- The paper introduces DriftSE, a latent equilibrium approach that reinterprets speech denoising as a distribution matching problem via one-step latent drift optimization.
- It leverages kernel-weighted drift fields and multi-layer semantic representations from SSL encoders like HuBERT and WavLM to enhance both acoustic fidelity and high-level semantic content.
- Empirical results on VoiceBank-DEMAND and DNS Challenge datasets show that DriftSE outperforms iterative diffusion-based methods in metrics such as PESQ, SI-SDR, SCOREQ, and DNSMOS.
Speech Enhancement via Drifting Models: An Expert Analysis
Problem Motivation and Framework Overview
The paper "Speech Enhancement Based on Drifting Models" (2604.24199) introduces DriftSE, a generative formulation for speech enhancement leveraging Drifting Models. Classical SE methods such as Wiener filtering and statistical estimators are limited by spectral artifacts and insufficient high-level representation. Deep discriminative architectures (RNNs, LSTMs, DCCRN) improve denoising but at the cost of oversmoothing and perceptual unnaturalness. More recent diffusion-based generative models achieve substantial gains in perceptual quality, yet their reliance on multi-step sampling processes incurs significant computational latency, rendering them suboptimal for real-time low-latency applications.
DriftSE reinterprets denoising as a distributional equilibrium problem, diverging fundamentally from trajectory-based paradigms. Instead of iterative numerical integration, DriftSE learns to perform native one-step inference through latent drift optimization, aligning its pushforward distribution with the clean speech distribution in a semantic latent space.

Figure 1: Overview of the DriftSE framework, illustrating the Direct Mapping formulation for single-step denoising.
Drifting Models: Theory and Structure
Drifting Models operationalize generative mapping by evolving the pushforward distribution of a parameterized function fθ to match a target data distribution. The drift process is driven by a learned correction vector field, decomposed into an attraction towards the empirical data and a repulsion from model-generated samples. Theoretical grounding is provided by mean-shift clustering theory, formalizing the equilibrium as the nullification of drift at each sample point.
The drift field is computed via kernel-weighted means in latent space, where a pre-trained SSL encoder (HuBERT, WavLM, DistilHuBERT) maps waveform inputs into multi-layer semantic representations. This construction enables fine-grained control over perceptual and phonetic content during enhancement, and permits minimization of distributional discrepancies without explicit noisy-clean paired supervision.
DriftSE: Enhancement Paradigms and Latent Drifting Mechanism
DriftSE supports two formulations:
- Direct Mapping: Deterministic or stochastic projection from noisy observations to clean latent states.
- Conditional Generator: Stochastic generation of clean speech from a Gaussian prior, conditioned on noisy input.
The drifting field is evaluated frame-wise across the hierarchical latent space, dynamically contrasting generated and clean distributions to drive equilibrium. Multi-temperature kernel mechanisms modulate drift across layers, ensuring both low-level acoustic fidelity and high-level semantic preservation.
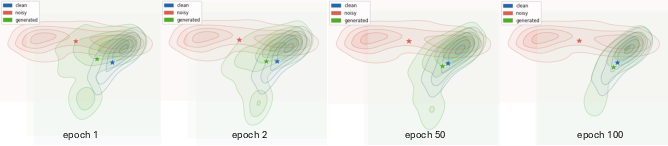
Figure 2: Evolution of frame-level distributions in the DistilHuBERT semantic space, showcasing how the generated distribution drifts from noisy input toward clean speech as training progresses.
Empirical Results and Analysis
DriftSE demonstrates strong numerical performance on VoiceBank-DEMAND and DNS Challenge datasets:
- Direct Mapping (DistilHuBERT, σ=0): Achieves PESQ 3.15 and SI-SDR 16.1 dB, outperforming iterative diffusion-based baselines such as SGMSE+ and one-step MeanFlowSE.
- Conditional Variant: Reaches SCOREQ 4.33 and DNSMOS 3.64, indicating improved perceptual quality and reference-free metrics compared to previous consistency models.
- Generalization: On unseen real-world noisy recordings, DriftSE attains state-of-the-art WV-MOS and SCOREQ, demonstrating robust out-of-domain performance and resilience to paired-data scarcity. Unpaired training is enabled, with only moderate degradation in pairwise fidelity but strong non-intrusive metrics, highlighting distributional flexibility.
The inclusion of noise prior and multi-layer latent drifting are empirically validated. Noise injection trades deterministic precision for perceptual quality, while hierarchical supervision outperforms deepest-layer-only approaches, confirming the necessity of structurally rich latent representations.
Implications and Future Directions
DriftSE represents a shift from trajectory-centric generative models towards latent equilibrium-based distributional matching. The framework's compatibility with unpaired data minimizes reliance on aligned datasets, furthering its scalability. The fusion of multi-step latent supervision and kernelized drift computation presents a robust training signal for SE, and aligns generated speech with high-density regions of the clean distribution without iterative refinement.
Practically, DriftSE offers low-latency, high-fidelity enhancement suitable for deployment in resource-constrained and real-time communication environments. This is particularly relevant for applications demanding both artifact suppression and structural preservation.
Theoretically, the equilibrium approach circumvents the limitations of path discretization and could generalize to other modalities beyond speech (image, video). Future research may extend latent drifting mechanisms to domains where deep semantic encoders provide rich structural priors, and explore adaptive bandwidth selection for kernelized drift in more diverse conditions. Integration with adversarial or diffusion distillation techniques could potentially yield further advances in model expressivity and efficiency.
Conclusion
The paper establishes DriftSE as a single-step latent drifting model for speech enhancement, reconfiguring generative denoising as an equilibrium distribution matching problem. The approach delivers competitive fidelity and perceptual quality across both in-domain and real-world scenarios, with strong results in reference-free metrics and robust generalization. The latent drifting methodology opens new avenues for non-iterative generative speech enhancement, reducing computational cost and broadening applicability in real-time and unpaired-data contexts.