- The paper presents EDIT-Bench, a new benchmark built on real user interactions to assess LLMs' code editing capabilities.
- The methodology employs a VSCode extension to collect 545 diverse tasks in Python and JavaScript, emphasizing error resolution, optimization, and functionality enhancement.
- The findings indicate that top closed models achieve up to 66.7% pass@1, highlighting the significance of enriched context information in improving editing performance.
EDIT-Bench: Evaluating LLM Capabilities in Code Editing
Introduction
EDIT-Bench aims to address the gap in evaluating LLM (LM) capabilities for real-world instructed code edits. Unlike existing benchmarks, which primarily focus on code generation or rely on constructed test cases, EDIT-Bench introduces a dataset built on authentic user interactions. Collected from in-use software development environments, it evaluates models on tasks that mirror real-world edit scenarios, including diverse user instructions and variable code contexts.
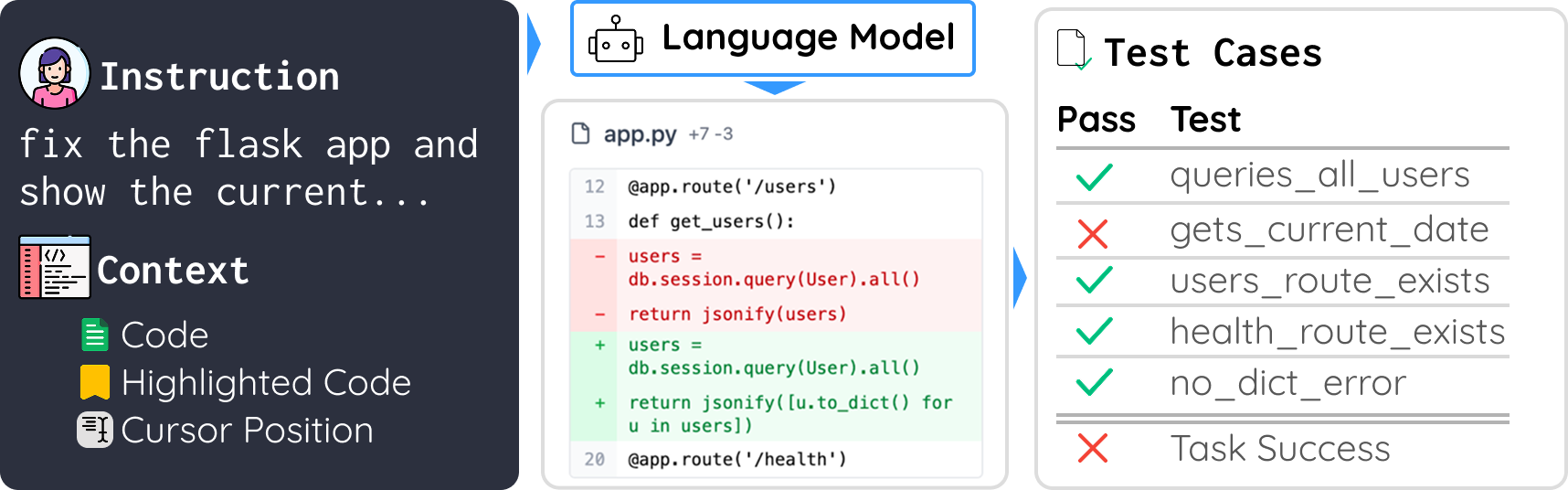
Figure 1: EDIT tests LLMs' real-world editing capabilities, requiring models to process live user instructions and edit code accordingly.
Methodology
Data Collection
To construct EDIT-Bench, an open-source Visual Studio Code (VSCode) extension was developed (Figure 2). This extension collects live user instructions and code snippets during actual coding sessions, ensuring that the problems reflect genuine developer needs. This approach gathers diverse linguistic and programming examples, critical for assessing model versatility across different languages.
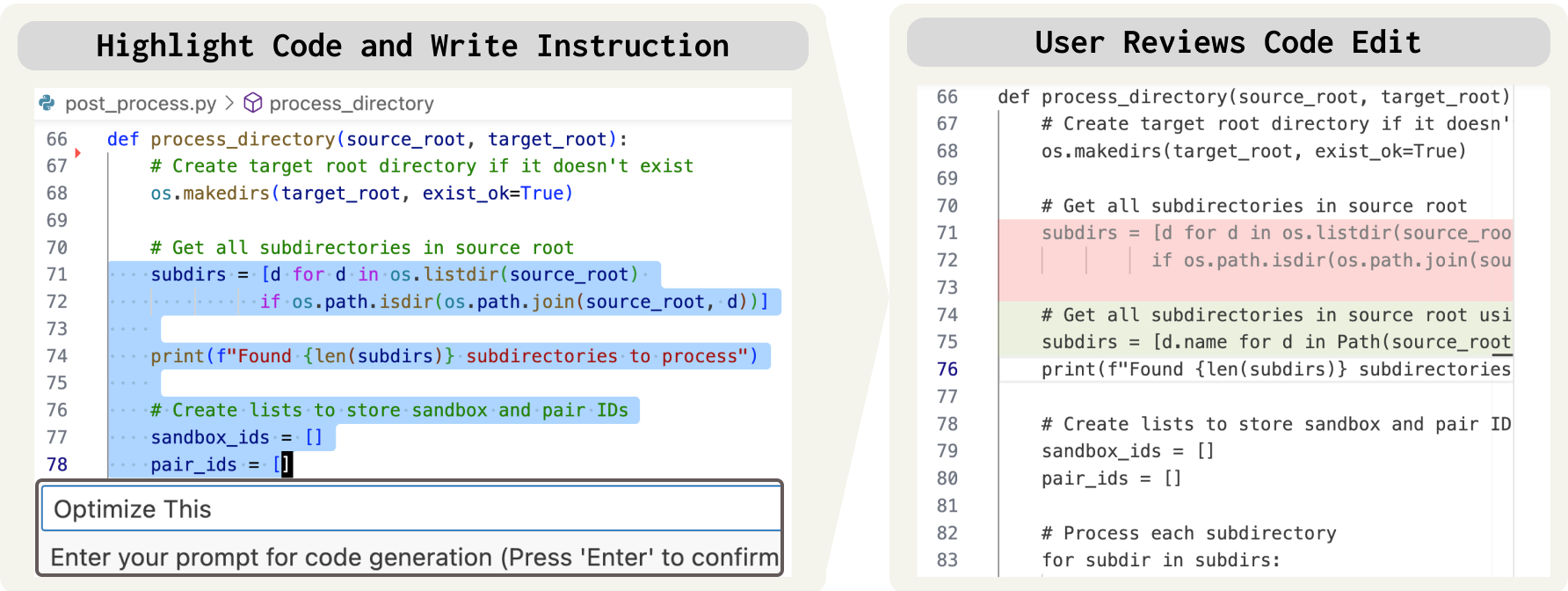
Figure 2: We develop an open-source VSCode extension to collect real-world edits.
Benchmark Characteristics
EDIT-Bench comprises 545 tasks spanning multiple programming languages, primarily Python and JavaScript. It features real-world problems including error resolution, performance optimization, and functionality enhancement, evaluated under realistic conditions with user's code context, highlighted code, and cursor positions.
Diversity in Context
The benchmark's problems include varied code contexts with tokens ranging significantly in length (Figure 3). This diversity challenges models to manage strong contextual dependencies rather than relying on template-based solutions.

Figure 3: Distribution of libraries in EDIT for Python problems, showing a wider variety of imports than previous benchmarks.
Evaluation Metrics
EDIT-Bench evaluates models using the pass@1 metric, where a solution passes all test cases on the first attempt. The benchmark evaluates 40 different LLMs, spanning both open and closed frameworks, highlighting notable performance disparities between them (Figure 4).
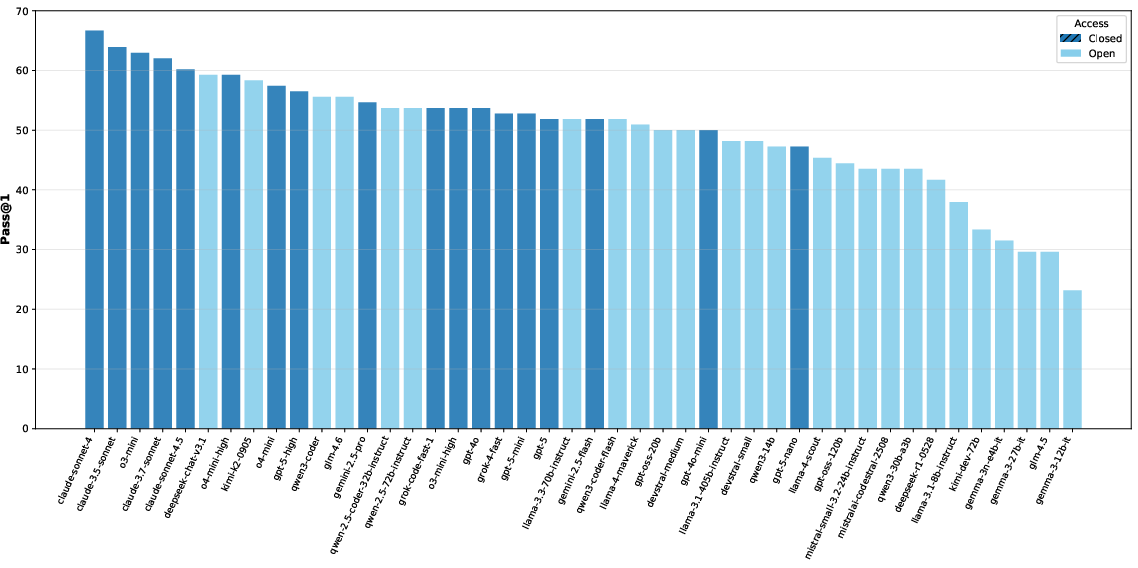
Figure 4: We evaluate 40 LLMs on EDIT, illustrating that only 5 have a pass@1 greater than 60\%.
Findings
The top-performing models, primarily closed-source, like Claude 4, demonstrated superior editing capabilities, greatly exceeding most open models. This indicates a significant gap that proprietary technologies maintain, potentially due to more rigorous training datasets or novel architectures. However, even top models only solved approximately 66.7% of the tasks, underscoring the complexity captured in EDIT-Bench.
Contextual Importance
Our experiments showed that enriched context details, like highlighted code and cursor positions, enhance model performance. Notably, adding only highlighted code substantially improved task success rates across models (Figure 5). This highlights the necessity for models to incorporate comprehensive contextual awareness in their editing processes.
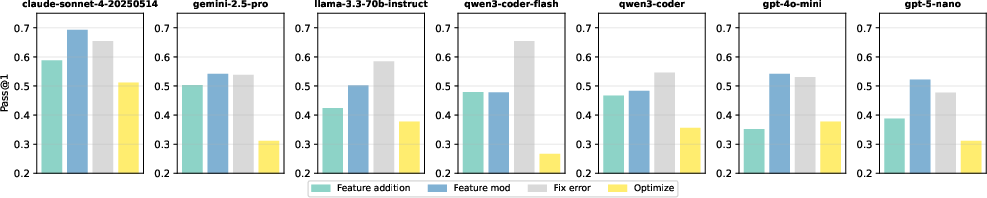
Figure 5: Performance across categories varies with each model excelling differently in aspects such as bug fixing or code optimization.
Task Category Variability
Models show distinct performance across the four main edit categories: feature addition, feature modification, bug fixing, and optimization. While most models performed best in bug fixing, they struggled notably with optimization tasks, pointing to potential areas for enhancements in training models on efficiency focused edits.
Comparative Analysis
EDIT-Bench correlates weakly with previous coding benchmarks like Aider Polyglot and SWE-Bench, emphasizing its unique challenge profile derived from real-world data. Its design specifically addresses diverse, unstructured, and contextually driven shopping tasks, distinguishing it from more uniform and curriculum-like benchmarks.
Conclusion
EDIT-Bench establishes a robust framework for evaluating LLMs on instructed code editing, leveraging authentic user edits. The benchmark reveals critical insights into model deficiencies and strengths, offering a path forward to enhance model robustness and contextual comprehension. As AI continues to complement software development, developing such comprehensive evaluations will be pivotal in advancing AI-assisted coding tools effectively.
Ultimately, EDIT-Bench provides a dynamic testing ground that captures practical code editing needs, encouraging continual refinement and advancement of LLM capabilities in real-world settings. Future work will focus on expanding the problem set's breadth and enhancing automated harness generation processes to streamline the creation of benchmark tasks as AI and development environments evolve.

