- The paper introduces UF-EMA, a scalable method that fuses noisy and enhanced speech via a UNet architecture to preserve speaker-specific cues.
- It leverages multiple pre-trained speech enhancement modules and uses exponential moving average to gradually adapt the speaker encoder.
- Experimental results on VoxCeleb benchmarks demonstrate superior performance with a consistent average EER of 4.22% under various noise conditions.
UNet-Based Fusion and Exponential Moving Average Adaptation for Noise-Robust Speaker Recognition
Introduction and Motivation
The integration of speech enhancement (SE) with speaker verification (SV) has become prevalent for robust speaker recognition under noisy acoustic environments. Traditional methods, either relying on standalone SV encoders or cascades of SE and SV modules, often fail to fully leverage pre-trained SE networks and neglect the preservation of speaker-specific cues during denoising. Furthermore, these paradigms introduce either overfitting or mismatch issues when directly transferring between clean and noisy domains. The paper “UNet-Based Fusion and Exponential Moving Average Adaptation for Noise-Robust Speaker Recognition” (2604.25624) introduces a scalable framework, UF-EMA, which simultaneously exploits rich information from noisy and enhanced speech inputs via spectrogram-level fusion and ensures gradual adaptation of the speaker encoder through exponential moving average (EMA).
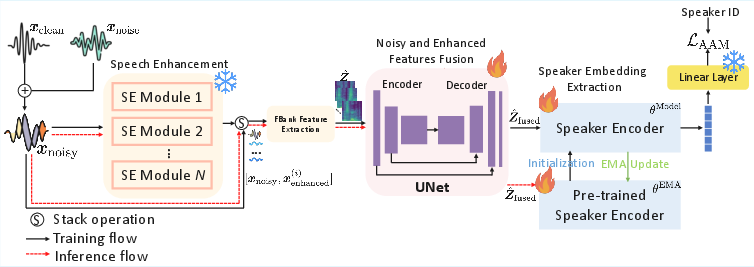
Figure 1: Overview of the UF-EMA method, combining multi-channel spectral fusion and EMA-based adaptation for noise-robust SV.
Methodological Framework
Multi-Module Speech Enhancement
The framework employs multiple frozen SE modules, specifically BSRNN (band-split RNN operating in the spectral domain) and DEMUCS (end-to-end encoder-decoder waveform model), to generate complementary enhanced speech features from noise-contaminated input. This ensemble approach mitigates noise-specific distortions and leverages diverse denoising priors without retraining, allowing scalable incorporation of additional SE back-ends.
UNet-Based Feature Fusion
Rather than simple linear interpolation or observation addition, the UF-EMA design stacks both noisy and enhanced speech channels to form a multi-dimensional log-mel spectrogram input to a UNet-based fusion network. The encoder-decoder UNet architecture produces a fused spectrogram with intricate skip connections, capturing non-linear, speaker-discriminative cues while offsetting artifacts introduced by SE modules. This fused representation allows the downstream SV encoder to exploit both clean and noisy signals for maximal discriminability.
Exponential Moving Average Adaptation
Typical SV training either freezes or aggressively fine-tunes the speaker encoder after SE input changes, risking instability or loss of domain robustness. UF-EMA initializes the SV encoder with pre-trained weights and applies EMA as a dynamic parameter update rule, enabling smooth adaptation from clean to noisy conditions while preventing catastrophic forgetting. A high smoothing coefficient α=0.999 ensures gradual parameter transition, preserving discriminative speaker information throughout environment shifts.
Experimental Evaluation
The evaluation protocol leverages VoxCeleb1 for training and Vox1-O for testing, utilizing challenging noise types (music, noise, babble) at SNRs of −5, $0$, $5$, and $10$ dB. Data augmentation prevents leakage, and test sets are corrupted with unseen noise types. Speaker representations are extracted using ECAPA-TDNN architectures trained with fused UNet outputs.
Numerical Results
The UF-EMA framework achieves an average EER of 4.22%, consistently outperforming prior methods, including NDML, VoiceID, ExU-Net, and Diff-SV, across all noise conditions except for Diff-SV in clean scenarios—the latter relies on computationally intensive diffusion models. UF-EMA achieves top-2 performance in all settings, with notably low EERs in babble interfered cases (e.g., 7.01% at SNR $0$ dB), indicative of superior artifact mitigation and speaker cue preservation. Ablation studies verify that omission of noisy input, BSRNN/DEMUCS modules, or EMA adaptation causes pronounced degradation, especially under high noise (e.g., EER increases from 17.04% to 22.57% for babble at −5 dB SNR without noisy input).
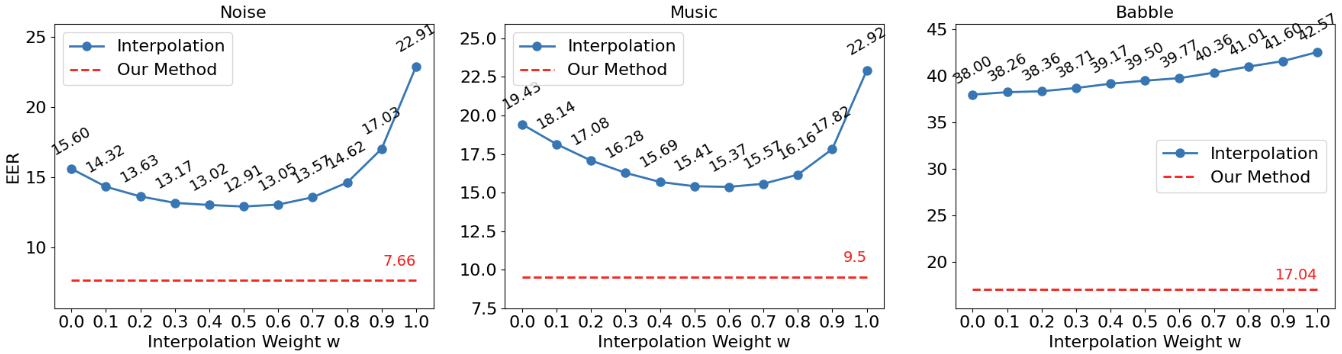
Figure 2: Comparison of EER for UF-EMA versus linear interpolation fusion under various noise types at −5 dB SNR.
Figure 2 further demonstrates that linear interpolation fusion between noisy and enhanced speech provides limited improvement, with EER sharply rising when the interpolation weight deviates from optimal. The UNet-based fusion, by contrast, consistently outperforms linear strategies regardless of noise type, substantiating the necessity of nonlinear spectrogram integration for SV robustness.
Theoretical and Practical Implications
The UF-EMA framework illustrates that multi-channel spectrogram fusion via UNet—integrating both noisy and enhanced modalities—assembles richer, speaker-specific representations than linear methods or single-channel denoising. The architecture’s scalability allows integration of additional SE priors, facilitating domain adaptation as new noise sources and enhancement paradigms emerge. EMA-based adaptation further establishes a template for gradual fine-tuning in domain-shifting SV problems, mitigating overfitting and ensuring cross-condition generalization.
Practically, UF-EMA permits real-time deployment under diverse real-world acoustic scenarios, as its components (pre-trained SE, UNet, frozen decoder blocks, SV encoder) remain computationally efficient compared to iterative diffusion strategies, thus enabling robust speaker authentication in consumer, security, and telecommunication applications.
Future Directions
Further investigation could focus on scaling UF-EMA with additional SE modules and optimizing UNet architectures for low-resource, online inference settings. Exploring fusion efficacy in tandem with self-supervised pre-trained speech models (e.g., WavLM, HuBERT, wav2vec 2.0) and extending EMA adaptation to other downstream speech tasks (ASR, speech separation) are promising directions. Robustness against unseen noise and overlapping speakers may be expanded via data-driven augmentation and adversarial adaptation mechanisms.
Conclusion
The UF-EMA methodology establishes a principled, efficient, and effective framework for noise-robust speaker recognition, combining high-fidelity non-linear fusion of noisy/enhanced speech via UNet with gradual encoder adaptation using EMA. The approach demonstrates strong empirical performance on standard benchmarks and retains theoretical generalizability, laying the groundwork for future robust SV systems across diverse noisy environments.

