- The paper introduces REBENCH, a benchmark that standardizes LLM evaluation on binary reverse engineering tasks such as name recovery and type inference.
- It employs a normalization pipeline with decompilation, abstraction, and deduplication to mitigate biases from decompiler inconsistencies and redundant code.
- Experimental findings show low F1 scores across architectures, highlighting the limitations of current LLMs and the need for specialized training on binary data.
REBENCH: A Procedural, Fair-by-Construction Benchmark for LLMs on Stripped-Binary Types and Names
Motivation and Contribution
The absence of a standardized, widely accepted evaluation benchmark has impeded progress in applying LLMs to binary reverse engineering tasks such as symbol name recovery and type inference. The heterogeneity of earlier datasets, inconsistencies in evaluation criteria, and the limitations of decompiler-generated ground truth have limited fair and systematic assessment of advances. The paper presents REBENCH, which addresses these challenges by introducing a large-scale, meticulously normalized, and extensible benchmark, supporting rigorous evaluation of both type inference and name recovery in stripped binaries over multiple architectures (x86, x64, ARM, MIPS) and optimization levels.
By consolidating and filtering datasets from prior work, REBENCH incorporates nearly 30 million decompiled lines of code for just the x64 architecture at O0 optimization, ensuring ample diversity and realism. The procedural generation of evaluation targets through knowledge-base-driven abstraction at the byte-stack level guarantees that both ground truth integrity and task difficulty are retained.
Dataset Design and Normalization Pipeline
REBENCH begins by filtering open-source C/C++ projects that are widely recognized, free of redistribution restrictions, and commonly used in binary analysis research. Selected code is compiled for multiple architectures and with various compiler optimizations. Each project undergoes dual compilation: (1) debugging-symbol-enriched binaries are used to assemble a comprehensive knowledge base (KB) mapping symbols and types to specific stack and heap offsets; (2) fully stripped binaries represent the real-world targets for downstream reverse-engineering evaluation.
A core aspect is the normalization pipeline, converting code to a universal format through decompilation, symbol abstraction, and placeholder substitution (e.g., VAR1, TYPE1). This transformation is guided by mappings in the KB, linking each abstracted identifier to its original semantic label. This process is illustrated in the normalization workflow.

Figure 1: The prompt used to instruct LLMs on type and name inference over placeholder-filled code.
Special attention is given to resolving ambiguities when decompilers diverge in variable recovery and representation for code with and without debug information. This byte-level KB enables faithful, bias-preventing ground truth, unaffected by decompiler idiosyncrasies or symbol leakage.
To avoid data leakage and redundancy, functions duplicated across projects or resulting from common library calls are pruned through code-similarity-based deduplication. Trivial and external functions are identified via heuristics (e.g., minimum line counts) and eliminated, focusing on substantial code with semantic depth.
Benchmarking Tasks and Evaluation Metrics
REBENCH supports multiple reverse engineering tasks:
- Function name recovery and variable name recovery: Predicting semantically meaningful labels for functions or variables based on stripped pseudocode.
- Type inference: Restoring full type information (primitive/composite types) for all decompiler-discovered variables and stack symbols.
- Extended applications include data structure re-aggregation, function similarity search, and control flow graph recovery.
REBENCH employs rigorous evaluation metrics. Type inference is assessed with strict exact type matching due to the critical C semantics distinctions (e.g., unsigned vs. signed integer types). Name recovery leverages semantic-aware scoring modeled on CodeWordNet—a resource mapping synonyms and sub-token similarity—rather than limiting to syntactic matches. This approach credits functionally synonymous predictions, addressing the known low collision rate in identifier naming among developers and the diversity of software idioms.
Experimental Findings
A suite of open-source LLMs specialized for code—including CodeLlama, Llama2, WizardCoder, DeepSeek-R1, Qwen2.5, Qwen3, and Phi4 Unsloth—are systematically benchmarked. Prompting follows a unified format across all models (Figure 1), ensuring comparability, with only template-wrapping adapted as required by model tokenizer conventions.
Numerical Results: Name Recovery and Type Inference
Function Name and Variable Name Recovery
For both tasks, all models exhibit consistently low F1 scores across architectures, with modest improvements for 2024–2025 LLMs such as Qwen2.5, Qwen3, and Phi4 Unsloth. The F1 for function name recovery typically peaks in the 0.1–0.15 range for the best models on x86/x64, but remains substantially lower for ARM and MIPS.
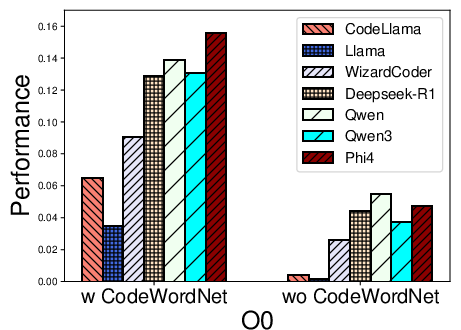
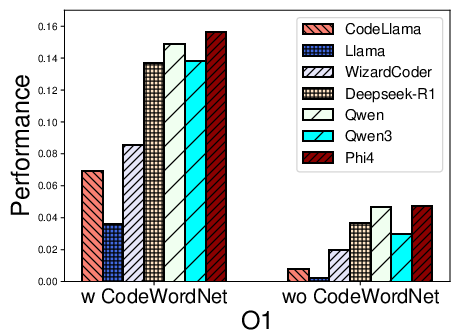
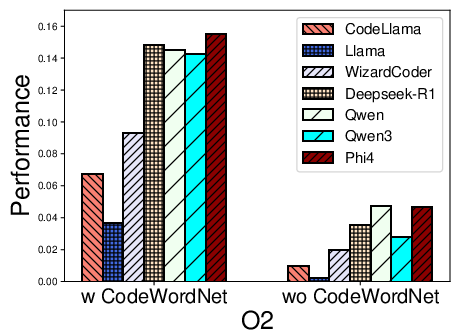
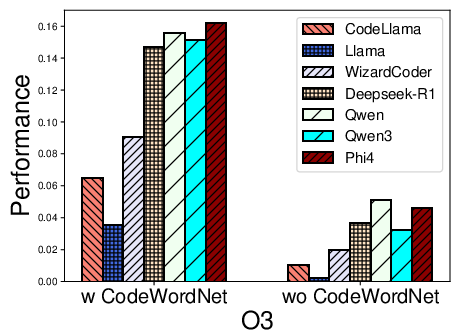
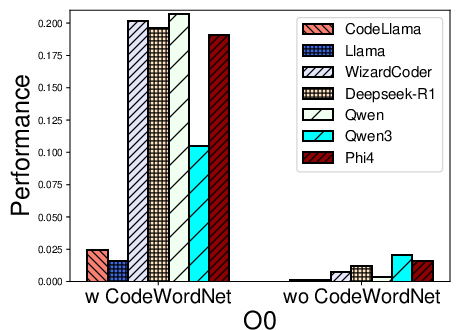
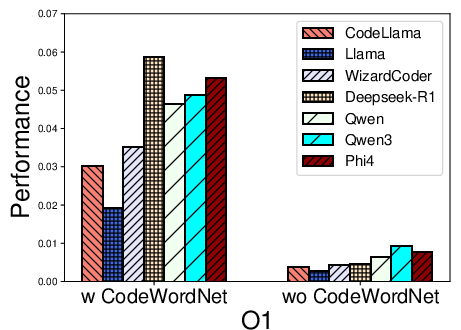
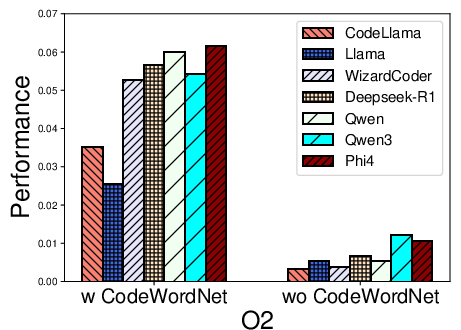
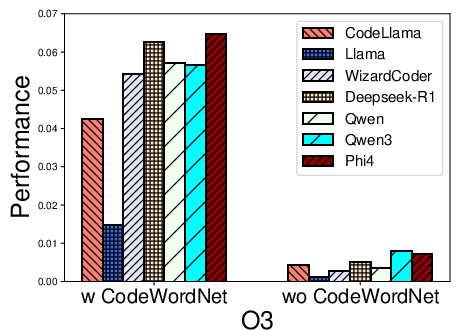
Figure 2: Performance distribution for function name recovery across architectures and optimization levels for multiple LLMs using REBENCH.
Figure 3: F1 score comparison for variable name recovery, revealing marked variability with architecture and compiler optimization, and a sharp performance drop at higher optimization levels.
Key findings:
- Name recovery on x86 outpaces that on ARM and MIPS, likely reflecting LLM pretraining biases (x86 predominance).
- Variable name recovery generally yields lower F1 than function names, reflecting the compounded challenge of local context and higher naming entropy for variables.
- Optimization levels O1–O3 cause marked decreases in F1, particularly for variable recovery, illustrating the obfuscatory effect of compiler transformations on both semantic preservation and code regularity.
Type Inference
Type inference is markedly more challenging: no LLM achieves F1 above 0.04 for most architectures and optimization settings. This underscores the acute limitations of current pretraining in capturing C/C++ low-level memory semantics and program dataflow.
Impact of Model Training, Architecture, and Evaluation Method
- CodeWordNet-based semantic evaluation proves indispensable: disabling it drops F1 scores on name tasks by more than an order of magnitude, showing LLMs can often produce functionally relevant—if not lexically matching—identifiers.
- Model scaling within one family (CodeLlama 7B, 13B, 34B) delivers inconsistent improvements, reinforcing that parameter count alone insufficiently compensates for weak training distributional overlap with binary reverse engineering tasks.
- Model generation date (i.e., exposure to more recent training datasets including decompiled code) leads to incremental, not radical, performance improvement.
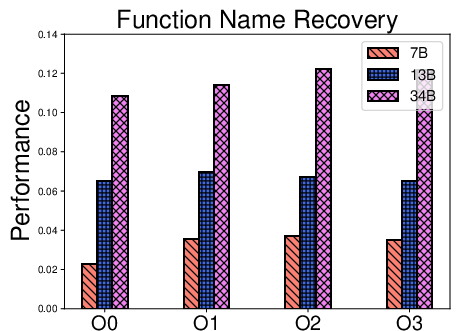
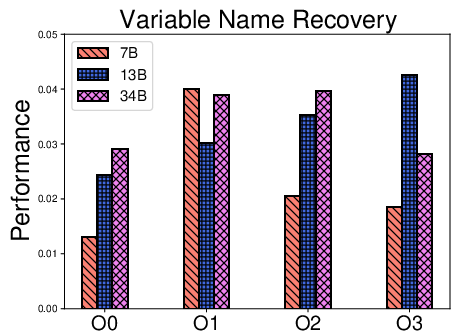

Figure 4: F1 score variations across CodeLlama model sizes for function name, variable name, and type recovery, indicating diminishing returns from model scaling.
- Real-world firmware experiments expose severe generalization limitations: models achieve only marginally higher F1 for variable name recovery, and virtually zero for function names or types, especially when evaluated on decompiler output (IDA Pro vs. Ghidra) not present in fine-tuning.
Practical and Theoretical Implications
REBENCH, by eliminating pipeline and metric inconsistencies, sets a new standard for fair LLM evaluation in binary analysis. The study's results highlight several critical implications:
- LLMs pre-trained on source code and documentation—even when fine-tuned—remain inadequate for robust, cross-architecture, semantically rich reverse engineering on stripped binaries, especially under realistic optimization and decompiler heterogeneity.
- Significant improvements will require pretraining (and possibly architecture changes) targeting stripped/decompiled code distributions, rigorous incorporation of compiler transformation semantics, and perhaps hybridization with static or dynamic program analysis.
- Semantics-aware, domain-specific evaluation resources (CodeWordNet) are vital for meaningful progress metrics in program understanding tasks.
Open problems remain for type inference, data structure (re-)construction, and supporting binary formats (e.g., with heavy obfuscation or unconventional optimizations).
Future Directions
The authors propose to:
- Expand REBENCH to incorporate additional reverse engineering challenges (memory corruption detection, control-flow integrity, binary similarity).
- Develop advanced, semantics-driven deduplication to further minimize data leakage risks.
- Maintain a living benchmark with real-world firmware, additional decompiler support (IDA Pro, angr), and continual updates to reflect evolving binary analysis practice.
The lessons from this work extend to any application of foundation models in software security, indicating that transfer from source-centric pretraining is neither robust nor sufficient where semantics, not syntax, drive the critical evaluation objectives.
Conclusion
REBENCH provides an essential infrastructure for the empirical, rigorous, and fair evaluation of LLMs in reverse engineering of stripped binaries, exposing the acute current limitations of state-of-the-art code LLMs in identifier and type recovery. The benchmark’s principled design and extensiveness set a high bar for future comparative research, and the findings illuminate both the difficulties in translating LLM source code abilities to the binary domain and the imperative for new, more specialized model development and evaluation standards.