- The paper introduces a dual-path adaptive weighting framework that calibrates supervision by routing student rollouts based on teacher and student perplexity.
- It empirically demonstrates an average 11.42% improvement in multi-sample accuracy while mitigating the Pass@k paradox relative to conventional methods.
- The study establishes a paradigm shift by dynamically filtering teacher noise, preserving reasoning diversity, and achieving robust LLM alignment.
Signal-Calibrated On-Policy Distillation: SCOPE Framework for LLM Reasoning Alignment
On-policy reinforcement learning with verified rewards has substantially boosted LLM reasoning capabilities but suffers from sparse, outcome-level credit assignment, particularly undermining token-level optimization in lengthy generation tasks. On-Policy Distillation (OPD), which overlays dense token-level KL supervision from a teacher model on student rollouts, improves convergence and stability but is hampered by two structural flaws: (1) uniform supervision fails to differentiate signal quality across rollouts, and (2) indiscriminate distillation amplifies dominant reasoning modes while marginalizing diverse, unconventional paths, leading to mode collapse and compounding the Pass@k paradox.
SCOPE introduces a dual-path adaptive weighting framework to calibrate supervision according to rollout correctness and signal quality. For incorrect student trajectories, teacher-guided weighting is implemented based on teacher perplexity, prioritizing those rollouts where the teacher provides low-entropy, meaningful correction, and discounting high-perplexity cases where the teacher is confused or hallucinating. For correct trajectories, student-guided weighting is applied using student perplexity to reinforce responses at the capability boundary (i.e., those with low student confidence), preserving unexplored valid reasoning routes and preventing diversity collapse.
Empirical Analysis and Motivation
Analysis of the Pass@k paradox demonstrates that optimizing for correct responses uniformly (e.g., via PSR or standard OPD) leads to a trade-off: Pass@1 (top-1 accuracy) improves, but Pass@32 (multi-sample diversity) declines (Figure 1). This is explained by reinforcement that overly sharpens the policy toward high-probability solutions, extinguishing rare but valid alternatives.
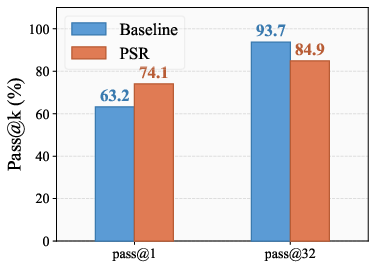
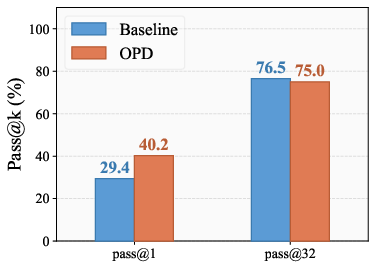
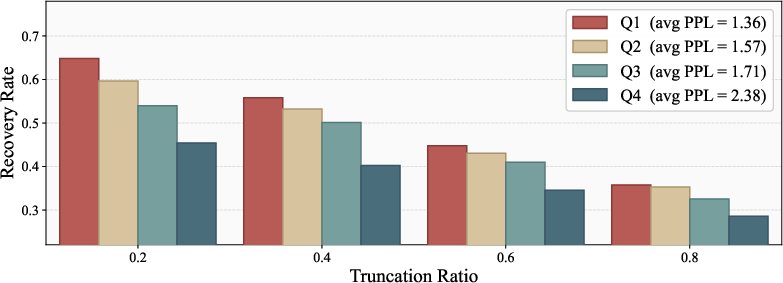
Figure 1: Qwen2.5-7B (PSR) shows Pass@1 improves but Pass@32 declines during reinforcement, exemplifying the Pass@k paradox.
Further, error recovery experiments stratifying incorrect student rollouts by teacher perplexity demonstrate that only those with low teacher perplexity are efficiently rectified (up to +19.4% higher recovery rate), while high-perplexity contexts degrade teacher guidance into noise. Thus, uniform distillation not only ignores this stratification but forcibly propagates teacher hallucinations, compromising downstream model fidelity.
SCOPE Framework: Architecture and Objective
SCOPE routes student rollouts by correctness into two branches:
- Correct Trajectories: Weighted MLE based on student perplexity amplifies supervision on low-confidence, boundary responses, encouraging exploration of unconventional valid reasoning paths.
- Incorrect Trajectories: KL distillation weighted inversely by teacher perplexity up-weights structurally coherent prefixes and discounts context-induced noise, filtering out misleading corrections.
A group-level normalization is applied within each prompt batch to ensure adaptive calibration of weighting across prompts of varying difficulty.
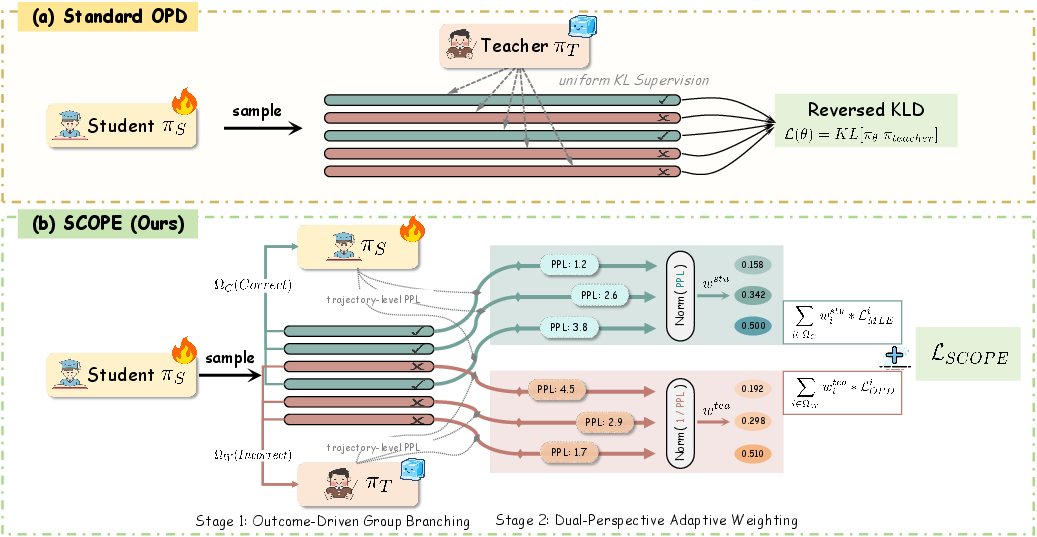
Figure 2: SCOPE pipeline routing rollouts into correct and incorrect branches, applying dual-path adaptive weighting, and integrating via a unified objective.
Mathematically, student-guided and teacher-guided weights are derived from softmax-normalized (prompt group) sequence perplexity, controlled by a temperature hyperparameter τ. Ablation experiments confirm that removal or reversal of either weighting direction substantially impairs performance, empirically validating the complementarity and necessity of DPAW.
Experimental Validation and Ablation
Extensive experiments across six mathematical reasoning benchmarks (AIME24, AIME25, AMC23, MATH500, Minerva, OlympiadBench) demonstrate that SCOPE achieves a consistent average relative improvement of 11.42% in Avg@32 and 7.30% in Pass@32 over strong baselines, notably GRPO and OPD. The superiority is particularly pronounced in multi-sample settings, where SCOPE preserves reasoning diversity and robustly scales Pass@k as k increases.
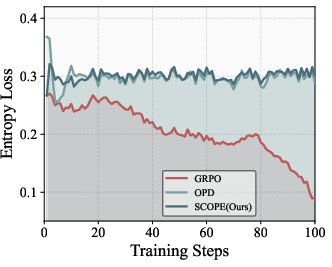
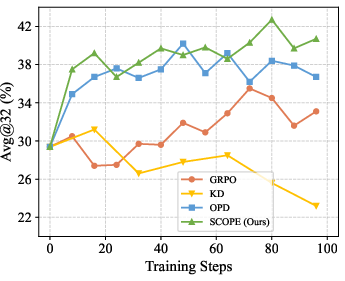
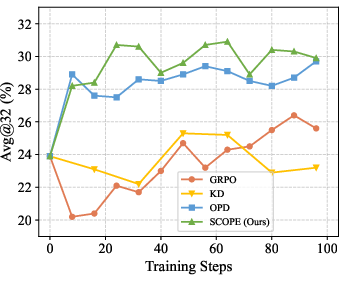
Figure 3: Dynamics of entropy loss illustrate that GRPO causes rapid entropy decay (mode collapse), while SCOPE sustains healthy policy entropy and sample diversity.
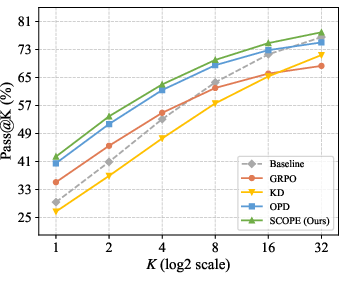
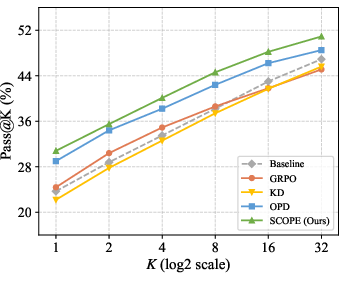
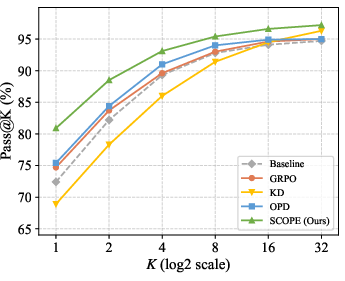
Figure 4: Pass@k on AIME24 indicates SCOPE’s superior scaling with multi-sample generation compared to OPD and GRPO.
SCOPE's performance remains optimal under weight temperature τ=1.0, with extreme temperature values degrading either diversity (overly sharp weights) or signal quality (overly flat weights). Training efficiency remains competitive, with the main computational overhead stemming from teacher scoring for KL distillation, which can be mitigated through asynchronous architectures.
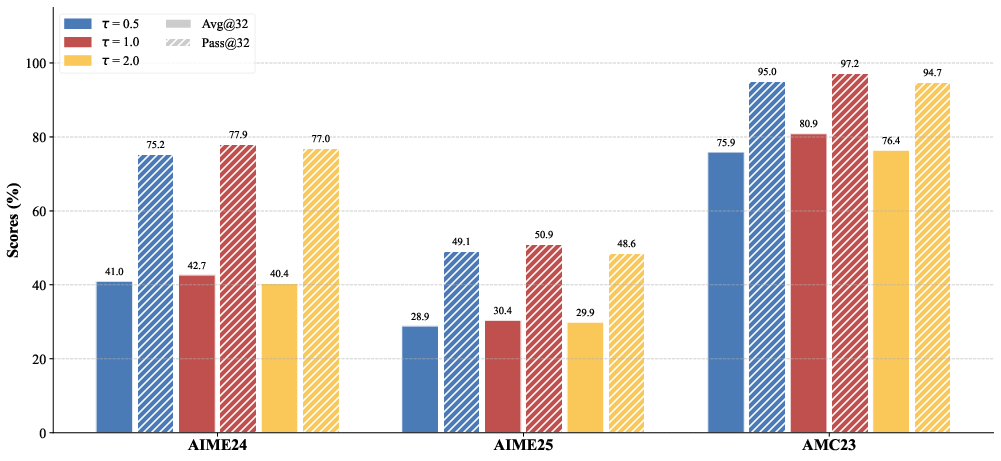
Figure 5: Impact of temperature τ on model performance across benchmarks empirically validates τ=1.0 as optimal for balancing signal calibration and diversity.
Theoretical and Practical Implications
SCOPE fundamentally redefines token-level supervision in post-training LLM alignment by introducing signal quality awareness. The dual-perspective weighting rigorously suppresses confirmation bias and hallucinated signals, which standard OPD and RL-KD hybrids naively reinforce, and simultaneously sustains a rich exploration space for valid reasoning routes. This architecture is applicable to domains with verified outcome rewards and teacher models of variable reliability, providing a general template for signal-calibrated distillation.
Practically, SCOPE sets new upper bounds in mathematical reasoning benchmarks, illustrating its utility for compact LLMs with limited capacity for credit assignment and diversity preservation. Theoretically, it introduces a paradigm shift from uniform to stratified supervision, opening avenues for further refinement with dynamic weighting (e.g., online confidence estimation) or adaptive teacher selection (e.g., ensemble distillation).
Conclusion
SCOPE demonstrably advances on-policy distillation in LLM reasoning alignment by routing rollouts according to correctness and calibrating supervision via dual-path adaptive weighting. Extensive empirical analysis substantiates its capacity to preserve reasoning diversity, filter teacher hallucinations, and optimize for signal quality. Both methodological and practical implications point toward more robust, efficient post-training strategies for LLMs, with future developments likely to generalize SCOPE’s principles to diverse alignment domains and composite reward landscapes.