- The paper introduces a unified model that fuses video, action, and language using a three-stream Mixture-of-Transformers with H-bridge attention.
- It leverages advanced training pipelines and inference optimizations to improve temporal dynamics perception and achieve over 50× acceleration in real-time robotic control.
- Experimental results demonstrate over 95% task success and rapid adaptation across heterogeneous robot platforms, highlighting its practical deployment potential.
MotuBrain: A Unified World Action Model for Robot Control
Introduction and Motivation
MotuBrain addresses fundamental limitations of Vision-Language-Action (VLA) policies in embodied robotics, which—despite strong semantic generalization—are often restricted by their reliance on static image-text data and lack fine-grained perception of temporal dynamics. The work targets a paradigm shift: leveraging the spatiotemporal priors and generative capabilities of modern video diffusion models to enhance the temporal comprehension and actionability of unified world models in robotics. MotuBrain builds upon advances such as UniDiffuser and the Mixture-of-Transformers (MoT) architecture, seeking to integrate multimodal information—video, actions, and language—in a tightly coupled, scalable, and data-efficient manner.
Architectural Overview
MotuBrain introduces a three-stream Mixture-of-Transformers architecture that fuses video, action, and language streams. It employs an H-bridge attention mechanism to support selective cross-modal interaction—applying joint attention predominantly in the model's intermediate layers, thus preserving modality-specialized representations in early and late layers while achieving efficient and semantically aligned cross-modal fusion.
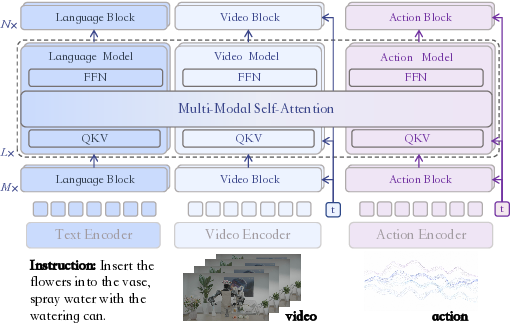
Figure 1: Overview of MotuBrain's architecture, highlighting the three-stream Mixture-of-Transformers and specialized H-bridge attention, as well as multiview input support via 3D RoPE offsets.
By integrating the UniDiffuser backbone, MotuBrain enables joint generative modeling over video and action modalities, supporting diverse inference tasks: vision-language-action policy regression, world modeling, video generation, inverse dynamics modeling, and joint prediction. This formulation allows for a broad spectrum of supervision signals (video only, action only, combined, heterogeneous robot embodiments), substantially enhancing data efficiency and generalization.
The multiview representation is achieved by independently encoding each camera view, with positional tokenization utilizing 3D RoPE-based view offsets, allowing for flexible, architecture-invariant visual input cardinality.
Training Methodology
The pre-training pipeline follows a hierarchical four-stage data pyramid: web-scale internet videos, egocentric manipulation videos, heterogeneous embodiment robot data, and high-fidelity, embodiment-specific control sequences. This strategy maximizes downstream data efficiency, bridges semantic gaps between open-world visual data and embodiment-specific manipulation, and allows rapid adaptation to novel robots with minimal same-embodiment data.
Pre-training is two-staged: the video stream is adapted first on broad, egocentric and heterogeneous-embodiment data (freezing the action branch), followed by action-branch adaptation (freezing the video branch) with unified action representations across embodiments, using a relative end-effector coordinate normalization. This provides direct transferability across robot platforms.
Attention masking and sequence factorization differ across training stages. Non-autoregressive post-training denoises the full observation window jointly; autoregressive post-training factorizes over temporally staged chunks, utilizing block-causal masking. V2A-style attention disables video-to-action attention at inference, enabling efficient action decoding without explicit video generation.
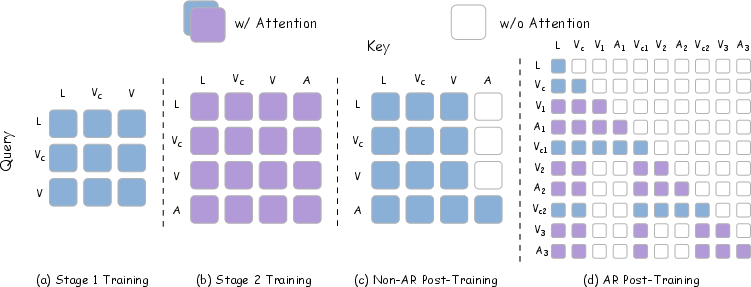
Figure 2: Visualization of attention masks across pre-training and post-training stages, reflecting differences in supervision and sequence modeling paradigms.
Inference and System Optimizations
Inference with world action models typically presents acute challenges in computational latency, especially with simultaneous high-dimensional video and action denoising. MotuBrain implements a stack of optimizations:
- SNR-based noise sampling and timeshifted training schedulers to robustify to noisy visual contexts and reduce inference steps without quality loss.
- Torch.compile-based graph optimization and FP8 quantization for efficient computation, targeting large transformer layers.
- DreamZero-style DiT caching exploits denoising redundancy, skipping evaluations when subsequent velocity predictions remain similar, reducing wasteful computation.
- V2A inference: action tokens continue to update after an initial joint denoising prefix, leveraging cached video/text representations.
- Action chunk smoothing and frequency-aware interpolation for execution smoothness and velocity preservation.
- Real-time control adaptation: asynchronous decoupling of inference and action loops, with intelligent chunk fusion to avoid discontinuities under variable latencies.
Collectively, these achieve over 50× acceleration relative to naive deployment, reaching 11 Hz inference rates, thus enabling real-time closed-loop deployment.
Experimental Results
Simulation Benchmarks: RoboTwin 2.0
MotuBrain outperforms all evaluated VLA baselines and world model counterparts on RoboTwin 2.0, achieving 95.8% (clean scenes) and 96.1% (randomized scenes) average success rates, with pronounced advantages on temporally extended, multi-stage, and visually varied tasks.
Key findings:
- MotuBrain is the only model achieving >95% average success rate under randomized evaluation, leading on 44 out of 50 tasks.
- Data and task scaling experiments demonstrate strong monotonic improvement with more tasks and demonstrations, exceeding VLA models in both scaling and sample efficiency.
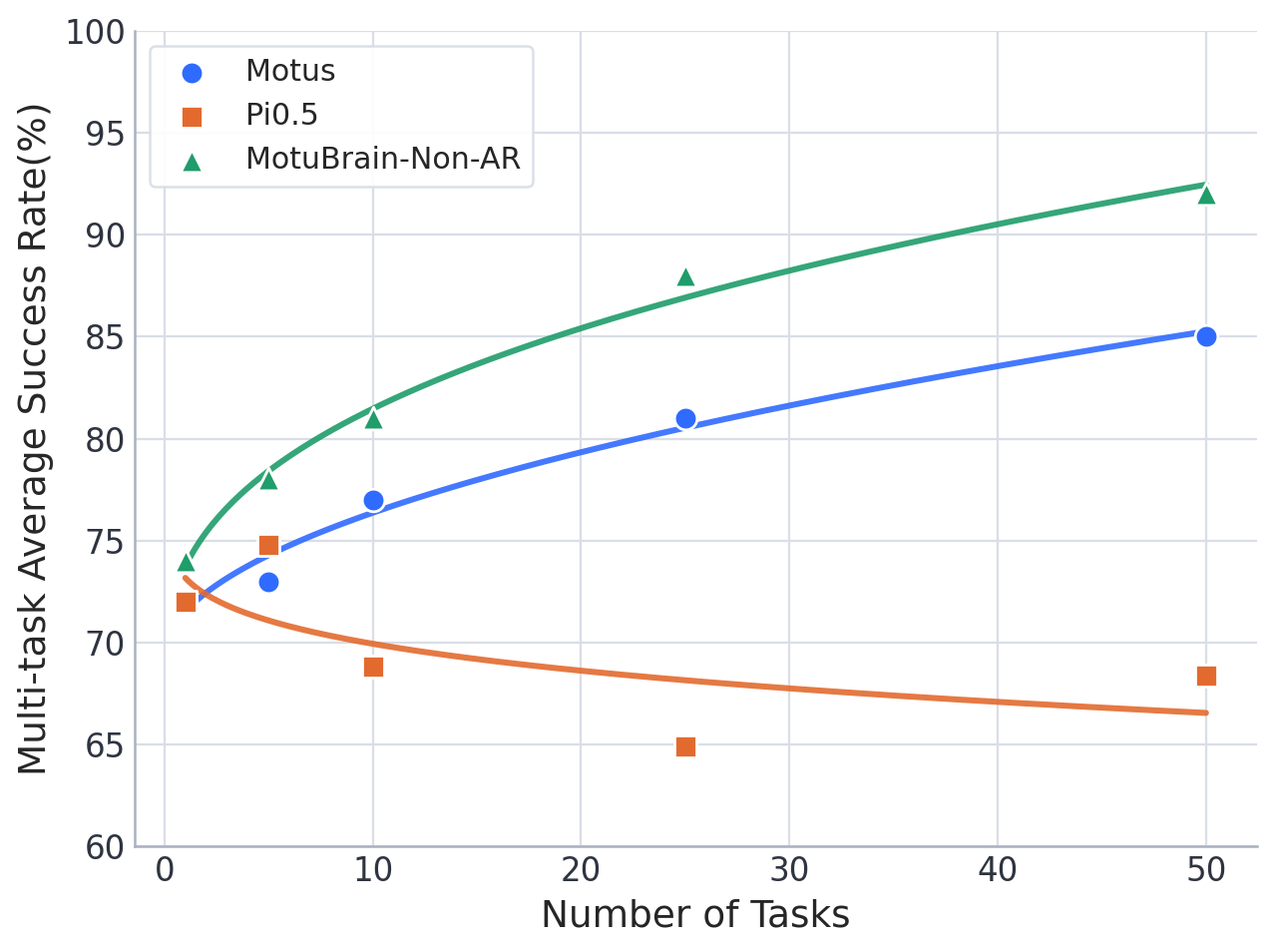
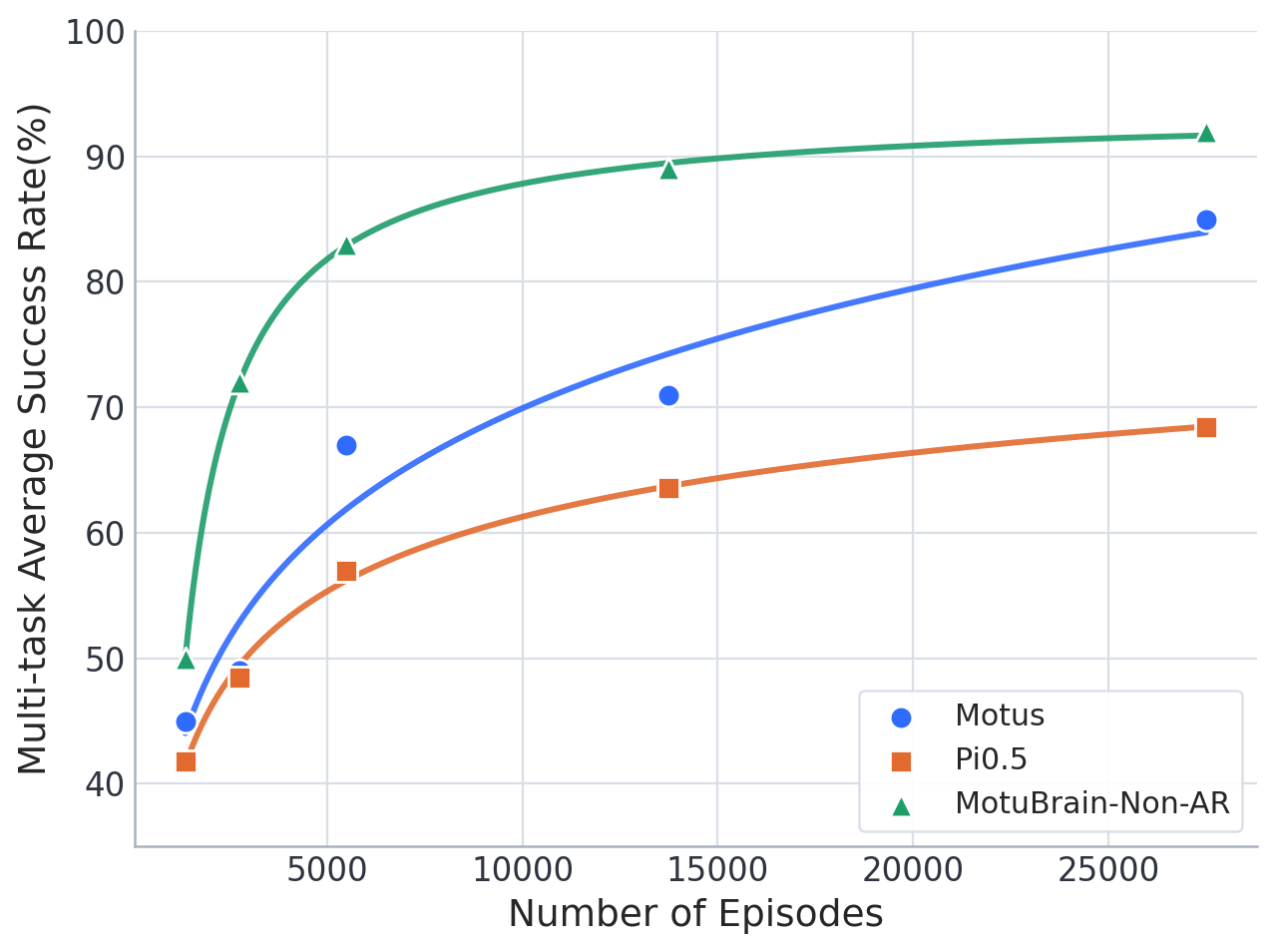
Figure 3: Task scaling curve demonstrates MotuBrain's improved success rate and stronger scaling behavior as the number of tasks increases.
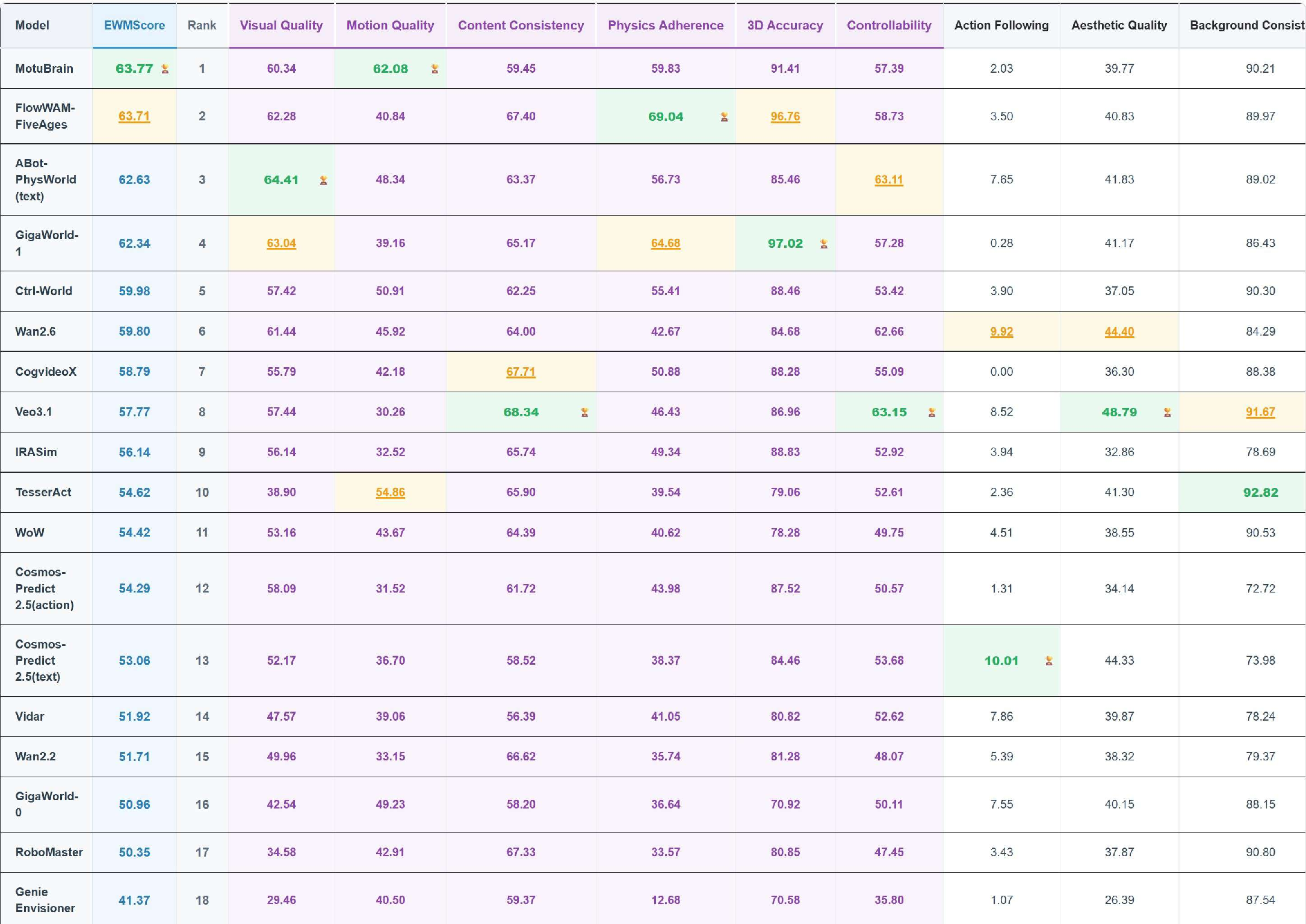
Figure 4: Data scaling curve shows continued policy improvement as additional demonstration data is provided, highlighting robustness to data scale.
World Model Evaluation: WorldArena
On the WorldArena benchmark, MotuBrain obtains the highest EWMScore across all public embodied world models and video generation baselines (EWMScore: 63.77). The model ranks first in motion quality metrics (Flow Score, Motion Smoothness, Dynamic Degree), indicating it generates perceptually compelling and physically plausible predictions without trivial static collapse or motion degradation.
(Figure 5)
Figure 5: MotuBrain ranks first on the WorldArena public leaderboard (EWMScore), excelling particularly in motion quality and physics adherence sub-metrics.
Crucially, MotuBrain bridges the typical gap between perceptual and functional utility: it achieves both high visual fidelity and actionable dynamics, correlating well with downstream policy success.
Real-World Deployment and Adaptation
Empirical trials across multiple humanoid platforms show MotuBrain can rapidly adapt to novel embodiments within 50–100 demonstration trajectories. The same world-action backbone is used for diverse household tasks, including long-horizon, bimanual manipulation (e.g., cocktail mixing, flower arrangement) with minimal retraining and without auxiliary planners or task decomposition heuristics.
Quantitative metrics indicate robust performance on extended multi-step tasks, with high normalized execution scores and successful self-correction in the presence of execution errors. Qualitative demonstrations highlight adaptability to unseen objects and environments, bimanual asynchrony, and scene generalization.
Implications and Future Directions
The results demonstrate that unified world-action modeling—wherein world prediction and action generation are jointly trained—offers substantial benefits over decomposed VLM+IDM or VLA paradigms. The integration of massive, heterogeneous multimodal datasets and scalable transformer-based designs results in high robustness to environmental stochasticity, strong transferability across embodiments, and a practical path toward high-performance closed-loop robotic deployment.
Key theoretical implications include the confirmation that direct joint modeling preserves critical physical priors and enables richer cross-task knowledge reuse than traditional imitation or sequential predictor approaches. On the practical side, MotuBrain's runtime and architecture optimization pipeline demonstrates that scaling world-action models no longer needs to be bottlenecked by inference latency.
Promising future research directions include:
- Further reducing the same-embodiment data requirement for adaptation via improved pretraining or meta-learning.
- Integrating enhanced uncertainty modeling and explicit long-term memory for robust open-world deployment.
- Extending the model to non-manipulation skills, tactile sensing, and dynamic multi-agent settings.
Conclusion
MotuBrain represents a mature instantiation of the unified world-action model paradigm, advancing both the algorithmic and systems aspects of embodied policy learning. By tightly integrating video prediction, action generation, and semantic instruction following in a highly scalable architecture, it achieves state-of-the-art performance on both perceptual and functional robotics benchmarks, while remaining deployable in real-world settings with realistic latency constraints. The work substantiates the argument for joint world-model/action-model learning as a scalable path forward for robust, generalist robotic control.