Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Abstract: On-policy distillation (OPD) has become a core technique in the post-training of LLMs, yet its training dynamics remain poorly understood. This paper provides a systematic investigation of OPD dynamics and mechanisms. We first identify that two conditions govern whether OPD succeeds or fails: (i) the student and teacher should share compatible thinking patterns; and (ii) even with consistent thinking patterns and higher scores, the teacher must offer genuinely new capabilities beyond what the student has seen during training. We validate these findings through weak-to-strong reverse distillation, showing that same-family 1.5B and 7B teachers are distributionally indistinguishable from the student's perspective. Probing into the token-level mechanism, we show that successful OPD is characterized by progressive alignment on high-probability tokens at student-visited states, a small shared token set that concentrates most of the probability mass (97%-99%). We further propose two practical strategies to recover failing OPD: off-policy cold start and teacher-aligned prompt selection. Finally, we show that OPD's apparent free lunch of dense token-level reward comes at a cost, raising the question of whether OPD can scale to long-horizon distillation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies a way to train smaller LLMs (students) by learning from bigger or better ones (teachers). The specific method is called “on‑policy distillation” (OPD). In OPD, the student writes its own answers and the teacher gives guidance at every step, helping the student adjust how it thinks, not just what final answer it gives. The authors ask: when does this work well, why does it sometimes fail, and how can we fix it?
What questions were the authors trying to answer?
- When does OPD help a student model improve, and when does it fail?
- What exactly is happening at the tiny, step‑by‑step level (each next word) during OPD that makes it work (or not)?
- Are there simple, practical tricks to make OPD work better when it’s not working?
- Are there limits to OPD—especially for very long answers?
How did they study this?
To keep things concrete, think of the teacher and student as two writers:
- The student writes an answer one small piece at a time (these tiny pieces are called “tokens,” like parts of words).
- After each piece, the teacher shows how likely it would choose each possible next piece. This is like giving a confidence score for each next word.
- The student compares its own choices with the teacher’s choices and adjusts to be closer.
Some helpful ideas and terms:
- On‑policy: The student practices on its own writing (its own “policy”), not on the teacher’s prewritten answers.
- Top‑k tokens: Instead of checking every possible next piece, they often look only at the student’s few most likely choices (like its top 16 candidates). This saves time while focusing on what the student actually considers.
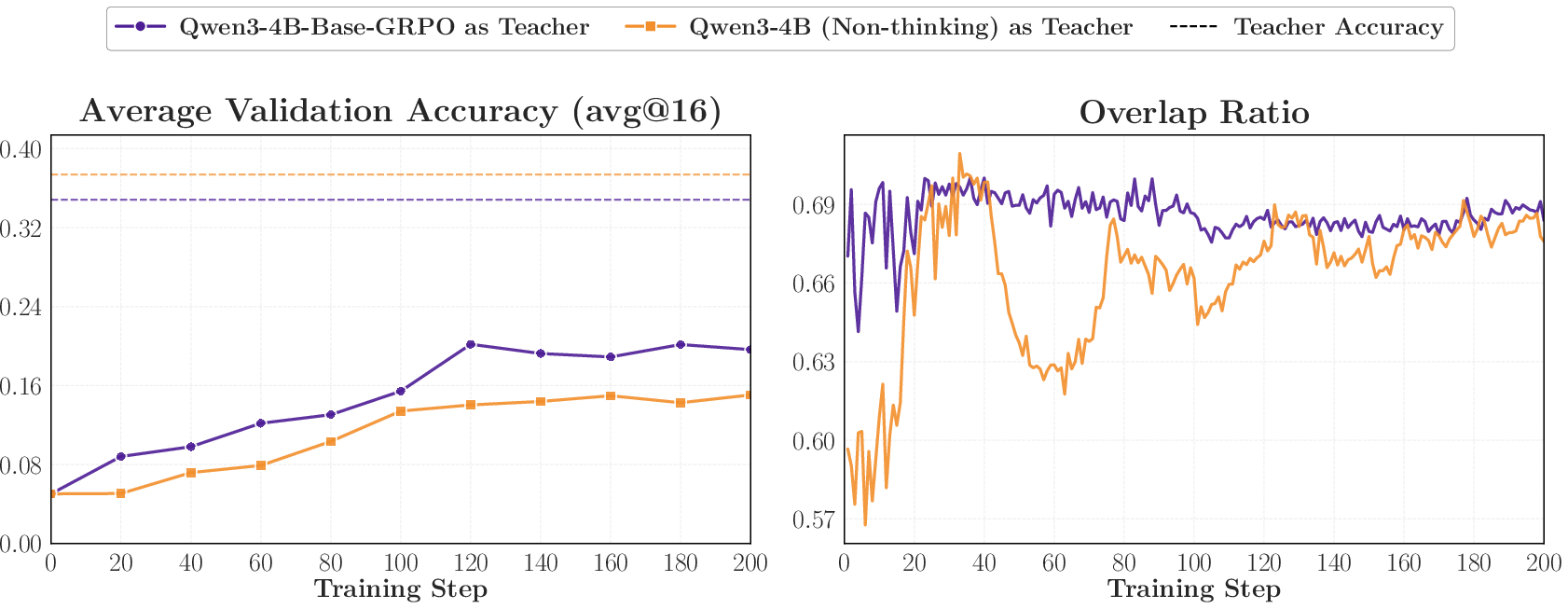
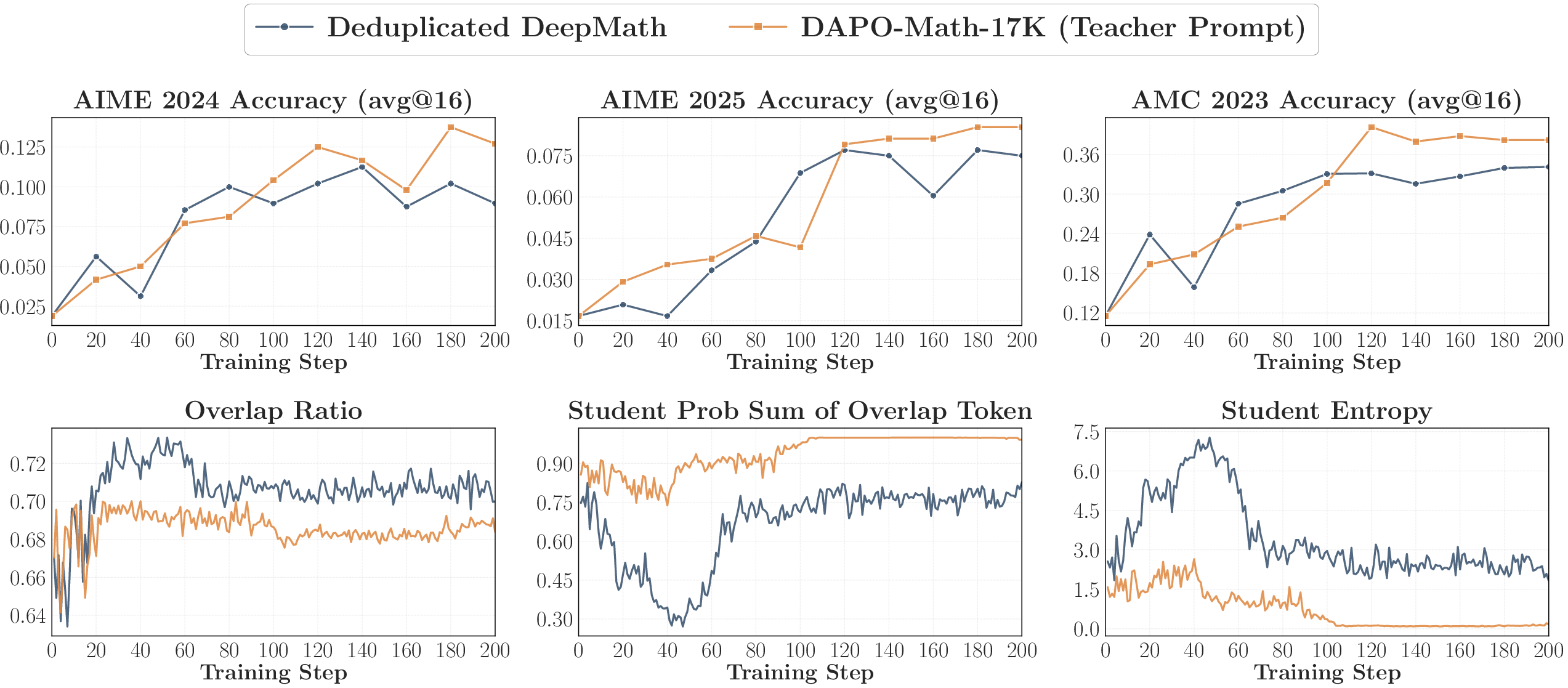
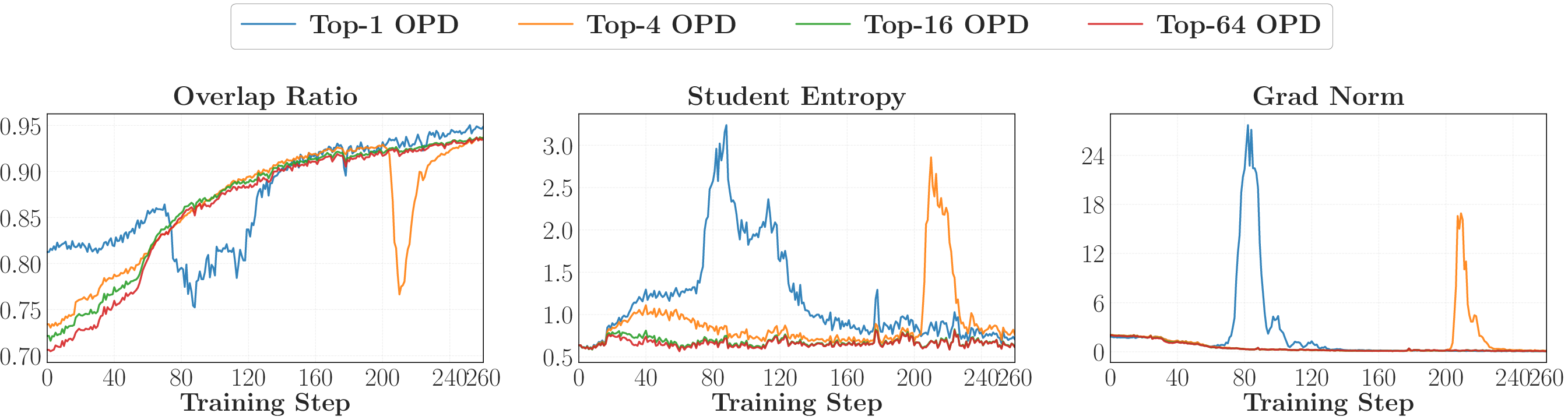
- Overlap ratio: How many of the student’s top choices are also among the teacher’s top choices. High overlap means their “thinking patterns” are similar.
- Entropy (simple idea): A way to measure how “confident” or “spread out” a model’s choices are. Low entropy = very confident in a few options; high entropy = more unsure, spreading probability across many options.
What they did:
- Ran many training runs where different students learned from different teachers, especially on math tasks.
- Measured how overlap, confidence (entropy), and performance changed during training.
- Tried “reverse distillation” (having a student learn from its own earlier version) to understand what exactly OPD passes along.
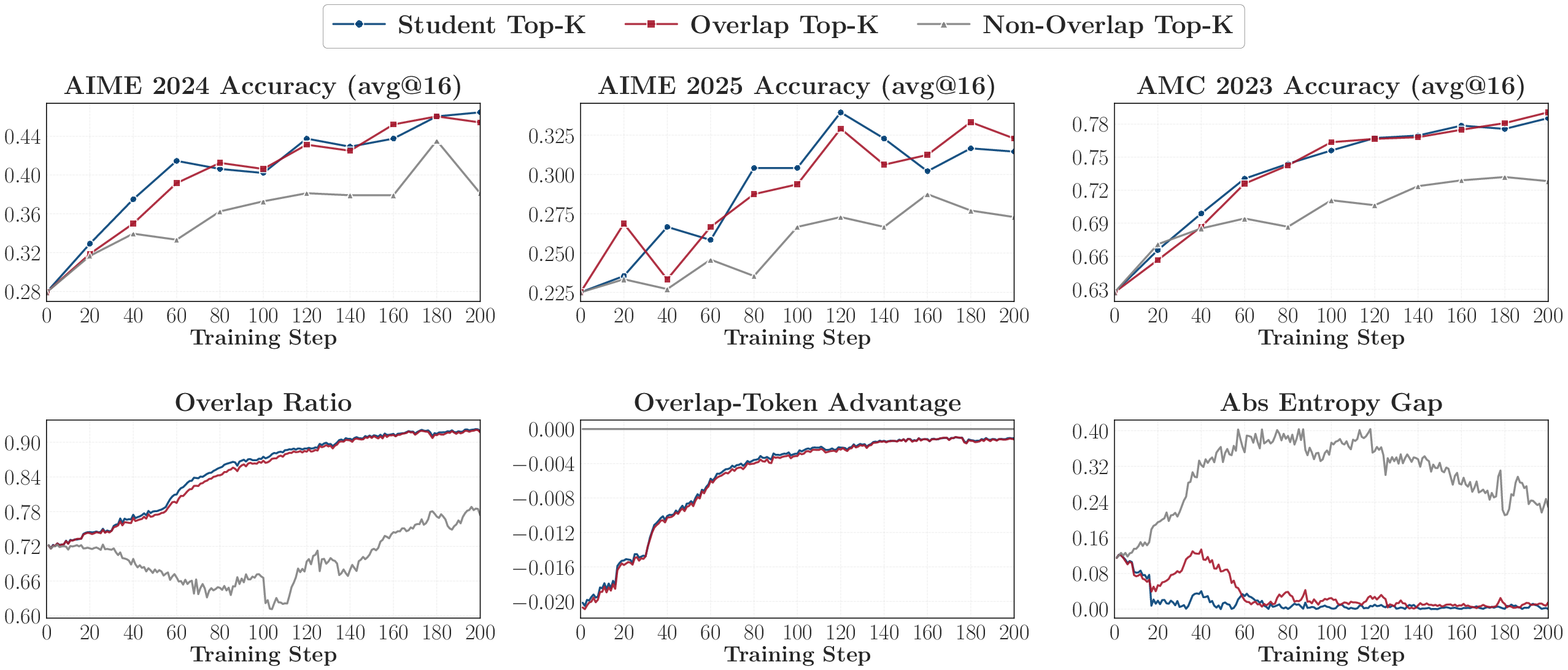
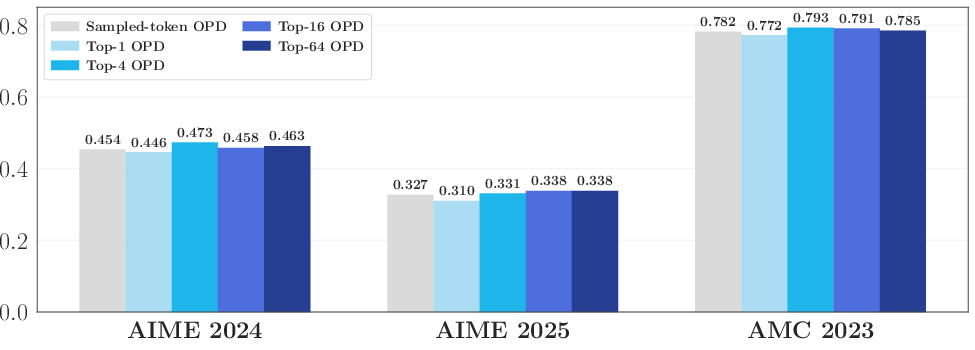
- Performed ablations (controlled tests) to see whether focusing only on shared high‑probability tokens is enough.
- Tested two practical tweaks to rescue failing OPD.
What did they find, and why is it important?
1) Two conditions determine whether OPD succeeds
- The student and teacher must have compatible thinking patterns.
- If they don’t “think” in similar ways (their top choices don’t overlap much), the teacher’s token‑by‑token advice is hard to use, and training stalls.
- The teacher must offer genuinely new knowledge, not just higher scores.
- A bigger teacher trained on the same data and in the same way may score higher but still not teach anything truly new. In that case, OPD gives little benefit.
Why it matters: Bigger isn’t automatically better. A strong teacher only helps if it thinks similarly to the student and brings new capabilities the student hasn’t seen.
2) What’s happening at the token level
- Successful OPD looks like “progressive alignment”: over time, the student and teacher agree more and more on the student’s most likely next tokens.
- Almost all the action happens on a small set of shared high‑probability tokens.
- That small shared set carries about 97–99% of the total attention (probability mass).
- Training only on these overlap tokens works almost as well as training on all top tokens. Tokens outside the overlap matter much less.
Why it matters: OPD mainly tunes how the student distributes confidence among the teacher‑preferred top tokens at the states the student actually visits. If overlap doesn’t grow, learning stalls.
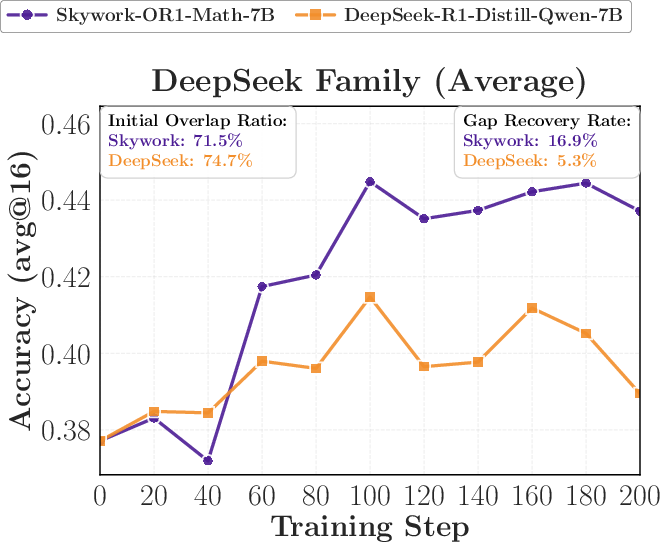
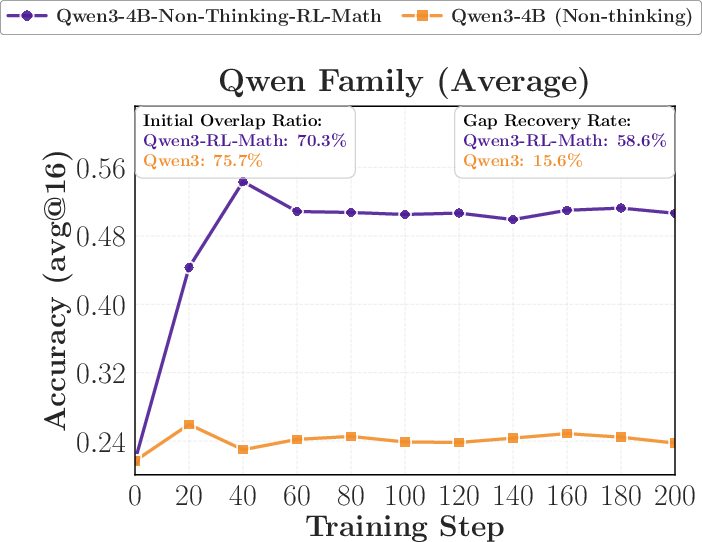
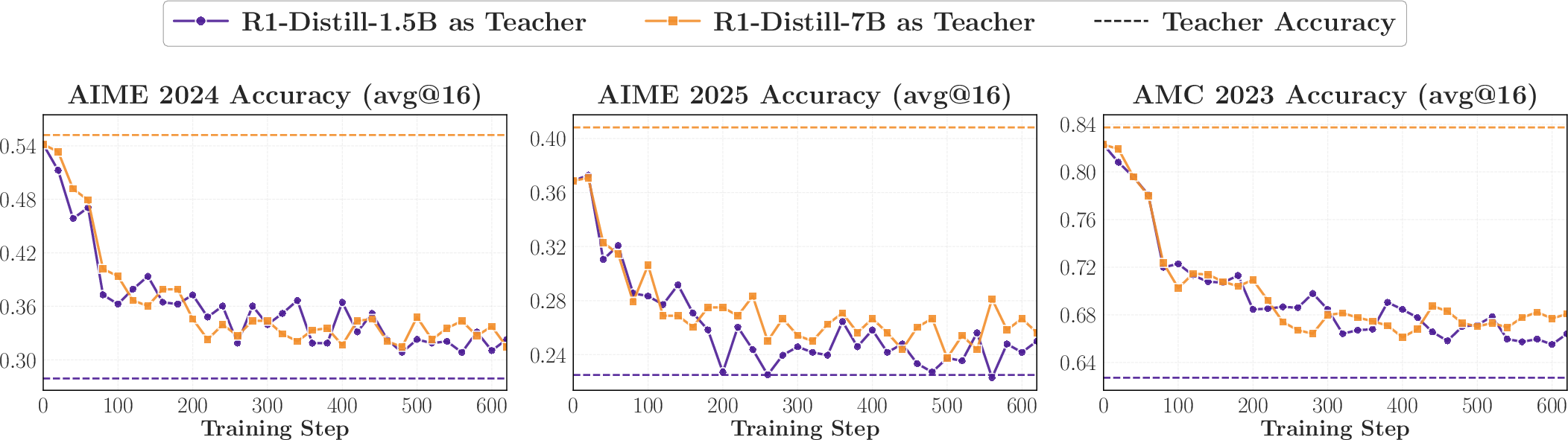
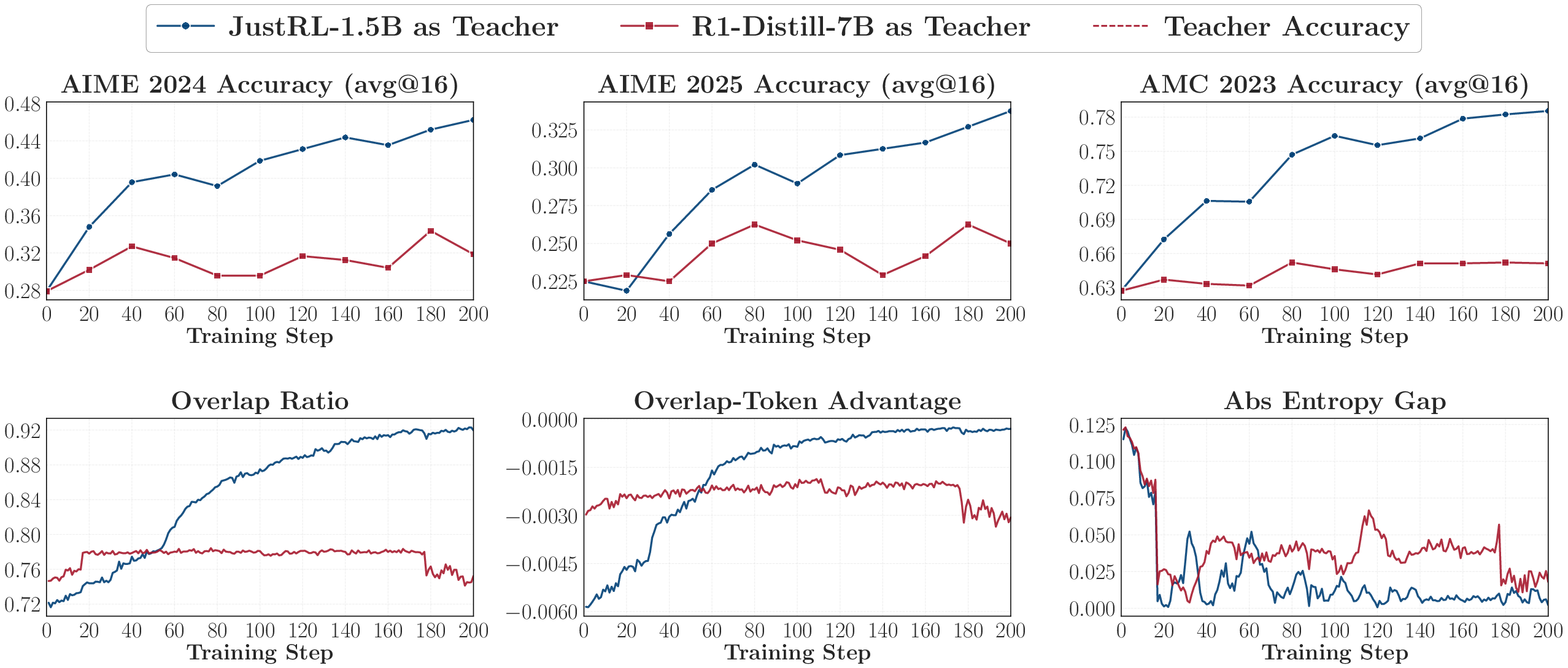
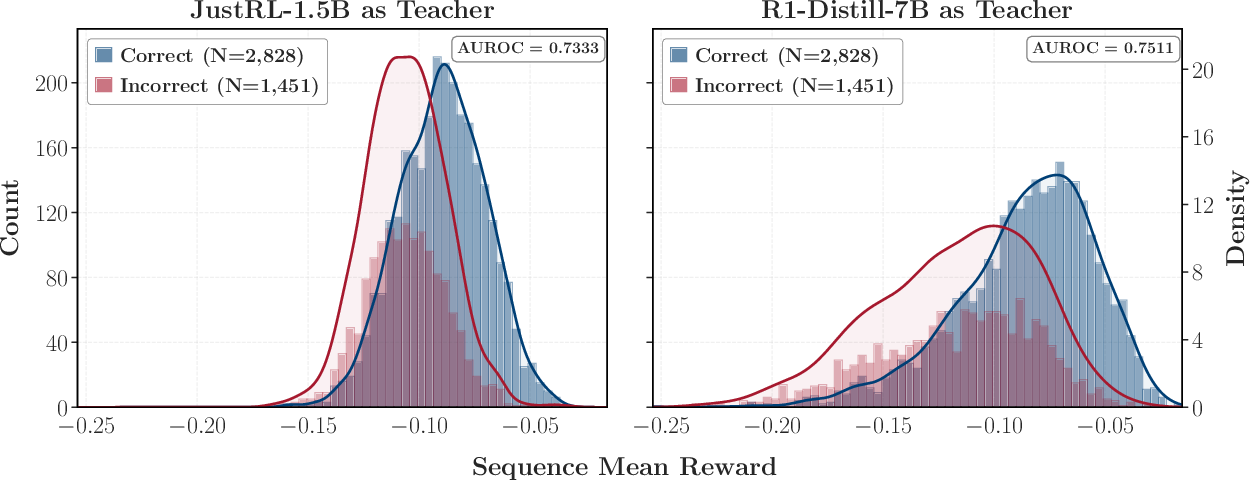
3) Surprising evidence from reverse distillation
- When a student that improved via reinforcement learning (RL) is distilled back toward its earlier (weaker) version, it “forgets” those gains and returns to the old performance.
- Using a larger model from the same family (with similar training) as teacher leads to nearly the same regression, even if that teacher scores a bit higher.
Why it matters: OPD transfers “how to think” patterns more than raw benchmark strength. If two teachers think similarly, the student treats them as almost the same—even if one is bigger.
4) Two practical ways to fix failing OPD
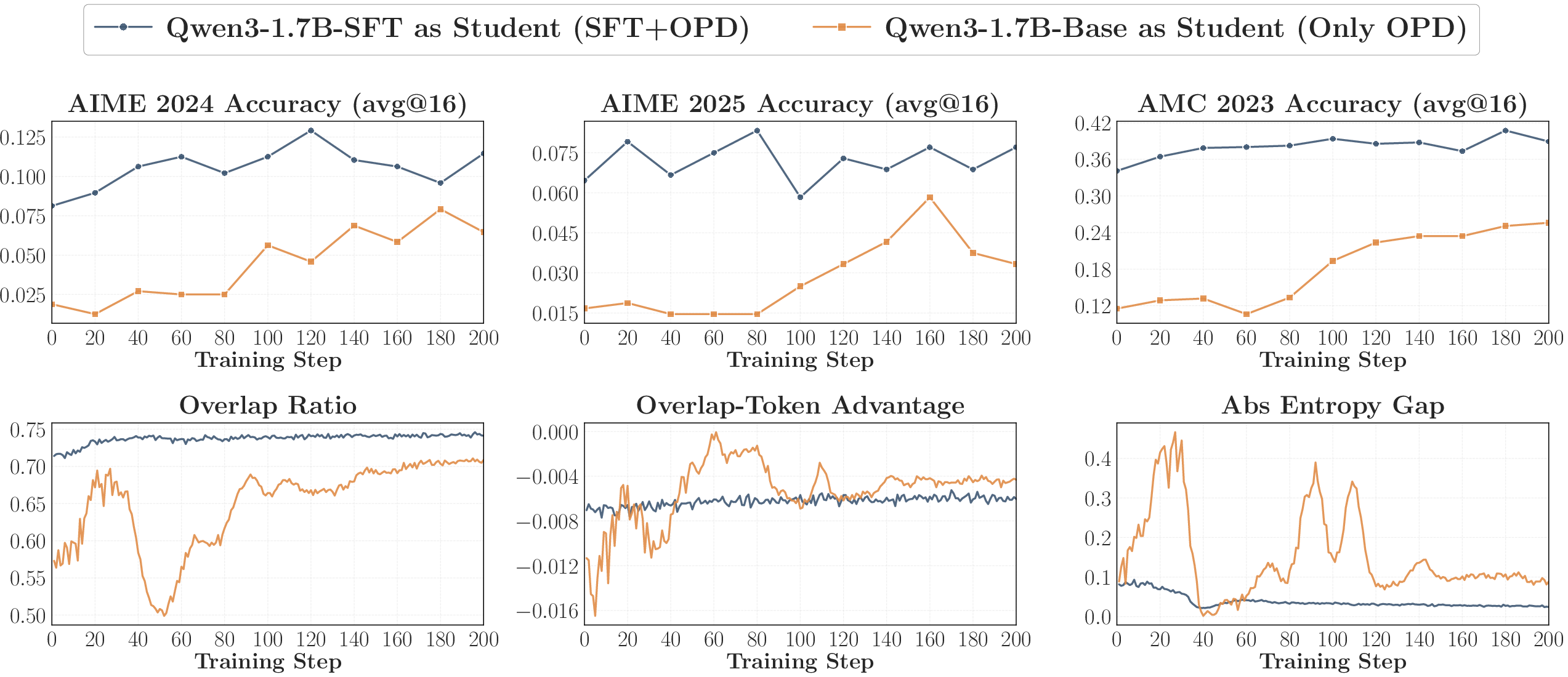
- Off‑policy cold start: First do a short supervised fine‑tune on teacher‑written answers, then switch to on‑policy distillation.
- This raises the initial overlap and makes OPD stable and more effective.
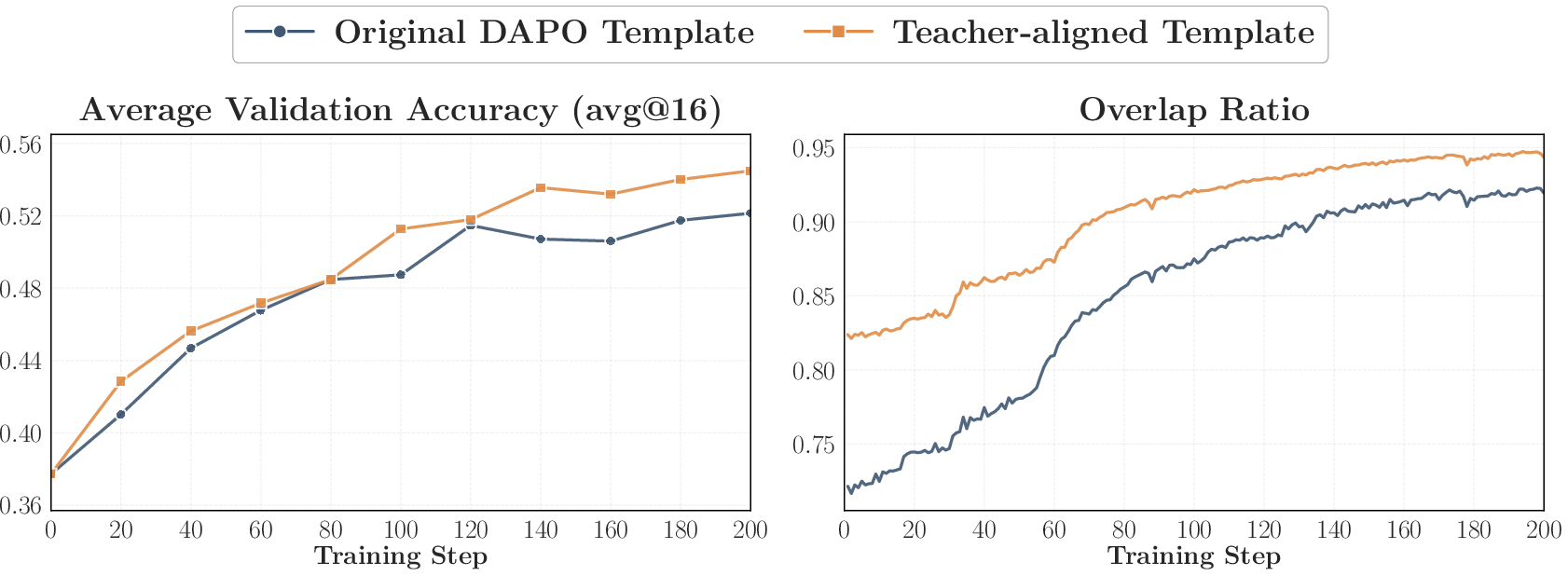
- Teacher‑aligned prompts: Use question formats and content similar to what the teacher saw during its own post‑training.
- This also boosts alignment and performance.
- Caution: Using only teacher‑aligned prompts can make the student too confident (very low entropy). Mixing in other prompts helps keep the student flexible.
Why it matters: You can often rescue OPD by making the student and teacher’s “thinking contexts” more similar before or during training.
5) Limits of OPD for long answers
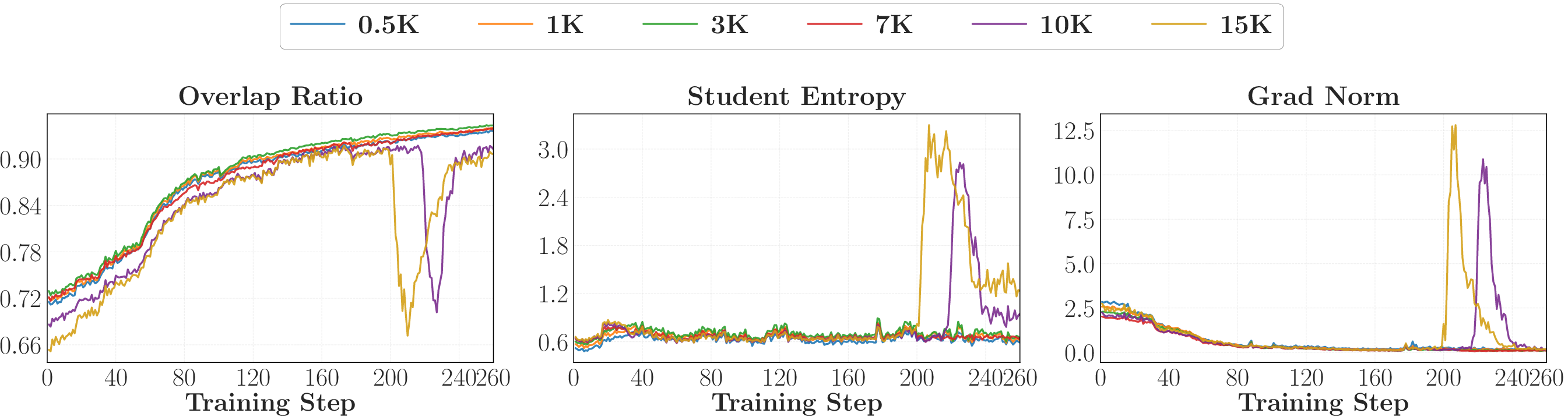
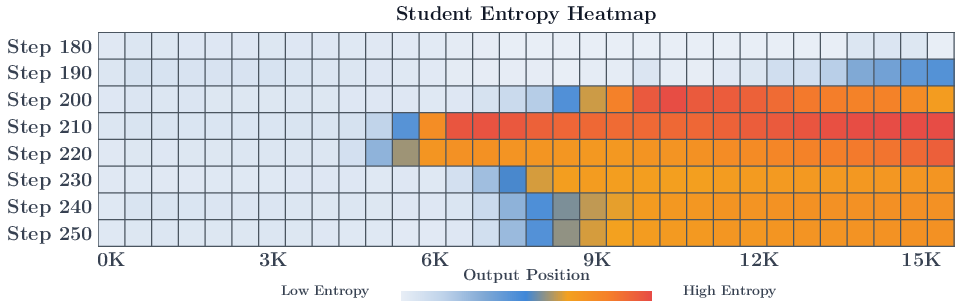
- OPD gives a reward at every token (dense supervision), which is great—but the quality of that signal gets worse deeper into long answers.
- Instability tends to start at later tokens and then spread backward during training.
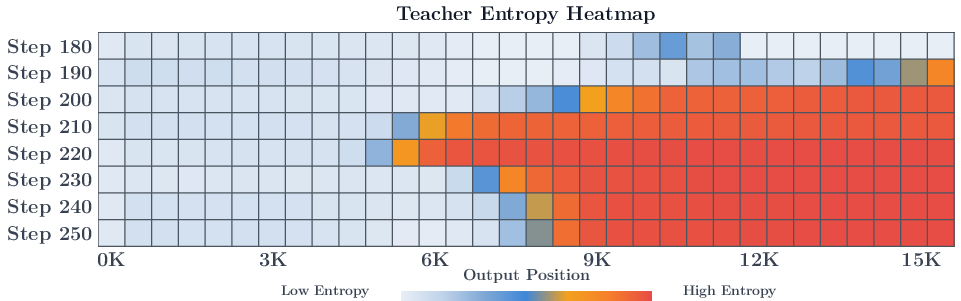
- Even when the teacher’s overall guidance correlates with correctness, the local signal around the student’s current behavior can be too weak or “flat” to push learning forward.
Why it matters: For very long reasoning chains, OPD can become unstable or less reliable. This raises questions about how well OPD scales to long, multi‑step tasks.
What’s the big picture impact?
- Better understanding: The paper explains not just whether OPD works, but why—highlighting thinking‑pattern compatibility and truly new knowledge as keys to success.
- Practical recipe: A short supervised warm‑up and teacher‑aligned prompts can reliably improve OPD.
- Design guidance: When choosing a teacher, don’t just pick the biggest or highest‑scoring one. Pick a teacher whose way of thinking matches the student and adds genuinely new skills.
- Caution for long reasoning: OPD may struggle on very long answers; future methods may need to combine OPD with other techniques to stay stable and effective.
In short, this paper turns OPD from a “mysterious but useful trick” into a method with clear rules and fixes, helping builders choose the right teachers, data, and training steps to make smaller models smarter in a stable, efficient way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues the paper surfaces—what remains missing, uncertain, or unexplored—framed to guide concrete follow-up research.
- Formal definition and measurement of “thinking-pattern compatibility.” The paper operationalizes compatibility via top‑k token overlap; future work should develop richer, predictive metrics (e.g., representation-level similarity, trajectory-level alignment, causal intervention tests) and validate which metrics best forecast OPD outcomes.
- Quantifying “new knowledge” in teachers. The study infers that OPD gains require teacher capabilities beyond the student’s training; there is no formal way to detect or measure this “newness.” Develop data/model-based proxies (e.g., information gain, mutual information on student-visited states, unseen capability probes) to predict transferability before training.
- Theory of OPD’s optimization geometry. The paper hypothesizes locally flat reverse‑KL landscapes around the student for some teachers; a formal analysis is missing. Derive conditions under which reverse‑KL on student-visited states yields flat/ineffective gradients and when alternative f‑divergences (e.g., forward KL, JS, α‑divergences) or mixtures would avoid failure.
- Long-horizon instability and late-token degradation. The study observes degraded reward quality at deeper positions and collapse at longer response lengths but provides no principled mitigation. Investigate positional weighting, truncation schedules, hierarchical/segmental OPD, teacher re-decoding from intermediate prefixes, or value/critic-assisted credit assignment to stabilize long trajectories.
- Generalization beyond math domain. All experiments are math-centric (AIME/AMC, DAPO-Math/DeepMath). Validate whether the mechanistic findings (overlap sufficiency, pattern compatibility) transfer to dialogue, instruction-following, coding, multilingual tasks, tool use, and multi-turn agentic settings.
- Scaling behavior with larger models. Results are centered on 1.5B–7B ranges; it remains unknown whether overlap dynamics, regression under reverse distillation, and long-horizon issues persist or change with 30B–>100B students/teachers.
- Robustness to sampling and decoding choices. OPD rollouts use a fixed temperature/top‑p; sensitivity to sampling parameters (temperature, top‑p, nucleus vs. beam, deterministic sampling) and their interaction with overlap/entropy dynamics is not explored.
- Alternative supervision supports. The study emphasizes student-top‑k and shared-overlap tokens; the utility of teacher‑top‑k, union‑top‑k, adaptive thresholds, advantage-weighted token selection, or dynamic k schedules is not systematically evaluated.
- Loss function variants and schedules. Only reverse‑KL variants are studied; it is unclear whether forward KL, symmetric KL, JS, adaptive α‑divergence, or curriculum schedules (e.g., reverse→forward) better handle thinking-pattern mismatches or late-token noise.
- Teacher entropy and logit calibration. The paper tracks entropy gaps but does not test whether calibrating teacher temperature/logit scales or matching entropies improves OPD stability and transfer.
- Protecting student capabilities against regression. Reverse distillation regresses an RL-improved student to its pre‑RL behavior; mechanisms to prevent overwriting (e.g., proximal constraints to the original policy, EWC-style regularization, KL anchors, multi-objective training, or adapter-based OPD) are not evaluated.
- Curriculum and mixing for prompt selection. While teacher-aligned prompts help, they can cause entropy collapse. There is no guidance on mix ratios, schedules, or active selection strategies that balance alignment and exploration.
- Predictive selection of teachers. Beyond “same pipeline vs. post-trained,” there is no procedure to pre-screen teachers for pattern compatibility and novel capability. Develop diagnostics (e.g., overlap/entropy probes, capability differentials on held-out probes) to choose among candidate teachers or ensembles.
- Multi-teacher/ensemble OPD. Combining teachers to trade off compatibility and new knowledge is untested. Explore mixture-of-experts or adaptive teacher routing on a per-prompt or per-state basis.
- Partial/active teacher querying. OPD assumes dense per-token supervision; the paper does not study budgeted or adaptive querying (e.g., only when student uncertainty is high or overlap is low), nor caching or distilling compact teacher surrogates.
- Positional credit assignment. The paper observes that instability originates in later tokens but does not test positional reweighting, token-wise confidence gating, or backward/forward curriculum strategies to emphasize reliable positions.
- PEFT vs. full-parameter OPD. The work fine-tunes full models; whether parameter-efficient OPD (LoRA/adapters) reduces catastrophic overwriting and improves stability is unknown.
- Self-distillation with privileged signals. Claims reference self-distillation literature but do not test whether the same dynamics (overlap sufficiency, pattern compatibility) hold when the “teacher” is the student with extra context or tools.
- Robustness to teacher errors and adversarial states. Although global teacher signal correlates with correctness, the paper does not explore selective trust mechanisms (e.g., filtering by teacher confidence, cross-checking with verifier models) when the teacher is wrong or miscalibrated on student-visited prefixes.
- Evaluation breadth and metrics. The study emphasizes avg@16 on a few math benchmarks; it lacks assessments of calibration, log-likelihood, diversity, chain-of-thought fidelity, pass@k sensitivity, and out-of-domain generalization.
- Data provenance and contamination checks. Using teacher post-training prompts risks subtle train–test leakage; systematic contamination audits and their impact on perceived OPD gains are not reported.
- Sensitivity to top‑k choice. Overlap sufficiency is shown for k=16; dependence on k, adaptive k schedules, or top‑p subsets remains unquantified, especially across domains with different token entropy profiles.
- Operational definition of “distributional indistinguishability.” Reverse-distillation results suggest indistinguishability at student-visited states across teacher scales, but there is no rigorous test (e.g., hypothesis testing on conditional distributions, state-conditional two-sample tests) to characterize when two teachers are indistinguishable to a given student.
- Safety and bias transfer. OPD’s focus on high-probability tokens risks copying teacher biases or unsafe behaviors; methods to detect and mitigate bias propagation during OPD are not addressed.
- Reproducibility under compute and seed variance. The paper presents trends but does not report variability across seeds, compute budgets, or hardware; standardized OPD benchmarks and reporting protocols would clarify robustness of the claimed dynamics.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s insights on OPD conditions, mechanisms, and recipes.
- OPD teacher selection checklist (software/AI engineering)
- Use teachers that share “thinking-pattern consistency” with the student and demonstrably possess “new knowledge” (e.g., post-RL capabilities beyond the student’s training set).
- Assumptions/dependencies: access to teacher logits/log-probs; comparable tokenization; licensing for teacher queries; a way to verify teacher’s post-training provenance.
- Overlap-aware OPD monitoring and early-stop heuristics (software/AI engineering)
- Instrument training with overlap ratio, overlap-token advantage, and entropy gap on student-visited states; halt or pivot when overlap stagnates or entropy gap widens persistently.
- Potential tool: an “OPD Monitor” dashboard that logs the paper’s dynamic metrics per step.
- Assumptions/dependencies: logging hooks at token level; compute for per-prefix teacher queries.
- Off-policy cold start before OPD (software/AI engineering; startups optimizing compute)
- Perform a short SFT phase on teacher-generated rollouts to raise initial overlap and stabilize OPD.
- Workflow: teacher generates K responses on a curated prompt subset → SFT → switch to OPD.
- Assumptions/dependencies: teacher API quotas; curated prompt subset; deduplication against OPD prompts.
- Teacher-aligned prompt templates and content (education, healthcare, legal, finance—domain specialization)
- Match prompt templates and, when feasible, prompt content to the teacher’s post-training data to sharpen alignment on high-probability tokens and improve transfer.
- Workflow: audit teacher’s post-training prompt schema; mirror format; mix aligned and out-of-distribution prompts to avoid entropy collapse.
- Assumptions/dependencies: access to template specs or public recipes; careful entropy monitoring.
- Mix teacher-aligned and out-of-distribution prompts to preserve entropy (software/AI engineering; applied NLP)
- Prevent overconfidence and brittleness by combining teacher-aligned prompts with diverse prompts; monitor entropy gap and adjust mixture proportion.
- Potential tool: an “Entropy Mixer” that tunes the ratio by targeting a desired entropy range.
- Assumptions/dependencies: prompt pool diversity; entropy metrics online.
- Top-k overlap-only supervision to cut teacher-query cost (software/AI engineering)
- Restrict OPD KL to overlap tokens within student and teacher top-k; the paper shows this matches full top-k outcomes.
- Benefits: reduced teacher compute; similar performance to standard top-k OPD.
- Assumptions/dependencies: ability to compute intersections efficiently; tuned k (e.g., 16).
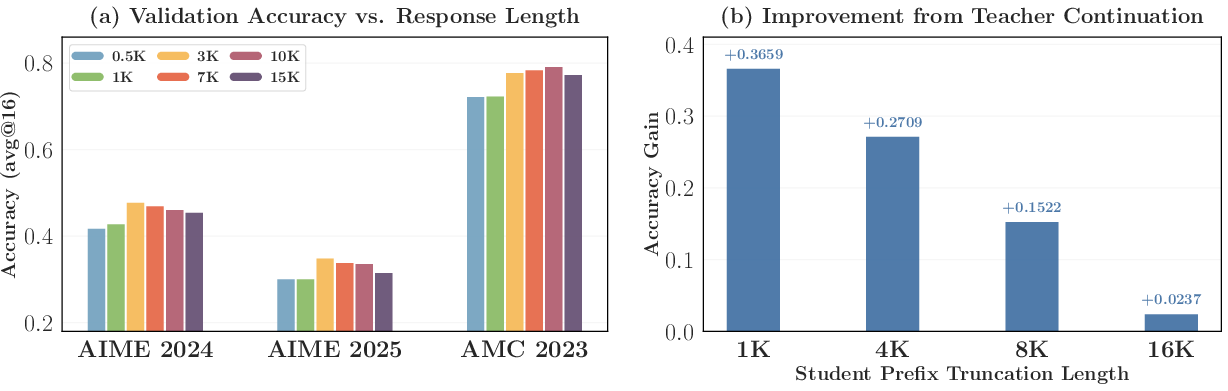
- Response-length scheduling with a sweet spot (software/AI engineering; production training)
- Set maximum response lengths around moderate ranges (e.g., 3K–7K) to avoid late-stage collapse and keep overlap rising smoothly.
- Potential tool: a “Length Scheduler” that probes multiple lengths and locks onto stable ranges.
- Assumptions/dependencies: validation harness for multiple lengths; budget to run short probes.
- Reverse-distillation guardrails (software/AI engineering; model ops)
- Avoid distilling toward a weaker pre-RL checkpoint or a same-pipeline larger model with no new knowledge; detect regression and roll back.
- Workflow: compute gap recovery rate; if negative or negligible, switch teacher or pipeline.
- Assumptions/dependencies: benchmark suite and sampling protocol; teacher selection alternatives.
- Domain-specific OPD pipelines (healthcare coding, claims processing; legal drafting; financial report analysis)
- Combine off-policy cold start with teacher-aligned prompts from domain corpora (e.g., medical Q&A, legal case templates) to produce small specialized models.
- Assumptions/dependencies: compliant data sources; domain teacher with proven “new capabilities”; risk and privacy controls.
- Compute-efficient post-training for small labs and startups (software/AI engineering; education tech)
- Replace expensive RL with OPD + cold start to reach competitive gains at a fraction of RL compute, following Qwen-like recipes.
- Assumptions/dependencies: reproducible OPD implementation; teacher access; careful metric monitoring.
- Automated prompt schema auditor (software tooling)
- A utility that compares student outputs against teacher’s preferred input/output formatting to suggest template changes that raise overlap.
- Assumptions/dependencies: teacher schema or exemplar pairs; template normalization library.
- Training documentation and reproducibility checklists (academia; industry governance)
- Require reporting of overlap ratio, entropy gap, teacher provenance, response-length choices, and prompt mixing policy to make OPD runs interpretable and repeatable.
- Assumptions/dependencies: agreement on metrics; simple logging integration.
Long-Term Applications
The following applications need additional research, scaling, or engineering to be practical at production scale.
- Long-horizon OPD for agentic reasoning and planning (software/AI engineering; robotics; operations research)
- Address reward quality decay with trajectory depth and late-token instability; develop methods to stabilize OPD beyond short reasoning spans.
- Dependencies: improved teacher conditional reliability on off-distribution prefixes; curriculum learning; new objectives that reweight later tokens.
- Adaptive on-policy curricula and teacher switching (software/AI engineering)
- Dynamically switch teachers or prompt distributions when overlap stagnates; use multi-teacher mixtures to ensure “new knowledge” is continuously available.
- Dependencies: fast teacher-evaluation routing; overlap-aware gating; mixture-of-policies infrastructure.
- Token-level reward shaping and geometry-aware objectives (academia; optimization research)
- Mitigate locally flat reward landscapes near the student’s policy; design alternative divergences or advantage schemes that amplify useful gradients in overlap regions.
- Dependencies: theoretical analysis of OPD geometry; efficient estimators that remain stable on deep trajectories.
- Self-distillation with privileged information for continual improvement (software/AI engineering; education tech)
- Use self-teaching variants (e.g., chain-of-thought with privileged context) while enforcing overlap growth and entropy controls to avoid collapse.
- Dependencies: privileged signals; guardrails for overfitting; monitoring tools.
- Overlap-aware data curation services (industry products; data vendors)
- Provide “teacher-aligned” prompt packs and schema translators for popular post-trained teachers; include entropy-preserving mixtures by design.
- Dependencies: licensing for teacher data schema; dedup pipelines; sector-specific compliance (HIPAA, GDPR).
- Standardized OPD reporting and compliance (policy; standards bodies)
- Create norms requiring disclosure of teacher provenance, alignment metrics, prompt mixture policy, and length schedules to prevent misleading benchmark gains (e.g., “higher scores ≠ new knowledge”).
- Dependencies: multi-stakeholder consensus; auditing capacity; regulator guidance.
- Safety and bias-aware OPD (policy; responsible AI; healthcare/legal)
- Ensure “thinking-pattern consistency” does not import unsafe or biased teacher behaviors; add bias audits focused on overlap regions where gradients concentrate.
- Dependencies: sector-specific safety checklists; bias detection in high-probability token sets; red-teaming infrastructure.
- Energy/performance trade-off optimizers (energy; green AI)
- Quantify compute savings vs. accuracy for OPD vs. RL at various lengths/k-values; develop planners that meet accuracy targets with minimal energy use.
- Dependencies: instrumentation of energy use; Pareto-optimization tools; standardized evaluation protocols.
- Cross-lingual and multi-modal OPD (education; accessibility; robotics)
- Extend overlap metrics and recipes to different vocabularies (languages) and modalities (text+vision+action) for broader accessibility and embodied tasks.
- Dependencies: shared representations or mapping layers; teacher capacity in multiple modalities; robust top-k intersection across vocabularies.
- Distillation-as-a-Service platforms (industry products)
- Offer managed OPD pipelines with overlap dashboards, cold-start SFT, prompt alignment, length scheduling, and regression detection.
- Dependencies: scalable teacher APIs; customer data governance; cost controls.
- Knowledge-gap estimators and teacher-auditing tools (academia; industry QA)
- Predict whether a candidate teacher offers “genuinely new capabilities” relative to a student before expensive OPD runs; approximate gap recovery potential.
- Dependencies: proxy tasks; calibration models linking metrics to expected improvement; teacher metadata access.
- Robust OPD for regulated domains (healthcare, finance, public sector)
- Blend OPD with verification layers (programmatic checking, tool-use), keeping overlap high while constraining unsafe trajectories in long outputs.
- Dependencies: tool integrations; domain validators; governance workflows.
Notes on Assumptions and Dependencies
Across applications, feasibility hinges on:
- Access to teacher logits/probabilities and compatible tokenization/vocabulary.
- Legal/licensing constraints around teacher models and post-training data (especially for teacher-aligned prompts).
- Reliable logging and evaluation (avg@16 sampling, standardized benchmarks) to compute overlap ratio, advantage, and entropy gap.
- Careful control of maximum response length and prompt mixtures to avoid late-token instability and entropy collapse.
- Teachers with genuinely new, transferable capabilities; same-pipeline teachers at larger scales may not provide useful signal despite higher scores.
- Sector compliance (HIPAA/GDPR in healthcare/finance) and safety/bias audits focused on high-probability overlap tokens where gradients concentrate.
Glossary
- Agentic settings: Contexts where models act autonomously and make extended chains of decisions; typically require robust long-horizon reasoning. "and point to the limitations of current OPD for long-horizon reasoning and agentic settings."
- Autoregressive factorization: Decomposing a sequence distribution into a product over conditional next-token distributions given the prefix. "Using the autoregressive factorization, this sequence-level objective admits the exact token-level decomposition:"
- Dense supervision: Training feedback given at many fine-grained points (e.g., every token) rather than sparsely at the end of a trajectory. "The appeal of OPD lies in its dense supervision, where every token receives a reward signal from the teacher, in contrast to the sparse outcome-level reward used in RL."
- Dense token-level reward: Per-token guidance signal provided by the teacher for each token in a generated sequence. "OPD's apparent free lunch of dense token-level reward comes at a cost, raising the question of whether OPD can scale to long-horizon distillation."
- Distributionally indistinguishable: Two models induce virtually the same probability distributions from a particular perspective or on certain states. "showing that same-family 1.5B and 7B teachers are distributionally indistinguishable from the studentâs perspective."
- Entropy gap: The absolute difference between the entropies (uncertainties) of two distributions at the same state. "and define the entropy gap as:"
- Entropy mismatch: A discrepancy between the confidence/uncertainty profiles of two policies on the same states. "By contrast, failing runs show stagnant overlap and persistent entropy mismatch from the outset."
- Exposure bias: A training-test mismatch where the model is only trained on teacher-generated prefixes but must generate its own at test time. "Unlike off-policy distillation, which trains the student on fixed teacher-generated sequences and suffers from exposure bias"
- Full-vocabulary OPD: An OPD variant that computes divergence over the entire token vocabulary at each step. "At the other extreme, one computes the divergence over the entire vocabulary at each prefix:"
- Gap recovery rate: The fraction of the teacher–student performance gap that is closed after training. "measured by the gap recovery rate $(\mathrm{Acc}_{\text{after OPD} - \mathrm{Acc}_{\text{before OPD}) / (\mathrm{Acc}_{\text{teacher} - \mathrm{Acc}_{\text{before OPD})$."
- GRPO: A specific reinforcement learning algorithm used to train teacher models in the study. "using GRPO"
- High-probability tokens: Tokens carrying most of the probability mass under a model’s distribution at a given step. "The high-probability tokens increasingly coincide (overlap ratio rising from 72\% to 91\%),"
- Knowledge distillation (KD): Transferring knowledge from a teacher model to a student by aligning their output distributions. "Knowledge distillation (KD) transfers knowledge from to "
- Kullback-Leibler (KL) divergence: A measure of how one probability distribution diverges from another. "A standard choice is the Kullback-Leibler (KL) divergence,"
- Local optimization geometry: The shape and properties of the loss landscape around the current policy that affect gradient-based updates. "the failure is not one of signal quality but of local optimization geometry."
- Long-horizon distillation: Distillation over extended sequences where errors or drift can accumulate across many steps. "raising the question of whether OPD can scale to long-horizon distillation."
- Monte Carlo estimator: A stochastic estimator that approximates an expectation using sampled outcomes. "sampled-token OPD uses an unbiased Monte Carlo estimator of each token-level KL term,"
- Mode mismatch: A situation where the student and teacher place probability mass on largely different sets of likely tokens. "suggesting significant policy divergence or ``mode mismatch''."
- Off-policy cold start: A warmup phase that distills the student on teacher-generated data before switching to on-policy training. "off-policy cold start"
- Off-policy distillation: Training the student on fixed sequences generated by the teacher rather than on student-generated rollouts. "Unlike off-policy distillation, which trains the student on fixed teacher-generated sequences"
- On-Policy Distillation (OPD): Distillation where the student generates trajectories and is trained using the teacher’s feedback on those student-visited states. "On-Policy Distillation (OPD) computes supervision on trajectories"
- Out-of-distribution prompts: Prompts that are outside the teacher’s post-training data distribution, used to maintain diversity/entropy. "necessitates mixing with out-of-distribution prompts."
- Overlap ratio: The fraction of shared tokens between the student’s and teacher’s top-k sets at a step. "A low overlap ratio indicates that the student's probability mass is concentrated on a disjoint set of tokens from the teacher"
- Overlap-Token Advantage: A metric capturing how well the student’s probabilities align with the teacher’s within the shared top-k tokens. "Overlap-Token Advantage."
- Policy entropy: A measure of randomness in a policy’s action distribution; lower entropy means more peaked/confident predictions. "to preserve policy entropy and maintain the studentâs capacity for exploration."
- Privileged information: Extra information available to the teacher in self-distillation setups that is not available to the student at inference. "a single model serves as its own teacher given privileged information"
- Reinforcement learning (RL): Learning via reward signals, often at the outcome level, to improve a policy. "outcome-reward reinforcement learning (RL)"
- Renormalized distributions: Distributions reweighted to sum to one over a restricted subset of tokens. "Define the renormalized student and teacher distributions on as:"
- Reverse distillation: Distilling from a weaker or earlier-stage model into a stronger or later-stage student to analyze dynamics. "reverse distillation experiments"
- Reverse KL divergence: The KL divergence computed as D_KL(student || teacher), emphasizing matching the student’s support to the teacher’s. "sequence-level reverse KL"
- Reverse-KL updates: Gradient steps induced by minimizing reverse KL, which tend to concentrate mass where the teacher places mass. "reverse-KL updates concentrate more mass on it,"
- Reward landscape: The structure of rewards over policy space that influences optimization dynamics and convergence. "A larger teacher may induce a reward landscape that is locally flat around the student's policy,"
- Reward quality: The reliability and usefulness of the teacher’s token-level signals for guiding learning. "We show that reward quality degrades systematically with trajectory depth"
- Rollouts: Sequences generated by a model (policy) when interacting with prompts or environments. "has the student generate its own rollouts"
- Self-distillation: A paradigm where a model acts as its own teacher (e.g., with extra information) to improve itself. "this has been extended to self-distillation settings where a single model serves as its own teacher"
- Subset KL divergence: KL divergence computed on a restricted subset (e.g., top-k tokens) rather than over the full vocabulary. "Distillation is then performed by minimizing the subset KL divergence"
- Supervised fine-tuning (SFT): Training a model to match ground-truth or teacher-provided outputs via supervised learning. "conventional supervised fine-tuning (SFT)"
- Support region: The set of tokens/actions where a model concentrates most of its probability mass. "implies the student has successfully located the teacher's support region."
- Student-visited states: Prefixes/states encountered along trajectories generated by the current student policy. "progressively more similar on student-visited states."
- Symmetric difference: The set of elements in either of two sets but not in their intersection. "which restricts optimization to their symmetric difference "
- Teacher-aligned prompts: Prompts drawn from or resembling the teacher’s post-training data, used to improve alignment. "teacher-aligned prompts"
- Teacher continuation: Having the teacher continue a student prefix to assess or improve outcomes. "Accuracy gain from teacher continuation under different student prefix truncation lengths."
- Thinking-pattern consistency: Compatibility between the student’s and teacher’s reasoning styles or token preferences. "Thinking-pattern consistency: the student and teacher should share consistent thinking patterns"
- Token-level mechanism: The underlying per-token dynamics by which OPD drives student–teacher alignment. "Probing into the token-level mechanism, we show that successful OPD is characterized by progressive alignment"
- Top‑k OPD: An OPD variant that computes divergence on only the top‑k tokens (e.g., by the student), reducing cost while focusing on high-probability mass. "Top- OPD provides an intermediate design between sampled-token and full-vocabulary OPD"
- Top‑p (sampling): Nucleus sampling that restricts choices to the smallest set of tokens whose cumulative probability exceeds p. "top- 0.95,"
- Trajectory depth: The position within a generated sequence; deeper positions correspond to later tokens in long responses. "Reward Quality Degrades with Trajectory Depth"
- Trajectory-level objective: An objective defined over entire generated sequences rather than individual tokens. "yielding the trajectory-level objective:"
- Weak-to-strong reverse distillation: Distillation experiments where a weaker model supervises a stronger one to probe mechanisms. "weak-to-strong reverse distillation"
Collections
Sign up for free to add this paper to one or more collections.