- The paper introduces a decoupled autoregressive backbone with modality-specific diffusion heads to achieve synchronized and high-fidelity audio-video generation.
- It significantly enhances sample efficiency and alignment, achieving SOTA results in terms of CER, WER, FID, FVD, and SyncNet metrics.
- The unified framework supports joint generation, audio-driven synthesis, and video dubbing without any architectural changes.
Talker-T2AV: Autoregressive Diffusion for Decoupled Talking Audio-Video Generation
Motivation and Conceptual Foundation
Recent advances in generative models for audio-visual content have highlighted the advantage of joint modeling for audio and video signals, especially in applications such as talking head synthesis and synchronized dialogue generation. SOTA commercial and open-source efforts (e.g., Sora-2, Veo-3, MOVA, Ovi, LTX-2) have largely converged on the dual-branch diffusion transformer (dual-DiT) architecture, which maintains separate DiT towers for audio and video, coupling them via cross-attention at every generative step. While this approach improves high-level cross-modal coherence over cascaded pipelines, it introduces two structural limitations: (i) excessive entanglement of high- and low-level features across modalities throughout the denoising trajectory, and (ii) non-causal fixed-length output, which fails to accommodate variable textual input length and nuanced speech rates.
Talker-T2AV addresses these limitations by explicitly decoupling the modeling of high-level semantic and temporal structure from low-level signal realization. The framework comprises a shared autoregressive backbone—inspired by language modeling methodology—that serves as the temporal semantic planner for both modalities. Low-level audio and video signal generation is delegated to independent diffusion transformer heads, which refine the shared high-level representation into patch-level latents specific to each modality. This segmentation allows for: (a) improved sample efficiency and modeling fidelity by avoiding unnecessary cross-modal mixing during signal rendering, and (b) natural support for variable output lengths, enabling adaptability to utterance content and dynamics. Moreover, the architecture’s element-wise summation fusion mechanism provides inherent flexibility, facilitating standard joint audio-video generation, audio-driven talking head synthesis, and video dubbing within the same model instance with no retraining or fine-tuning.
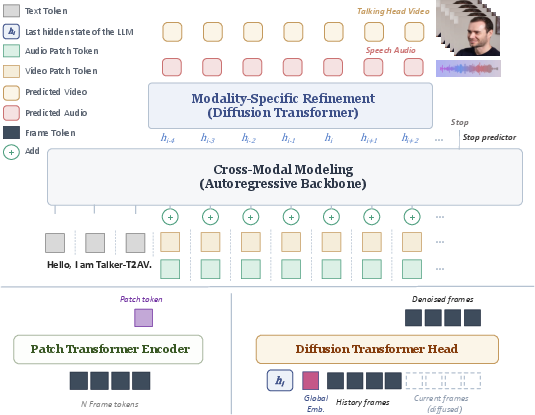
Figure 1: Architecture of Talker-T2AV, illustrating autoregressive backbone processing of the causal token sequence and modality-specific diffusion heads for low-level emission.
Technical Architecture
High-Level Cross-Modal Planning (Autoregressive Backbone)
The autoregressive backbone is a causal LM initialized from Qwen3-0.6B. Input consists of a text prefix, followed by a temporally-aligned sequence of joint audio-video patch tokens, where each patch token is formed as the element-wise sum of audio and video patch embeddings at each temporal position. The core modeling distribution is
p(A,V∣t)=i=1∏Np(ai,vi∣a<i,v<i,t)
with N adaptively determined by a learned stop predictor. By using temporally aligned latents—WhisperX-VAE for audio and LIA-X for video, both operating at 25 Hz—frame-level alignment between modalities is guaranteed a priori, eliminating the need for expensive cross-modal attention to discover synchrony.
Patch transformer encoders compress P frames per token, reducing input sequence length and further improving efficiency for the backbone. Importantly, the learned element-wise summation (as opposed to interleaving or delayed fusion) is empirically optimal for cross-modal synchronization according to ablations (see below).
The output of the autoregressive backbone at each step is consumed by two independent lightweight diffusion transformer heads—one for audio, one for video—which perform OT-CFM (optimal-transport conditional flow matching) denoising in their respective latent spaces. Each head is conditioned on the shared LM hidden state, a global embedding (e.g., identity/speaker), a context window, and the current noisy patch. This factorization enables each diffusion head to specialize in the signal properties of its target modality, boosting both speech intelligibility and video fidelity.
Multi-task training across T2AV and TTS objectives—achieved by a simple task-tag mechanism and zeroing out losses for missing modalities in unpaired batches—allows the backbone and diffusion heads to benefit from abundant unpaired TTS data. This is especially significant for strengthening text-to-speech mapping, with clear transfer to lip-articulation accuracy in the video head.
Experimental Results
Joint Audio-Video Generation
Talker-T2AV demonstrates strong improvements over dual-branch diffusion baselines such as MOVA, Ovi, LTX-2, UniVerse-1, and UniAVGen. Notably, substantial gains are shown in:
- Speech Content Accuracy: Achieves lowest CER (Chinese) and WER (English) in joint generation scenarios, confirming that the decoupled architecture and variable-length decoding directly benefit linguistic fidelity.
- Video Quality: Delivers SOTA FID and FVD, consistently outperforming both general-purpose and facial-optimized dual-DiT models. These gains indicate that semantic control over facial motion is richer with the AR backbone.
- Audio-Visual Synchronization: Achieves highest SyncNet Confidence and lowest Distance, empirically validating the design hypothesis that high-level joint AR planning enables sharper cross-modal alignment than pervasive low-level attention.
Audio-to-Video and Video-to-Audio Dubbing
Despite not being tailored for conditional settings, Talker-T2AV’s shared backbone with element-wise summation directly supports audio-driven and video-driven generation:
- Audio-to-Video: Matches or surpasses dedicated audio-driven talking head systems (FLOAT, Ditto, Sonic) in lip-sync and video quality, with Sync-C/Sync-D metrics competitive or SOTA.
- Video-to-Audio: On the Chem video dubbing benchmark, achieves minimal duration distance, highest emotion similarity, and SOTA WER and UTMOS, matching or exceeding specialized dubbing models (InstructDubber, ProDubber, Speak2Dub).
Ablation Study
Empirical ablation on backbone token arrangement confirms the importance of time-aligned fusion:
- Element-wise summation (proposed) yields optimal synchronization, video quality, and speech accuracy for joint generation.
- Interleaved or delayed video tokens result in degraded coherence and fidelity, particularly for text-initiated generation.
- For audio-driven A2V generation, modest video-token delay can marginally improve synchronization, highlighting the context dependency of optimal fusion.
Limitations and Implications
While the method delivers strong results, two limitations persist:
- The use of continuous latent autoregressive modeling leads to accumulation of prediction errors in very long sequences, causing gradual quality degradation; discrete token AR approaches may alleviate this.
- Video realism is currently constrained by the representational ceiling of the video autoencoder.
Theoretically, the decoupled AR+diffusion approach demonstrates a principled path towards scalable, flexible cross-modal generation. Practically, the unified architecture that seamlessly switches between joint generation, audio-driven, and video-driven regimes without any architectural change has direct utility for multi-lingual dubbing, avatar-based communication, and generative media production.
Future directions include exploring more expressive autoencoders, extending to higher dimensions (e.g., body-gesture-video, 3D avatars), and explicit modeling of conversational dialogue with multiple speakers.
Conclusion
Talker-T2AV introduces an efficient, theoretically grounded decoupled modeling approach for joint talking audio-video generation, demonstrably surpassing prevailing cross-attentive diffusion transformers in both flexibility and fidelity (2604.23586). Its design clarifies when and how cross-modal fusion is most beneficial, and the empirical results establish a new baseline for unified multimodal generation architectures in the domain.