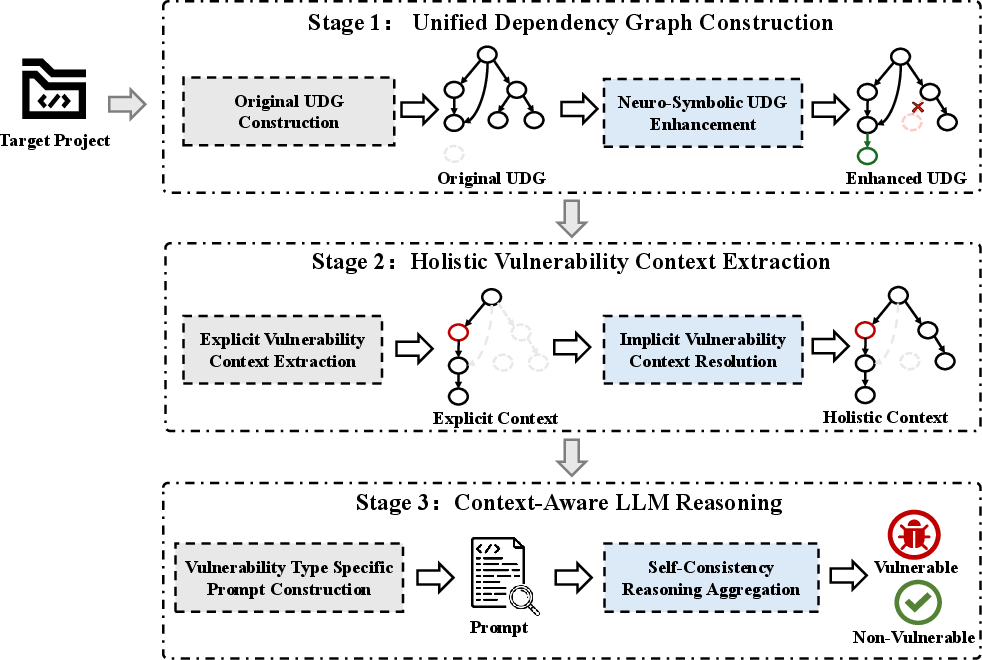
- The paper introduces a neuro-symbolic framework that combines enhanced program representations with guided LLM reasoning to improve source-level vulnerability detection.
- It employs unified dependency graph construction and holistic context extraction to resolve semantic fragmentation and reinforce static analysis.
- Empirical results demonstrate significant improvements in F1 and VP-S metrics over traditional and LLM-based approaches, validating its scalability and accuracy.
VulWeaver: Weaving Broken Semantics for Grounded Vulnerability Detection
Introduction and Motivation
Detecting true vulnerabilities in source code at scale remains a persistent challenge due to the limitations of existing static analysis methods and current LLM-driven approaches. Classic static analysis tools often rely on program representations that prioritize scalability over semantic granularity, inducing high rates of both false positives and negatives. LLM-based approaches, though promising, tend to operate over limited (e.g., single-function) or incomplete inter-procedural contexts and commonly fail to ground their predictions in precise semantic reasoning. The VulWeaver work introduces a neuro-symbolic framework targeting these gaps by enhancing program representations, extracting holistic vulnerability contexts, and structurally guiding the LLM’s reasoning process to achieve robust, transparent, and actionable source-level vulnerability detection (2604.10767).
Analysis of Broken Semantics and Contextual Failure Modes
A major source of detection failure in SAST and LLM approaches is semantic fragmentation—static analyses either omit key dependencies or inject spurious relations, and context slicing frequently stops at function boundaries, missing broader global or inter-procedural information.
For instance, in the patched version of CVE-2023-29523, dynamic code features (reflection) obscure actual call relationships, causing static tools and LLMs to hallucinate the presence of an exploitable path in non-vulnerable code.
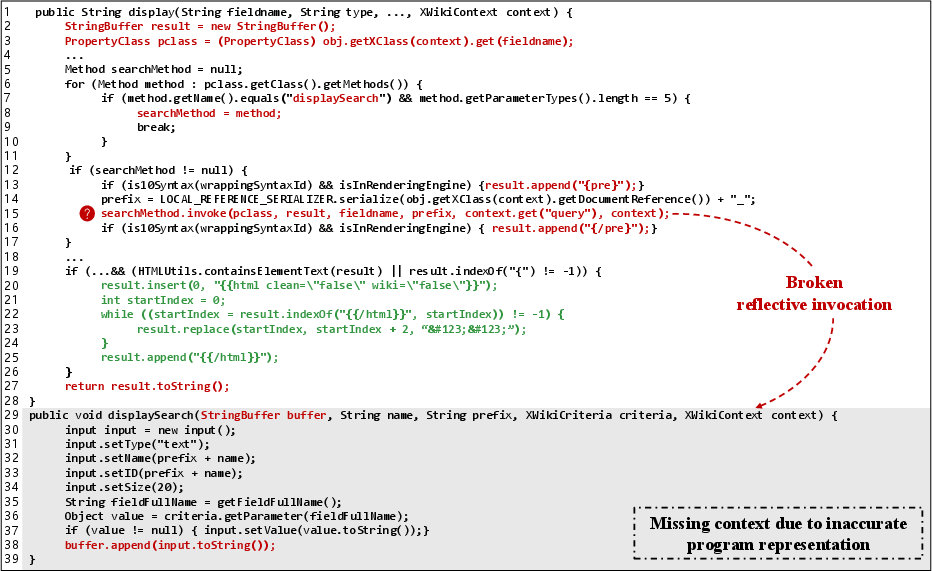
Figure 1: Patched code of CVE-2023-29523 highlighting semantic fragmentation due to incomplete call graph resolution, leading to false positives.
Similarly, in the patched version of CVE-2020-26282, the omission of global sanitization logic causes LLMs—when relying on conventional context extraction—to erroneously classify safe code as vulnerable.

Figure 2: Patched code of CVE-2020-26282 where incomplete context omits critical global sanitizer logic, resulting in LLM misclassification.
Pilot studies articulated in the paper show that LLMs, when unassisted, are brittle to adversarial perturbations (semantic identifier renaming), with F1 and VP-S drops up to 44% and 1050% respectively. By contrast, expert-guided, structured meta-prompting stabilizes performance, showcasing that vulnerability-aware reasoning supersedes superficial pattern matching.
The VulWeaver Approach
VulWeaver encompasses three key stages:
Neuro-Symbolic UDG Enhancement
The unified dependency graph is improved through four enhancements:
- Addition of global context nodes (e.g., variable and class definitions) using Tree-sitter.
- LLM-augmented call resolution for polymorphism and reflection, addressing silent failures in static call graph extraction.
- Deterministic reconstruction of intra-procedural non-local jumps (e.g., labeled breaks/continues).
- Summary-based, flow-sensitive taint analysis for precise data dependency pruning.
This enhancement substantially increases context completeness, especially for vulnerabilities distributed across multiple program components or dynamically dispatched code regions.
Holistic Context Construction
For each sensitive code location, VulWeaver extracts not only traditional backward/forward slices but also recursively incorporates:
- Usage Context: Intra-callee sanitization and validation downstream of sensitive sinks.
- Definition Context: Full variable provenance, including global field initializations otherwise missed in single-scope analysis.
- Declaration Context: Import/package/class declarations enabling accurate API and type disambiguation.
This advanced context inclusion is critical for LLM reasoning: empirically, omission of implicit context or UDG enhancements causes F1 and VP-S drops up to 59%.
Unlike vanilla CoT prompts, VulWeaver uses meta-prompts parameterized by CWE-specific semantic predicates and defense heuristics. Detection proceeds in a four-step trajectory: context analysis, trigger verification, defense assessment, and evidence-driven synthesis. Each step is bound to explicitly defined domain knowledge (e.g., robust vs. ad-hoc mitigations for SQLi, XSS) and mandated to produce intermediate evidence, rather than relying on opaque statistical inferences.
Statistical aggregation (majority voting across multiple runs) further stabilizes predictions, with significant robustness under adversarial identifier renaming.
Numerical Results and Ablations
On the chronologically-split PrimeVul4J dataset (Java, 1620 unique samples; 41 CWEs), VulWeaver achieves F1=0.75, recall=0.70, precision=0.81, and VP-S=0.58 on the test set. These figures reflect improvements of 23% (vs. DeepDFA), 15% (vs. VulInstruct), and 60% (vs. VulTrial) in F1, and 164% in VP-S over the best LLM baseline.
Strong generality is observed on PrimeVul (C/C++, 435 pairs): F1=0.78, VP-S=0.48, with the core architecture requiring minimal modifications.
Ablations and per-CWE breakdowns show:
- Removing the holistic context (w/o C) degrades VP-S by 59%, confirming its criticality.
- UDG enhancement particularly benefits weaknesses in static analysis, yielding context and performance gains as high as 141% and 112% (token size, VP-S) in CWE-707.
- Meta-prompting yields drastic resilience to adversarial renaming, whereas CoT performance is brittle.
- VulWeaver maintains strong F1 and VP-S across all context lengths, with minimal lost-in-the-middle phenomena even for multi-thousand-token slices.
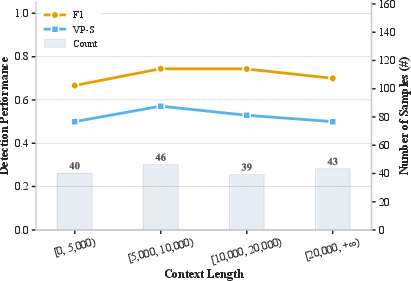
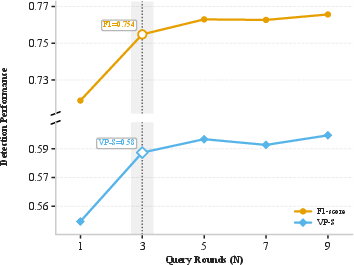
Figure 4: Left—VulWeaver’s F1 and VP-S are robust to increasing context length, indicating resilience to “token tax”; Right—Parameter sensitivity with respect to majority voting rounds, with diminishing returns after three iterations.
On nine large-scale real-world Java projects, VulWeaver localized 26 true vulnerabilities (precision 0.68, 15 ultimately confirmed, five assigned CVEs), and detected another 40 vulnerabilities in a major industrial codebase.
Theoretical and Practical Implications
The synthesis of neuro-symbolic analysis and LLM reasoning fundamentally alters the effective context window for vulnerability detection. By structurally restoring broken program semantics and supplying comprehensive, vulnerability-specific evidence to the LLM, VulWeaver eliminates the predominant failure modes in both static and language-model-based approaches. Its context-aware prompting paradigm not only ensures transparency and consistency in verdicts, but also demonstrates that scalable AI-driven auditing pipelines need not sacrifice semantic precision for tractability.
In practical terms, the approach can serve as a downstream verifier for traditional SAST tools, drastically reducing triage burdens, and supports extensibility for rapid inclusion of new CWEs or project-based refinements.
Theoretically, VulWeaver provides an operational framework for integrating neuro-symbolic program analysis, grounded knowledge synthesis, and LLM reasoning, with direct applicability to broader semantic program understanding tasks, cross-language security analysis, and automated patch validation.
Future Directions
The paper highlights several avenues for research:
- Extension of neuro-symbolic UDG enhancement for language- or framework-specific constructs (e.g., indirect calls in C/C++, annotation-driven flows in Java).
- Adaptive, agentic context extraction—modularizing skills for on-demand program slicing, automatic API/vulnerability discovery, and explanation generation.
- Self-supervised or LLM-driven prompt construction for long-tail vulnerability types and emergent security patterns.
Incremental progress toward these goals will enhance the scalability, reliability, and automation level of AI-enabled software security tools and expand their applicability to complex, large-scale industrial codebases.
Conclusion
VulWeaver demonstrates that program reasoning benefiting from integrated static analysis and vulnerability-specific guided LLM inference can fundamentally improve vulnerability detection performance and reliability. Its design addresses key limitations of both classic and contemporary approaches, establishing robust, cross-language, and explainable vulnerability detection, with validated utility in both open source and industrial settings (2604.10767).