- The paper presents a multi-agent system, SAFEdit, that decomposes code editing into planning, editing, and verification to enhance reliability.
- SAFEdit achieves a task success rate boost by up to 17.4 percentage points and eliminates regression errors through iterative correction cycles.
- Experimental results demonstrate better multilingual performance and robustness compared to single-agent approaches like ReAct and conventional LLM pipelines.
Structured Multi-Agent Decomposition for Reliable Instructed Code Editing: The SAFEdit Framework
Introduction
The paper "SAFEdit: Does Multi-Agent Decomposition Resolve the Reliability Challenges of Instructed Code Editing?" (2604.25737) provides a rigorous exploration of reliability in LLM-based instructed code editing, with a focus on architectural decomposition. Prior studies demonstrated persistent limitations in LLMs on the EditBench benchmark, with most models achieving task success rates (TSR) below 60% under executable test constraints. SAFEdit is introduced as a multi-agent system for code editing, instantiated via CrewAI, which splits the task into planning, editing, and verification roles. The central hypothesis is that explicit decomposition, together with iterative, execution-grounded refinement, addresses inherent reliability limitations of single-model and single-agent pipelines.
Figure 1: Overview of the SAFEdit framework, detailing Planner, Editor, and Verifier agents operating in an iterative refinement loop with structured feedback and error taxonomy.
Methodology: Agent Design and Iterative Pipeline
Instructed code editing requires transforming existing code according to natural-language instructions and passing associated unit test suites. The paper operationalizes EditBench’s spatial context variants—CODE ONLY, HIGHLIGHT, HIGHLIGHT + CURSOR POSITION—to assess the influence of localization cues on editing performance. The dataset comprises 445 filtered, validated editing tasks spanning English, Polish, Spanish, Chinese, and Russian.
SAFEdit Agent Roles
- Planner Agent: Receives instructions and visible code, producing structured edit plans with semantic intent, target location, explicit modification actions, and constraints, while adhering strictly to the information relevant for the selected visibility variant.
- Editor Agent: Given the edit plan, applies minimal, literal changes to the original code, preserving invariants and formatting. Edits are restricted to instructed fragments, minimizing collateral modifications.
- Verifier Agent: Executes the proposed code using real unit tests in a sandbox, generating pass/fail signals and granular logs.
When tests fail, a deterministic Failure Abstraction Layer (FAL) produces structured diagnostic feedback—mapping exceptions, expected/actual values, and repair suggestions, enabling targeted iterative refinement. SAFEdit permits up to three correction cycles, balancing improvement against computational cost.
Experimental Setup and Baselines
Baseline Comparison
SAFEdit is benchmarked against:
- EditBench Single-Model Baselines: Zero-shot LLMs interact via prompt-response editing.
- ReAct Baseline: Single-agent iterative code editing via the reasoning–acting paradigm, instantiated with the same GPT-4.1 backbone for parity. Both operate under identical iteration budgets and test infrastructure.
Evaluation Metrics
- Task Success Rate (TSR): Fraction of tasks where the edited code passes all unit tests.
- Iteration Efficiency: Average refinement steps per task.
- First-Try Success Rate: Proportion resolved in the initial edit.
- Failure Taxonomy Distribution: Classification of errors—Instruction Hallucination (IH), Implementation Gap (IG), Regression Error (RE), Context Misalignment (CM)—using LLM-based analysis for interpretability.
SAFEdit achieved 68.6% TSR under the HIGHLIGHT context, outperforming ReAct by +8.6pp and the strongest EditBench leaderboard model (claude-sonnet-4) by +3.8pp, all using identical backbone models.
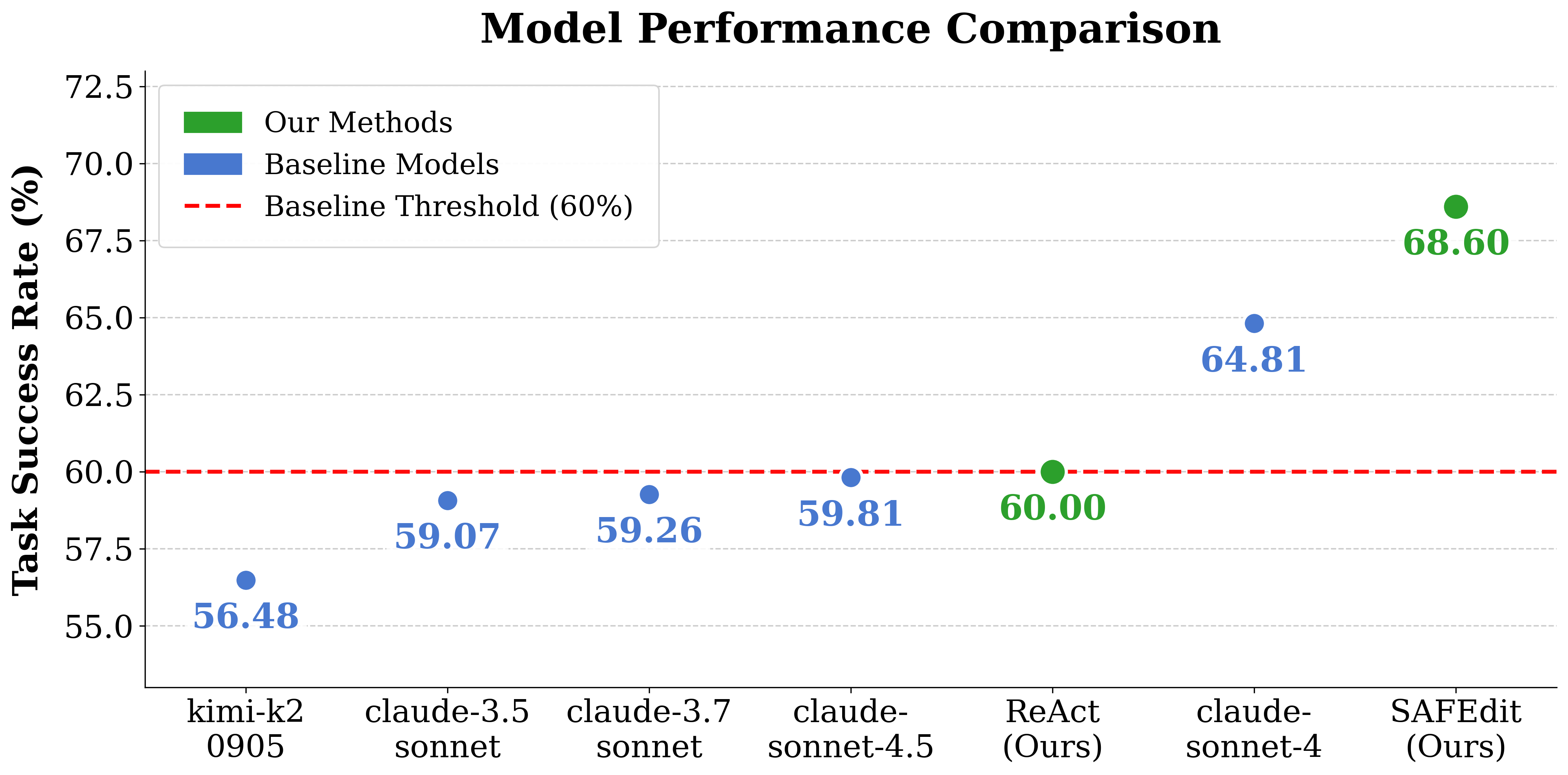
Figure 2: Comparative TSR under HIGHLIGHT visibility for SAFEdit, ReAct, and EditBench leaderboard baselines.
Multilingual Robustness and Variant Sensitivity
Across languages, SAFEdit consistently outperformed ReAct (improvements from +5.7pp to +12.4pp), suggesting the benefits are not language-specific. Performance was stable across context variants in English, with minor regressions in some non-English settings when introducing fine-grained spatial cues. Notably, SAFEdit’s planner abstraction mitigated context-sensitivity, promoting robust localization and intent extraction.
Iterative Refinement and Correction Efficiency
Refinement contributed an average of +17.4pp to final TSR. About half of tasks were solved on the first pass, with most remaining failures resolved within one or two additional correction cycles. The structured feedback loop via the FAL prevented over-editing and guided targeted repairs.
Failure Taxonomy Insights
Failure modes for SAFEdit and ReAct diverged. ReAct exhibited dominant IG errors (failure to implement the correct change), with non-trivial regression errors in several languages. SAFEdit distributed failures across IH and IG, entirely eliminating regression errors (0.0%) in all languages and minimizing context misalignment. This demonstrates qualitative improvements beyond aggregate TSR.
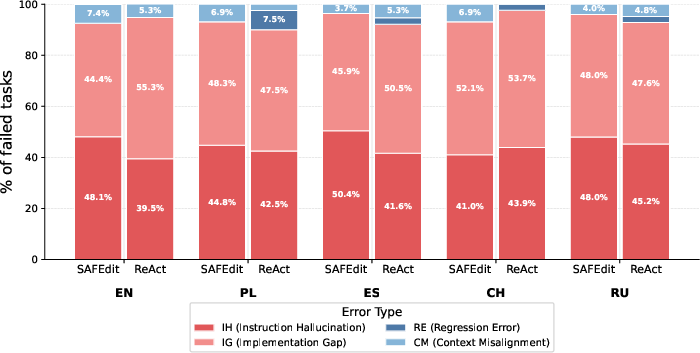
Figure 3: Stacked error distributions for failed editing tasks by root-cause taxonomy categories across evaluated languages (SAFEdit and ReAct).
Discussion
Structured decomposition in SAFEdit yielded measurable improvements over single-agent approaches, with robustness to varying context granularity and language. Architectural separation enabled each agent to specialize—reducing instruction hallucination, over-editing, and regression errors. Iterative correction was computationally efficient, leveraging deterministic structured feedback versus raw log parsing, with minimal LLM overhead.
The empirical results establish that reliable code editing is not a mere function of LLM scale, but critically depends on explicit process structure, role separation, and execution-grounded verification. The findings have implications for agentic system design and benchmarking: multi-agent orchestration offers interpretable error signals, reduces collateral damage, and promotes reproducible editing outcomes.
The taxonomy-based analysis revealed that structural improvements reshape—not just reduce—failure profiles, highlighting the necessity of qualitative evaluation metrics alongside aggregate pass/fail rates.
Implications and Future Directions
SAFEdit demonstrates the efficacy of multi-agent decomposition for instructed editing under real-world constraints, establishing a new reliability bar for EditBench-style tasks. Practical adoption of such frameworks may require consideration of cost and latency, though average iteration counts were low.
Future research avenues include:
- Extending agentic editing to broader, repository-level scenarios, integrating more complex propagation and dependency management.
- Evaluating architectural decomposition across diverse backbone models and longer correction horizons.
- Enhancing taxonomy with human-in-the-loop evaluations for richer, more granular failure interpretability.
Conclusion
The SAFEdit framework illustrates that multi-agent decomposition, iterative structured refinement, and explicit feedback mechanisms substantially enhance reliability in instructed code editing. Achieving consistent gains in both aggregate and qualitative metrics, SAFEdit sets a precedent for building trustworthy LLM-powered developer tools where task-localization, execution validation, and regression avoidance are critical. Architectural design, not just backbone capability, is shown to be a key determinant of real-world editing effectiveness.

