- The paper examines the fitness of CanItEdit and EDIT-Bench benchmarks for real-world code editing.
- The study compares benchmark language, intent, and domain coverage against authentic software development practices.
- It reveals that weak test oracle design inflates LLM performance estimates, urging more representative evaluation criteria.
Empirical Audit of Instructed Code-Editing Benchmarks: Scope, Test Adequacy, and Benchmark Validity
Introduction
"Edit, But Verify: An Empirical Audit of Instructed Code-Editing Benchmarks" (2604.05100) critically evaluates the validity of current instructed code-editing benchmarks, specifically CanItEdit and EDIT-Bench, which are widely used to assess LLM competence in IDE-integrated code modification tasks. This audit is motivated by the central role these benchmarks play in guiding deployment decisions for AI-powered software development tools, with the expectation that benchmark performance is predictive of real-world editing capability. The authors present an exhaustive empirical analysis contrasting the benchmarks' design and evaluation procedures against distributions and behaviors observed in production AI-assisted code editing. Two research questions drive the audit: whether these benchmarks are representative along key dimensions of real code-editing activity, and whether their test oracles provide reliable signals of functional correctness and behavioral preservation.
Benchmark Selection and Design
The study commences with a systematic survey of over 150 code-related benchmarks, filtering for datasets featuring human-authored instructions, code editing (rather than code generation), and test-based evaluation in single-file, IDE-local scopes. Only two benchmarks, CanItEdit and EDIT-Bench, satisfy these constraints. CanItEdit consists of 105 hand-crafted Python problems with dual instruction types and comprehensive test harnesses targeting corrective, adaptive, and perfective maintenance, and employs stringent test validation (enforcing 100% line coverage and fail-before/pass-after semantics). EDIT-Bench, in contrast, sources 108 core problems from authentic IDE usage logs (Copilot Arena) encompassing a mix of natural and translated instructions, and features test suites retrofitted by human annotators without ground-truth reference code or enforced coverage guarantees.
Coverage of Real-World Code Editing: Language, Intent, and Domain Analysis
To assess representativeness, the paper compares benchmark distributions to three real-world anchors: Copilot Arena interaction logs, the AIDev dataset of agent-authored PRs, and the GitHub Octoverse 2025 report.
Programming Language Coverage:
Both benchmarks are highly skewed in favor of Python, with over 90% of their evaluation instances exclusively targeting this language, while TypeScript—now the most-used language by contributor count on GitHub—is entirely absent. Other high-usage languages (Java, C#, Go, Rust) are similarly missing, undermining the external validity of score interpretation for diverse development ecosystems.
Edit Intent Distribution:
Analysis of editing task types (Conventional Commit categories) reveals that both benchmarks predominantly focus on feature addition and bug fixing, which together account for more than 79–86% of all problems. However, tasks encompassing documentation, test creation, continuous integration/build configuration, and maintenance—collectively representing over 31% of real-world human PRs and a significant share of agent-authored edits—are entirely missing from both datasets.
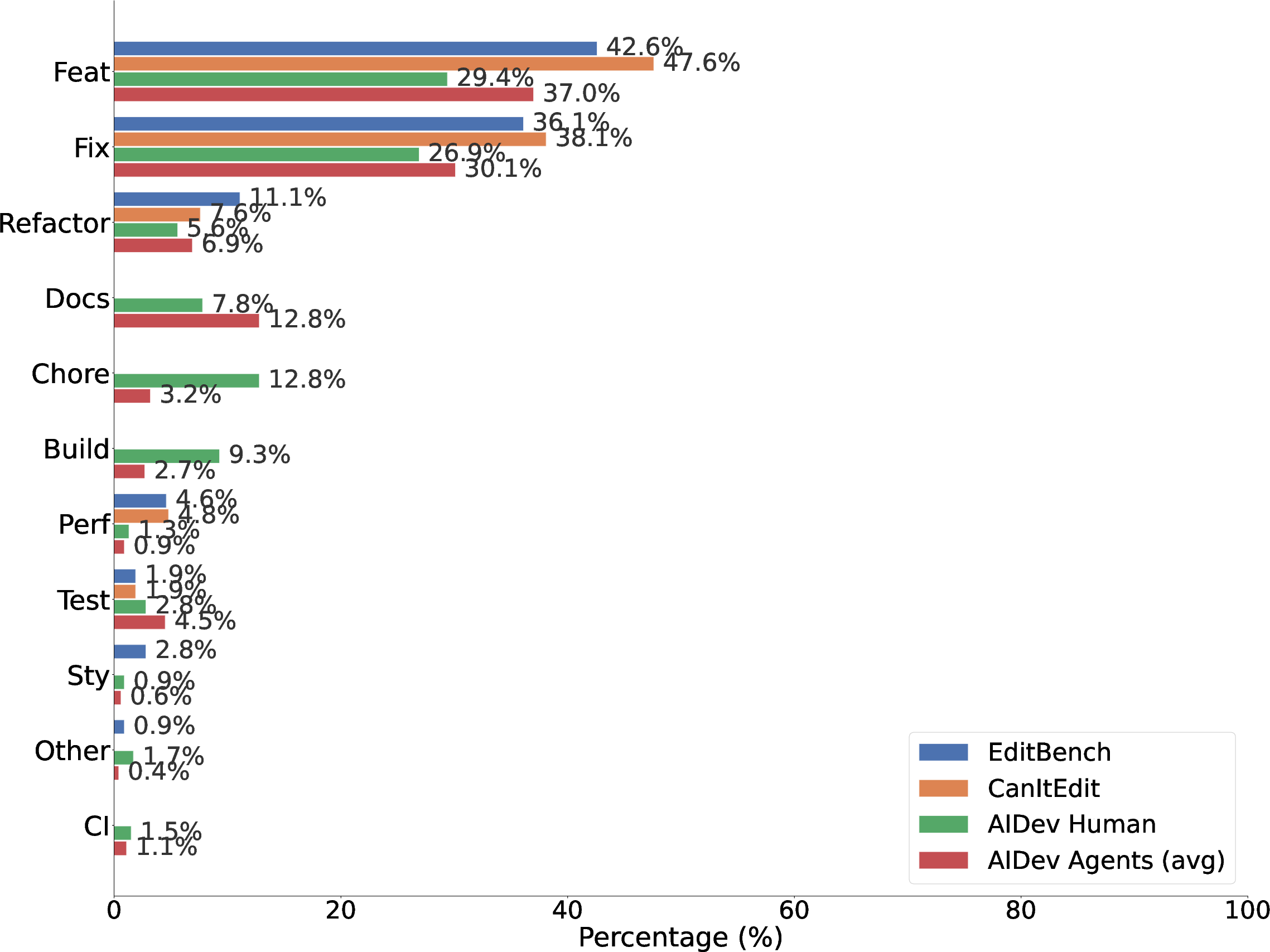
Figure 1: Edit-intent distribution across benchmarks and real-world AI-assisted development (AIDev).
Application Domain Representation:
Benchmark tasks are disproportionately devoted to academic-style algorithm and AI/ML domains (CanItEdit over-indexes algorithm design; EDIT-Bench biases toward AI/ML and ML-adjacent tooling), whereas backend and frontend development (which comprise nearly half of real-world editing activity) are systematically underserved (absent in CanItEdit, only partially present in EDIT-Bench).
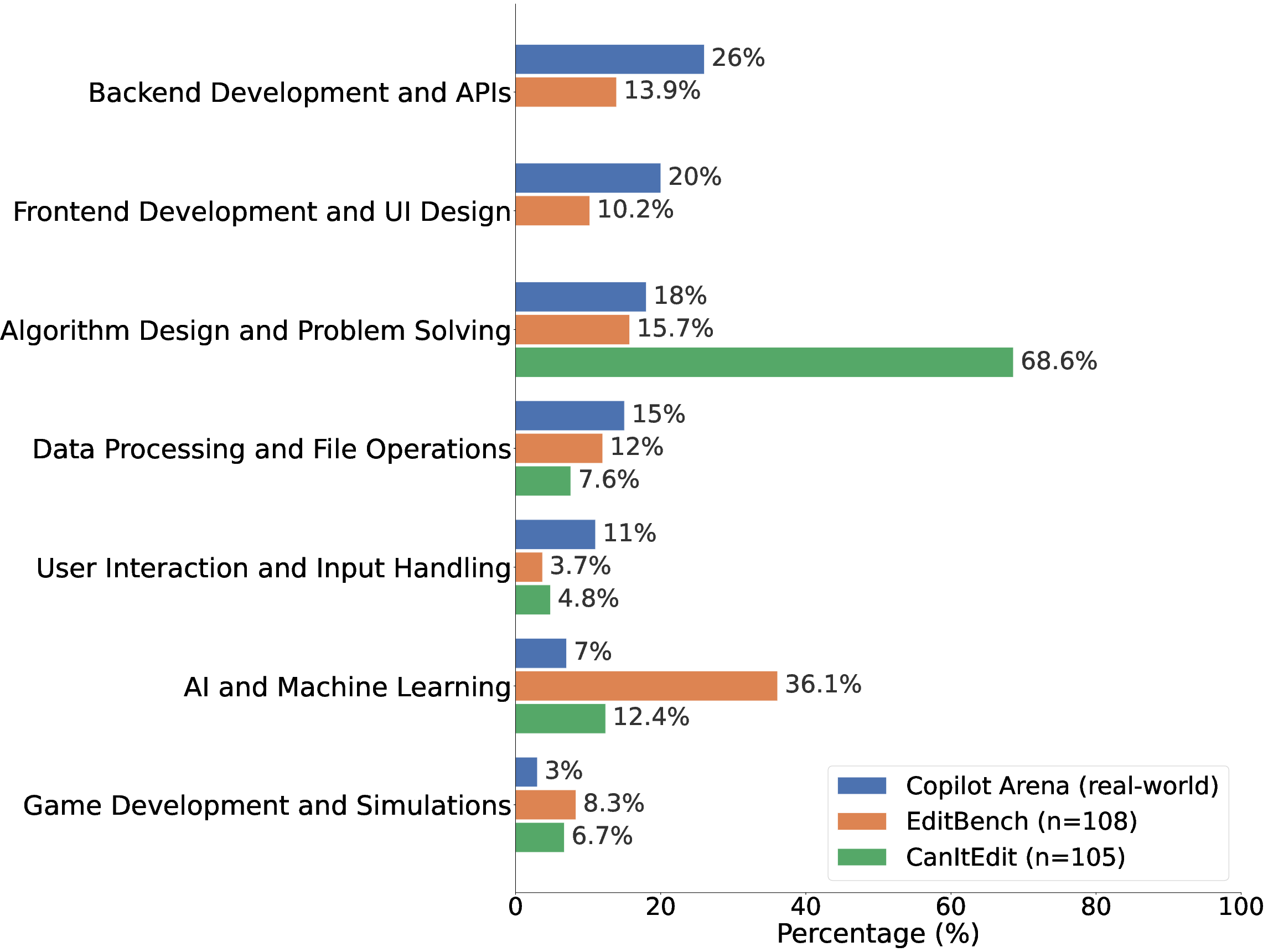
Figure 2: Application-domain distribution across benchmarks and real-world AI-assisted editing (Copilot Arena).
Within the AI/ML taxon, both benchmarks also fail to capture the ongoing paradigm shift toward LLM-native application development. Problems requiring model orchestration, agent integration, and prompt template engineering—now rapidly proliferating in practice—remain rare or absent.
Test Oracle Adequacy: Depth and Preservation Assessment
The adequacy of test suites within both benchmarks is quantitatively and qualitatively dissected using code coverage metrics, suite size, and the discriminability of test oracles.
Test Suite Size and Coverage:
EDIT-Bench yields a median of only 4 tests per problem, covering merely 40% of code statements at the whole-file level, with a substantial subset of problems relying on a single test as an oracle. CanItEdit, although modest in per-problem test count (median 13), compensates with enforced near-complete coverage. Importantly, over 59% of low-coverage EDIT-Bench test suites do not monitor for extraneous modifications outside the requested diff region, rendering them incapable of catching non-local model behaviors, a crucial deficiency given known LLM tendencies for undesired collateral changes.

Figure 3: Number of tests per problem.
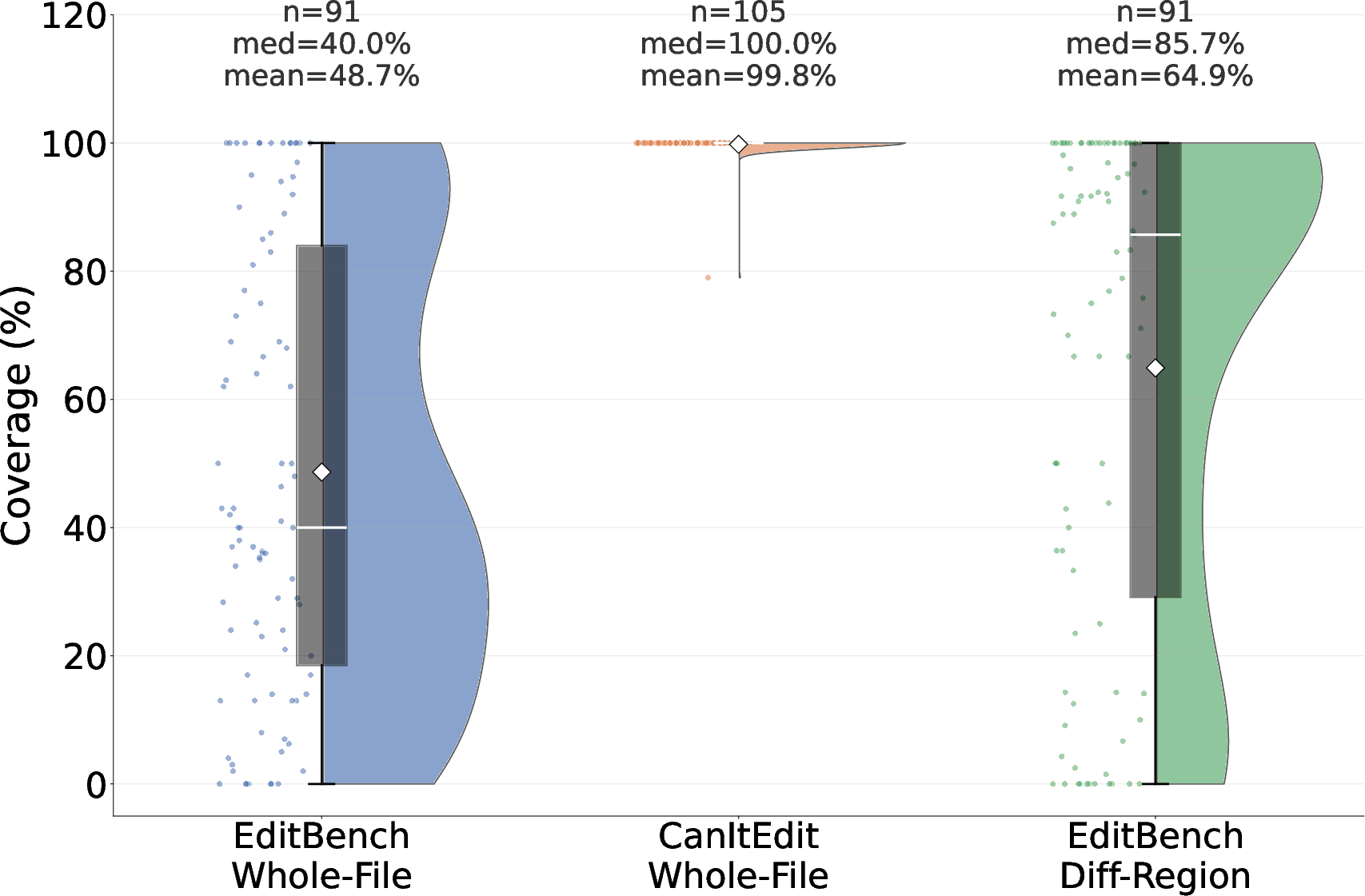
Figure 4: Test coverage distributions of EDIT-Bench and CanItEdit benchmarks.
Preservation-Focused Evaluation:
CanItEdit's pipeline enforces fail-before/pass-after validation and high statement coverage, boosting confidence in edit specificity and preservation. EDIT-Bench, lacking such guarantees, demonstrates that the majority of its suites can be fooled by unrequested changes, thus overestimating functional correctness.
Benchmark Artifacts and Codebase Duplication:
Manual error analysis of the universally unsolved EDIT-Bench problems reveals that artifact-level deficiencies (e.g., infrastructure bugs, poorly specified test assertions, unstated environmental requirements) account for 73% of failures, as opposed to genuine model incompetence. Moreover, 29% of EDIT-Bench problems and 6% of CanItEdit problems share a codebase, indicating code context redundancy and reducing the diversity and discriminability of evaluation results.
Desiderata for Next-Generation Code-Editing Benchmarks
Based on these findings, the paper formulates six desiderata for future benchmark construction:
- Broad Language Coverage: Inclusion of the six most prevalent languages to ensure scores generalize to the dominant production environments (e.g., TypeScript, JavaScript, Go, Java, C#, Python).
- Representative Application Domains: Realistic task sampling reflecting the actual application mix seen in IDEs and production PRs, with proportional coverage given to backend, frontend, AI-native, data-processing, and other domains.
- Edit Intent Diversity: Systematic inclusion of documentation, test/maintenance, configuration, and refactoring edits, extending beyond the traditional feature/fix dichotomy.
- Test Oracle Preservation Strength: Enforced regression-aware test suites with diff-region coverage, fail-before/pass-after validation, and the ability to detect non-local code changes.
- Problem Independence: Codebase deduplication and per-problem solvability confirmation to prevent context leakage and spurious difficulty inflation.
- Dynamic Adaptation to Development Trends: Periodic inclusion and updating of tasks involving emerging paradigms such as LLM/agent orchestration, reflecting shifting software development practices.
Implications for Evaluation and Deployment
The results demonstrate that current instructed code-editing benchmarks systematically overestimate real-world LLM performance by both task selection bias and insufficient test adequacy. Reliance on such benchmarks for deployment gating risks failures in production, especially for use cases involving languages, domains, or edit intents absent from current evaluation surfaces. Rigorous, representative, and preservation-focused benchmarks are necessary for reliable LLM capability assessment. These desiderata directly inform the design of more robust proxies for IDE-integrated and production-grade LLM editors, with implications for both tool developers and academic evaluation.
Conclusion
The audit concludes that neither CanItEdit nor EDIT-Bench, nor by extension their published scores, are reliable proxies for broad real-world code-editing capability of LLMs. Language, domain, and intent coverage mismatches, paired with test oracle inadequacy and artifact-induced evaluation error, collectively undermine external and construct validity. The empirically grounded desiderata outlined provide a clear blueprint for next-generation benchmarks. As the scale and criticality of LLM-powered code editing accelerates, systematic and representative evaluation is essential to both empirical research and production deployment in AI-driven software engineering.