- The paper introduces a modular, multi-agent system that automates target safety assessment by integrating diverse biomedical evidence.
- The framework employs a hierarchical agent architecture with programmatic hooks to ensure robust validation, data provenance, and error mitigation.
- The interactive human-in-the-loop process allows expert revisions at the section level, enhancing reproducibility and regulatory compliance.
TSAssistant: Agentic Framework for Human-in-the-Loop Target Safety Assessment
Introduction
Target Safety Assessment (TSA) is pivotal in preclinical drug discovery, requiring integration of genetic, transcriptomic, homology, pharmacological, and clinical evidence to identify potential safety liabilities associated with therapeutic targets. Manual TSA workflows are iterative, expert-driven, and lack standardization, impeding scalability and reproducibility. The increasing complexity and volume of biomedical evidence exacerbate these challenges. TSAssistant introduces a modular, multi-agent, human-in-the-loop system to automate evidence synthesis while preserving expert-driven decision-making, enforcing programmatic constraints, and supporting iterative refinement at the section level.
Hierarchical Agent Architecture and Enforcement Mechanisms
TSAssistant leverages a hierarchical multi-agent architecture wherein an Orchestrator delegates TSA report composition to specialized Research and Synthesis Subagents, each responsible for ground-truthing and citation within distinct evidence domains (Figure 1). Subagents interact with biomedical sources via MCP-standardized tool interfaces, ensuring structured retrieval and provenance tracking. Context isolation and cross-agent memory stores enable controlled information transfer, minimizing context pollution and error propagation. The execution lifecycle incorporates pre-, post-, and runtime hooks for security, validation, citation checking, memory compression, and quality assurance, delivering hard constraints beyond LLM prompt bias.
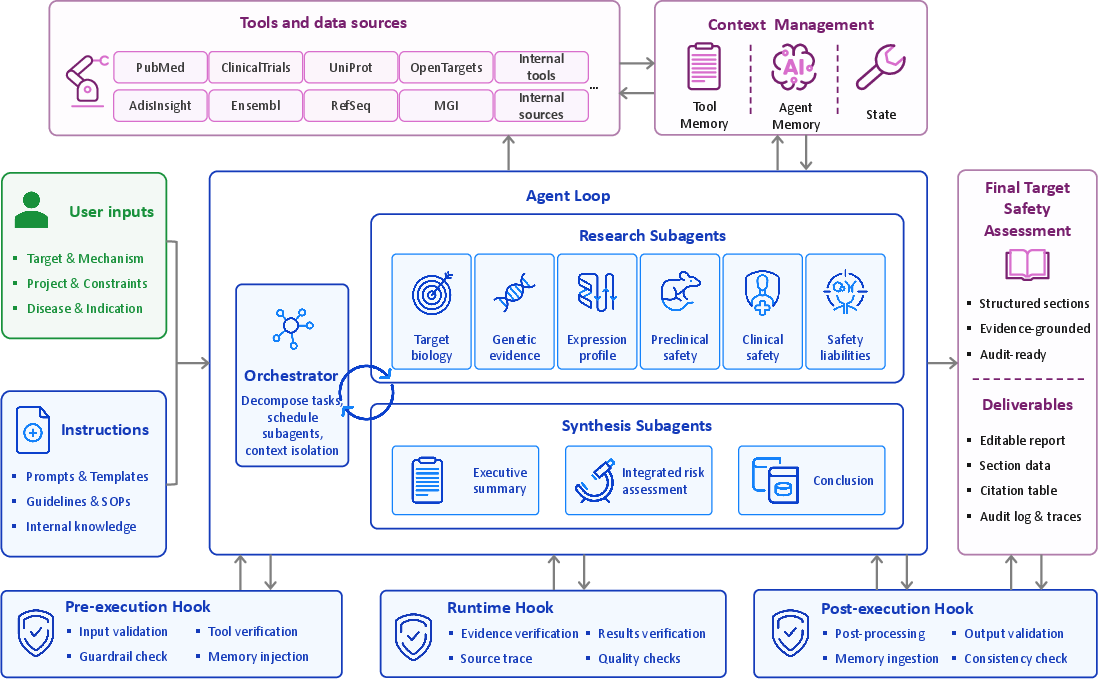
Figure 1: TSAssistant's hierarchical agent pipeline decomposes TSA drafting into specialized subagents, enforcing modularity, citation traceability, and programmatic validation via hooks and memory stores across curated biomedical sources.
Context management comprises tool memory (persistent evidence records with full provenance), agent memory (compressed factual representations for downstream synthesis), and execution state (supporting pipeline resumability). This design mimics expert workflows and facilitates cross-section validation, auditability, and efficient targeted revision.
Three-Layered Instruction Architecture
Agent behavior is governed by a stratified prompt framework:
- Layer 1: System Prompts encode agent roles, coordination, expected structure, and global quality constraints.
- Layer 2: Domain Skill Modules encapsulate section-specific retrieval strategies, evidence weighting heuristics, and domain writing guidelines; these modules are independently versioned for maintainability.
- Layer 3: Runtime User Instructions inject project- and context-specific constraints, superseding lower-layer defaults for granular customization.
This separation enables robust adaptation: domain specialists can refine evidence interpretation in one section without destabilizing global coordination, while project owners maintain context-specific integrity.
Interactive Human-in-the-Loop Refinement
Following initial draft generation, TSAssistant implements an interactive refinement loop for section-level expert review (Figure 2). Experts can edit content, append information, upload new evidence, or re-invoke subagents for targeted revision. System memory preserves conversational context, enabling iterative adaptation of retrieval and prompt strategies. Human validation occurs at the section level, intercepting errors earlier and reducing downstream error cost. Citation enforcement and evidence traceability are designed for regulatory compliance, supporting audit readiness.
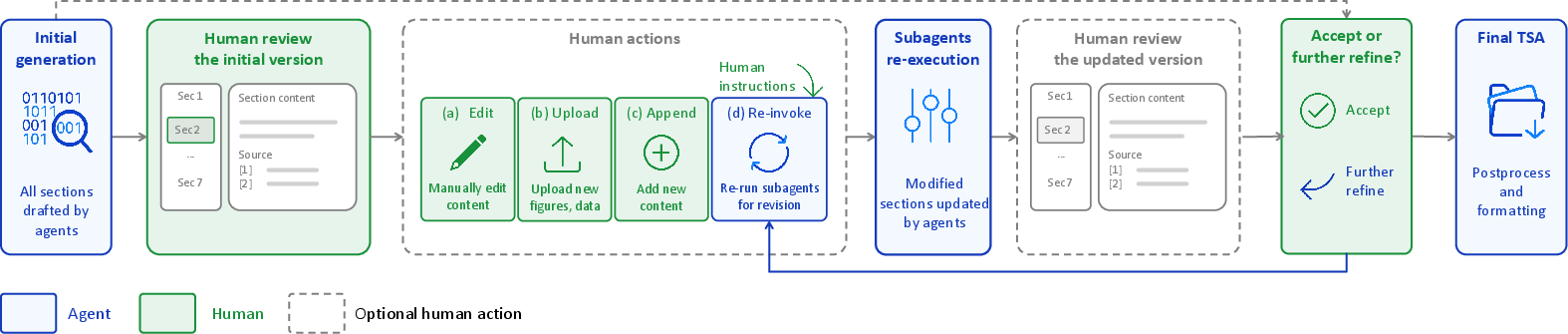
Figure 2: TSAssistant's section-level interactive refinement loop enables expert-driven revision, memory preservation, and personalized retrieval adaptation within modular report sections.
Subagents access domain-specific biomedical evidence via MCP tool interfaces, integrating resources such as Ensembl, RefSeq, UniProt, Gene Ontology, KEGG, Reactome, NHGRI-EBI GWAS Catalog, ClinVar, Human Protein Atlas, GTEx, Expression Atlas, Open Targets, MGI, ClinicalTrials.gov, and AdisInsight. Each interface encodes multi-step data processing, filtering, cross-referencing, and provenance tagging before evidence reaches the LLM. This design enforces consistent methodology, data standardization, and analytic logic reflecting domain expert workflows.
Evaluation Framework
TSAssistant is evaluated across 50+ therapeutic targets, with reports assessed for factual consistency, evidence completeness, structural alignment, and evidence traceability:
- Factual Consistency: Claims are cross-verified against cited evidence and categorized as supported, unsupported, contradicted, or hallucinated.
- Evidence Completeness: Section coverage of expected subdomains (e.g., GWAS, knockout phenotypes, variant burden) is reviewed.
- Structural Alignment: Conformance with internal TSA templates, writing style, hedging language, and evidence prioritization is measured.
- Evidence Traceability: Fraction of claims with verifiable, primary-source inline citations is tallied.
Expert workflow efficiency (drafting time, refinement cycles) is measured for practical impact; quantitative results are pending, but the design highlights improved error detection and modular revision capabilities.
Implications and Future Directions
TSAssistant operationalizes a hybrid AI-human model for TSA report drafting, explicitly aligning with regulatory guidelines mandating expert accountability for safety decisions. Section-level modularity supports personalized revision pipelines, early interception of errors, and integration of ambiguous or conflicting evidence. The dual enforcement (prompt structure and programmatic hooks) addresses critical requirements for reproducibility, traceability, and auditability.
The framework is extensible: domain skill modules and tool interfaces can be adapted to emerging evidence types and expanded to related safety endpoints (e.g., genotoxicity, cardiotoxicity). Anticipated developments include automated evidence conflict resolution, integration of proprietary data assets, and tighter error mitigation pipelines. The approach provides a generalizable blueprint for agentic systems in regulated scientific workflows demanding evidence-backed traceability and human oversight.
Conclusion
TSAssistant presents a modular, hierarchical, multi-agent system for target safety assessment, integrating structured prompt engineering, programmatic hard constraints, and interactive human-in-the-loop reinforcement. The system streamlines evidence synthesis and report composition in high-stakes pharmaceutical domains, maintaining expert-driven decision authority and facilitating regulatory-compliant traceability. This architecture underscores the value of agentic AI as an augmentation—rather than a replacement—for scientific workflows requiring nuanced expert interpretation, laying groundwork for broader adoption of hybrid AI-human methodologies in biomedicine.