- The paper introduces Intern-Atlas, a novel infrastructure that constructs an explicit, causally annotated graph mapping the evolution of AI methods.
- It employs a three-stage pipeline—entity resolution, edge typing, and evidence extraction—over a corpus of over 1 million AI papers.
- The system enhances research idea evaluation and generation through robust metrics and a self-guided temporal tree search algorithm.
Intern-Atlas: Methodological Evolution Graph Infrastructure for AI Research
Motivation and Limitations of Document-Centric Scientific Infrastructure
Traditional scientific infrastructure in AI, such as Google Scholar, Semantic Scholar, and OpenAlex, is fundamentally document-centric, providing citation-based connectivity between publications but lacking semantic, methodological-level structure. This paradigm implicitly assumes that humans perform the heavy lifting of reconstructing method lineages, synthesizing bottleneck-mechanism relationships, and tracking the causal drivers of technical evolution entirely in their heads.
The emergence of AI research agents—LLM-driven automata that consume scientific data programmatically—exposes significant limitations of this infrastructure. Such agents lack the implicit contextual and reasoning faculty of human researchers and cannot reliably induce evolutionary trajectories or discover structural knowledge gaps from unstructured text. Consequently, their ability to generate, evaluate, and traverse research ideas is bottlenecked by the absence of a machine-readable, semantically explicit knowledge base for the progression and interrelation of methodologies.
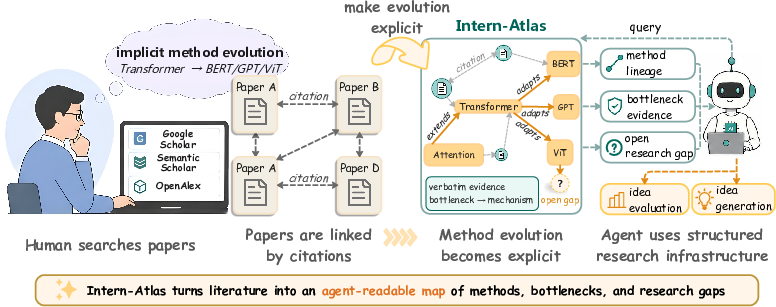
Figure 1: Traditional citation graphs hide methodological evolution, whereas Intern-Atlas constructs an explicit, causally labeled, agent-readable method evolution graph supporting direct lineage and bottleneck queries.
System Architecture: From Document Corpus to Methodological Evolution Graph
Intern-Atlas introduces a method-centric infrastructure layer by constructing a heterogeneous, typed graph over 1,030,314 AI papers, unifying papers, methods, and stubs as nodes, and causal relations as edges. The methodology graph construction proceeds in three main stages:
- Entity Resolution: Canonical method entities are automatically curated through a blend of hand-crafted seed lists, LLM-based expansion, and robust alias resolution, yielding 8,155 canonical methods and 9,545 aliases.
- Edge Typing: Every intra-corpus citation is semantically typed by an LLM classifier into one of seven relation categories (extends, improves, replaces, adapts, uses_component, compares, background), emphasizing directionality and causal semantics.
- Evidence Extraction: For each non-background, causal edge, a verbatim evidence record is attached, comprising quoted bottleneck and mechanism spans and a bottleneck taxonomy label (span across 14 axes such as computational complexity, accuracy, generalization, etc.).
The resulting graph comprises over 9 million typed edges, with lineage-inducing subgraphs defined by strong causal relations (extends, improves, replaces, adapts). Each edge is grounded in verbatim, context-specific source evidence enabling downstream auditability.
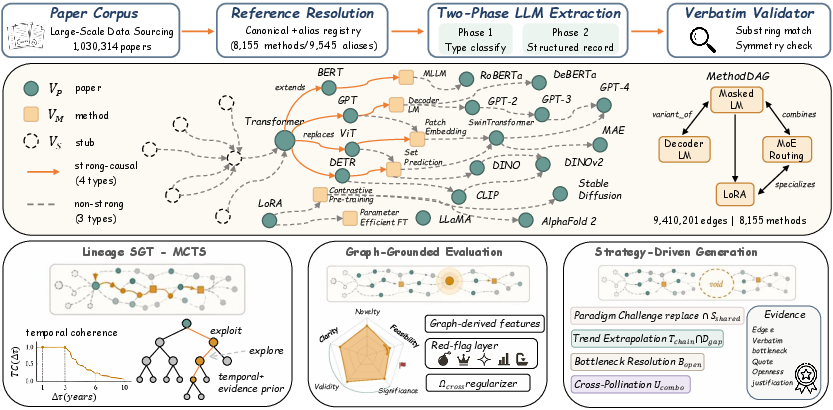
Figure 2: Intern-Atlas pipeline: from raw literature through entity resolution, edge typing, evidence extraction, and downstream operators for lineage/traversal, evaluation, and idea generation.
Graph-based Operators: Enabling Automated Reasoning and Idea Manipulation
Intern-Atlas exposes three core operator classes:
- Lineage Reconstruction: The Self-Guided Temporal Monte Carlo Tree Search (SGT-MCTS) algorithm traverses the strong-causal subgraph while optimizing for edge confidence and publication-year coherence. This enables robust recovery of plausible, temporally ordered methodological innovation chains beyond what greedy/beam/random walk strategies can reconstruct.
- Graph-Grounded Idea Evaluation: Research ideas are mapped onto the graph and scored across five technical axes (Novelty, Feasibility, Significance, Validity, Clarity). Each score is a deterministic function of graph statistics—capturing structural novelty, maturity, frontier-significance, evidence-backed validity, and compositional clarity. A cross-dimensional regularizer encodes empirical priors (e.g., penalizing highly novel yet infeasible mashups).
- Strategy-Driven Idea Generation: The graph is scanned for under-populated regions (structural gaps, sacrifice axes, under-solved bottlenecks, disconnected method pairs). Each gap is paired with a generation strategy (bottleneck resolution, trend extrapolation, cross-pollination, paradigm challenge), producing novel proposals tightly anchored to explicit, verifiable methodological bottlenecks in the literature.
Empirical Evaluation: Graph Quality and Research Utility
Intern-Atlas’s method-entity coverage reaches a node match ratio (NMR) of 91.0% and an edge reachable ratio (ERR) of 89.7% on expert-curated survey graphs, indicating a near-exhaustive representation of surveyed methods and their relations. Path semantic correctness (PSC) is 92.0%, confirming preservation of evolution semantics.
SGT-MCTS achieves node recall, edge recall, and chain alignment scores (NR/ER/CAS) of 84.8%/79.0%/84.8%, compared to beam search (max 44.9%/23.2%/44.9%) and random walk (28.1%/0.7%/28.1%). The methodological lineages reconstructed are thus substantially closer to human expert references, especially through branching and high-connectivity points where greedier strategies fail.
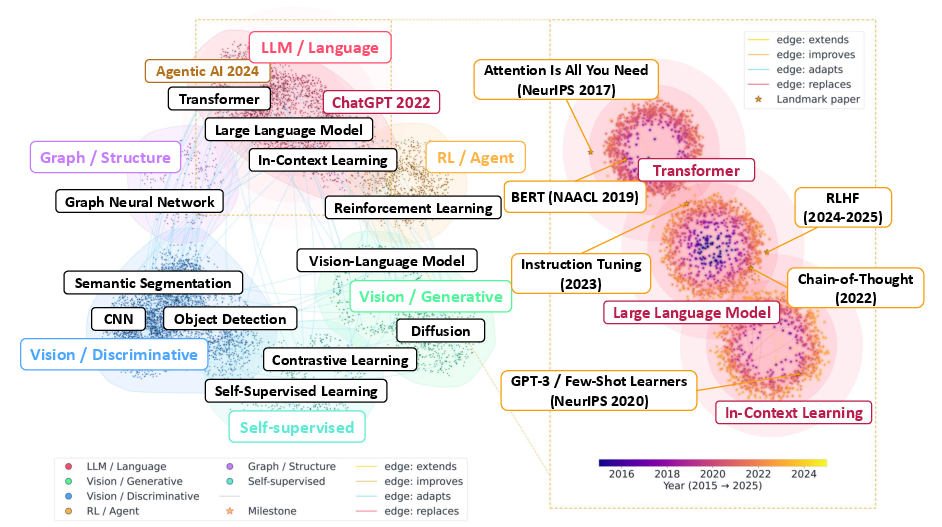
Figure 3: The AI methodological landscape clusters into paradigm continents (e.g., LLMs, vision, optimization), visualizing evolution chains and hub methods.
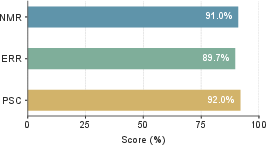
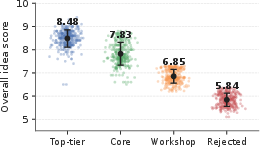
Figure 4: Static graph quality metrics show Intern-Atlas matches most surveyed methods and relations, with high semantic correctness.
Evaluation of Graph-Grounded Idea Assessment
Across 1,200 ideas spanning accepted and rejected submissions, Intern-Atlas automatically stratifies idea scores in line with publication strata. Top-tier conference papers receive the highest mean overall score (8.48), decreasing through core conferences, workshops, and rejected submissions (down to 5.84). Dimension-wise, Significance and Validity scores vary most, while Clarity is weakest as a separator.
Human expert alignment is strong: Intern-Atlas yields a mean Spearman correlation of 0.81 (compared to 0.58 for a pure LLM baseline), with particularly high alignment for Novelty (0.84 vs. 0.52) and Significance (0.82 vs. 0.55). This demonstrates effective structural grounding absent from purely text-based LLM judgments.
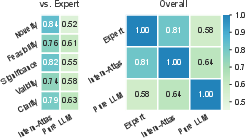
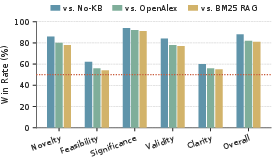
Figure 5: Spearman correlations demonstrate that Intern-Atlas idea evaluations align more strongly with human expert judgment than LLM-only approaches.
Graph-Grounded Idea Generation
In automated idea generation, Intern-Atlas outperforms document-based retrieval engines (OpenAlex, Semantic Scholar, standard RAG) as a knowledge grounder. Generated ideas achieve significantly higher scores on Novelty, Significance, and Validity, and are preferred by human experts in blind pairwise comparison (win rate 81–88% across all baselines). Gains are particularly marked for research queries targeting methodological bottlenecks and structural knowledge gaps.
Implications and Future Directions
Intern-Atlas constitutes a critical transformation from flat, citation-centric scientific infrastructure to a granular, typed, causally annotated methodology graph. This shift underpins a new paradigm for AI-driven scientific discovery:
- Automated Research Agents: By externalizing method lineage and bottleneck-mechanism structure, Intern-Atlas enables sophisticated planning, hypothesis generation, and evaluation workflows for LLM research agents—tasks previously feasible only via unconstrained parameter memory and unreliable context scraping.
- Deterministic, Auditable Evaluation: The deterministic, zero-trainable-parameter design facilitates reproducibility and transparency in idea review and generation, mitigating the biases and sampling variance inherent in LLM-based judges.
- Complex Lineage Recovery: The robustness of SGT-MCTS over high-branching graphs sets a new standard for reconstructing evolutionary trends in AI, supporting historical analysis and synthetic trajectory generation.
- Open Infrastructure: The release of the graph and pipeline as an open asset invites community extension toward broader scientific domains and dynamic taxonomy expansion.
Future work could incorporate cross-disciplinary method mappings, dynamic updating for rapid fields, learning-enhanced traversals, and integration with experimental platforms for closed-loop AI-driven discovery.
Conclusion
Intern-Atlas realizes an explicit, agent-readable graph of methodological evolution for the AI research community. Its combination of large-scale scope, interpretable causal typing, and empirical effectiveness in reconstruction, idea evaluation, and ideation, strongly supports its role as an infrastructural prerequisite for machine-driven science. As automated discovery agents proliferate and methodology graphs become indispensable, systems like Intern-Atlas will define the next generation of scientific knowledge management and reasoning.