From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills
Abstract: LLM agents increasingly rely on reusable skills, capability packages that combine instructions, control flow, constraints, and tool calls. In most current agent systems, however, skills are still represented by text-heavy artifacts, including SKILL.md-style documents and structured records whose machine-usable evidence remains embedded largely in natural-language descriptions. This poses a challenge for skill-centered agent systems: managing skill collections and using skills to support agent both require reasoning over invocation interfaces, execution structure, and concrete side effects that are often entangled in a single textual surface. An explicit representation of skill knowledge may therefore help make these artifacts easier for machines to acquire and leverage. Drawing on Memory Organization Packets, Script Theory, and Conceptual Dependency from Schank and Abelson's classical work on linguistic knowledge representation, we introduce what is, to our knowledge, the first structured representation for agent skill artifacts that disentangles skill-level scheduling signals, scene-level execution structure, and logic-level action and resource-use evidence: the Scheduling-Structural-Logical (SSL) representation. We instantiate SSL with an LLM-based normalizer and evaluate it on a corpus of skills in two tasks, Skill Discovery and Risk Assessment, and superiorly outperform the text-only baselines: in Skill Discovery, SSL improves MRR from 0.573 to 0.707; in Risk Assessment, it improves macro F1 from 0.744 to 0.787. These findings reveal that explicit, source-grounded structure makes agent skills easier to search and review. They also suggest that SSL is best understood as a practical step toward more inspectable, reusable, and operationally actionable skill representations for agent systems, rather than as a finished standard or an end-to-end mechanism for managing and using skills.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
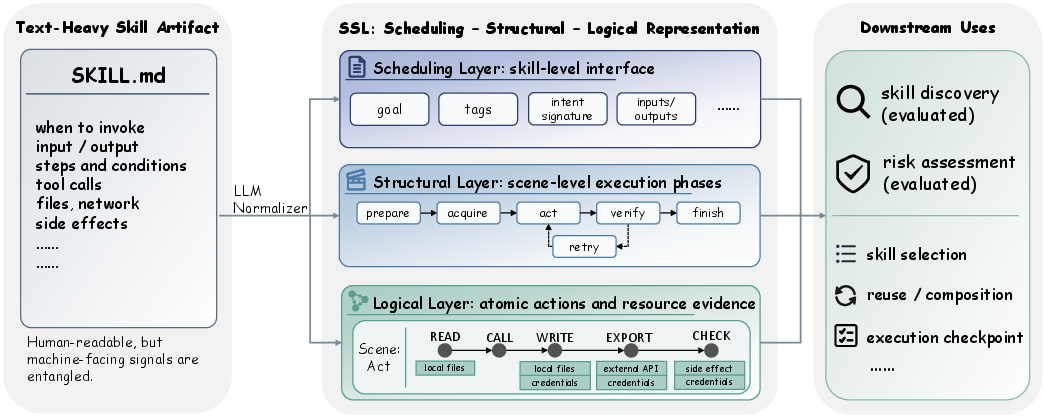
This paper is about making “skills” for AI assistants easier for computers to understand, search, and check for safety. Today, many AI skills are described mostly in long text files (like SKILL.md). That’s easy for people to read but hard for machines to use. The authors propose a new, clearer way to store what a skill does, called the SSL representation, so that both people and machines can work with skills more reliably.
What questions the paper tries to answer
- How can we turn a long, text-heavy skill description into a tidy, structured format that computers can understand without guessing?
- Will this structure make it easier to find the right skill for a user’s request?
- Will this structure help detect possible risks (like accessing private data or doing harmful actions) before a skill is used?
How the researchers approached it (in simple terms)
Think of a skill like a recipe:
- The “when to use it” part (e.g., “Use this recipe when you want pasta”)
- The “steps” part (e.g., “Boil water → add pasta → drain → add sauce”)
- The “tiny actions and resources” part (e.g., “pour 2 cups of water,” “use stove,” “open can of tomatoes”)
The authors built a three-layer structure called SSL that captures these pieces:
- Scheduling layer (When): describes the skill’s purpose, inputs/outputs, and when it should be used.
- Structural layer (How): breaks the skill into ordered “scenes” or phases (like prepare, act, verify).
- Logical layer (What exactly): lists the smallest actions and resources used (like open a file, call a web service, read a password), using consistent labels.
They wrote an LLM-based “normalizer” that reads a SKILL.md file and converts it into this structured SSL form (stored like a neat JSON graph). They kept it “grounded,” meaning only information actually found in the skill’s text is extracted—no guessing.
Then they tested whether SSL helps in two tasks:
- Skill Discovery (finding the right skill for a request) using a large pool of 6,184 skills and 403 test queries.
- Risk Assessment (spotting possible dangers in a skill) over 500 skills labeled across six risk areas (like data exfiltration or destructive behavior).
What they found and why it matters
- Better skill search: Using SSL information alongside short descriptions made it much easier to find the right skill. The main score (MRR) improved from 0.573 to 0.707. In plain terms, the system was more likely to rank the correct skill near the top.
- Better risk spotting: Adding SSL to the original text helped an LLM reviewer notice more risk signals, raising overall macro F1 from 0.744 to 0.787. In other words, organized action/resource details helped catch risks that can be buried in long paragraphs.
- Not a replacement for the original text: SSL works best as a structured “map” next to the skill’s full description. The structure makes key evidence easy to find; the original text provides extra context and examples.
Why this matters:
- Developers and systems can more reliably reuse skills across tasks.
- Registries can search and route skills more accurately.
- Reviewers and safety checks can more quickly see what a skill may do and what resources it touches.
What this could change in the future
If skill descriptions come with SSL:
- AI agents could select and combine skills more confidently.
- App stores for AI skills could search smarter and enforce policies more easily.
- Security reviews could focus on the most relevant, concrete actions (like file access, network calls, or credential use).
The authors note limits: SSL describes static text, so it can miss behaviors that only appear when a skill runs; it depends on an LLM to extract details; and they mainly evaluated search and risk review—not live agent performance yet. Still, SSL is a practical step toward making AI skills more inspectable, reusable, and safer to operate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces SSL and evaluates it on Skill Discovery and Risk Assessment. The following unresolved issues highlight what remains missing, uncertain, or unexplored:
- Absence of a gold-standard structured annotation: no human-curated ground truth for SSL fields, preventing direct measurement of normalizer precision/recall, calibration of extraction errors, or per-field accuracy.
- Limited evaluation scope to offline tasks: no assessment of SSL’s impact on real agent planning, execution, monitoring, recovery, or post-hoc refinement during end-to-end task runs.
- Static-only analysis: SSL is extracted from SKILL.md and ignores runtime behavior; dynamic properties (conditional branching, environment-dependent actions, API return-driven flows) and execution traces are not integrated.
- Code-grounding gap: normalization operates on documentation, not source code or manifests; malicious or outdated docs can misrepresent actual code behavior, risking false safety or incorrect capabilities.
- Lack of provenance and confidence in extraction: SSL does not record source spans, evidence strength, or uncertainty for each field, impeding auditability and trust calibration.
- Closed vocabularies coverage: adequacy of act_type primitives, scene types, and control-flow enums across diverse domains (e.g., robotics, UI automation, web, cloud ops, multimodal I/O) is untested.
- Formal semantics and executability: scene and logic-step transitions lack a formal semantics (e.g., control-flow constructs, pre/postconditions, invariants, loop/branch conditions), limiting machine-checkable validation or simulation.
- Repository-level structure is missing: no mechanism to link skills into dependency graphs (imports, version ranges, capability composition) or to compute cross-skill constraints and compatibilities.
- Versioning and evolution: no procedure to track skill updates, schema migrations, diffs, or incremental re-normalization; open question how to detect and reconcile drift between SSL and changing sources.
- Normalizer robustness: no ablation across LLMs, prompts, or temperatures; sensitivity to prompt wording, model choice, and adversarial/obfuscated docs remains unknown.
- Adversarial resilience: no study of how well SSL resists deceptive SKILL.md (e.g., minimization of risky actions in prose), or evasion by embedding risky behavior in code and benign language in docs.
- Multilingual and multimodal artifacts: normalization is evaluated on English SKILL.md; handling of non-English docs, code comments, images/diagrams, UI flows, or multimodal inputs/outputs is unaddressed.
- Missing integration with policy and enforcement: SSL is not linked to sandboxes, MAC/LSM policies, capability tokens, or runtime permission systems; unclear how SSL fields would drive automated policy checks or gating.
- Human-in-the-loop usage: no user study or workflow design on how auditors, maintainers, or operators use SSL to speed review, reduce errors, or triage risks.
- Cost and scalability: normalization latency/cost per skill, memory/compute overhead for large registries, and throughput of batch normalization/re-normalization are unreported.
- Field-level importance and ablative utility: beyond shallow/scheduling/rich groupings, there is no per-field contribution analysis (e.g., which specific SSL attributes drive retrieval or risk wins).
- Generalization across retrieval models: Skill Discovery fixed a single embedder and FAISS; transferability of SSL gains to other dense retrievers, sparse/hybrid retrieval, or cross-encoders is unknown.
- Query realism in retrieval: queries are model-generated with manual checks; impact on performance with fully human-authored, noisy, or ambiguous queries and task narratives remains untested.
- Severity calibration in Risk Assessment: moderate-or-higher thresholds favored full text; how to augment SSL with contextual safeguards (confirmations, scopes, human approvals) to improve severity judgments is open.
- Labeling protocol validity: risk labels rely on LLM triage (median of three models) with spot checks; alignment to expert audits, inter-rater reliability, and correlation with real-world incident rates are unverified.
- Multi-source consolidation: most skills include code, config, examples, and READMEs; combining heterogeneous artifacts (code analysis, API specs, logs) into a unified SSL without hallucination is not addressed.
- Data-flow and resource modeling depth: current resource-use evidence is coarse; fine-grained data lineage, taint tracking, secrets flow, and persistence scope are not modeled or validated.
- Compositionality and reuse: how SSL supports composing multiple skills, resolving interface mismatches, or synthesizing new skills from scenes/logic steps is unstudied.
- Conflict and contradiction handling: the schema does not capture contradictory or ambiguous statements in source docs, nor does it expose unresolved conflicts for reviewer attention.
- Uncertainty-aware reasoning: no mechanism for SSL to carry confidence scores into downstream decision-making (e.g., risk judges weighting low-confidence fields differently).
- Interoperability with existing standards: mapping between SSL and OpenAPI/JSON Schema, workflow engines (e.g., BPMN), or capability specs (e.g., Android intents, OAuth scopes) is unspecified.
- Real-world security outcomes: improvements are shown in structured detection metrics, but not linked to reduced exploitation rates, time-to-detect, or reviewer productivity in live settings.
- Error recovery and safety scaffolding: representation of safeguards (rate limits, confirmations, canary writes, dry-run modes) and fallback paths is insufficiently formalized for automated assessment.
- Schema governance: there is no process for extending the act_type inventory, deprecating fields, or community-driven evolution of the schema while preserving backward compatibility.
- Confidence-weighted retrieval and ranking: how to integrate SSL fields as structured features in learned rerankers or graph-aware retrieval (beyond simple embedding concatenation) is not explored.
- Agent-time consumption: whether agents can exploit SSL during planning (e.g., preconditions, checkpoints, expected effects) to reduce errors or improve sample efficiency remains open.
- Calibration on sparse/underspecified skills: when SKILL.md is minimal, how SSL should represent unknowns, defer judgments, or request human input is not specified.
- Benchmark external validity: the 6,184-skill corpus and 500-skill risk set may not reflect proprietary, enterprise, or domain-specific skills (finance, healthcare, ICS); cross-domain generalization is untested.
- Continual monitoring: no design for detecting when external API changes invalidate SSL (e.g., endpoints deprecated, scope semantics altered) or for automated re-verification.
- Explainability for evaluators: SSL does not provide human-readable rationales bound to source evidence for each risk dimension, which would support traceable, auditable decisions.
- Guarding against over-regularization: the normalizer may compress nuanced behavior into coarse enums; guidelines to avoid loss of critical intent or safeguards during normalization are not validated.
- Integration with program analysis: hybrid pipelines combining SSL with static/dynamic code analysis, permission inference, and API spec parsing are proposed but not implemented or evaluated.
Practical Applications
Immediate Applications
The paper’s SSL representation (Scheduling–Structural–Logical) and LLM-based normalizer can be applied now to improve how agent skills are documented, discovered, governed, and integrated across organizations. The following use cases map to concrete sectors and workflows.
- Industry (Software Platforms) — Skill registries with better search and routing:
- What: Use SSL-Rich fields (skill goals, intent signatures, scene types, inputs/outputs) to index skills and retrieve them for user queries; plug into existing FAISS/Vector DB pipelines.
- Why: The paper reports retrieval MRR gains from 0.573 to 0.707 using Desc + SSL-Rich.
- Tools/products/workflows:
- “SSL Indexer” microservice that runs the normalizer over SKILL.md and pushes JSON to a vector index.
- Router/ranker that embeds SSL-derived fields for candidate selection.
- Assumptions/dependencies: Skills have SKILL.md-like artifacts; embedding model availability; normalizer quality on your domain.
- Industry (Enterprise IT/Security) — Risk triage dashboards for third‑party skills:
- What: Parse SSL Logical layer (atomic actions, resources) to auto-flag risks (e.g., data exfiltration, destructive ops, credential access) and drive approval workflows.
- Why: Macro F1 for risk detection improves from 0.744 (Full MD) to 0.787 (MD + SSL).
- Tools/products/workflows:
- “Skill Risk Center” that ingests SSL JSON, maps act_types/resources to a risk taxonomy, and surfaces findings in a SOC dashboard.
- Policy-as-code rules (e.g., OPA/Rego) that consume SSL fields for gating installs.
- Assumptions/dependencies: Static analysis limits; need human-in-the-loop for severity; enumerations must reflect your environment (e.g., internal data zones).
- Industry (DevOps/MLOps) — CI linting and manifest enforcement for skills:
- What: Add an SSL normalizer to CI to validate skill manifests, check required fields, and warn on risky capabilities before merge.
- Tools/products/workflows:
- GitHub Action/CI job that fails on missing intent signatures or undefined resource scopes.
- PR diff viewers that highlight changes in scenes and logical steps (“structural diffs”).
- Assumptions/dependencies: Stable schema governance; developer adoption.
- Industry (Platform Ops) — Permission/least‑privilege scaffolding:
- What: Generate fine-grained permission manifests (e.g., tool scopes, file directories) from SSL Logical resource evidence and attach to runtime sandboxes.
- Tools/products/workflows:
- Policy generator translating SSL to sandbox profiles (macOS TCC, Linux seccomp/AppArmor, container capabilities).
- Assumptions/dependencies: Runtime supports granular permissions; SSL coverage of resources is sufficient.
- Industry (Vendor/Marketplace) — Safer skill installation flows:
- What: Use SSL to render “capability and risk consent” screens listing concrete actions/resources; require user approval per scope.
- Tools/products/workflows:
- App store UI components sourced from SSL fields (scenes, act_types, data flows).
- Assumptions/dependencies: UX alignment; accurate normalization of third‑party artifacts.
- Academia (IR/NLP/SE Research) — Reproducible retrieval and security benchmarks:
- What: Use the released 6,184-skill corpus and SSL annotations for research on tool/skill retrieval, structural representations, and risk detection.
- Tools/products/workflows:
- Baseline replicators embedding different SSL field subsets; ablations on scene vs logical features.
- Assumptions/dependencies: Continued dataset availability; consistent schema adherence.
- Academia/Education — Teaching structured agent design:
- What: Use SSL to teach students to decompose capabilities into goals, scenes, and actions; auto-grade completeness and safety considerations.
- Tools/products/workflows:
- Course assignments where students author SKILL.md and compare the normalized SSL to rubrics.
- Assumptions/dependencies: Educator-provided rubrics; manageable domain scope.
- Cross‑sector (Compliance) — Pre‑deployment compliance checks:
- What: Map SSL resource targets and data-flow cues to regulatory controls (e.g., PHI/PII handling for HIPAA/GDPR); generate audit evidence.
- Sectors: Healthcare, finance, enterprise SaaS.
- Tools/products/workflows:
- “Compliance Mapper” that tags SSL resources with data-classification labels and checks against policy rules.
- Assumptions/dependencies: Accurate data classification; legal interpretation remains human-led.
- Cross‑sector (Observability) — Scene‑aware monitoring and runbooks:
- What: Tie telemetry to SSL Structural scenes to generate runtime checkpoints, timeouts, and recovery steps.
- Sectors: Customer support automation, IT automation, operations.
- Tools/products/workflows:
- Orchestrator plugins that align logs with scene IDs for easier incident triage.
- Assumptions/dependencies: Instrumentation to emit scene IDs; alignment between static scenes and runtime behavior.
- Daily Life/Consumer Agents — Transparent capability cards:
- What: Present end users with structured “skill cards” listing goals, steps, and required resources; enable informed consent and easier skill selection.
- Tools/products/workflows:
- Personal agent apps rendering SSL summaries with toggles for optional operations.
- Assumptions/dependencies: Consumer-facing UIs; non-technical explanations derived from SSL.
- Industry (Integration/Standards) — Interop bridges with existing manifests:
- What: Convert between SSL and OpenAPI/JSON Schema/function-call specs to unify tool/skill catalogs.
- Tools/products/workflows:
- “Manifest Bridge” library mapping SSL scheduling layer to API signatures and back.
- Assumptions/dependencies: Mapping coverage; fidelity losses in round‑trip conversions.
- Security Engineering — Automated red-teaming scaffolds:
- What: Feed SSL graphs to red-team frameworks to synthesize attack paths targeting risky scenes/steps.
- Tools/products/workflows:
- Scenario generators that mutate scenes and act_types to probe unsafe behaviors.
- Assumptions/dependencies: Static model of behavior; false positives require human review.
Long-Term Applications
These opportunities require broader adoption, runtime signals, formalization, or ecosystem standards to realize.
- Industry/Robotics/Operations — SSL‑aware automated planners and composers:
- What: Use SSL graphs to plan, adapt, and compose multi-skill workflows at inference time (e.g., automated service runbooks, robotic task sequencing).
- Dependencies: Runtime traces to refine scenes; compositional planners; reliable action semantics.
- Cross‑ecosystem — Repository‑level “Graph of Skills” and supply‑chain analytics:
- What: Build dependency graphs across SSL artifacts for recommendation, deduplication, and impact analysis (e.g., which skills break if an API changes).
- Dependencies: Broad repository participation; consistent identifiers; versioning and provenance.
- Formal Safety/Verification — Model checking over skill structures:
- What: Translate scenes/logic steps to formal models (e.g., state machines) and verify properties (no write without confirmation, no secret exfiltration).
- Dependencies: Formal semantics for act_types/resources; toolchains (TLA+, Alloy) and expertise.
- Runtime Governance — Just‑in‑time privilege granting:
- What: Use SSL to request and grant capabilities per scene (capability-based security), revoking after completion.
- Dependencies: OS/container sandboxes with dynamic policies; low-latency policy engines.
- Standards/Policy — Skill manifest standards and certification:
- What: Establish SSL-like standards for public skill distribution; regulators and app stores require manifests for labeling and certification.
- Sectors: Consumer AI platforms, healthcare/finance regulated software.
- Dependencies: Multi‑vendor consensus; governance bodies; compliance frameworks.
- Training LLMs — SSL‑supervised skill internalization:
- What: Use SSL as supervision to train models to reason over goals/scenes/actions, improving in‑context routing and safe tool use.
- Dependencies: Large-scale SSL corpora; curriculum design; evaluation metrics linking structure to behavior.
- IDEs/Authoring — Schema‑guided skill authoring and autocompletion:
- What: Developer tools that generate scene skeletons, suggest resources, and auto‑fill intent signatures from examples.
- Dependencies: Mature schema extensions; feedback loops from runtime traces to authoring suggestions.
- Sector‑specific Templates — Domain manifests with risk controls:
- What: Prebuilt SSL templates for healthcare (PHI redaction, consent scenes), finance (approval scenes), energy (fail‑safe actions).
- Dependencies: Domain ontologies; stakeholder input; certified guardrails.
- Regulatory Auditing — End‑to‑end provenance and attestations:
- What: Tie runtime logs to SSL steps to generate auditable trails and machine‑readable attestations for external audits.
- Dependencies: Trusted logging, signing, and secure storage; standardized attestation formats.
- Multi‑agent Systems — Negotiation and coordination via scene contracts:
- What: Agents expose scenes as contracts for coordination (who provides which resource, when), enabling robust teamwork.
- Dependencies: Protocols for scene exchange; trust and identity layers; conflict resolution mechanisms.
- Edge/Embodied AI — Safety‑aware actuation maps:
- What: Map SSL Logical actions to physical actuators with safety interlocks and formal constraints for robots/drones.
- Dependencies: High‑fidelity actuation models; certification processes; runtime monitors.
- Market Analytics — Skill quality and risk scoring at scale:
- What: Combine SSL features with usage metrics to score discoverability, reliability, and risk for marketplace ranking.
- Dependencies: Telemetry integration; bias and fairness controls; shared benchmarks.
Key Assumptions and Dependencies Across Applications
- Input availability: Skills must have sufficient textual artifacts (e.g., SKILL.md) for normalization; low-quality docs reduce fidelity.
- Normalizer accuracy: LLM-based extraction must reliably fill typed fields; domain-specific tuning may be required.
- Static vs dynamic behavior: SSL is static; dynamic code paths, downloads, or conditional behaviors need runtime traces to avoid under/over-reporting.
- Schema governance: Closed vocabularies and enums must evolve without fragmenting ecosystems.
- Integration readiness: Runtime systems require permissioning, logging, and policy engines to act on SSL evidence.
- Human oversight: Risk assessment and compliance remain human-led for severity/context judgments.
- Interoperability: Alignment with existing standards (OpenAPI, JSON Schema, SBOM) improves adoption and reduces vendor lock-in.
Glossary
- ablation: An analysis technique where parts of a system are removed or altered to assess their contribution. Example: "The ablation further shows that the choice of structured fields matters."
- act_type: A typed label selecting the primitive action category for an atomic step in the logical layer. Example: "Each atomic action selects an act_type from the closed primitive inventory as described in Appendix~\ref{app:ssl-schema}, and records arguments, effects, and resource boundaries as typed evidence."
- atomic actions: Minimal operational steps captured in the logical layer, representing the smallest actions without inferring implementation. Example: "a logical graph of atomic actions and resource-use evidence."
- closed primitive inventory: A restricted set of predefined action primitives that atomic actions must draw from. Example: "closed primitive inventory"
- Conceptual Dependency: A theory that represents sentence meaning using primitive action structures, abstracting away from surface form. Example: "Conceptual Dependency, which decomposes linguistic meaning into primitive action structures that abstract away from surface wording"
- containment links: Relations that explicitly record hierarchical membership among layers (e.g., steps within scenes). Example: "Validation checks structural well-formedness, identifier consistency, allowed enum values, containment links, entry pointers, and transition targets;"
- control-flow features: Properties indicating how execution proceeds or branches within a skill. Example: "intent signature, control-flow features, and an aggregate scene profile;"
- covert execution: Running actions in a hidden or non-transparent way that may conceal behavior. Example: "data exfiltration, destructive behavior, privilege escalation, covert execution, resource abuse, and credential access."
- data exfiltration: Unauthorized or risky transfer of data out of a controlled environment. Example: "data exfiltration, destructive behavior, privilege escalation, covert execution, resource abuse, and credential access."
- DeepSeek-V3.2: A specific LLM used as a fixed evaluator in the risk assessment experiments. Example: "For evaluation, we fix the judge to DeepSeek-V3.2"
- entry pointers: References to the starting scene or logic step in the structured representation. Example: "Validation checks structural well-formedness, identifier consistency, allowed enum values, containment links, entry pointers, and transition targets;"
- FAISS inner-product index: A similarity search structure (from FAISS) using inner products to rank vector embeddings. Example: "All methods rank the same 6,184 candidates using a FAISS inner-product index over L2-normalized embeddings"
- Frame Semantics: A linguistic theory where meanings are understood relative to structured scenes with participant roles. Example: "Fillmore's Frame Semantics treats word meaning as grounded in scenes with participant roles"
- Frame Theory: A knowledge representation approach using frames with slots and defaults to model familiar situations. Example: "Minsky's Frame Theory represents familiar situations through slots, defaults, and expectations"
- indirect prompt-injection: An attack where external text indirectly influences an agent’s instructions or behavior. Example: "Indirect prompt-injection work shows that retrieved or tool-returned text can blur the distinction between data and instructions"
- L2-normalized embeddings: Vector representations scaled to unit L2 norm, commonly used for similarity computations. Example: "L2-normalized embeddings"
- least-authority execution: A security principle ensuring components run with the minimal privileges needed. Example: "least-authority execution frames safety as a question of privilege boundaries and resource access"
- LLM-based normalizer: A language-model-driven component that parses and converts text artifacts into the structured SSL schema. Example: "We then instantiate SSL with an LLM-based normalizer that converts existing SKILL.md files into the SSL schema."
- logic-step graph: The graph capturing transitions among atomic logic steps within the logical layer. Example: "G_{\mathrm{log}$ is the logic-step graph,"</li> <li><strong>logical layer</strong>: The SSL layer that encodes atomic actions, their arguments, effects, and resource use. Example: "The logical layer corresponds to $G_{\mathrm{log}$ in Eq.~\ref{eq:ssl-representation}."
- macro F1: The unweighted average of F1 scores computed independently per class/dimension. Example: "improves macro F1 from 0.744 to 0.787"
- mean absolute error (MAE): The average absolute difference between predicted and true scores; reported here as a macro average. Example: "macro mean absolute error (MAE) on the original 1--5 scores."
- mean reciprocal rank (MRR): An information-retrieval metric averaging the reciprocal rank of the first relevant item. Example: "We report mean reciprocal rank (MRR) as the primary metric because each query has one source skill"
- Memory Organization Packets: Schema-like structures that organize knowledge around recurring goals to support retrieval and context. Example: "Memory Organization Packets model recurring goal-oriented contexts"
- NDCG@10: Normalized Discounted Cumulative Gain computed at rank 10, assessing top-10 ranking quality. Example: "and use NDCG@5, NDCG@10, and Recall@10 to measure top-rank quality and top-10 coverage."
- NDCG@5: Normalized Discounted Cumulative Gain computed at rank 5, assessing top-5 ranking quality. Example: "and use NDCG@5, NDCG@10, and Recall@10 to measure top-rank quality and top-10 coverage."
- privilege escalation: Gaining higher permissions than intended, posing security risks in agent skills. Example: "data exfiltration, destructive behavior, privilege escalation, covert execution, resource abuse, and credential access."
- prompt-flow integrity: Ensuring that the sequence of prompts and responses remains unmanipulated and trustworthy. Example: "Work on prompt-flow integrity, mandatory access control, and least-authority execution frames safety as a question of privilege boundaries and resource access"
- Qwen3-Embedding-0.6B: A specific embedding model used to produce dense vectors for retrieval. Example: "and all dense vectors are produced with Qwen3-Embedding-0.6B~\citep{qwen3embedding_2025}."
- resource abuse: Misuse or overuse of computational or external resources by a skill. Example: "data exfiltration, destructive behavior, privilege escalation, covert execution, resource abuse, and credential access."
- scheduling layer: The SSL layer capturing invocation-level capability, inputs/outputs, and high-level cues. Example: "The scheduling layer corresponds to $r_{\mathrm{sch}$ in Eq.~\ref{eq:ssl-representation}."
- scheduling record: The structured summary of invocation-level signals in SSL. Example: "a scheduling record for invocation-level signals"
- Script Theory: A theory modeling stereotyped activities as ordered scenes with roles and transitions. Example: "Script Theory represents stereotyped activities as ordered event sequences with roles and transitions"
- SKILL.md: A text-heavy instruction/documentation file used to describe a skill. Example: "SKILL.md-style instruction files"
- source-grounded intermediate representation: A structured form derived strictly from evidence in the original artifact without speculative inference. Example: "instead of as a reusable, source-grounded intermediate representation that disentangles invocation interfaces, execution structure, and action/resource-use evidence."
- source-grounded normalizer: A converter that preserves traceability to the original source while producing SSL. Example: "converted by a source-grounded normalizer"
- stratified sampling: A sampling strategy ensuring coverage across predefined strata or categories. Example: "We adopt a stratified sampling to ensure that the benchmark includes enough skills with observable risk-relevant evidence"
- structural layer: The SSL layer representing scenes and their phase-level transitions. Example: "The structural layer corresponds to $G_{\mathrm{str}$ in Eq.~\ref{eq:ssl-representation}."
- structural well-formedness: A validity property ensuring the representation’s graphs and references are consistent and properly structured. Example: "Validation checks structural well-formedness, identifier consistency, allowed enum values, containment links, entry pointers, and transition targets"
Collections
Sign up for free to add this paper to one or more collections.

