- The paper presents a dual-mode framework that fuses few-step and multi-step autoregressive diffusion to eliminate reliance on teacher-forcing for efficient streaming generation.
- It leverages a hybrid self-distillation strategy (combining DMD and ShortCut) to enhance train-inference consistency and robust cross-modal synchronization.
- Empirical results demonstrate superior audio-video alignment and real-time throughput (up to 30 FPS) compared to traditional models.
Mutual Forcing: Dual-Mode Self-Evolution for Efficient Streaming Audio-Video Generation
Introduction and Problem Analysis
"Mutual Forcing: Dual-Mode Self-Evolution for Fast Autoregressive Audio-Video Character Generation" (2604.25819) addresses critical bottlenecks in joint audio-video generation, specifically: (1) robust cross-modal synchronization on long horizons, and (2) practical frame-wise streaming generation with low inference cost. Previous paradigms, such as teacher-forcing and self-forcing, suffer from tractability, scalability, and performance degradation over long sequences, primarily due to train-inference mismatches and a reliance on computationally intensive teacher architectures that limit duration and generalization.
The Mutual Forcing framework eliminates these bottlenecks by uniting few-step and multi-step autoregressive diffusion within a single weight-shared backbone, integrating self-evolution, self-distillation, and flexible sequence-length training for improved train-inference consistency and real-time throughput.
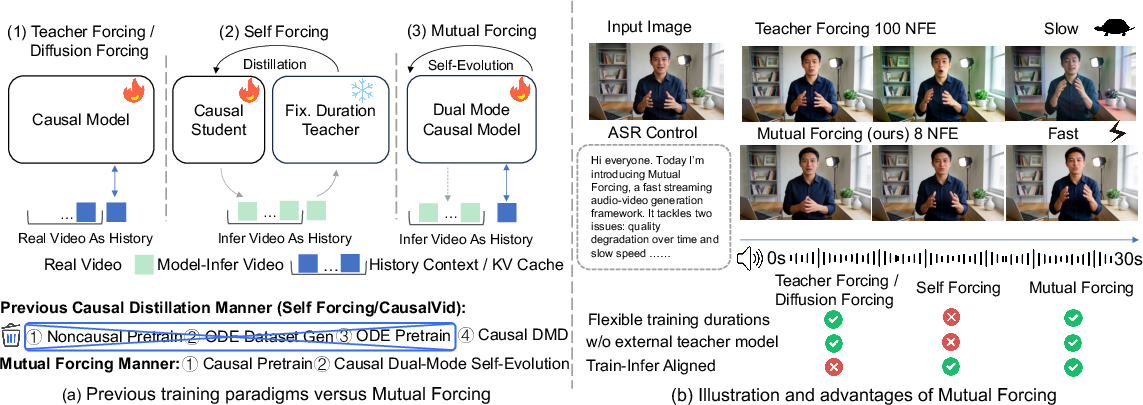
Figure 1: Schematic comparison of prior training paradigms and the Mutual Forcing framework, emphasizing the removal of bidirectional teachers and self-distillation within a native causal model for efficient long-horizon streaming generation.
Methodology: Dual-Mode, Weight-Shared Streaming Diffusion
The architecture consists of dual uni-modal branches (audio and video) initially pretrained independently, which then undergo supervised joint training with coupled self-attention for direct cross-modal token interaction. This design is explicitly tailored for efficient, temporally aligned autoregressive generation.
Central to the method is the dual-mode (Few-step and Multi-step) operational regime within a single parameterization:
- Multi-step Mode: Standard diffusion ODE process with dense, small-step velocity field updates for high-quality denoising.
- Few-step Mode: Coarse, large-step interval predictions trained via a hybrid self-distillation objective combining DMD and ShortCut strategies, using the Multi-step mode as an in-situ teacher (with gradients stopped).
Context generation for each step uses Few-mode inference to provide model-predicted history for Multi-mode supervision, ensuring that all learning incorporates the model's own inference errors—essential for closing exposure bias loops.
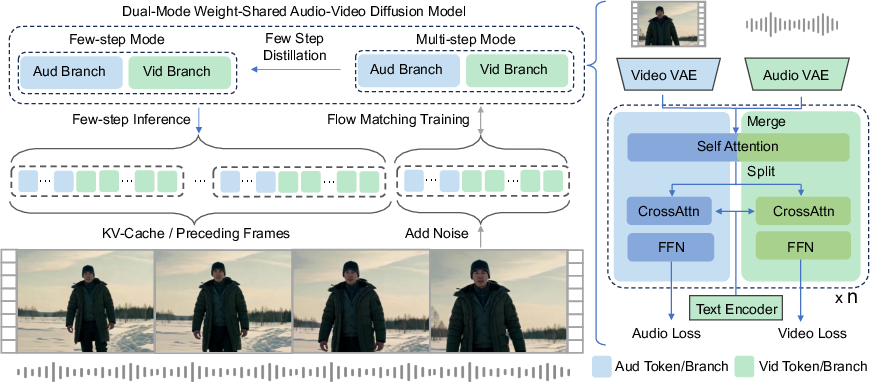
Figure 2: Mutual Forcing pipeline: multi-step and few-step modes operate in tandem, both modes sharing weights, with self-distillation and train-inference consistency objectives for each streaming chunk.
Hybrid self-distillation is critical for few-step accuracy: DMD provides strong quality in extremely shortened schedules, while the ShortCut (SC) loss guarantees stability and convergence. Their combination yields robust, high-speed inference without loss of fidelity.
Empirical Results
Quantitative Evaluation
Comprehensive benchmarks on long-duration audio-video generation show that Mutual Forcing achieves comparable or superior metrics in audio-video alignment (LSE-C), video quality (MS, AS, ID), and audio quality (PQ, PC, CE, CU) against both domain-specific (e.g., Fantasy-Talking, Omni-Avatar, Wan-S2V) and joint generation baselines (e.g., Universe-1 [wang2025universe], Ovi [low2025ovi]), often with only 4–8 function evaluations (NFEs) compared to 50–100 in baselines. Notably, Mutual Forcing eschews the need for classifier-free guidance (CFG), further halving compute.
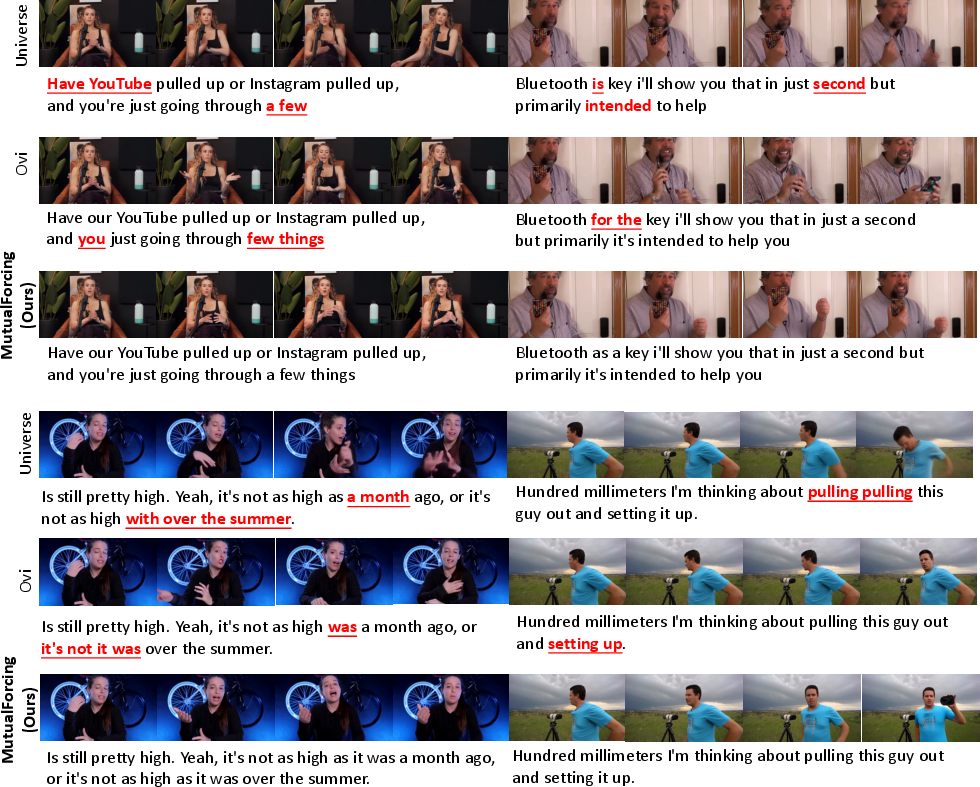
Figure 3: Qualitative audio-video generation comparisons with Universe-1 and Ovi; Mutual Forcing demonstrates superior audio-visual synchrony and speech-to-visual fidelity at drastically reduced sampling cost.
Qualitative and Human Study Analysis
Mutual Forcing's generated sequences preserve lexical and prosodic integrity over long runs and display enhanced visual continuity. This is corroborated by human preference studies, where Mutual Forcing achieves higher win rates in visual preference, audio alignment, and overall quality assessment relative to leading competitive models.
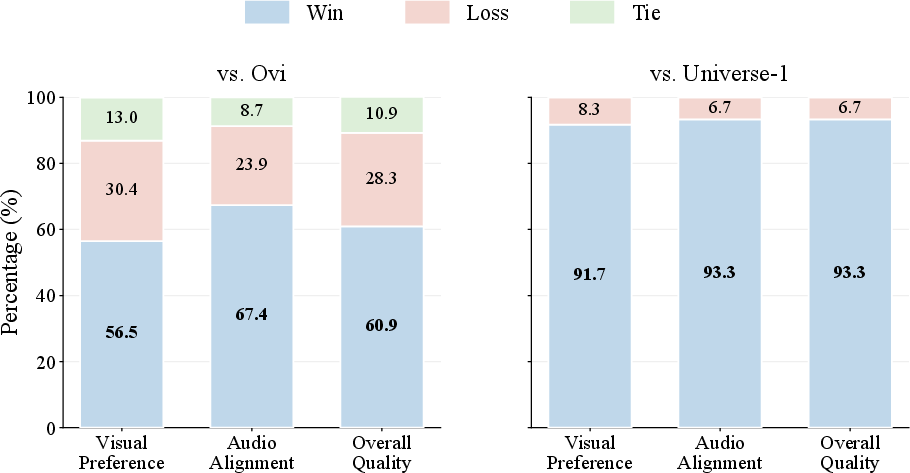
Figure 4: Human evaluation statistics, where Mutual Forcing decisively outperforms Ovi and Universe-1 across all subjective criteria.
Ablations and Architectural Insights
Analysis of attention maps reveals >97% similarity between few-step and multi-step weights, validating the efficacy of self-evolution in harmonizing representations across operational modes and minimizing context-induced long-horizon drift. In addition, Mutual Forcing produces more temporally distributed attention allocations compared to teacher-forcing-based baselines, mitigating the problem of error amplification by avoiding over-reliance on specific historical frames.
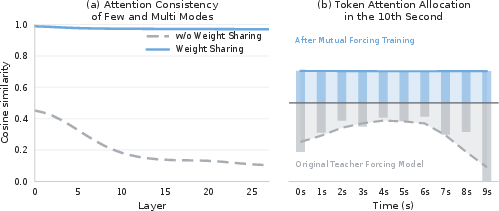
Figure 5: Attention consistency and allocation heatmaps demonstrate the internal alignment between dual modes and improved robustness against cumulative error.
Further ablation shows that the SC+DMD hybrid distillation strategy is essential for uncompromised quality, with the hybrid consistently outperforming either component alone, especially under aggressive step reduction.

Figure 6: Visual ablation—only the hybrid distillation (SC+DMD) yields preserved motion accuracy and sharp boundaries for fast-moving subjects in low-step settings.
Long-Horizon Robustness and Throughput
Mutual Forcing demonstrates stable audio and video quality across 25s streaming windows, with negligible degradation, whereas traditional teacher/student or self-forcing schemes collapse after 10–15s due to exposure bias. The practical impact is manifest in real-time throughput: Mutual Forcing attains up to 30 FPS at 192×336 resolution on a single GPU, compared to <1.5 FPS for Ovi/Universe-1 with multi-GPU setup.
Practical and Theoretical Implications
Practically, Mutual Forcing enables deployable, high-quality, long-duration audio-video generation for real-time avatars, human-computer interfaces, and downstream multimodal agents, unencumbered by teacher distillation or CFG. Architecturally, the unification of streaming inference and robust autoregressive quality under a dual-mode, weight-shared, self-evolving regime represents a directionally critical step for token-efficient, train-inference aligned diffusion modeling.
Theoretically, these results reinforce the value of self-consistency objectives and joint parameterizing for mitigating exposure bias. The extensibility of the method to additional modalities (e.g., pose, text, depth) and other streaming conditional generation tasks is immediate, given the abstraction of context and the plug-and-play nature of the pipeline.
Conclusion
Mutual Forcing establishes a new standard in efficient, high-quality streaming audio-video generation, integrating self-distillation and train-inference consistency in a unified framework. The empirical evidence supports both performance and inference cost claims, with architectural and methodological implications that are poised to influence future research in multi-modal generative modeling and real-time interactive AI systems.