Co-Evolving Policy Distillation
Abstract: RLVR and OPD have become standard paradigms for post-training. We provide a unified analysis of these two paradigms in consolidating multiple expert capabilities into a single model, identifying capability loss in different ways: mixed RLVR suffers from inter-capability divergence cost, while the pipeline of first training experts and then performing OPD, though avoiding divergence, fails to fully absorb teacher capabilities due to large behavioral pattern gaps between teacher and student. We propose Co-Evolving Policy Distillation (CoPD), which encourages parallel training of experts and introduces OPD during each expert's ongoing RLVR training rather than after complete expert training, with experts serving as mutual teachers (making OPD bidirectional) to co-evolve. This enables more consistent behavioral patterns among experts while maintaining sufficient complementary knowledge throughout. Experiments validate that CoPD achieves all-in-one integration of text, image, and video reasoning capabilities, significantly outperforming strong baselines such as mixed RLVR and MOPD, and even surpassing domain-specific experts. The model parallel training pattern offered by CoPD may inspire a novel training scaling paradigm.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching one big AI model to be good at several different skills at the same time—like solving math problems using text, understanding images, and making sense of videos—without losing quality in any one skill. The authors introduce a new training method called Co-Evolving Policy Distillation (CoPD) that helps different “expert” models learn from each other while they are still training, so their knowledge can be combined smoothly into one strong, all-in-one model.
What questions did the researchers ask?
They asked three main questions:
- Why do current training methods struggle when teaching one model many different skills at once?
- How can we make “distillation” (a method where a strong teacher model guides a student model) more effective so the student really absorbs the teacher’s knowledge?
- Can we design a training process where multiple experts learn in parallel and share knowledge continuously, so the final model gets great at text, image, and video reasoning all together?
How did they do it?
To understand the method, it helps to know two existing ideas:
- RLVR (Reinforcement Learning with Verifiable Rewards): Think of this as practice with an automatic checker. The model tries answers; a checker tells it if they are correct, and the model improves based on that feedback. This works well for building one specific skill.
- OPD (On-Policy Distillation): Think of this as a teacher model watching a student’s work and guiding it token-by-token (word by word) along the student’s own path. This transfers knowledge from the teacher to the student.
What goes wrong with the usual approaches?
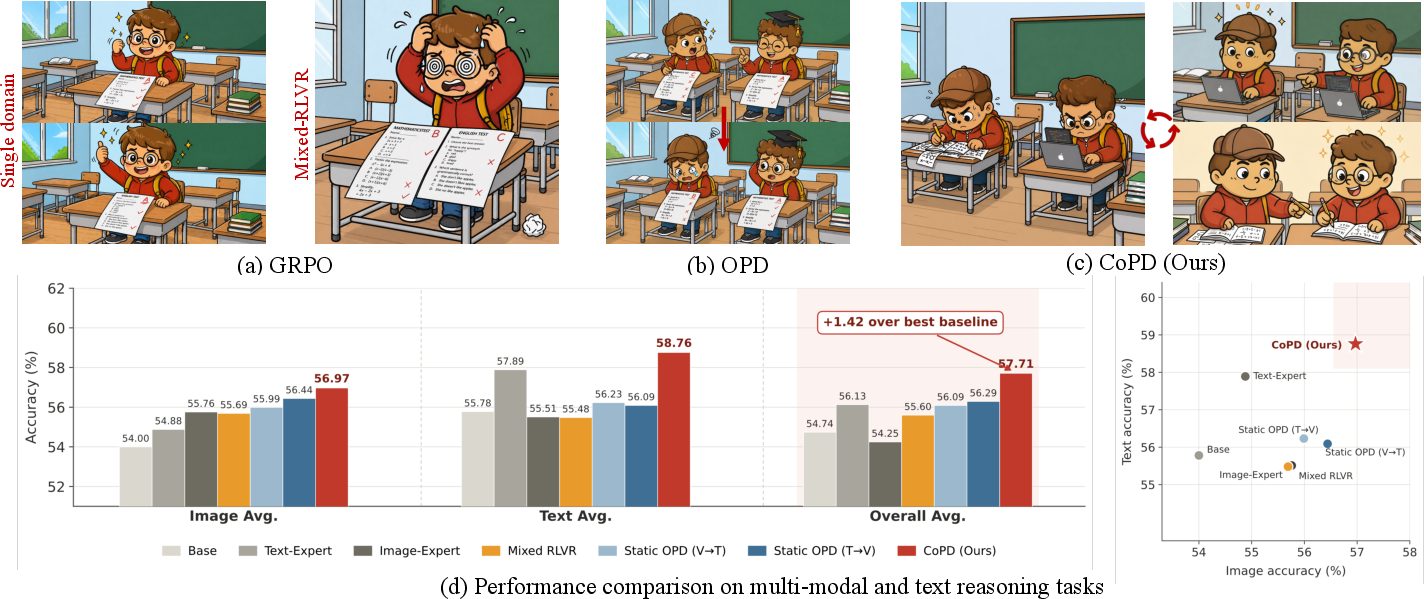
- Mixed RLVR (training on all skills at once): This is like pulling in different directions during a tug-of-war. When the model trains on mixed text, image, and video tasks together, the updates for one skill can clash with the others. The result: improving one skill can make another worse (a trade-off).
- Static OPD (train experts first, distill later): If experts are trained separately until they become very specialized, the way they “think” can be too different from the student’s way. That’s like a teacher speaking a very advanced language the student doesn’t understand. The guidance becomes hard for the student to absorb, and much of the expert’s knowledge doesn’t transfer.
A simple measure: “behavior overlap”
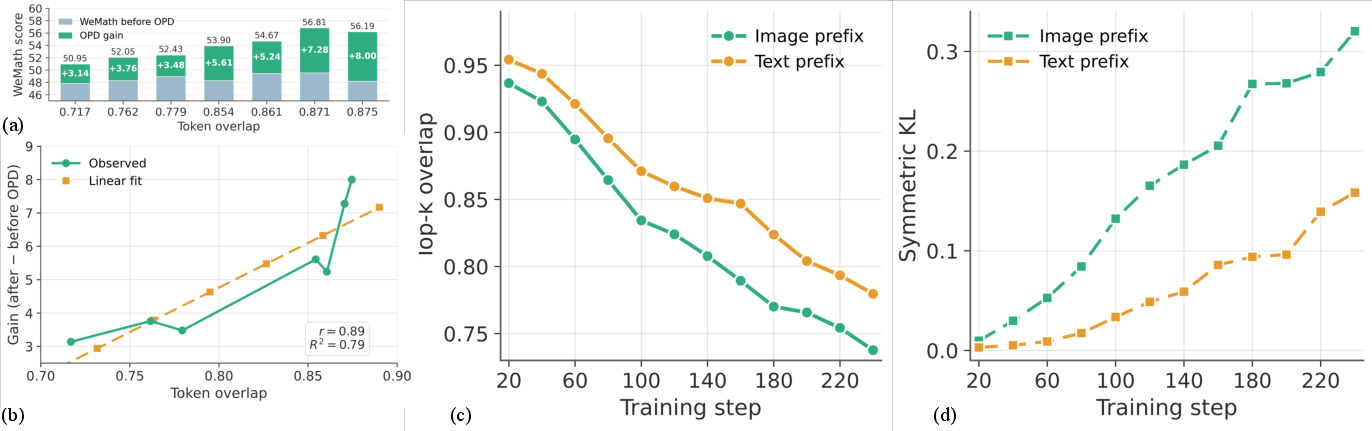
The authors propose measuring how similar a teacher and student “behave” during generation using “top‑k token overlap.” Imagine both the teacher and student listing their top 10 next-word choices at each step. If lots of those choices overlap, their behavior is similar; if not, they think very differently. The paper shows that distillation works best when teacher and student have moderate overlap—not too far apart, not too identical.
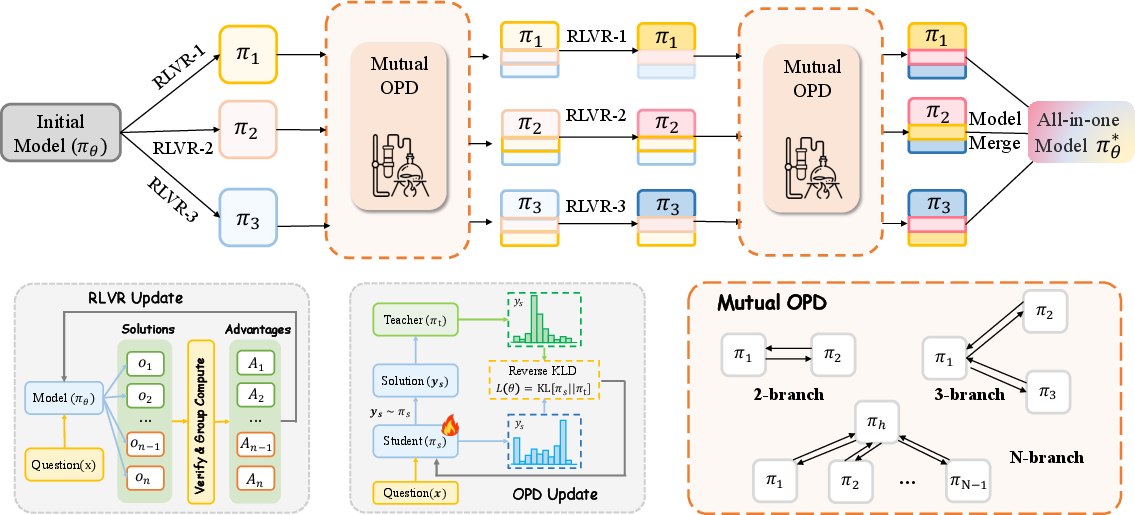
The CoPD method: co-evolve teachers and students
CoPD trains multiple branches (each focused on a skill like text, image, or video) in parallel and lets them continuously teach each other. Training alternates between two phases:
- RLVR phase: Each branch practices its own skill with the automatic checker, becoming more specialized and discovering new knowledge.
- Mutual OPD phase: The branches take turns being teacher and student. Each one generates answers on the other branch’s data, and the other branch provides token-level guidance. Because they are trained in parallel and regularly aligned, their behavior stays similar enough for the guidance to be absorbed.
This rhythm creates a healthy cycle:
- RLVR pushes branches apart just enough to learn new, useful stuff.
- Mutual OPD pulls them back together so they can share that new stuff effectively.
At the end, because the branches never drift too far, their parameters can be merged to form a strong, unified model.
What did they find?
The authors tested CoPD on building a single model with text, image, and video reasoning capabilities. They compared it against several baselines:
- Training everything together with mixed RLVR (the tug-of-war approach)
- Training separate experts and then doing one-way distillation (static OPD)
- Distilling from multiple teachers at once (MOPD)
Their results show:
- CoPD consistently beats mixed RLVR and static OPD/MOPD across many benchmarks.
- CoPD often surpasses the individual, domain-specific experts themselves, which is unusual—normally a unified student model is weaker than the specialized experts.
- CoPD scales well: it works not just for two branches (text and image) but also for three branches (text, image, and video).
They also did a pilot study confirming that:
- Distillation is more effective when the teacher and student behave similarly (higher top‑k token overlap).
- Standard separate expert training makes the teacher drift far from the student, which reduces overlap and makes distillation less effective.
- CoPD keeps the overlap in a “sweet spot,” allowing more knowledge to be transferred.
Why does this matter?
This research suggests a better way to build general-purpose AI models that can handle many kinds of tasks without sacrificing quality. Instead of training experts separately and trying to combine them at the end, CoPD lets experts learn and teach each other while they train. This reduces conflicts, improves knowledge sharing, and produces stronger all-in-one models.
Potential impacts:
- More capable multimodal AI: A single model that’s good at text, image, and video reasoning could be much more useful in the real world.
- New training “scaling” paradigm: Training multiple branches in parallel and letting them co-evolve might become a standard way to grow models’ capabilities.
- Better efficiency: Keeping teacher and student behavior aligned means distillation signals are easier to absorb, so we waste less training effort.
In short, CoPD turns skill trade-offs into mutual gains, helping build smarter, more versatile AI systems.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, grouped to guide concrete follow-up research.
Theoretical understanding
- Lack of a formal link between behavioral overlap and absorption efficiency: the paper posits an absorption function η(𝒪) and shows empirical correlation with top-k overlap, but provides no theoretical characterization of η(𝒪), its monotonicity range, or conditions under which it fails.
- Overlap metric choice is unvalidated theoretically: top-k token overlap is used as the sole indicator of “behavioral proximity,” without analysis of when it better predicts OPD gains than alternatives (e.g., probability mass overlap, Jensen–Shannon divergence, pathwise KL, trajectory-level FID, or state-visitation distances).
- No derivation of stability/convergence guarantees: CoPD alternates RLVR and OPD but lacks analysis of convergence properties, fixed points, or conditions preventing oscillations/collapse of branch diversity.
- Absorbable-range not quantified: the “moderate overlap” regime is qualitatively described but no principled target band (e.g., 𝒪∈[𝒪_min, 𝒪_max]) or control mechanism is specified or justified.
Algorithmic design and training dynamics
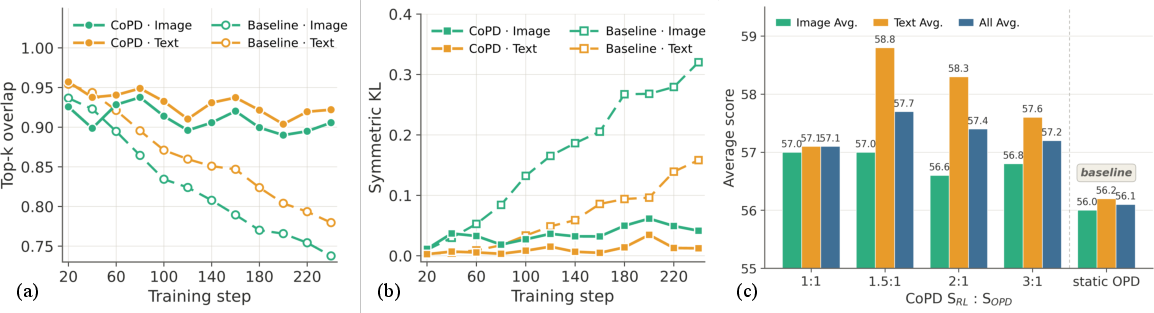
- No adaptive controller to regulate overlap: the schedule (S_RL vs S_OPD) is fixed; there is no mechanism to detect and maintain overlap near a target range (e.g., feedback control adjusting phase lengths or β_k dynamically).
- Sensitivity to hyperparameters is underexplored: the impact of k in top-k overlap, β_k (distillation weight), rollout temperatures, clipping thresholds, and OPD/RL loss mixing ratios is not systematically studied.
- Risk of capability collapse with excessive OPD: while warned conceptually, there is no empirical study quantifying at what OPD intensity or schedule branches lose complementary knowledge.
- Distillation target design is narrow: OPD uses token-level log-prob differences on the student’s on-policy trajectories; it remains unknown whether other targets (e.g., full KL on teacher’s trajectories, value/advantage heads, hidden-state matching, reasoning chain supervision) yield better transfer.
- Interaction between RLVR and OPD gradients is opaque: the paper interleaves objectives but does not analyze gradient interference, credit assignment across phases, or how to mitigate conflicting gradients (e.g., through orthogonalization or adaptive weighting).
- Off-policy effects not addressed: teachers evaluate tokens on student rollouts; there is no investigation of importance weighting or corrections if teacher and student policies diverge substantially on some states.
- Hub-and-spoke multi-branch design is heuristic: the hub choice (text branch) is justified intuitively; there’s no criterion or empirical analysis of hub selection, alternative topologies (ring, fully-connected), or dynamic hub reassignment.
- Parameter merging is underspecified: “simple parameter merging” is claimed to suffice without detailing the merge rule (e.g., weighted average, layer-wise gates, Fisher-weighted merging), its robustness to larger divergences, or failure cases.
Scalability and systems considerations
- Compute and communication overheads are unreported: CoPD trains K parallel branches and alternates phases, but there is no accounting of wall-clock time, GPU-hours, memory footprint, or inter-branch communication cost relative to mixed RLVR or (M)OPD.
- Staleness and asynchrony are unexamined: the method implicitly assumes synchronized branches; effects of asynchronous updates, stale teachers, or delayed parameters in real distributed settings are not studied.
- Scaling beyond three branches is unclear: while a hub-and-spoke is proposed, there is no empirical evaluation of K>3, the cost/benefit as K grows, or how overlap and absorption behave with many heterogeneous experts.
- Data/step budgeting fairness under scaling: although total steps are matched in two/three-branch setups, it’s unclear how budgets should be normalized across K and whether CoPD remains sample-efficient at larger scales.
Experimental scope and evaluation
- Limited model diversity: results are primarily on Qwen3-VL-4B; it remains unknown whether gains hold for larger/smaller backbones, different architectures (e.g., Llama, Mistral, DeepSeek), or pure-text LLMs vs VL/VL-video models.
- Domain generality not shown: evaluation focuses on math-oriented text, image, and video reasoning; transfer to other domains (e.g., coding, scientific QA beyond math, multi-turn agents, speech/audio, multilingual tasks) is unexplored.
- Overlap–gain correlation validated narrowly: the pilot study demonstrates correlation on a single task choice and with k=10; robustness across datasets, domains, k values, and alternate similarity metrics is not validated.
- Lack of error/behavior analysis: the paper reports accuracies but does not analyze failure cases, error shifts per domain, or whether CoPD improves reasoning faithfulness, calibration, or chain-of-thought consistency.
- No statistical significance reporting: improvements are reported without variance across seeds, confidence intervals, or significance tests, making robustness of gains uncertain.
- Benchmark coverage gaps: cross-modal, tightly coupled tasks (requiring integrated video–text–image reasoning in a single instance) and real-world/interactive settings are limited or absent.
- Reward function descriptions are high-level: verifiable rewards are assumed, but precise reward definitions per dataset, their potential biases, and sensitivity to reward mis-specification are not fully documented.
Practical robustness and safety
- Robustness to weak or noisy teachers is unknown: if one branch underperforms or carries spurious patterns, the effect on the joint system and mechanisms to downweight/harden against such teachers are not explored.
- Negative transfer and catastrophic forgetting not quantified: while CoPD aims to avoid trade-offs, the degree of negative transfer within branches and over long training horizons is not rigorously measured.
- Safety and alignment considerations are absent: the impact of co-evolving distillation on harmful bias propagation, hallucinations, or undesirable cross-domain behaviors is not evaluated.
- Data provenance and leakage risks are unaddressed: potential overlap between training and evaluation sets, and its influence on results or distillation efficacy, are not discussed.
Open design questions for actionable follow-up
- How to design an adaptive scheduler that targets a desired overlap band in real time (e.g., via PID control on 𝒪_k, curriculum on S_RL/S_OPD, or β_k annealing)?
- Which similarity measure best predicts OPD gains across modalities and model sizes, and can it be computed efficiently online?
- What parameter-merging strategies (e.g., Fisher-weighted, task-conditioned gates, layer-wise selective merge) maximize consolidation under higher divergence?
- Can alternating phases be improved with joint multi-objective optimization (e.g., PCGrad, GradDrop) to better manage RLVR–OPD gradient conflicts?
- How does CoPD perform under asynchronous, large-scale distributed training with stale teachers, and what synchronization/consensus protocols mitigate degradation?
- Can CoPD be extended to non-verifiable-reward domains by integrating preference/implicit-feedback objectives (e.g., DPO/RM-based RL) without degrading stability?
- What mechanisms prevent capability collapse (e.g., diversity regularizers, contrastive objectives between branches) while maintaining high absorption?
Practical Applications
Immediate Applications
Below are practical, deployable ways to use the paper’s findings and methods today. Each item includes suggested sectors, potential tools/workflows/products, and key assumptions/dependencies that affect feasibility.
- Unified multimodal assistant deployment
- Sectors: software, e-commerce, customer support, content moderation, media
- What: Consolidate separate text-, image-, and video-reasoning experts into a single model via CoPD to reduce inference footprint and context switching (e.g., one endpoint for chat + screenshot analysis + short-clip understanding).
- Tools/workflows: Implement alternating RLVR and mutual OPD in existing RL pipelines (e.g., verl/EasyR1); use hub-and-spoke topology with an LLM hub; periodically merge branches to produce a single deployable checkpoint.
- Assumptions/dependencies: All branches share the same base architecture/tokenizer for parameter merging; verifiable rewards are available per domain (e.g., math answers, multiple-choice labels); sufficient compute for parallel training.
- Training-pipeline upgrade for multi-capability consolidation
- Sectors: AI labs, MLOps, enterprise AI platforms
- What: Replace static “train experts → post-hoc OPD” with CoPD’s alternating RLVR + mutual OPD to improve absorption and avoid capability trade-offs.
- Tools/workflows: CoPD scheduler that orchestrates S_RL:S_OPD cycles; hub-and-spoke for K>2 branches; automated branch merging; continuous evaluation on per-domain benchmarks.
- Assumptions/dependencies: RLVR implementation with verifiable rewards; orchestration across multi-GPU/cluster setups; data balance and reward calibration by domain.
- Behavioral-overlap monitoring for OPD quality control
- Sectors: MLOps, research, quality assurance
- What: Track top-k token overlap and symmetric KL between branches to keep teacher–student within an “absorbable” range; use these as KPIs to drive early stopping or schedule adjustments.
- Tools/workflows: Training dashboard that logs O_k metrics and triggers OPD/RLVR phases when overlap drifts below/above thresholds.
- Assumptions/dependencies: Access to on-policy trajectories and distributions for both teacher and student; metric computation overhead is manageable.
- Cost and footprint reduction via parameter merging
- Sectors: edge/embedded AI, mobile, SaaS
- What: Merge co-evolved branches into a single checkpoint to reduce storage and deployment complexity versus hosting multiple experts.
- Tools/workflows: Weight-merging utilities integrated into CI/CD; regression tests to confirm no capability regressions.
- Assumptions/dependencies: Branches start from the same base and remain close in parameter space (as in CoPD); compatibility of modality encoders (for VLM/video branches).
- Domain co-evolution across distributed teams
- Sectors: enterprise AI, partnerships/consortia
- What: Allow different teams to evolve capability branches (e.g., documents, charts, short video) and mutually distill across branches at agreed intervals.
- Tools/workflows: Model exchange contracts; synchronized checkpoints; scheduled mutual-distillation windows; governance on reward functions and datasets.
- Assumptions/dependencies: IP/data sharing agreements; consistent base model and tokenization; versioning discipline.
- Safer capability consolidation
- Sectors: trust & safety, policy, compliance
- What: Add a safety/alignment branch with verifiable reward signals (policy checks, red-team filters) that co-evolves and distills into other branches to propagate safer behaviors.
- Tools/workflows: Safety reward design; mutual OPD to cross-pollinate refusal and risk-detection patterns.
- Assumptions/dependencies: Well-specified, verifiable safety rewards; monitoring to avoid reward hacking.
- Multimodal education and tutoring prototypes
- Sectors: education, consumer apps
- What: Tutors that handle math problems with diagrams and short videos (e.g., whiteboard captures), delivering step-by-step solutions.
- Tools/workflows: Use CoPD-trained unified model; integrate camera and screen recording capture; constraint-based verifiable reward (answer correctness).
- Assumptions/dependencies: High-quality curated math/visual datasets; alignment with academic integrity policies.
- Document and media understanding for enterprise workflows
- Sectors: finance, legal, logistics
- What: Single model that reads mixed-format inputs (scanned docs, charts, screenshots, short clips) for KYC, claims, or compliance checks.
- Tools/workflows: CoPD-trained model embedded in document pipelines; structured output enforcement through validators (verifiable fields).
- Assumptions/dependencies: Availability of verifiable signals (e.g., matching fields, known answers); robust OCR/VLM preprocessing.
- Research methodology and evaluation
- Sectors: academia, corporate research
- What: Use top-k token overlap as a standard diagnostic for distillation absorbability; use CoPD as a baseline for multi-expert consolidation studies.
- Tools/workflows: Public benchmark suites (image/text/video) and scripts for overlap/KL tracking; ablation templates for S_RL:S_OPD ratios.
- Assumptions/dependencies: Access to the same or similar benchmarks; reproducible RLVR setups.
Long-Term Applications
These opportunities require further research, scaling, or development before broad deployment.
- Datacenter-scale co-evolution as a new training paradigm
- Sectors: foundation model providers, cloud platforms
- What: Operate dozens of capability branches (code, audio, 3D, planning, scientific reasoning) co-evolving in parallel with a hub-and-spoke mutual-OPD fabric; move from data- to capability-parallel scaling.
- Tools/workflows: Cluster schedulers that optimize overlap-aware phase scheduling; bandwidth-efficient distillation protocols; automated branch selection/weighting.
- Assumptions/dependencies: Significant compute and engineering investment; robust reward design across many capabilities; efficient parameter/gradient streaming.
- Lifelong capability onboarding for enterprise assistants
- Sectors: enterprise software, productivity, DevOps
- What: Continuously add new skills (e.g., domain-specific tools, GUIs, workflows) as new branches and co-distill into the unified assistant without catastrophic forgetting.
- Tools/workflows: Skill registration API; automatic detection of overlap degradation; rolling merge and rollback; A/B gating per skill.
- Assumptions/dependencies: Scalable data pipelines; verifiable rewards for new tools/tasks (e.g., unit tests for coding skills).
- Robotics: unified perception–reasoning–control policies
- Sectors: robotics, manufacturing, logistics
- What: Co-evolve branches for perception (video), language reasoning (task instructions), and low-level control (sim RL or execution traces) to create a single model that handles “see-think-act.”
- Tools/workflows: Simulator-derived verifiable rewards (task completion); hardware-in-the-loop training cycles; safety branch for constraints.
- Assumptions/dependencies: Reliable verifiable rewards for control tasks; sim-to-real transfer; real-time inference constraints.
- Multimodal clinical assistants
- Sectors: healthcare
- What: Integrate text (EHR), images (X-rays), and video (ultrasound clips) reasoning into a unified assistant co-evolved with safety and protocol branches; decision support under clinician supervision.
- Tools/workflows: Federated or privacy-preserving training; verifiable proxies (radiology report matching, structured label checks); post-hoc audit trails of overlap metrics.
- Assumptions/dependencies: Regulatory approval; curated, de-identified datasets; stringent evaluation and bias/safety audits.
- Financial analytics and compliance with multimodal evidence
- Sectors: finance
- What: Combine text filings, charts, scanned contracts, and media (earnings-call videos) to perform risk analysis and compliance checks with co-evolved branches for each evidence type.
- Tools/workflows: Verifiable checks (numeric consistency, rule templates); scenario simulators for policy adherence.
- Assumptions/dependencies: Access to high-quality multi-format corpora; robust verifiable reward functions for compliance outcomes.
- Energy and industrial monitoring
- Sectors: energy, manufacturing
- What: Unified models that reason over sensor logs, charts, imagery, and operational videos for anomaly detection and root-cause analysis.
- Tools/workflows: Verifiable signals (alarm confirmations, downstream KPI changes); continuous co-evolution with new sensor types as branches.
- Assumptions/dependencies: Ground-truth generation at scale; integration with SCADA/telemetry systems.
- Personalized assistants with dynamic skill graphs
- Sectors: consumer tech
- What: User-specific branches (e.g., smart-home controls, calendar video summaries) co-evolve and distill into a personal unified model while protecting privacy.
- Tools/workflows: On-device or federated CoPD; overlap thresholds tuned to device constraints; periodic merges.
- Assumptions/dependencies: Efficient on-device RLVR/OPD; privacy-preserving verifiable rewards; lightweight multimodal encoders.
- Overlap-aware training controllers and standards
- Sectors: standards/policy, MLOps tooling
- What: Industry standards for reporting teacher–student overlap and symmetric KL during distillation; controllers that auto-tune S_RL:S_OPD and teacher selection based on overlap.
- Tools/workflows: Open metrics/telemetry spec; compliance dashboards; certification tests for multi-domain consolidation.
- Assumptions/dependencies: Community consensus; reproducibility benchmarks; vendor cooperation.
- Generalized verifiable rewards for open-ended tasks
- Sectors: research, cross-industry
- What: Expand RLVR to tasks without explicit answers (e.g., long-form reasoning, design critique) using programmatic verifiers, simulators, or human-in-the-loop scoring integrated into CoPD.
- Tools/workflows: Verifier development toolkits; hybrid reward modeling; confidence-weighted OPD schedules.
- Assumptions/dependencies: Scalable and reliable verifiers; cost-effective human oversight pipelines.
Notes on Cross-Cutting Assumptions and Dependencies
- Verifiable rewards: CoPD relies on RLVR; the availability and quality of verifiable reward functions per capability are decisive.
- Shared base and architecture: Branches must share tokenizer/architecture and start from the same base to enable stable parameter merging and high overlap.
- Compute and orchestration: Alternating multi-branch training requires robust cluster scheduling, checkpoint synchronization, and bandwidth for cross-branch rollouts.
- Data quality and balance: Each capability needs sufficiently curated data; mixing difficulty levels and maintaining coverage affect convergence and overlap.
- Safety and governance: Reward hacking and domain drift remain risks; overlap metrics should complement human audits and safety evaluations.
Glossary
- Ablation study: A controlled analysis that removes or alters components of a method to assess their individual contributions. "Ablation Study"
- Absorption-efficiency function: A function measuring how effectively a student absorbs supervision from a teacher as a function of their behavioral overlap. "where is an absorption-efficiency function depending on teacher--student behavioral overlap "
- Behavioral consistency hypothesis: The claim that OPD is more effective when teacher and student behave similarly along their trajectories. "Behavioral consistency hypothesis."
- Behavioral distance: A quantitative notion of how different the outputs or trajectories of teacher and student policies are. "teacher and student should co-evolve, with their behavioral distance kept within the absorbable range throughout training"
- Bidirectional OPD: Distillation applied in both directions between two models so each acts as both teacher and student. "making OPD bidirectional"
- Capability consolidation: The process of combining multiple specialized capabilities into a single policy/model. "a widely adopted approach for capability consolidation"
- Capability divergence: The phenomenon where optimizing for one capability harms another due to conflicting objectives or gradients. "We refer to this phenomenon as capability divergence"
- Capability divergence cost: The loss in achievable performance when jointly training on heterogeneous capabilities due to gradient conflicts. " is the capability divergence cost"
- Clipping bounds: Limits used to constrain policy update ratios in PPO-style objectives to stabilize training. "The clipping bounds are set to $\epsilon_{\text{low} = 0.2$ and $\epsilon_{\text{high} = 0.28$."
- Co-Evolving Policy Distillation (CoPD): A training framework that alternates capability-specific RLVR with mutual on-policy distillation across branches to co-evolve experts. "We propose Co-Evolving Policy Distillation (CoPD)"
- Domain-specific experts: Models specialized through training on a single domain or capability. "even surpassing domain-specific experts."
- Gradient conflict: The disagreement between gradients from different tasks/capabilities that impedes simultaneous optimization. "the disagreement manifests as gradient conflict within each parameter update."
- GRPO: A PPO-style group-based reinforcement learning algorithm used for sequence models in RLVR. "each branch independently performs GRPO on the data corresponding to capability "
- Hub-and-spoke topology: A coordination pattern where a central “hub” branch exchanges distillation with multiple “spoke” branches to reduce pairwise overhead. "we adopt a hub-and-spoke topology"
- Mixed-data RLVR: Training a single model with RLVR on a mixture of datasets from different capabilities. "Mixed-data RLVR pays this cost as the seesaw effect"
- Multi-teacher OPD (MOPD): Distillation where multiple expert teachers supervise a single student model simultaneously. "also known as Multi-teacher OPD (MOPD) when multiple experts serve as teachers simultaneously"
- Mutual OPD: A distillation setup where branches teach each other in alternating or concurrent steps. "In the mutual OPD phase, each branch generates rollouts on the other branch's data and receives token-level supervision from the other"
- On-policy distillation (OPD): A distillation method where the student learns from teacher signals evaluated along the student’s own on-policy trajectories. "these experts are then consolidated into a unified policy model through on-policy distillation (OPD)"
- On-policy trajectories: Sequences generated by the current student policy, used for evaluation and learning signals. "top- token overlap along on-policy trajectories."
- Parameter merging: Combining parameters from multiple co-evolved branches into a single final model. "the final unified model can be obtained through simple parameter merging."
- Reinforcement learning with verifiable rewards (RLVR): An RL post-training paradigm where rewards are computed via verifiable (e.g., programmatic) checks on model outputs. "Reinforcement learning with verifiable rewards (RLVR) has emerged as the dominant post-training paradigm for large models"
- Rollouts: Sampled output sequences from a policy used to compute rewards or distillation signals. "generates rollouts on the other branch's data"
- State visitation distribution: The distribution over states (prefixes/contexts) encountered when following a policy during generation. " is the state visitation distribution induced by the student."
- Symmetric KL: A distance measure computed as the sum of KL divergences in both directions between two policies. "top- overlap drops and symmetric KL rises"
- Teacher signal: The per-token guidance computed from the teacher’s log-probabilities used to update the student. "the teacher signal is defined as:"
- Teacher–student behavioral overlap: The degree to which teacher and student assign high probability to the same tokens at the same states. "teacher--student behavioral overlap "
- Token-level advantage: An advantage value computed per token to weight updates in sequence-level RL or distillation. "the token-level advantage for the cross-branch update is "
- Token-level supervision: Supervision provided at each token position, typically via teacher probabilities, rather than only at sequence level. "receives token-level supervision from the other branch"
- Top- token overlap: A metric measuring how many of the top-k predicted tokens are shared between teacher and student at each state. "measure the behavioral distance between teacher and student via top- token overlap"
- Verifiable reward function: A programmatic evaluator that assigns rewards to outputs based on verifiable criteria (e.g., correctness). "the capability-specific verifiable reward function "
Collections
Sign up for free to add this paper to one or more collections.