- The paper introduces How2Bench, a comprehensive 55-criteria guideline that enhances the design, construction, evaluation, analysis, and release of code-related benchmarks for LLMs.
- It reviews 274 existing benchmarks to identify common pitfalls in data quality, reproducibility, and transparency.
- The work emphasizes rigorous evaluation practices and open-source release to standardize and improve benchmark development in software engineering.
The paper "How Should We Build A Benchmark? Revisiting 274 Code-Related Benchmarks For LLMs" provides a comprehensive framework named How2Bench, which consists of a 55-criteria checklist to guide the development of high-quality, reliable, and reproducible benchmarks specifically tailored for LLMs in code-related tasks. It offers an exhaustive review and evaluation of 274 existing benchmarks to identify common pitfalls and best practices.
Introduction
The advent of LLMs has transformed several domains, including software development and programming tasks, with various benchmarks proposed to evaluate their capabilities. Benchmarks serve as essential tools for assessing LLM performance across diverse tasks such as code generation, program repair, defect detection, and more. However, many existing benchmarks suffer from issues related to data quality, reproducibility, and transparency.
This paper introduces How2Bench, a guideline that outlines necessary criteria across five phases of benchmark development (design, construction, evaluation, analysis, and release) in order to produce benchmarks that accurately measure LLM capabilities.
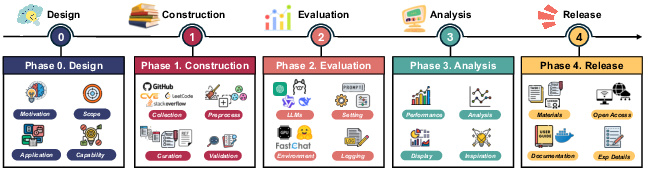
Figure 1: Lifecycle of Benchmark Development.
Benchmark Design
In the design phase, benchmarks should clearly define the intended scope, target capabilities, and application scenarios. This involves ensuring the benchmark fills a significant gap in existing research and specifying precise capabilities being evaluated, such as intention understanding or debugging capabilities.

Figure 2: Guideline for Benchmark Design.
Benchmark Construction
The construction phase emphasizes traceability and quality of data sources, rigorous preprocessing for cleanliness, and validation of data representativeness. Key practices include deduplication, manual and automated checks for data quality, and ensuring that test oracles, such as code execution or test case validation, are reliable.

Figure 3: Guideline for Benchmark Construction.
Benchmark Evaluation
Evaluation processes should involve assessing a diverse array of LLMs and validating prompt configurations to ensure comprehensive comparison. Recording the experimental environment and repeating evaluations helps ensure reproducibility and minimize the effects of random variations.
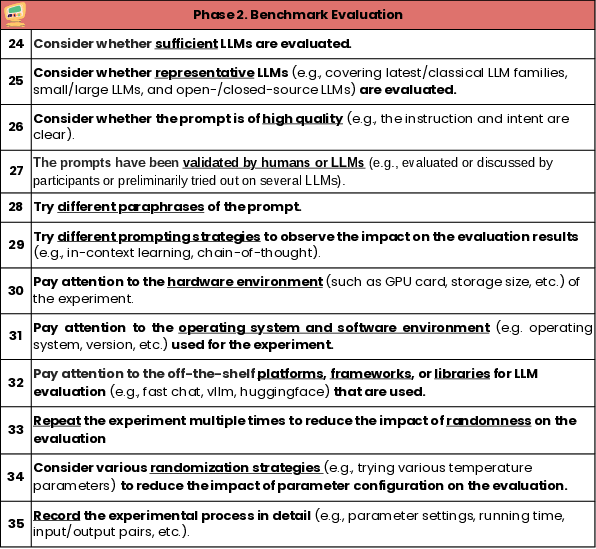
Figure 4: Guideline for Benchmark Evaluation.
Evaluation Analysis
Analyses should incorporate multiple perspectives, including difficulty, stability, and differentiability of benchmarks, accompanied by clear and effective visualizations of results. Benchmarks should provide comprehensive interpretations of experimental findings to guide future research.
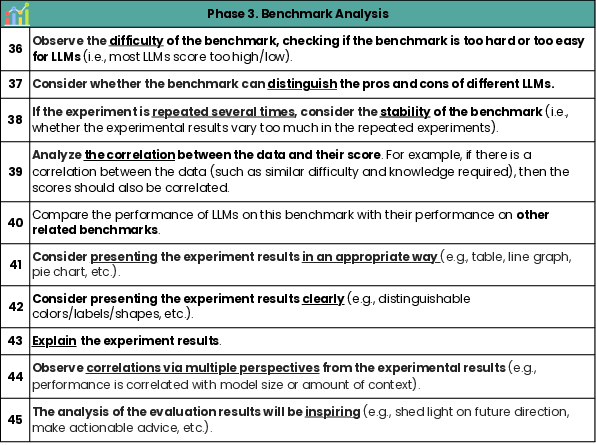
Figure 5: Guideline for Evaluation Analysis.
Benchmark Release
Finally, the release phase underscores the importance of open-sourcing benchmarks and ensuring all data, scripts, and documentation are openly accessible. Key considerations include removing sensitive information, providing comprehensive user manuals, and ensuring experimental details are replicable.
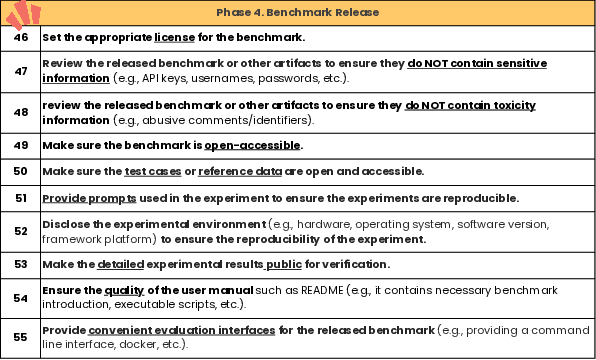
Figure 6: Guideline for Benchmark Release.
Conclusion
How2Bench offers a structured approach to improve benchmark quality, transparency, and reliability, thereby fostering more robust evaluation of LLMs in code-related tasks. By adhering to these guidelines, benchmark developers can contribute to advancing the standardization and effectiveness of evaluations in software engineering research, ultimately enhancing the credibility and utility of LLMs in practical applications.

