Sci-Reasoning: A Dataset Decoding AI Innovation Patterns
Abstract: While AI innovation accelerates rapidly, the intellectual process behind breakthroughs -- how researchers identify gaps, synthesize prior work, and generate insights -- remains poorly understood. The lack of structured data on scientific reasoning hinders systematic analysis and development of AI research agents. We introduce Sci-Reasoning, the first dataset capturing the intellectual synthesis behind high-quality AI research. Using community-validated quality signals and an LLM-accelerated, human-verified pipeline, we trace Oral and Spotlight papers across NeurIPS, ICML, and ICLR (2023-2025) to its key predecessors, articulating specific reasoning links in a structured format. Our analysis identifies 15 distinct thinking patterns, with three dominant strategies accounting for 52.7%: Gap-Driven Reframing (24.2%), Cross-Domain Synthesis (18.0%), and Representation Shift (10.5%). The most powerful innovation recipes combine multiple patterns: Gap-Driven Reframing + Representation Shift, Cross-Domain Synthesis + Representation Shift, and Gap-Driven Reframing + Cross-Domain Synthesis. This dataset enables quantitative studies of scientific progress and provides structured reasoning trajectories for training the next generation AI research agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Sci-Reasoning, a new dataset that tries to capture the “thinking process” behind top AI research papers. Instead of just listing who cited whom, it shows how new papers build on older ones: which ideas they borrowed, what problems they spotted, and how they combined pieces to create something new. The goal is to better understand how scientific breakthroughs happen and to help build AI tools that can do smarter research.
What questions does it try to answer?
The paper asks three main questions, in everyday terms:
- How do great AI papers find gaps or problems in past work and turn them into new ideas?
- How do they mix ideas from different places (like different subfields) to create something fresh?
- Are there common “thinking patterns” that many successful papers use, and can we map them in a structured way?
How did the researchers study this?
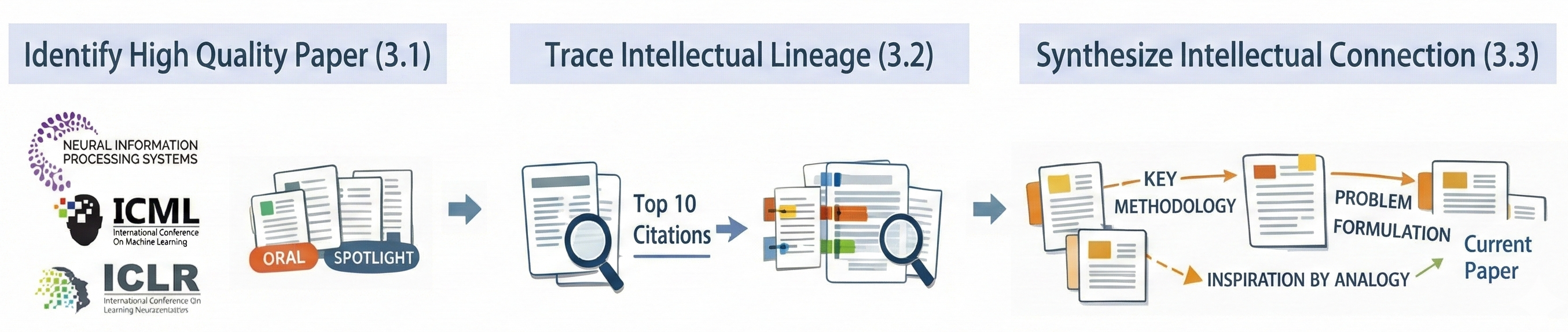
Think of a great paper as a new Lego model made from older bricks. The authors:
- Picked top-tier AI papers: They collected 3,819 “Oral” and “Spotlight” papers from big conferences (NeurIPS, ICML, ICLR) from 2023–2025. These are like the “top picks” chosen by experts.
- Found the key older papers (“predecessors”): They used a LLM—an advanced AI that can read and reason over long texts—to scan each paper and identify the 5–10 older works it most heavily builds on, not just who it cites, but why those citations matter.
- Mapped the connections: For each “new” paper and its key predecessors, they created a structured “Lineage Graph.” This includes:
- The role of each older paper (for example, a method that was extended, a problem definition, a benchmark to beat).
- The type of relationship (for example, “addressed limitation,” “combined with,” “reframed”).
- A short, human-readable story of how the ideas were put together.
- Checked quality: They validated these results using multiple AI models and human review for uncertain cases. They also ran tests to measure how well different AI models identify key predecessors. One model (called GPT-5 in the paper) had the best recall (found about 89.73% of the correct predecessors in their test).
If “citation graphs” are like a simple family tree showing who is related, these “Lineage Graphs” are like a detailed story explaining how family members helped each other grow.
What did they find, and why is it important?
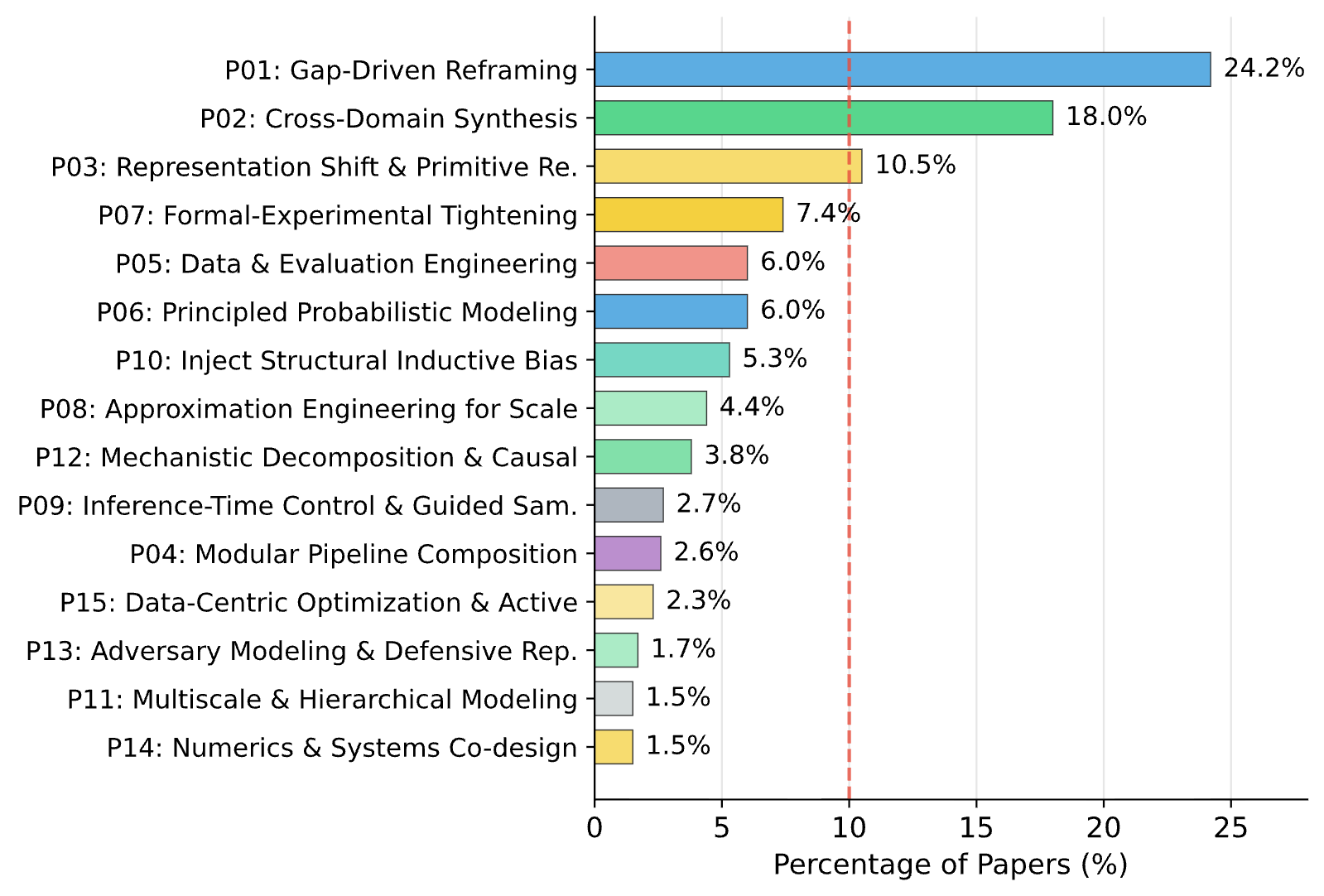
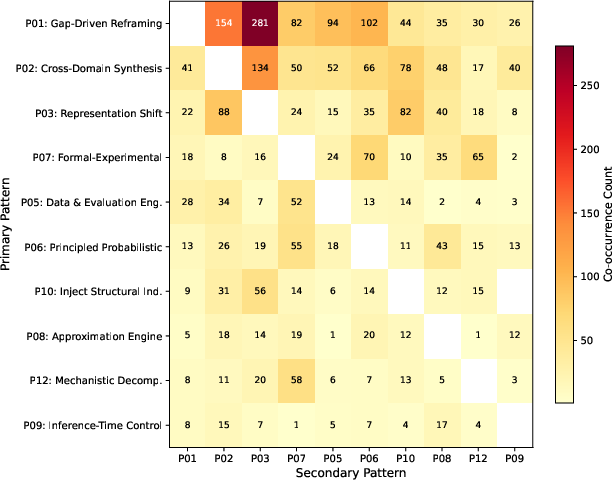
From the structured maps and stories, they discovered 15 common thinking patterns used by successful AI papers. Three stood out as the most common:
- Gap-Driven Reframing (24.2%): Spot a clear weakness in current methods, then redefine the problem so a better approach fits. In short: “Find the hole, reshape the problem.”
- Cross-Domain Synthesis (18.0%): Borrow a solution from another area and adapt it. In short: “Grab a tool from a neighboring field and make it work here.”
- Representation Shift (10.5%): Change the basic building blocks of the problem (for example, switch from pixels to another representation) so the solution becomes easier. In short: “Use a better set of building blocks.”
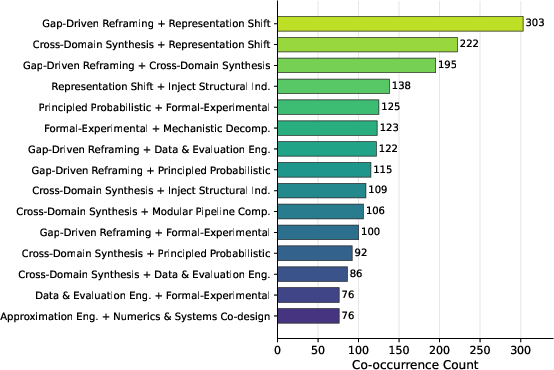
They also found that the strongest papers often combine these patterns—like following a recipe:
- Reframe + New Primitive: Gap-Driven Reframing + Representation Shift
- Import + Adapt: Cross-Domain Synthesis + Representation Shift
- Diagnose + Borrow: Gap-Driven Reframing + Cross-Domain Synthesis
Two more notable results:
- The dataset helps predict research directions: Given a paper’s key predecessors, an AI model could generate ideas similar to what was actually published about half the time (Hit@10 up to 49.35%). This suggests the reasoning maps capture real, useful signals.
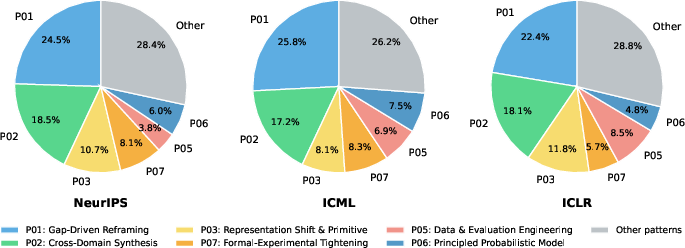
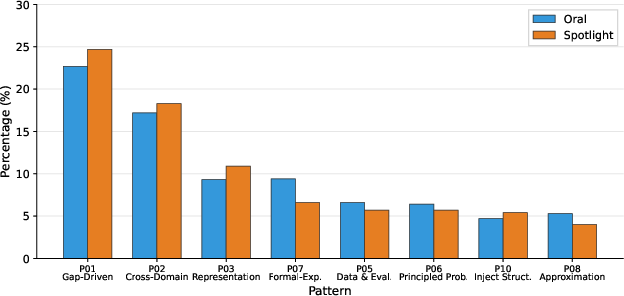
- Conference styles differ slightly: ICML leans more theoretical, ICLR favors representation and benchmarking, NeurIPS is broader and more cross-disciplinary. This can guide how people shape their submissions.
Overall, these findings turn the “mystery” of innovation into patterns we can study, learn, and use.
What’s the impact?
- For students and researchers: Sci-Reasoning shows how top papers are built—like guided tours through the authors’ thought process. It can teach better ways to find gaps, borrow ideas wisely, and combine them into powerful contributions.
- For AI research assistants: The structured reasoning paths are training data for AI that could help design new experiments, suggest productive combinations of ideas, and avoid dead ends.
- For science as a whole: With more transparent “how we got here” maps, we can study progress more systematically and speed up discovery.
A few caveats:
- Papers are polished stories, not the messy real-life path of discovery. The dataset reflects the final “justification” of ideas, not every detour along the way.
- It covers 2023–2025 AI papers in top ML conferences—useful but not the entire scientific world.
- Innovation patterns can change over time as fields evolve.
Even with limits, Sci-Reasoning is a big step toward making scientific reasoning visible, measurable, and teachable—and toward building AI that can assist with genuine research creativity.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed at guiding future research:
- Establish a human-annotated benchmark for predecessor identification, lineage roles, and relationship types to quantify precision, recall, and F1 beyond the small (~30-paper) internal validation.
- Report precision and error analysis for predecessor extraction; current evaluation emphasizes recall only, leaving false-positive rates and failure modes uncharacterized.
- Clarify construction of the “ground-truth predecessors” (for the 77-paper validation): criteria, annotator protocol, inter-annotator agreement, and public release of the benchmark.
- Evaluate robustness of predecessor extraction to paper length, domain subfields (e.g., theory vs. systems vs. applications), and writing style differences; quantify performance variance across these axes.
- Assess susceptibility of the single-pass LLM pipeline to hallucinations and rhetorical citation bias (e.g., perfunctory or negative citations misinterpreted as intellectual lineage).
- Incorporate non-citation influences (talks, code repositories, datasets, blog posts, social media discussions, review feedback) to mitigate the known gap between “logic of justification” and actual discovery processes.
- Measure stability and reproducibility of pipeline outputs across LLM versions, providers, and prompt variations; include sensitivity analyses and versioned artifacts.
- Replace or complement proprietary LLMs with open-source models to improve reproducibility, cost transparency, and accessibility; benchmark trade-offs.
- Provide quantitative calibration of LLM self-reported confidence scores used to trigger cross-validation and manual review; assess overconfidence and missed errors in “high-confidence” cases.
- Define and evaluate a controlled ontology for “predecessor roles” and “relationship types” (e.g., extend/bridge/address-limitation/reframe), including guidelines, edge cases, and cross-domain applicability tests.
- Compare LLM-based lineage extraction to established citation-intent and context models (e.g., structural scaffolds, argumentative zoning) to quantify added value and potential gaps.
- Validate the 15-pattern taxonomy with expert human coders at scale, report inter-annotator agreement, and identify patterns prone to ambiguity or conflation.
- Test generalizability of the 15 patterns beyond 2023–2025 and beyond NeurIPS/ICML/ICLR (e.g., AAAI, IJCAI, UAI, CVPR, ACL), as well as across interdisciplinary areas (e.g., bio/health, neuroscience, symbolic AI).
- Establish causal links (rather than correlations) between thinking patterns and outcomes (acceptance decisions, long-term citations, real-world impact); design quasi-experiments or matched controls.
- Quantify conference-specific biases introduced by using Oral/Spotlight status as the “high-quality” filter; evaluate how pattern distributions change under alternative quality proxies.
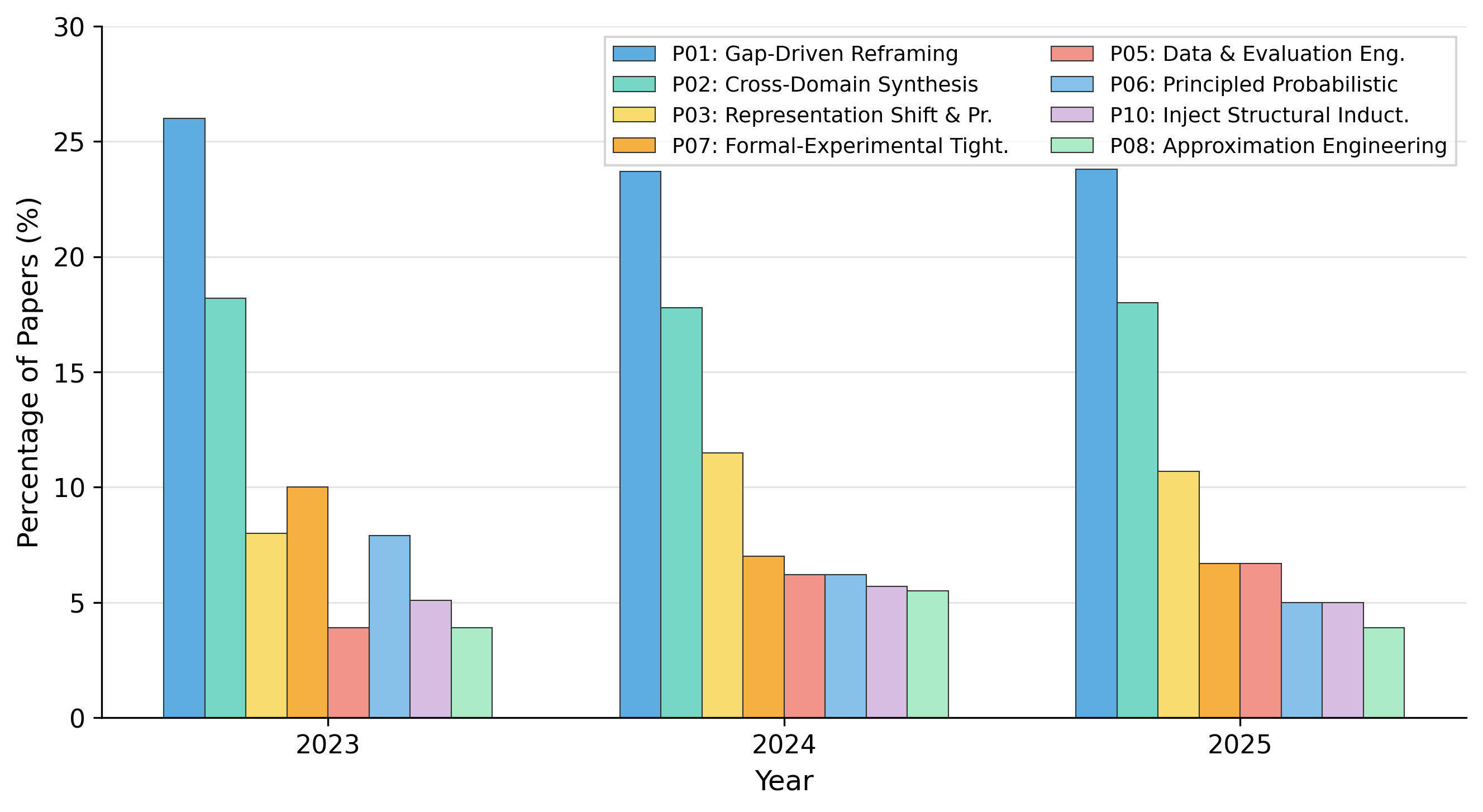
- Track longitudinal evolution of patterns and pattern combinations beyond the 3-year snapshot; assess stability, emergence, and decay of strategies over time.
- Clarify the meaning of “most powerful innovation recipes”: define power operationally (e.g., downstream impact, novelty, acceptance likelihood) and test statistically.
- Provide uncertainty estimates (confidence intervals) and significance testing for pattern distributions, temporal trends, and conference comparisons.
- Expand the lineage beyond cited works to include uncited-but-acknowledged influences (e.g., via acknowledgments, related talks, project histories), and evaluate added explanatory power.
- Analyze how dataset representations handle multi-modal content (figures, math, code) that often carry core intellectual contributions but are difficult for LLMs to parse.
- Investigate multilingual and non-English papers and venues to identify language and regional biases in lineage tracing and pattern taxonomy.
- Evaluate whether training AI research agents on Sci-Reasoning measurably improves literature review quality, idea generation novelty, and experimental validity; define tasks and baselines.
- Design additional benchmarks (beyond Hit@10 ideation) for “research reasoning” (e.g., gap diagnosis, reframing, representation choice, cross-domain mapping) with rigorous human evaluation.
- Reduce evaluation circularity by avoiding single-model judges; use multi-judge ensembles (human + diverse LLMs), adjudication protocols, and agreement metrics for ideation matching.
- Control for common-trend confounds in the ideation task (e.g., many contemporaneous papers explore similar directions); include random/matched baselines and novelty/coverage metrics.
- Report detailed computational cost, throughput, and carbon footprint of the pipeline; analyze cost-quality trade-offs and scaling limits for broader adoption.
- Provide a clear licensing and compliance statement for use of full texts and metadata (especially for non-arXiv content), and document data provenance and exclusions.
- Integrate Sci-Reasoning with existing research knowledge graphs (e.g., S2ORC, CHIMERA) and evaluate improvements to retrieval, synthesis, and ideation tasks.
- Explore methods to mitigate the Matthew effect and community biases (e.g., reweighting, stratified sampling, counterfactual analyses) so agents trained on the dataset do not amplify existing inequities.
- Release failure case studies illustrating where lineage links or synthesis narratives are incorrect or misleading, along with guidance on error detection and correction.
Practical Applications
Immediate Applications
The following applications can be implemented now using the released dataset and code, leveraging Sci-Reasoning’s structured lineage graphs, pattern taxonomy, and LLM-validated synthesis narratives.
- Research ideation copilot for labs and companies (sectors: software, AI, healthcare, finance, robotics)
- What: An assistant that proposes concrete research directions by recombining “innovation recipes” (e.g., Diagnose + Borrow, Import + Adapt) drawn from the dataset and the user’s internal corpus.
- Tools/products/workflows: InnovationRecipe Copilot; LineageRAG pipeline that retrieves predecessors, classifies thinking patterns, and prompts an LLM to generate k research ideas; built-in Hit@10 evaluation for idea quality.
- Dependencies/assumptions: Reliable full-text access to target corpora; LLMs with ≥50-page context windows; human-in-the-loop review; novelty signals beyond Oral/Spotlight where needed.
- Role-aware scientific search and literature dashboards (sectors: enterprise R&D, academia, publishing)
- What: Scholar search ranks results by predecessor role (e.g., method, benchmark, formulation) and relationship type (extend, reframe, address limitations), with lineage visualizations.
- Tools/products/workflows: Role-aware Scholar Search; LineageGraph Explorer; integration with Exa semantic search and LitLLM-style RAG.
- Dependencies/assumptions: Consistent citation-to-bibliography linking; access to full texts; robust role and relationship tagging on non-ML corpora.
- Novelty assessment and reviewer support (sectors: academia, publishing, policy/funding)
- What: Triage manuscripts and grant proposals by mapping predecessors and classifying dominant pattern combinations to surface novelty risk and likely impact.
- Tools/products/workflows: NoveltyScore & Recipe Map; ReviewerLens plugin for editorial systems; grant panel dashboards highlighting gap diagnoses and representation shifts.
- Dependencies/assumptions: Agreement that Oral/Spotlight is an adequate quality proxy; safeguards against field-specific biases; domain-adapted pattern classifiers.
- Team onboarding and knowledge transfer via “pattern cards” (sectors: all R&D)
- What: Condensed briefs that explain the reasoning patterns underlying a lab’s focus areas and key papers, accelerating ramp-up for new hires and collaborators.
- Tools/products/workflows: Pattern Cards; Lineage Briefs auto-generated from the dataset; internal wiki templates and checklists for “Reframe + New Primitive.”
- Dependencies/assumptions: Up-to-date corpus coverage; acceptance of standardized pattern taxonomy across teams.
- Courseware for teaching scientific reasoning (sectors: education, academia)
- What: Assignments that require tracing intellectual lineage, identifying gaps, and proposing reframes or representation shifts; auto-feedback with dataset exemplars.
- Tools/products/workflows: Sci-Reasoning Classroom Pack; LMS plugins; rubric aligned to 15 canonical patterns; student-facing “recipe library.”
- Dependencies/assumptions: Instructor adoption; ethical use of LLM assistance in coursework; alignment with departmental learning outcomes.
- Competitor and technology scouting (sectors: healthcare, energy, robotics, medtech)
- What: Detect cross-domain synthesis opportunities (e.g., importing control-theoretic stability into clinical decision systems), and identify licensable mechanisms.
- Tools/products/workflows: Synthesis Radar; “compatibility layer” suggestion workflows; patent-paper lineage overlays.
- Dependencies/assumptions: Patent and licensing metadata integration; legal/IP reviews; transfer feasibility assessments.
- Research knowledge graph enrichment (sectors: knowledge management, software tooling)
- What: Add predecessor roles, relationship types, and synthesis narratives to internal knowledge graphs for queryable reasoning trails.
- Tools/products/workflows: Lineage ETL; ResearchOps Copilot; connectors to S2ORC/SPECTER embeddings; role-aware graph queries.
- Dependencies/assumptions: Data governance and privacy; schema harmonization with existing KGs; scalable long-document processing.
- Benchmarking and training of AI research agents (sectors: AI tooling and platforms)
- What: Use the dataset’s structured trajectories as training/evaluation data to improve agents’ literature analysis and ideation (with Hit@10-style metrics).
- Tools/products/workflows: AgentEval: Ideation Hit@10 Benchmark; Lineage QA tasks; ablation of model choices (e.g., GPT-5 vs. GPT-5.2).
- Dependencies/assumptions: Dataset licensing compliance; domain generalization; careful prompt and reward design to avoid shortcut learning.
- Product strategy reframing workshops (sectors: software, finance, healthcare)
- What: Translate Gap-Driven Reframing into product roadmaps (turn failure modes into design constraints) and explore Representation Shift (change primitives, e.g., tokens-to-events).
- Tools/products/workflows: Reframe Workshop Toolkit; recipe checklists; PM-Engineer pairing sessions guided by “diagnose → reframe → validate” flows.
- Dependencies/assumptions: Cultural buy-in; mapping research patterns to product constraints; availability of evaluation datasets.
- Editorial analytics and venue strategy (sectors: publishing, academia)
- What: Tailor submissions to venue-specific preferences revealed by pattern distributions (e.g., ICML’s formal methods lean, ICLR’s representation emphasis).
- Tools/products/workflows: VenueFit Analyzer; pattern distribution dashboards by conference/year; submission brief generator.
- Dependencies/assumptions: Patterns remain stable enough for tactical use; authors maintain methodological integrity rather than gaming patterns.
Long-Term Applications
These applications require further research, scaling, standardization, or cross-domain expansion before broad deployment.
- Autonomous research agents that conduct end-to-end studies (sectors: academia, biotech, materials science)
- What: Agents that generate ideas from lineage graphs, plan experiments, run them on automated platforms, and iterate using “innovation recipes.”
- Tools/products/workflows: AutoPI (Principal Investigator Agent); lab automation integration (e.g., ELNs, robotics); closed-loop ideation–experiment cycles.
- Dependencies/assumptions: Reliable experiment execution; safety and compliance; robust scientific verification; compute and data access; strong human oversight.
- Funding foresight and portfolio optimization (sectors: policy/funders)
- What: Predict emerging research directions from predecessor constellations and pattern trends to allocate funds and design calls (e.g., incentivize Import + Adapt).
- Tools/products/workflows: Funding Foresight; trend simulation; recipe impact forecasts; scenario planning dashboards.
- Dependencies/assumptions: Longitudinal, multi-field datasets; fairness and bias mitigation; interpretable models acceptable to stakeholders.
- Early trend detection and risk monitoring for AI governance (sectors: policy, standards)
- What: Track Representation Shifts and Cross-Domain Synthesis to anticipate regulatory needs (e.g., new modalities, safety challenges).
- Tools/products/workflows: Trend Sentinel; policy alerts mapped to pattern spikes; standards working group briefs.
- Dependencies/assumptions: Broader coverage beyond ML; stable signal-to-noise; engagement with standards bodies.
- Cross-domain transfer engines for translational innovation (sectors: healthcare, robotics, energy)
- What: Systematically mine adjacent fields to recommend compatible mechanisms and design “compatibility layers” for adaptation.
- Tools/products/workflows: Idea Importer; Compatibility Layer Designer; cross-domain ontology mappings; validation sandboxes.
- Dependencies/assumptions: High-quality cross-domain ontologies; robust mapping of assumptions and constraints; domain expert validation.
- Creativity metrics and responsible research assessment (sectors: academia, institutions)
- What: Quantify innovation via pattern combinations (e.g., Reframe + New Primitive) for formative feedback and program evaluation.
- Tools/products/workflows: Creativity Index Dashboard; recipe diversity scores; longitudinal impact correlations.
- Dependencies/assumptions: Community acceptance; safeguards against metric gaming; alignment with qualitative peer judgment.
- Role-aware citation metadata standard in publishing (sectors: publishing, infrastructure)
- What: Journals adopt “predecessor role” and “relationship type” metadata, enabling machine-actionable citation intent across the scholarly ecosystem.
- Tools/products/workflows: RoleCite Standard; editorial tooling; APIs for repositories and indexers.
- Dependencies/assumptions: Standards development and adoption; retrofitting legacy content; legal and technical interoperability.
- Domain-general expansion beyond ML (sectors: all sciences and engineering)
- What: Extend Sci-Reasoning to biomedicine, physics, social sciences, and engineering with field-specific pattern refinements and multilingual support.
- Tools/products/workflows: Sci-Reasoning-Global; multilingual LLMs; field-calibrated taxonomies; cross-repository ingestion.
- Dependencies/assumptions: Full-text access across disciplines; domain adaptation of prompts; community validation in each field.
- Personalized “research path planner” for learners (sectors: education, workforce development)
- What: Map a learner’s interests to lineage graphs and suggest projects that exercise specific thinking patterns, building “innovation muscle.”
- Tools/products/workflows: Research Path Planner; portfolio tracking; recipe-based mentoring programs.
- Dependencies/assumptions: Privacy-preserving learner models; institutional buy-in; equitable access.
- Marketplaces for collaborative recipe refinement (sectors: academia–industry interfaces)
- What: Platforms where researchers share, remix, and test innovation recipes, with attribution and IP-safe exchange.
- Tools/products/workflows: RecipeHub; versioned recipe artifacts; sandboxed validation challenges.
- Dependencies/assumptions: Incentive design; IP frameworks; moderation and quality control.
Global assumptions and dependencies that affect feasibility across applications
- The Oral/Spotlight signal is a strong but time-bound proxy for “high quality”; broader impact may diverge and domain biases exist.
- LLM pipeline accuracy depends on long-context comprehension, prompt quality, and access to full texts; human verification remains important, especially for edge cases.
- The dataset currently covers ML (NeurIPS/ICML/ICLR, 2023–2025); generalization requires field-specific calibration and extended temporal coverage.
- Legal/IP and data governance considerations (full-text rights, patents, privacy) must be addressed for enterprise deployment.
- Pattern distributions and venue preferences can evolve; tools should refresh analyses and avoid prescriptive use that induces gaming.
Glossary
- Ablation study: A controlled comparison to assess the contribution or performance of components or models by systematically varying them. "Through a model ablation study comparing GPT-5.2, GPT-5, GPT-5-mini, and GPT-4.1 on predecessor extraction (Section~\ref{sec:model-ablation})"
- Cross-Domain Synthesis: A thinking pattern where ideas or mechanisms from one field are imported and adapted to another to create innovation. "Cross-Domain Synthesis is the second most common pattern (687 papers, 18.0\%),"
- Data/Evaluation Engineering: A research strategy focusing on designing datasets and evaluation protocols to improve rigor and measurement. "while growth in Data/Evaluation Engineering reflects the field's maturation toward rigorous empirical methodology."
- Frontier LLMs: The most advanced, state-of-the-art LLMs at the capability frontier. "A critical enabler of this approach is frontier LLMs' demonstrated capability to comprehend page papers"
- GPQA-Diamond: A benchmark dataset containing PhD-level science questions to evaluate advanced knowledge and reasoning. "GPQA-Diamond~\cite{rein2023gpqa} provides PhD-level science questions testing knowledge retrieval,"
- Hit@10: An evaluation metric indicating success if a correct item appears among the top 10 generated candidates. "We measure success using Hit@10: whether any of the 10 generated ideas matches the ground truth paper according to the LLM judge."
- Human-in-the-loop: A workflow design where humans intervene to validate or refine automated system outputs. "This human-in-the-loop approach concentrates expert attention on genuinely ambiguous cases (approximately 3\% of papers) while leveraging the complementary strengths of frontier LLMs for the majority of cases."
- Intellectual lineage: The chain of influence and conceptual inheritance linking a work to its key predecessors. "identifying high-quality papers, tracing their intellectual lineage, and articulating structured lineage graphs"
- LLM-accelerated pipeline: A processing pipeline that uses LLMs to automate and scale tasks. "while maintaining quality through our LLM-accelerated pipeline with human validation for quality assurance."
- LLM judge: Using a LLM as an evaluator to assess the quality or correctness of outputs. "according to the LLM judge."
- Lineage Graphs: A structured representation of how a target paper connects to predecessors, with annotated roles and relationships. "representing intellectual lineage as structured ``Lineage Graphs'' that combine rich natural language narratives with queryable annotations."
- Lineage Links: Annotated edges in a lineage graph describing the role and relationship between a predecessor and a target paper. "through structured ``Lineage Links'' that include predecessor roles, relationship types, and natural language descriptions of the reasoning process."
- Multi-model cross-validation: A validation method that compares outputs across multiple models to assess agreement and reliability. "we employ multi-model cross-validation with Claude Opus 4.5 and Google Gemini 3.0."
- Neural implicit functions: Continuous function representations learned by neural networks, often used for 3D shape or scene modeling. "such as replacing explicit meshes with neural implicit functions for 3D reconstruction."
- Oral/Spotlight: Select presentation categories at top ML conferences that signal high-quality, high-impact papers. "using a validation set of 77 Oral/Spotlight papers with ground-truth predecessors."
- Power law: A heavy-tailed distribution where a small number of events account for most effects, common in scientific and network phenomena. "while the distribution follows a power law with a long tail of specialized strategies"
- Progenitor index: A metric identifying the single most influential prior work for a given paper. "the progenitor index~\cite{jo2022see} identifies the single most influential prior work,"
- Publication Source Tracing: A formalized task of identifying the sources and influences behind publications. "PST-Bench~\cite{zhang2024pst} formalized ``Publication Source Tracing'' as a task,"
- Representation Shift: A thinking pattern involving changing the fundamental representation or primitives to simplify or reconceptualize the problem. "Representation Shift appears in 401 papers (10.5\%),"
- Research Knowledge Graphs: Knowledge graphs that encode entities and relationships in scientific research for machine-actionable analysis. "Research Knowledge Graphs~\cite{zloch2025research} provide machine-actionable representations of research relations."
- Retrieval-augmented generation: A technique where a model retrieves relevant documents to condition or guide text generation. "Systems like LitLLM~\cite{agarwal2024litllm} use retrieval-augmented generation for literature review,"
- Stratified sampling: A sampling method that divides a population into strata and samples from each to ensure balanced coverage. "We employ stratified sampling~\citep{patton2001qualitative} across conferences (NeurIPS, ICML, ICLR), years (2023--2025), and presentation types (Oral, Spotlight),"
- Synthesis Narrative: A structured, explanatory paragraph detailing how a target paper integrates ideas from predecessors. "Synthesis Narrative: An LLM-generated paragraph (200-400 words) explaining the intellectual synthesis that occurred."
- Thinking patterns: Recurring cognitive strategies that researchers use to generate and structure innovative contributions. "we identify 15 distinct thinking patterns---the cognitive strategies researchers employ to develop breakthrough ideas"
- Vision-language-action models: Models that jointly process visual, linguistic, and action modalities to enable integrated reasoning and control. "reinforcement learning from visual reasoning, vision-language-action models, and related AI systems have transformed what AI systems can accomplish"
Collections
Sign up for free to add this paper to one or more collections.

