- The paper introduces the UniPASE framework, a generative model that achieves high perceptual quality and low hallucinations in universal speech enhancement.
- It utilizes a four-component, self-supervised architecture (DeWavLM-Omni, Adapter, Vocoder, PostNet) to robustly process multi-distortion audio signals.
- Experimental results across benchmarks (DNS, PLC, GSR, URGENT) demonstrate significant improvements in metrics such as UTMOS, PESQ, and dWER.
UniPASE: A Generative Model for Universal Speech Enhancement with High Fidelity and Low Hallucinations
Introduction and Motivation
Universal Speech Enhancement (USE) encompasses the restoration of speech contaminated by a broad variety of distortions—additive noise, reverberation, clipping, bandwidth limitation, codec artifacts, packet loss, and wind noise—across multiple sampling rates. Traditionally, most high-performing systems employ predictive or hybrid predictive–generative architectures. Purely generative models typically offer superior perceptual quality but introduce hallucinations, manifesting as linguistic inaccuracies and inconsistencies in speaker characteristics, thus undermining the reliability required in real-world applications.
UniPASE builds on the low-hallucination PASE framework, explicitly targeting the USE setting with the goal of high perceptual quality without sacrificing linguistic and speaker fidelity. The framework is designed for seamless adaptation to variable sampling rates and multi-distortion environments, reflecting the stringent demands established in benchmarks like the URGENT 2025 and 2026 challenges.

Figure 1: Overview of the proposed UniPASE framework for universal speech enhancement.
Architecture and Key Methodological Innovations
UniPASE is a four-component generative system that operates through distinct representation domains within the self-supervised WavLM model:
- DeWavLM-Omni: An SSL-based enhancement backbone, fine-tuned via denoising representation distillation and robustified through knowledge distillation over a large multi-distortion corpus. The system employs a packet loss detection (PLD) module to further mask and handle missing regions, using a shared learnable mask embedding for missing packets, yielding enhanced phonetic and unenhanced acoustic representations.
- Adapter: To complement semantic enhancement, an explicit acoustic enhancement stage is introduced. The Adapter—built upon an improved Vocos backbone—maps degraded acoustic representations, conditioned on the enhanced phonetic representations, to refined acoustic representations optimized for high-fidelity vocoder synthesis. Critically, it introduces an adversarial multi-scale representation discriminator (MSRD), promoting structural faithfulness in the learned acoustic features.
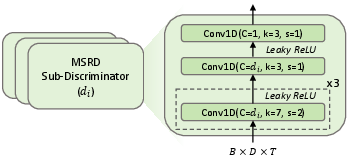
Figure 2: Architecture of the multi-scale representation discriminator (MSRD).
- Vocoder: The waveform synthesizer operates at 16 kHz, mapping enhanced acoustic representations to time-domain signals. The Vocoder is trained independently and leverages a multi-resolution adversarial and reconstruction loss stack to maintain signal naturalness.
- PostNet: For sampling rates >16 kHz, this module extends the signal bandwidth to 48 kHz using an STFT-domain TF-GridNet-based architecture, explicitly copying low-frequency regions from the vocoder output and reconstructing the high-frequency content, followed by flexible resampling. Transition bands ensure smooth spectral integration.
Experimental Results and Ablation
UniPASE is extensively evaluated across four critical USE sub-tasks: conventional speech enhancement (DNS 2020 test set), packet loss concealment (PLC 2024 validation set), general speech restoration (VoiceFixer GSR test set), and the full USE protocol (URGENT 2025 non-blind test set). The results are consistently strong across metrics that capture perceptual quality, intelligibility, low-level fidelity, and linguistic correctness.
Key numerical highlights:
- On DNS 2020 (no-reverb): UTMOS 4.06, PESQ 3.05, SpkSim 0.96, dWER 2.17%.
- On DNS 2020 (with-reverb): DNSMOS 3.33, UTMOS 3.62, dWER 8.16%.
- On PLC 2024: PLCMOS 4.30, SpkSim 0.94, WER 13.55%.
- On GSR: NISQA 4.37, dWER 8.21%, SpkSim 0.81.
- On URGENT 2025: DNSMOS 3.26, NISQA 4.18, CER 12.90%, SpkSim 0.81.
UniPASE decisively surpasses all other generative baselines on hallucination metrics (dWER, CER), with dWER values frequently lower than even the noisy input, a sharp contrast to most prior generative models which saw severe degradations in these metrics. In perceptual metrics, UniPASE achieves scores on par with and frequently higher than the strongest predictive/hybrid models.
Ablation studies demonstrate:
- The phonological prior inherited from pre-trained WavLM is essential, reducing CER by over 20 points.
- Explicit PLD-based masking improves robustness for both packet loss and general distortions.
- The Adapter (acoustic enhancement), especially when combined with MSRD, yields marked perceptual and fidelity gains (e.g., CMOS improvements >1.2).
- PostNet significantly boosts high-frequency perceptual quality, confirmed in subjective listening tests.
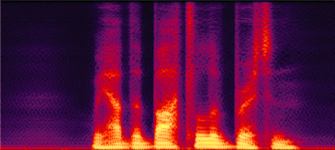
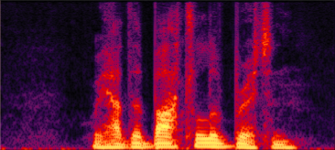
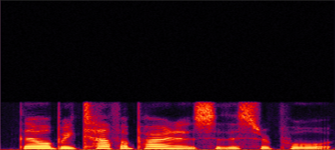
Figure 3: Qualitative comparisons. Top: effect of MSRD. Bottom: effect of PostNet. Each row should be compared horizontally.
Robustness, Generalization, and Cross-lingual Analysis
UniPASE’s PLC sub-system remains robust for loss fractions up to 40% and burst lengths up to 25 packets, effectively handling challenging scenarios for content and speaker recovery. WER increases moderately only in extremely adverse regimes (very high burst rates), while core metrics like SpkSim and LPS remain stable.
Cross-language evaluation (Chinese, English, French, German, Spanish) indicates:
- Acoustic representations generalize robustly across languages (PESQ 3.37–3.60, SpkSim 0.93–0.95).
- Phonetic representations, although best in English, deliver substantial phoneme- and character-level integrity in all languages.
- The improvement from noisy to enhanced speech (LPS, ΔCER) is consistent across languages, confirming that the WavLM phonological prior encodes language-agnostic phoneme structures.
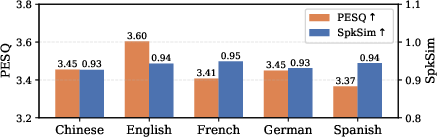
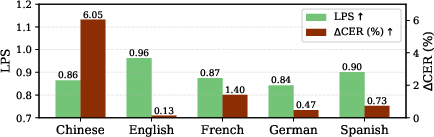
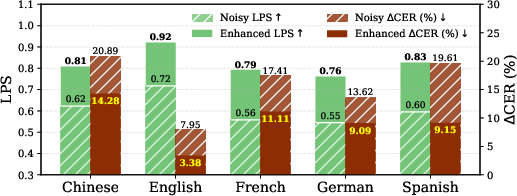
Figure 4: Cross-language analysis of (a) acoustic representations, (b) phonetic representations, and (c) the phonological prior.
Implications and Future Directions
The results evidencing high fidelity and low hallucination from a purely generative model establish UniPASE as a definitive backbone for universal speech enhancement in real-world, multi-distortion scenarios. The explicit semantic–acoustic enhancement separation, adversarial MSRD, and flexible sample-rate handling point to core architectural components for future systems. Given strong cross-lingual transfer, SSL-based phonological priors present scalable solutions for multilingual enhancement pipelines even with monolingual pre-training.
UniPASE’s architecture is amenable to hybridization, as demonstrated in its successful integration (with TF-GridNet) yielding first-place rankings in multi-task challenge settings. The modular design and robust adaptation to powerful discriminative or predictive priors foreshadow expansion into broader speech restoration domains, such as domain adaptation, non-speech audio, and task-specific enhancement (e.g., diarization, speech separation).
Conclusion
UniPASE presents a fully generative, high-fidelity, low-hallucination framework for universal speech enhancement, robust across distortions, languages, and sampling regimes. Through SSL-guided dual-representation enhancement, adversarially regularized acoustic mapping, and efficient post-processing, UniPASE closes the gap between perceptual quality and linguistic reliability, setting a new standard for generative speech enhancement systems and enabling reliable deployment in real-world noisy communication environments.