- The paper introduces CODESTRUCT, replacing brittle text-based operations with AST-based actions to improve accuracy and efficiency.
- It demonstrates significant gains in pass@1 accuracy and token consumption reductions across different LLM scales using structured navigation and editing.
- Experimental results on SWE-Bench and CodeAssistBench validate the framework’s robustness, error mitigation, and scalability over traditional methods.
Structured Action Spaces for Code Agents: A Technical Summary of CODESTRUCT
Motivation for Structured Code Action Spaces
LLM-based code agents have seen uptake for multi-file and repository-scale software engineering tasks, but a foundational abstraction mismatch remains: most agents treat codebases as unstructured text, implementing navigation and edit operations via line numbers or string matching. This approach discards intrinsic syntactic and semantic code structure, leading to brittle, high-overhead, and error-prone agent behavior—particularly in the presence of function reordering, whitespace changes, or formatting drift. Even recent repository maps or code summarization interfaces supplement but do not fundamentally reform the granularity and semantics of agent actions.

Figure 1: Contrasting code agent action spaces; the structured agent scopes edits to semantic entities rather than brittle text spans, offering robust localization and compact modification.
The CODESTRUCT Framework
CODESTRUCT introduces an action space and framework that realigns agent interaction primitives around the program's Abstract Syntax Tree (AST). Instead of anonymous text edit operations, agents operate over named program entities (e.g., file.py::ClassName::method). The structured primitives consist of:
- readCode: Returns complete syntactic units, e.g., functions or classes, via symbolic selectors; it supports coarse-to-fine navigation using directory browsing, structural summaries, and scoped retrieval—eliminating the ambiguities and inefficiencies of line-based reading.
- editCode: Applies syntax-validated AST node transformations (insert, replace, remove), ensuring edits are robust, precise, and always maintain syntactic correctness by construction. Failed modifications are rejected, and tool errors become explicit for agent recovery.
This design moves beyond structural hints, enforcing a complete decoupling of code semantics from text layout and regressing unintended dependencies on text patterns.
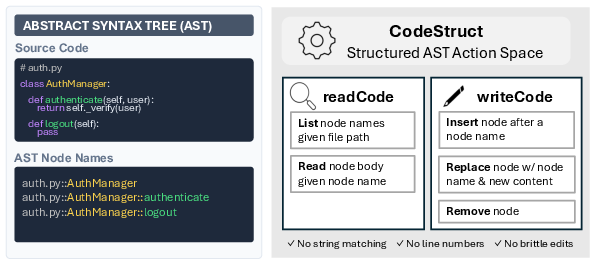
Figure 2: Overview of CODESTRUCT, in which agents interact with code via structured AST node actions, ensuring precise, semantic code navigation and modification.
Experimental Evaluation and Empirical Observations
CODESTRUCT is evaluated on SWE-Bench Verified (repository-level bug-fixing) and CodeAssistBench (conversational code assistance), integrating with six LLMs (GPT-5, Qwen3-family, various scales). The central findings are:
Ablation and Error Analysis
Ablations isolating the readCode and editCode primitives demonstrate their complementary contributions. Removing readCode results in the largest accuracy degradation and brute-force search behavior (increased interaction steps and token usage). Removing editCode increases agent cost and iteration count due to fallback on brittle string-based patching, causing more repeated failed tool attempts.
Error analysis reveals CODESTRUCT's largest gains accrue for models where text-based interface errors (ambiguity, malformed edits) rather than reasoning capacity limit performance. For smallest models, structure-aware actions unlock new strategies but impose higher syntactic and specification demands, reflected in the increased recoverable tool error rates but decreased empty patches.
Implications and Future Directions
CODESTRUCT demonstrates that recasting LLM agent action spaces in terms of program structure—explicitly bridging the semantic gap between agent intent and code artifact—delivers measurable and systematic improvements in both solution quality and computational efficiency. Practically, this design offers drop-in integration with leading agent frameworks, as the MCP-based tool interface is model-agnostic and readily composable.
Theoretically, structured action spaces serve as a foundation for more analyzable, traceable, and robust agent behaviors, and naturally extend to interpretable multi-turn workflows, audit trails, and automatic error recovery. Extension opportunities include support for broader language families (with varied AST models), richer structure-sensitive tasks such as code review or test synthesis, and integration with abstract interpretation- or type-theoretic reasoning for even stronger correctness guarantees.
CODESTRUCT's results advocate an architectural shift away from low-level text manipulation toward high-level, syntax-aware agent design as the default paradigm for automated code reasoning and modification.
Conclusion
CODESTRUCT formalizes and operationalizes structure-aware action spaces for LLM-based code agents, redefining code interaction around named AST entities and syntactic guarantees. This approach eliminates failure modes endemic to text-based interfaces, drives up accuracy—markedly so for less capable models limited by interface brittleness—and consistently reduces cost and resource overhead. The empirical evidence underscores the case for structure-grounded action primitives as the essential abstraction for scalable, reliable code agents across a range of software engineering tasks.


