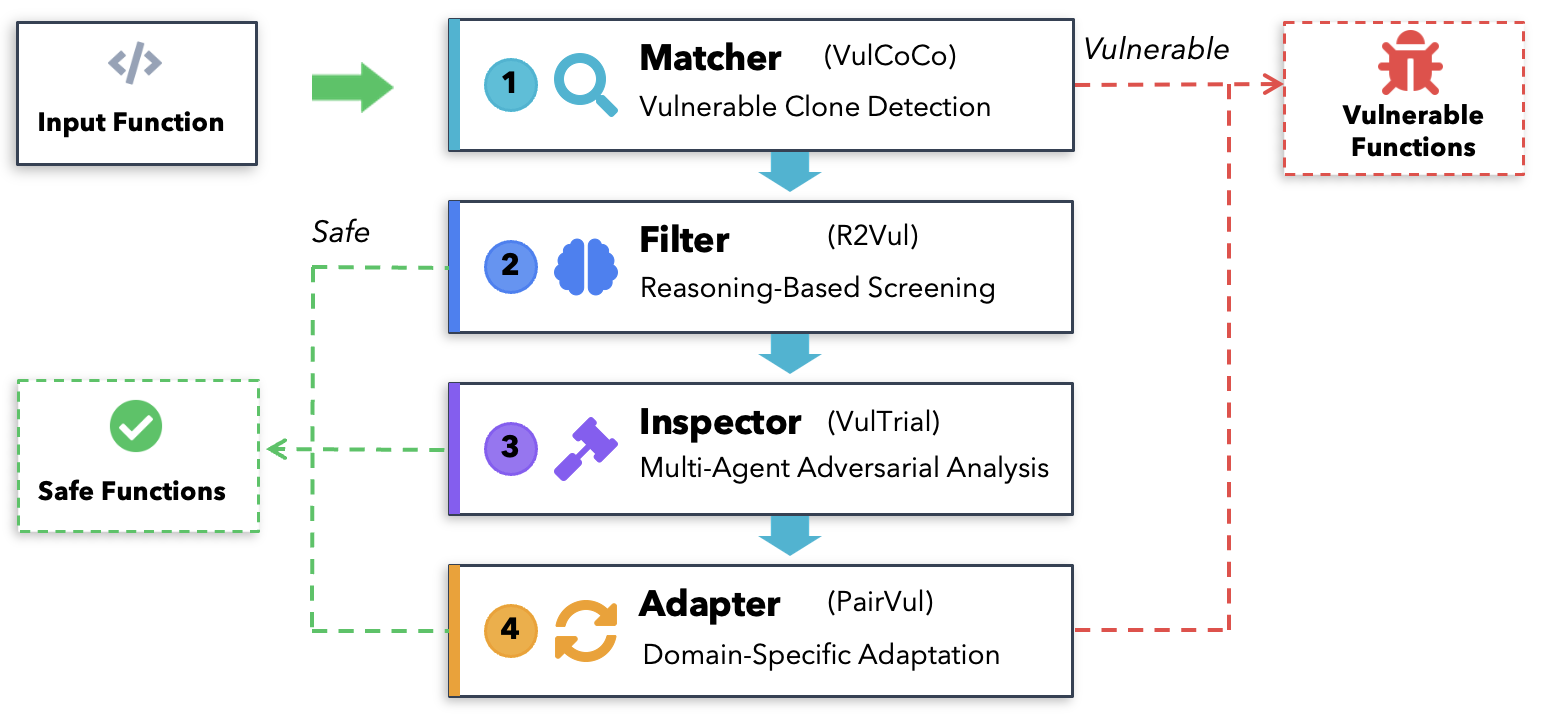
Figure 1: Overview of the TitanCA pipeline showing the four main modules—Matcher (VulCoCo), Filter (R2Vul), Inspector (VulTrial), and Adapter (PairVul)—each progressively refining vulnerability detection results.
Matcher (VulCoCo): Vulnerable clone detection employs embeddings and similarity search against curated vulnerability databases—including the NVD and TitanVul—leveraging an LLM as semantic validator to distinguish genuine vulnerabilities from syntactic matches. This stage is optimized for high recall, bypassing subsequent modules for confident matches.
Filter (R2Vul): Structured reasoning distillation via R2Vul differentiates between grounded reasoning and misleading explanations. The RLAIF paradigm with ORPO preference optimization enforces explicit reasoning, with inference-time calibration using conditional log-likelihoods and confidence thresholding. This reduces false positives substantially—from 28% to 20%—while maintaining over 77% recall under typical class imbalance.
Inspector (VulTrial): VulTrial’s mock-courtroom framework features multi-agent deliberation, assigning roles to specialized LLMs (Security Researcher, Code Author, Moderator, Review Board/Jury). This adversarial structure surfaces subtle vulnerabilities and mitigates confirmation bias present in single-model predictions.
Adapter (PairVul): Domain adaptation is performed by analyzing deployment-time false positives, labeling samples, and applying feedback-driven fine-tuning. PairVul’s iterative relabeling and fine-tuning ensure precision across diverse organizational contexts, frameworks, and coding idioms.
Data Foundation and System Infrastructure
TitanCA’s detection efficacy is underpinned by robust data engineering. Over 342,000 likely vulnerability samples are drawn from real-world disclosures and synthetic generation. CleanVul systematically eliminates label noise, combining automated and LLM-assisted verification, thus avoiding silent degradation in model performance commonly encountered in public datasets. Benchmark datasets (TitanVul, BenchVul) target the MITRE Top-25 CWEs, highlighting that in-distribution performance is an unreliable proxy for real-world generalization. The operational footprint includes 500 TB of data engineering workloads and persistent monitoring of 127,000 repositories, supporting cross-language and cross-pattern coverage.
TitanCA’s deployment in OSS reveals strong numerical outcomes: identification and remediation of 203 vulnerabilities, assignment of 118 CVEs, with public listing of these CVEs. 35% of detected vulnerabilities are rated as critical, with 95% at least medium severity and 91% exhibiting low attack complexity, attesting to their practical exploitability.
Approximately 50% of discovered issues map to the MITRE Top-25 CWEs—predominantly out-of-bounds access and integer errors—demonstrating focused impact in high-risk categories.
Engineering Insights
Decomposing the detection process into specialized collaborative modules substantially outperforms end-to-end monolithic models, particularly in mitigating false positives. Each module targets specific operational failure modes, mirroring human security workflows.
Cost-Aware Pipeline Optimization
Ordering modules by computational selectivity—filtering before expensive deliberation—reduces per-function cost and overall system overhead. This principle is akin to query optimization in databases.
Precision as Operational Priority
TitanCA employs F0.3 as a primary metric, emphasizing precision threefold over recall, which more closely matches developer needs. The academic focus on F1 is criticized for its misalignment with practical utility; future work should report precision-weighted metrics.
Structured Reasoning Enhances Trust
Training LLMs for explicit, grounded reasoning chains improves not just classification accuracy but developer acceptance; invalid explanations lead to discarding valid alerts, undermining effectiveness.
Multi-Agent Deliberation Captures Edge Cases
Adversarial, role-based debate in VulTrial ameliorates confirmation bias, enhancing robustness beyond the limits of solo inference.
Domain Adaptation Remains Critical
PairVul addresses the persistent limitation of models trained solely on public datasets, continuously adapting to organizational-specific vulnerability patterns, frameworks, and deployment contexts via feedback loops.
Theoretical and Practical Implications
TitanCA demonstrates that agentic orchestration in LLM-powered pipelines can deliver scalable, precise, and generalizable vulnerability discovery, markedly improving over SAST baseline tools. The modularity, reasoning-driven filtering, adversarial deliberation, and domain adaptation principles are extensible beyond vulnerability detection to other complex security tasks involving heterogeneous data and distribution shift.
In Phase 2, TitanCA aims to transcend function-level detection, leveraging broader context, automated repair generation, and behavioral studies to refine developer interaction. Open research directions persist in secure code generation benchmarking, especially as LLM coding agents proliferate, and in vulnerability detection in AI-generated code.
Conclusion
TitanCA’s orchestration of specialized LLM agents enables scalable and precise vulnerability detection in large codebases, validated by strong real-world performance and extensive CVE assignments. The modular approach, cost-aware ordering, structured reasoning, adversarial deliberation, and domain adaptation principles refine vulnerability detection workflows and are poised to influence future AI-augmented security tooling.