- The paper introduces Aurora, a unified system that couples online speculative inference with asynchronous RL-style training for real-time adaptation.
- It leverages a novel Tree Attention mechanism and token-level supervision to optimize draft model proposals, achieving significant improvements in acceptance length and throughput.
- Experimental results demonstrate day-zero adaptation, reduced serving latency, and scalable performance across diverse batch sizes and large frontier models.
Unified Online Speculative Decoding via RL: Aurora System Analysis
Motivation and Problem Framing
Online deployment of LLMs is increasingly limited by inference bottlenecks. Speculative decoding, which leverages a lightweight draft model to propose multiple tokens and a stronger verifier to select the longest matching prefix, is a prominent system optimization. The effectiveness of speculative decoding depends on tight alignment between draft and verifier, quantified as the acceptance rate and lookahead span. However, typical deployment architectures use a separated two-stage pipeline for offline draft model training and online serving. This split leads to elevated time-to-serve, persistent training-serving mismatches, pronounced staleness from target-model drift, and excessive infrastructure overhead.
The paper introduces Aurora, a unified system architecture that tightly couples online speculative inference with asynchronous RL-style training, effectively reframing speculative decoding as a joint learning-and-serving problem. Aurora enables day-zero support (serving with untrained speculators), direct mitigation of distribution mismatch, reduced memory footprint, algorithmic agnosticism, and support for heterogeneous request traffic.
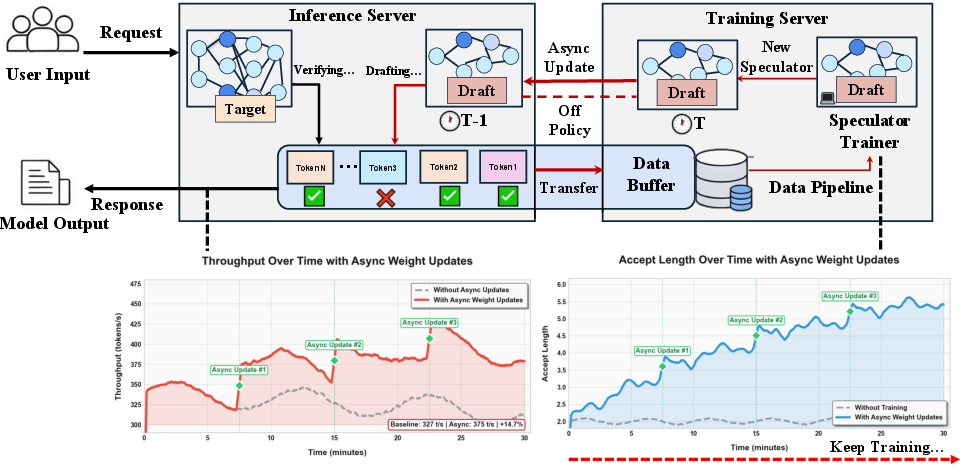
Figure 1: Aurora system architecture integrates speculative decoding inference and RL-style asynchronous speculator updates, with minimal serving disruption and stable throughput adaptation.
System Architecture and Technical Design
Aurora consists of decoupled inference and training servers. The inference server executes real user traffic using the SGLang engine with speculative decoding—draft model proposals undergo verification against the target model, and both acceptance and rejection traces are streamed to a distributed buffer. Hidden state transfer is optimized by only forwarding compressed representations and filtered logits as needed. The training server asynchronously aggregates experience and updates the speculator, pushing revised weights via hot-swap to the inference server. The communication is implemented using batched GPU-aware RPC (TensorPipe), minimizing memory fragmentation and latency. Aurora’s architecture enables parallel training/serving, rapid hot-swaps, and horizontal scaling to distributed environments, including disaggregated serving stacks.
The training pipeline utilizes a novel Tree Attention mechanism, allowing efficient batched computation of speculative decoding trees (including all accepted and rejected branches), optimized for token-level gradients. Supervision comprises acceptance imitation and rejection-based counterfactual loss, accomplished via reverse KL and discard sampling with top-k filtering, resulting in dense and reward-aligned learning signals.
Speculative decoding is mapped onto an asynchronous RL paradigm. The draft model functions as a policy π, and the target-verifier acts as the environment, delivering accept/reject outcomes as reward signals. The objective is not traditional RL throughput but serving efficiency—maximizing expected acceptance per request and minimizing latency under production constraints. Aurora employs “lazy” synchronization to avoid inference disruptions, allowing controlled staleness and stable adaptation over online traffic. Domain shift, induced by abrupt workload changes, is treated as the primary failure mode—rapid adaptation is necessary for sustained acceptance rates and throughput.
Day-Zero Speculator Adaptation and Policy Synchronization
Aurora enables deployment of a randomly initialized speculator from day zero. Experiments with a multi-domain prompt stream (math, SQL, code, finance, instruction) reveal rapid adaptation: in both mixed and ordered traffic scenarios, acceptance length and throughput recover and surpass static pretrained baselines within thousands of requests.
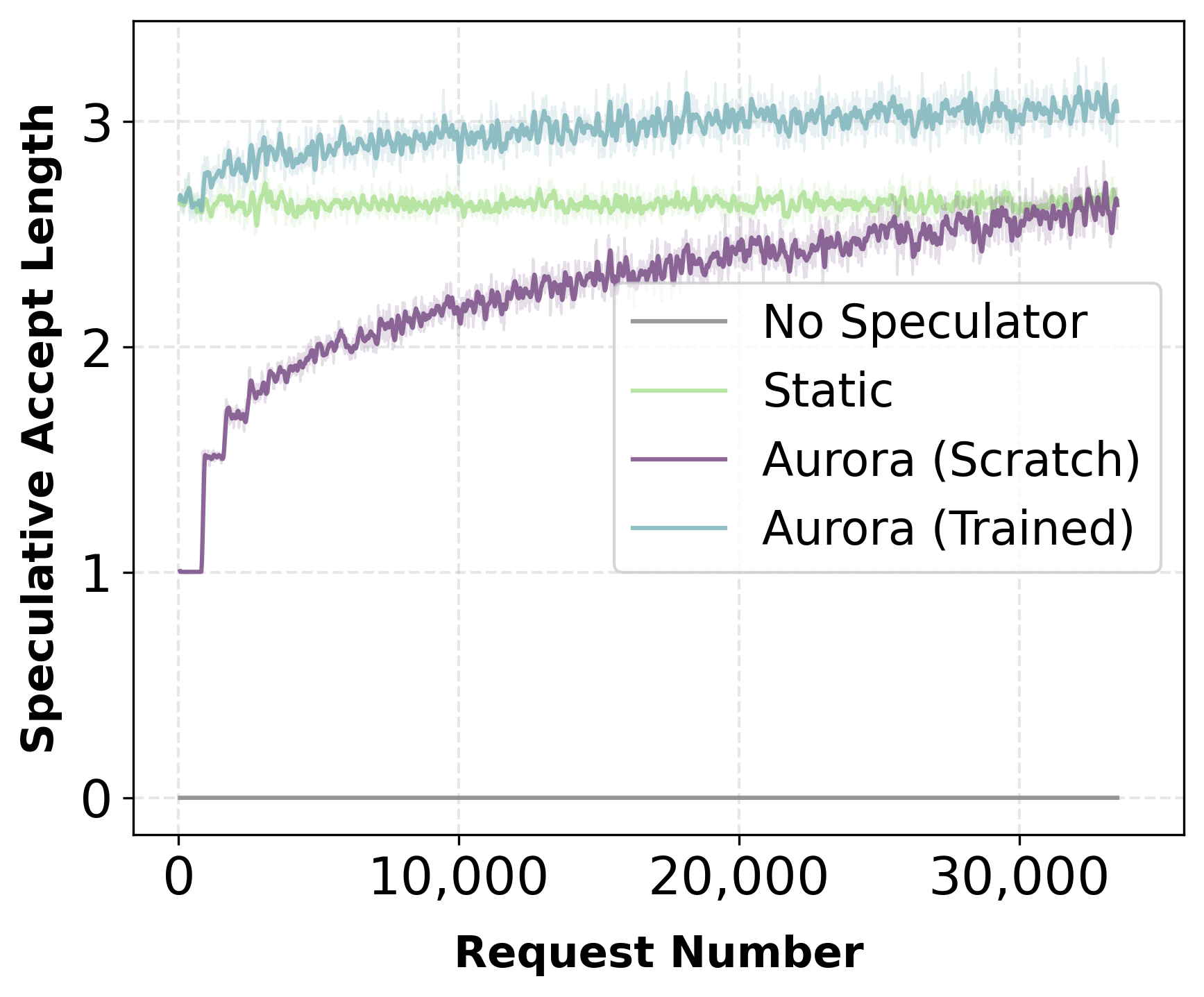
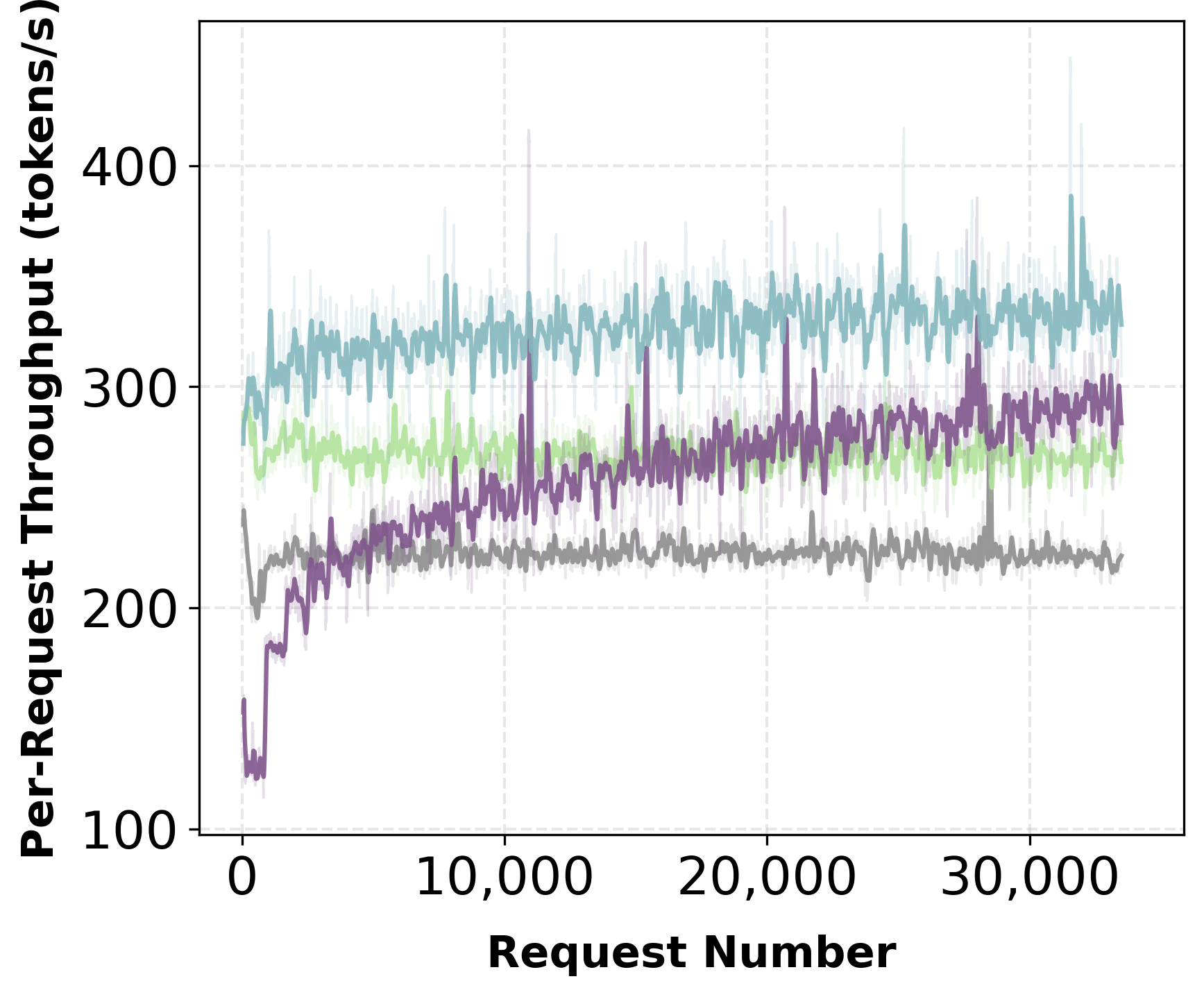
Figure 2: Mixed traffic—day-zero adaptation rapidly increases acceptance length and throughput, converging with or exceeding the static baseline.
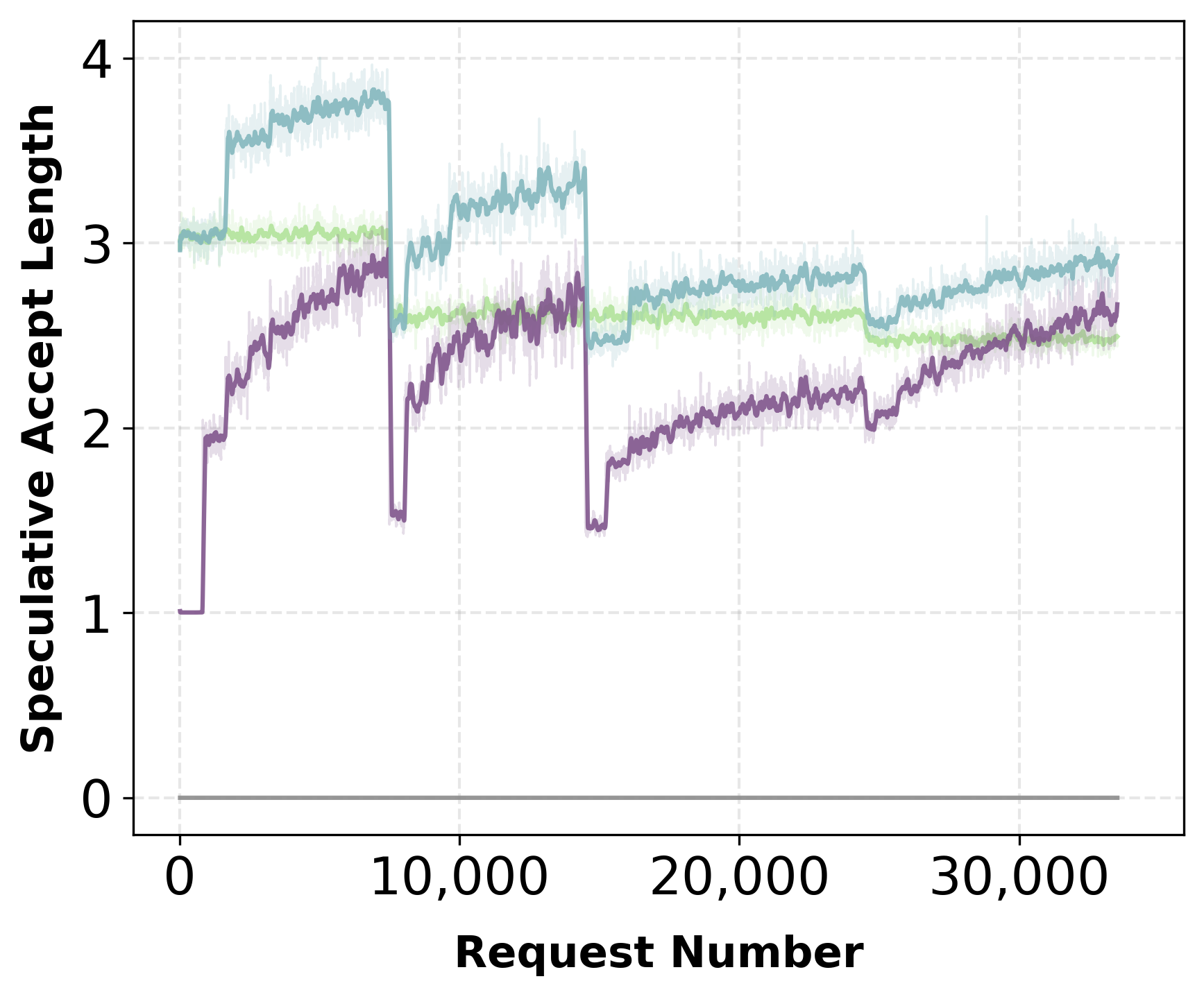
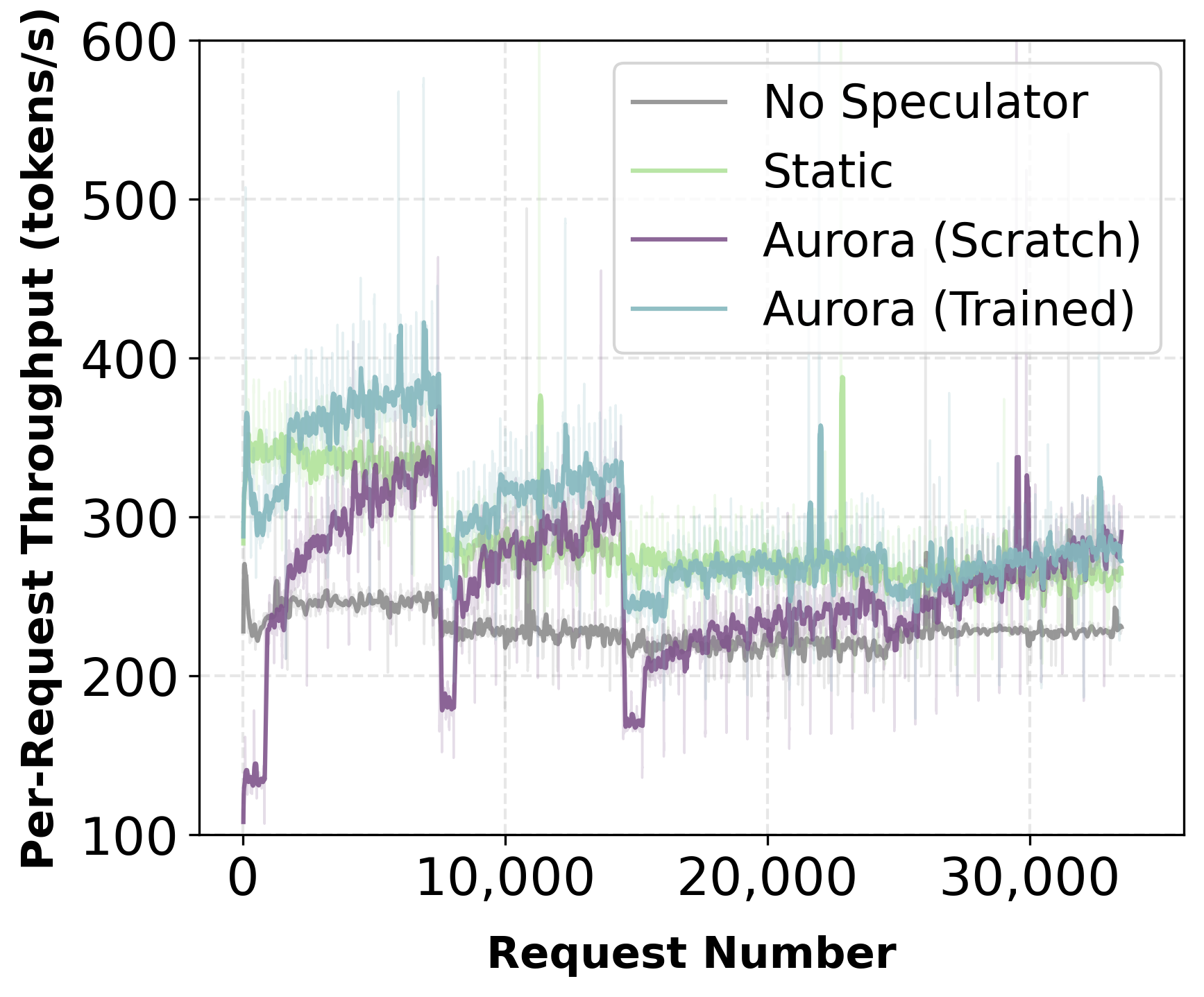
Figure 3: Ordered traffic—speculator adapts quickly under domain shift, acceptance rate achieves baseline levels despite abrupt changes.
A sweep of synchronization intervals quantifies the adaptation-throughput tradeoff. Aggressive updates recover acceptance length faster but incur higher serving overhead; moderately lazy schedules yield a strong Pareto optimum, preserving nearly all adaptation benefits with minimal throughput degradation.
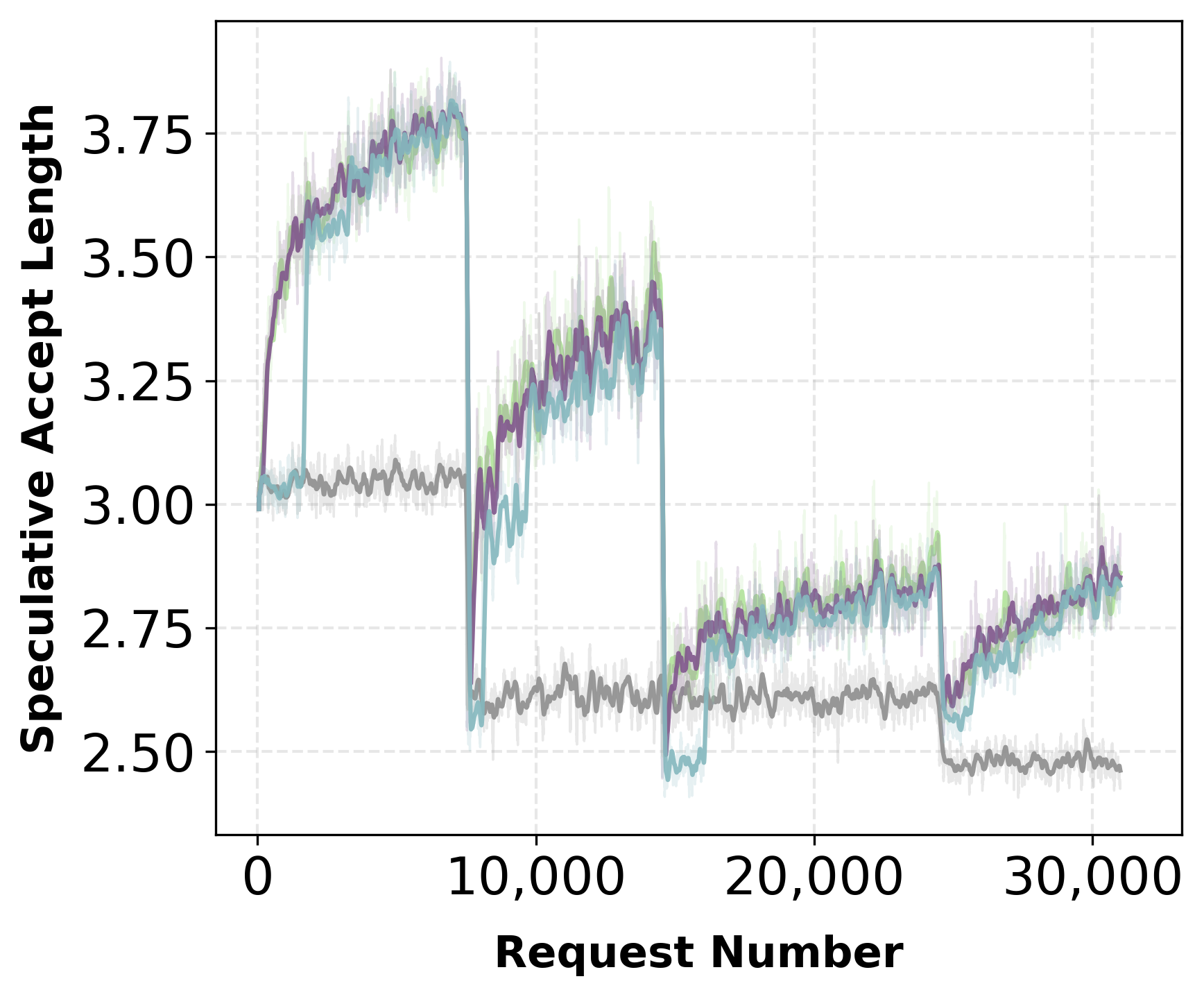
Figure 4: Synchronization schedule—moderate refresh preserves throughput while recovering acceptance, providing practical policy refresh intervals.
Ablation Studies: Training Objectives and Lookahead
Multiple online adaptation strategies were evaluated: static frozen drafts, online fine-tuning with forward/reverse KL, auxiliary next-token prediction, and discard-token learning. The dominant gains are realized through online fine-tuning and on-policy updates. Incorporation of discarded tokens yields only marginal improvement unless the lookahead is increased—only under aggressive speculative settings do rejection-based objectives contribute substantial gains.
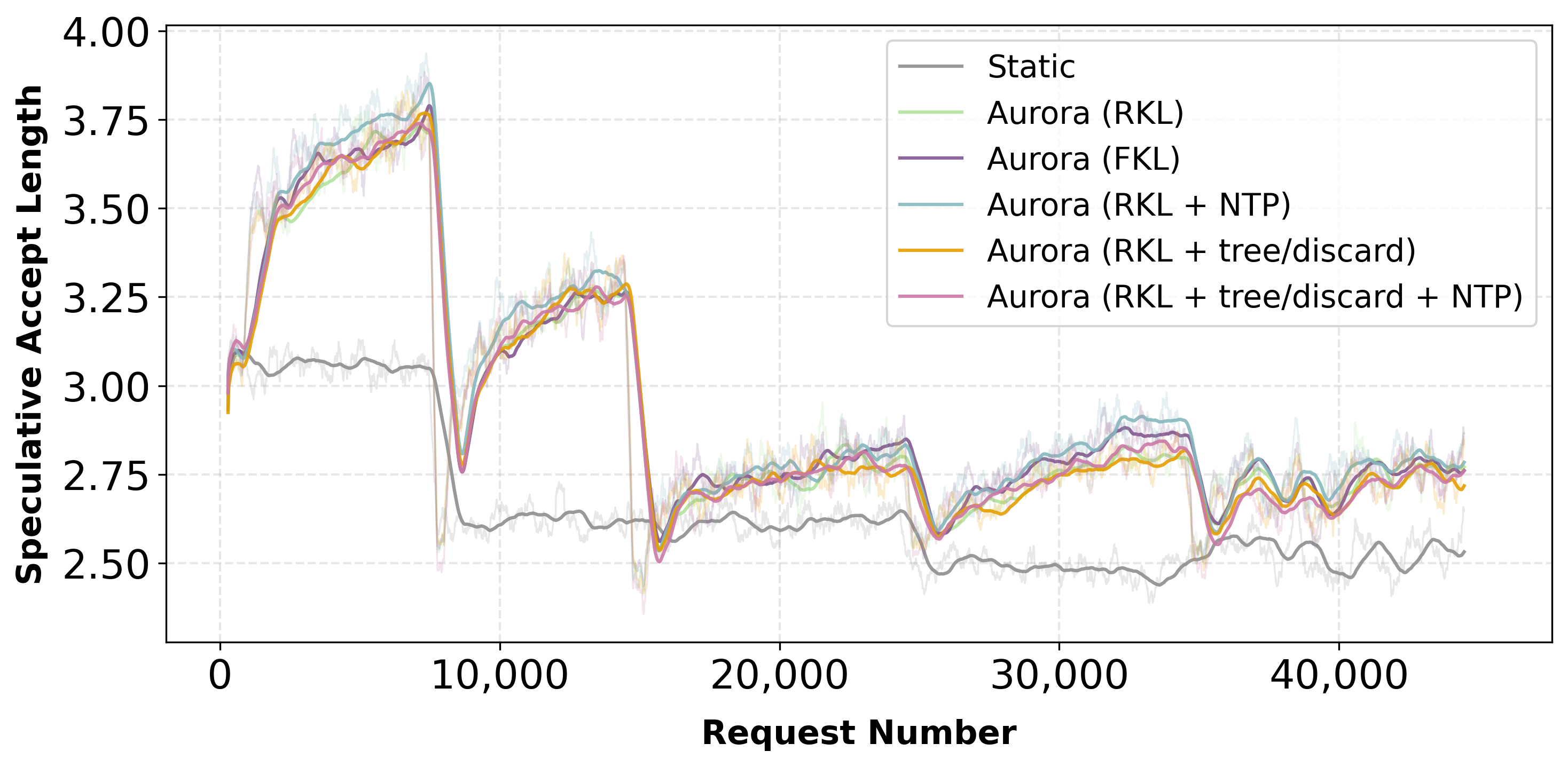
Figure 5: Acceptance length for Qwen-8B-Instruct—online fine-tuning consistently outperforms static baselines, discard and tree-based objectives add minimal extra benefit under domain shift.
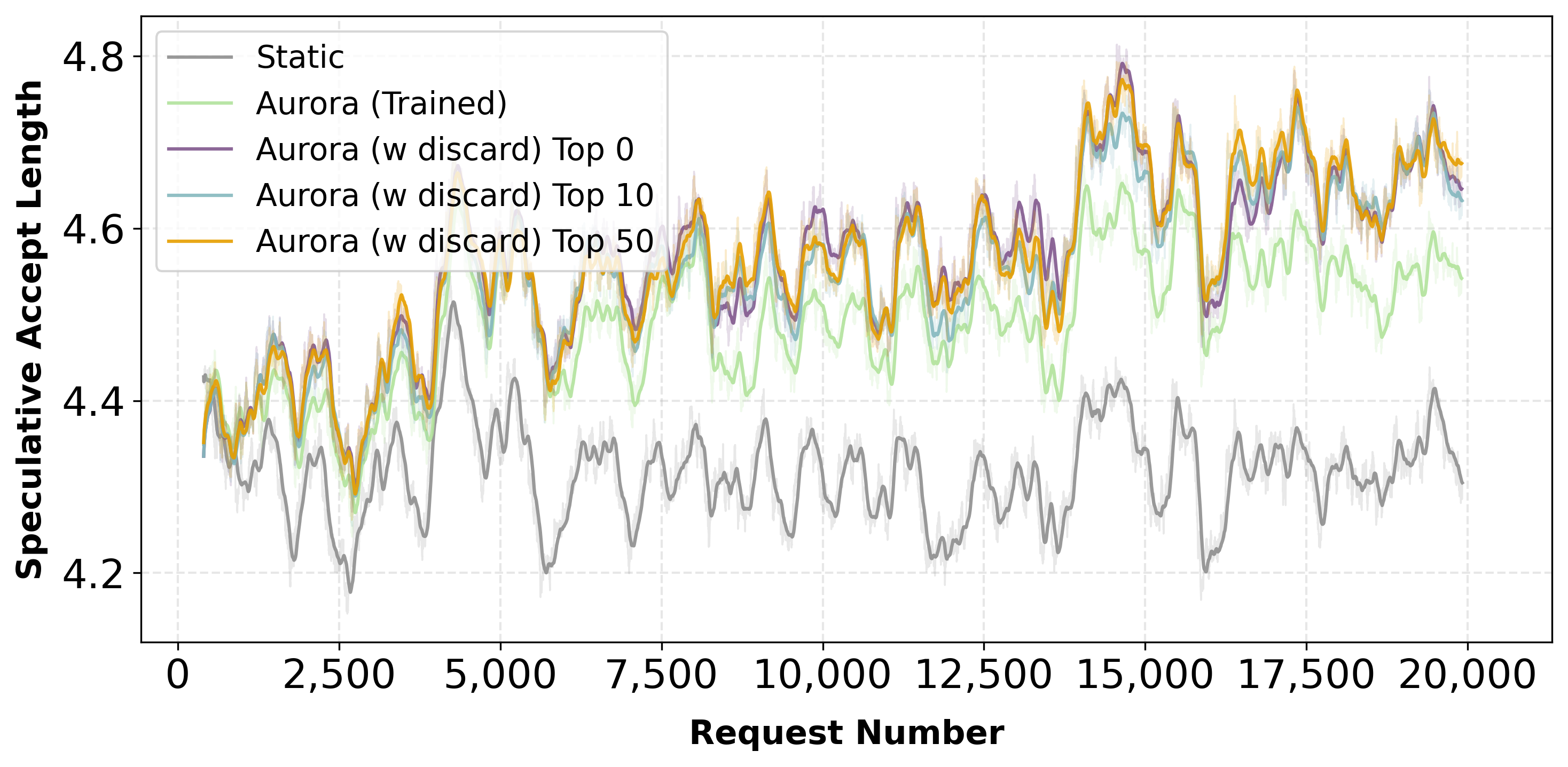
Figure 6: Llama-3.1-8B-Instruct—lookahead=10, discard token training yields additional acceptance length, but top-k strategies are nearly indistinguishable, supporting efficient memory usage.
Analysis on batch size demonstrates that Aurora’s throughput benefit is maximized under low hardware utilization regimes (small batch sizes). As batch size grows, speculative overhead dominates and the speedup diminishes.
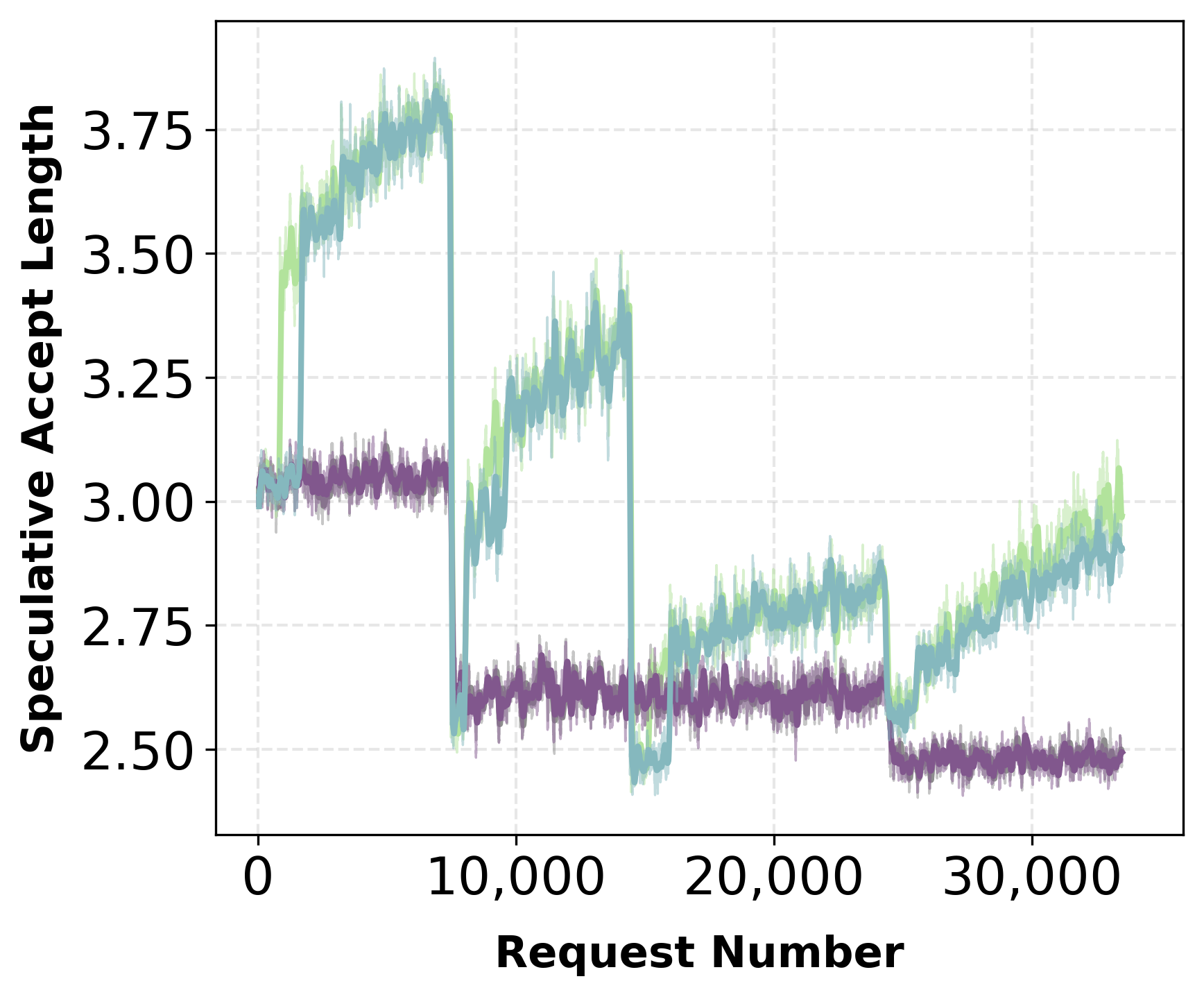

Figure 7: End-to-end throughput as a function of batch size—Aurora achieves larger proportional speedups at low batch sizes due to inference bottlenecks.
Large Model Scaling and Algorithmic Generality
Aurora was benchmarked on major open-source frontier models, including MiniMax M2.1 and Qwen3-Coder-Next (both large MoE designs with extended context windows and large expert routing). The system scales efficiently: mean accepted draft length of 2.8–3 is achieved, translating into 1.45×–1.21× throughput improvement over the baseline, with largest gains at batch size 1–8 and modest regression at batch size 32 due to verification overhead.


Figure 8: MiniMax M2.1—Aurora (Scratch) demonstrated sustained acceptance length and 1.45× throughput uplift.
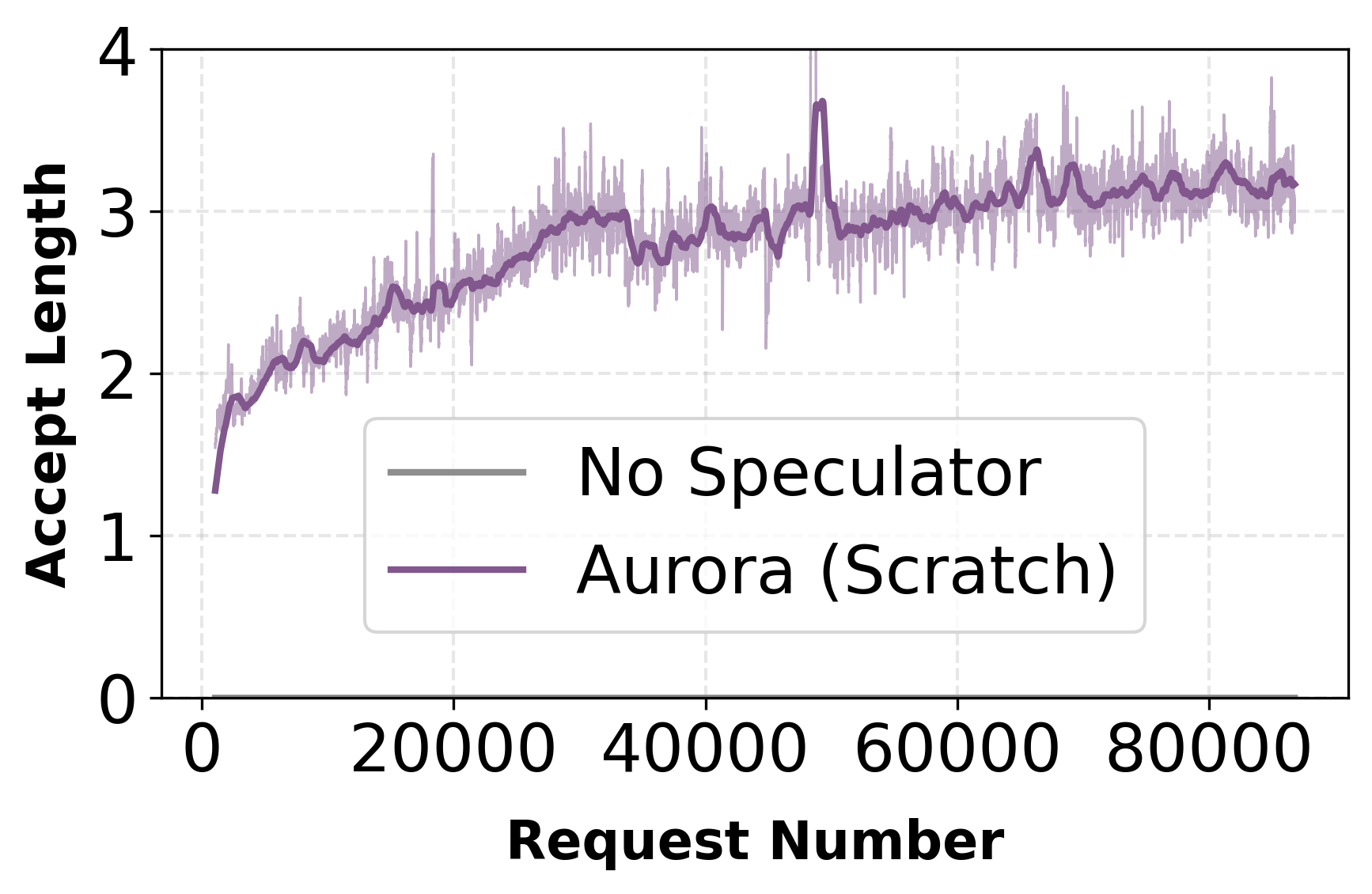
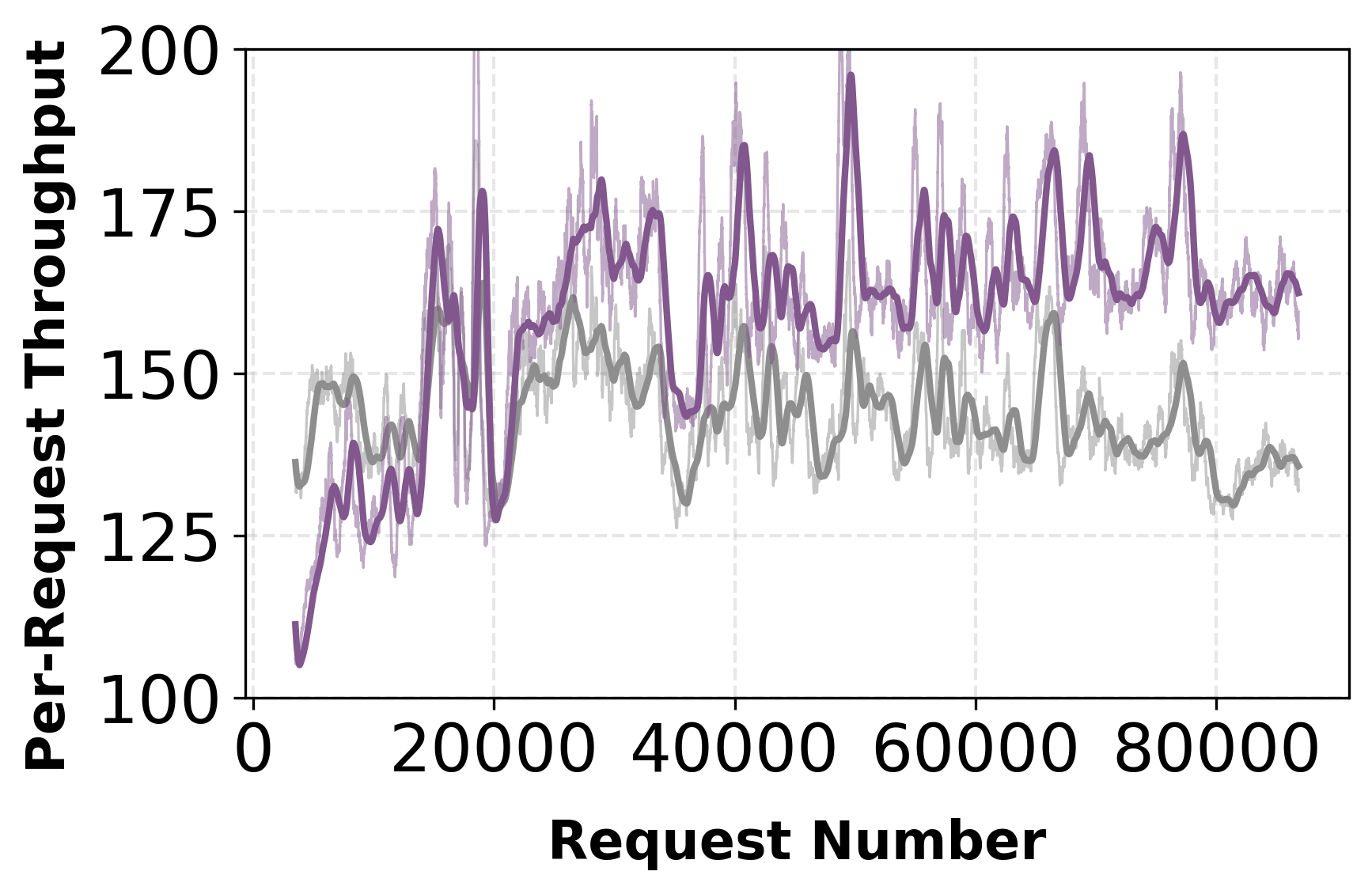
Figure 9: Qwen3-Coder-Next—Aurora (Scratch) raises acceptance length above 3 and delivers 1.23× throughput improvements at moderate batch size, robust under hybrid TP/EP parallelism.
These results show that Aurora is robust across architectures and context lengths, with future directions suggested for speculative kernel optimizations and algorithmic advances.
Practical and Theoretical Implications
Aurora’s unified approach resolves longstanding deployment barriers: training-serving mismatch, verifier drift, memory overhead, and multi-domain adaptation. Serving-time training enables immediate on-policy adaptation, directly tracking the production distribution. The algorithmic neutrality allows future speculative decoding variants to be seamlessly integrated, with scalable deployment across distributed clusters and disaggregated stacks.
Theoretically, the RL-style asynchronous adaptation demonstrates that reward-aligned online updates offer maximal attainable efficiency gains, and that serving-time adaptation requires principled synchronization policy design—a departure from naively aggressive RL actor-learner paradigms. The dominance of token-level objectives under realistic domain shift, and the marginal impact of tree-based supervision, highlight practical boundaries in learning signal design for speedup-centric optimization.
Conclusion
Aurora represents a paradigm shift in speculative decoding: the system closes the loop between inference and training, enabling continuous adaptation via RL-aligned asynchronous updates. Day-zero serving with rapid convergence, robust scalability across large frontier models, and precise throughput-acceptance tradeoffs, position Aurora as an enabling infrastructure for production LLM deployment and future speculative algorithm research. The results strongly suggest that offline pretraining cycles are unnecessary for draft models; efficient online adaptation suffices, fundamentally challenging ex ante assumptions underlying the speculative decoding literature.
(2602.06932)

