- The paper presents a unified generative framework that leverages latent flow matching and a multi-modal diffusion Transformer to jointly enhance and separate speech signals.
- It employs a three-stage pipeline integrating a pre-trained w2v-BERT extractor, a VAE for latent representation, and a flow predictor to handle both noise and complex acoustic degradations.
- Experimental results demonstrate superior robustness and perceptual quality, outperforming conventional methods under both additive noise and real-world corruptions.
Unified Generative Architecture for Robust Speech Enhancement and Separation
Introduction and Context
The Geneses framework addresses the challenge of simultaneous speech enhancement (SE) and speech separation (SS) in conditions with both additive noise and complex signal degradations, such as reverberation, clipping, codec artifacts, and packet loss. Existing deep neural network (DNN)-based SE-SS methods demonstrate competency under additive-noise-only conditions, but fail in scenarios with multifaceted corruption due to their reliance on mask-based discriminative architectures. Geneses proposes a unified generative modeling strategy employing latent flow matching and a multi-modal diffusion Transformer, targeting joint restoration and separation of clean speech signals from corrupted, multi-speaker mixtures.
System Architecture
Geneses utilizes a three-stage pipeline: an input feature extractor, a variational autoencoder (VAE) for latent representation, and a flow predictor for generative reconstruction. The feature extractor is based on the pre-trained w2v-BERT 2.0 model, selected for its robustness in multilingual and degraded conditions, and is fine-tuned via LoRA to maintain domain knowledge in SSL features. The VAE compresses the waveform into a low-dimensional latent space, separating tracks for each speaker to facilitate both SE and SS via flow matching. Latent flow matching is performed on the compressed representations, leveraging rectified flows for efficient trajectory computation between the noise prior and the target clean latent embedding.
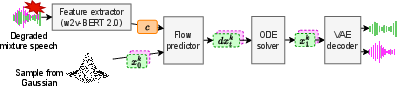
Figure 1: Inference pipeline of Geneses, with flow matching performed on the VAE's latent representation.
The flow predictor, parameterized by θ, employs MM-DiT—a transformer variant with modality-specific weights and shared attention—operating over the concatenated VAE latents, SSL features, and time embeddings. The predictor estimates the directional vector field necessary for ODE-based reconstruction of clean latent states conditionally on the degraded input features.
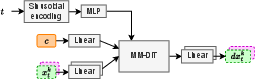
Figure 2: Architecture of the flow predictor responsible for learning the conditional vector field in latent space.
Inference proceeds by sampling a noise prior x0∼N(0,I) and numerically solving the ODE dtdxt=vθ(xt,c,t) to reach the clean separated state x1, subsequently decoded by the pre-trained VAE.
Training Paradigm
Geneses employs MSE minimization between the predicted and ground-truth vector fields in the latent domain, optimizing the flow predictor and LoRA-adapted SSL extractor, with the VAE kept frozen. Unlike conventional SS methods, permutation invariant training (PIT) is avoided since the generative objective is deterministic in directionality for each target latent, and PIT would introduce ambiguity counterproductive to the consistent flow trajectory learning.
Experimental Methodology
The framework is evaluated on two-speaker mixtures from LibriTTS-R, with two degradation regimes: additive noise and complex real-world corruptions comprising reverberation, bandwidth limitation, clipping, codecs, and packet loss, each probabilistically applied. The SSL features are 1,024-dimensional vectors, and the VAE produces 16-dimensional latent vectors at 25 Hz.
Reference-free metrics (DNSMOS, NISQA, UTMOSv2, and WER) and reference-aware metrics (ESTOI, MCD, LSD, SBS, SpkSim) are employed for objective assessment. For baseline comparison, the conventional cascaded SE-SS model with gradient modulation and multi-task learning is replicated.
Numerical Results and Analysis
Under additive-noise-only conditions, Geneses closely matches ground truth in perceptual quality metrics (DNSMOS: 3.40 vs. ground truth 3.37, NISQA: 4.44 vs. 4.73, UTMOSv2: 3.44 vs. 3.65), outperforming the baseline by a substantial margin. However, Geneses exhibits slightly higher WER (0.39) and increased spectral distortion (MCD, LSD) compared to the baseline (WER: 0.35, MCD: 7.17), consistent with known generative SE trade-offs including hallucinations and content loss [scheibleruniversal]. Nevertheless, SBS and SpkSim remain close to oracle values, indicating strong perceptual speaker fidelity.
Critically, under complex degradation, Geneses demonstrates boldly superior robustness. The conventional method becomes ineffective (WER: 5.54, NISQA: 1.34), producing unrecognizable output, while Geneses preserves intelligibility and perceptual quality (WER: 0.43, NISQA: 4.44). All reference-aware metrics confirm this advantage: Geneses approaches ground truth for ESTOI, SBS, and SpkSim, and delivers significantly reduced spectral distortions relative to the baseline. These strong results substantiate the generative model's capacity to generalize beyond additive noise and restore speech under multifaceted real-world corruption.
Implications and Future Directions
The architectural integration of latent flow matching with SSL-based conditioning in Geneses enables unified, data-driven restoration and separation—a marked advance compared to conventionally specialized discriminative approaches. Practically, this paradigm has significant implications for telepresence, extended reality, and data cleansing for large-vocabulary annotation pipelines, where high perceptual quality and intelligibility must be maintained in adverse acoustic conditions.
Theoretical implications extend to generative modeling for other multimodal restoration tasks. The latent flow matching scheme could be adapted to accommodate additional modalities (vision, text, physical sensor data) and more complex speaker mixtures. There is further scope for research into mitigation of hallucination phenomena and improvement of content preservation, leveraging architectural innovations from generative image and language modeling.
Conclusion
Geneses utilizes latent flow matching and multi-modal diffusion transformers for unified SE-SS in scenarios with both additive noise and multidimensional signal degradation. The framework achieves substantially higher perceptual and intelligibility metrics compared to conventional methods, and exhibits robustness against complex corruptions where baseline architectures fail. The generative paradigm adopted by Geneses constitutes a technically sound and extensible foundation for future work in robust, multi-speaker audio restoration.