MedAI: Evaluating TxAgent's Therapeutic Agentic Reasoning in the NeurIPS CURE-Bench Competition
Abstract: Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions among patient characteristics, disease processes, and pharmacological agents. Tasks such as drug recommendation, treatment planning, and adverse-effect prediction demand robust, multi-step reasoning grounded in reliable biomedical knowledge. Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG). TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse), integrating FDA Drug API, OpenTargets, and Monarch resources to ensure access to current therapeutic information. In contrast to general-purpose RAG systems, medical applications impose stringent safety constraints, rendering the accuracy of both the reasoning trace and the sequence of tool invocations critical. These considerations motivate evaluation protocols treating token-level reasoning and tool-usage behaviors as explicit supervision signals. This work presents insights derived from our participation in the CURE-Bench NeurIPS 2025 Challenge, which benchmarks therapeutic-reasoning systems using metrics that assess correctness, tool utilization, and reasoning quality. We analyze how retrieval quality for function (tool) calls influences overall model performance and demonstrate performance gains achieved through improved tool-retrieval strategies. Our work was awarded the Excellence Award in Open Science. Complete information can be found at https://curebench.ai/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about using AI to help doctors make safe and smart decisions about treatments, like choosing the right medicine for a patient. The authors test and improve a special AI system called TxAgent, which can look up medical facts from trusted sources and reason through tricky questions step by step. They evaluate TxAgent in a competition called CURE-Bench at NeurIPS 2025, which checks how well AI systems understand medical problems, use tools correctly, and explain their thinking. Their team won the Excellence Award in Open Science.
Goals and Questions
The paper focuses on a few simple questions:
- How can an AI safely recommend treatments and predict side effects by using reliable medical information?
- Does improving the AI’s ability to “look things up” (retrieve information) make it better at answering medical questions?
- Which tools and strategies help the AI choose the right medical databases at the right time?
- What happens to performance when different types of retrieval methods (sparse vs. dense) and different LLMs are used?
How the AI Works (Methods and Approach)
Think of TxAgent as a smart, careful assistant that can use a set of medical “apps” (tools) to answer questions. When given a patient’s situation, it follows a repeatable plan:
- It rewrites the question to make the main goal clear (for example, “find side effects of a drug for a pregnant patient”).
- It picks the best tools from a collection called ToolUniverse. These tools connect to trusted databases like the FDA Drug API, OpenTargets, Monarch, and DailyMed.
- It makes “function calls,” which are like sending a precise request to a specific app. For example, “Get the official drug label for Drug X.”
- It reads the results, decides if more information is needed, and repeats the process until it can give a good answer with reasons.
- Finally, it produces an answer and a “reasoning trace,” which shows the steps it took and the tools it used.
Key ideas explained in everyday language:
- Agentic AI: An AI that not only talks but also “acts”—it plans, chooses tools, checks results, and updates its approach as it goes.
- Retrieval-Augmented Generation (RAG): When the AI doesn’t just rely on what it “remembers,” but actively looks up fresh information from trusted sources and uses it to answer correctly.
- Tool calling / function calls: The AI decides which specialized app to use and sends it a properly formatted request to get exact data (like a drug’s official label).
- Sparse vs. dense retrievers: Two ways the AI matches a question to the right tool description. Sparse (like BM25) uses exact word matching; dense uses meaning and context.
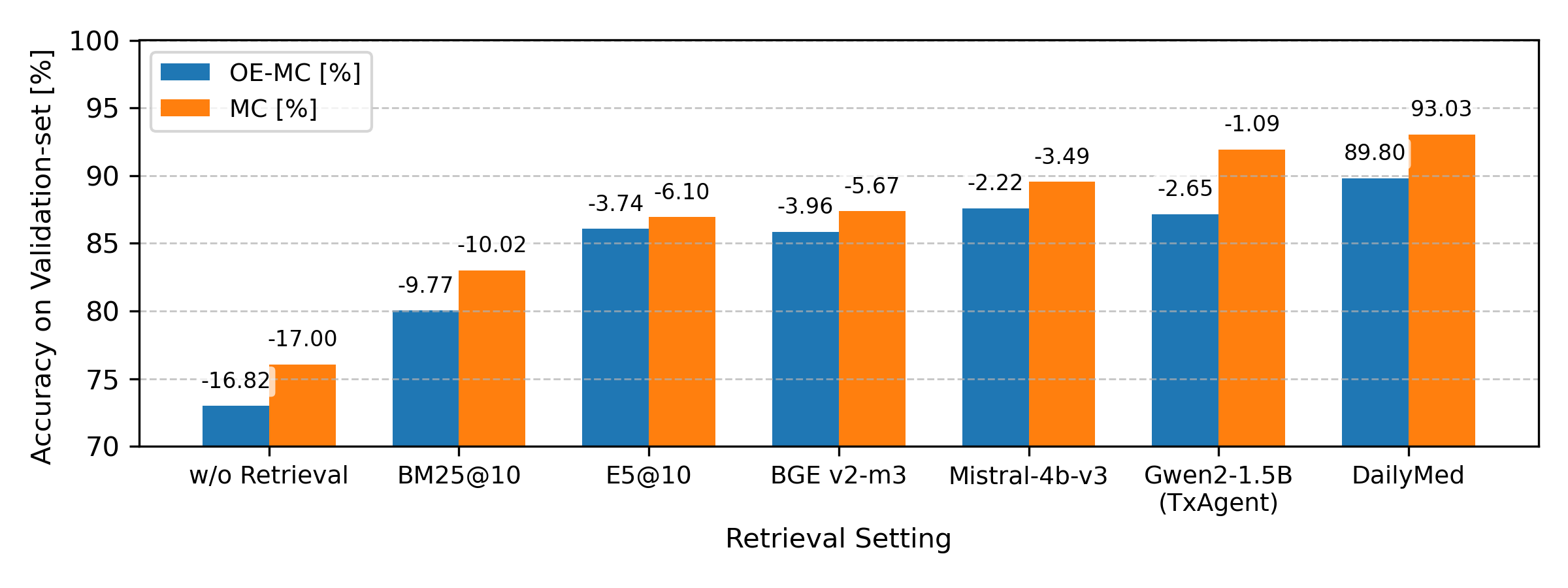
The authors also added a new tool: DailyMed, which provides full, official drug labels (called Structured Product Labeling or SPL). This helps the AI get complete, up-to-date, human-readable medical information in one go, rather than piecing it together from many smaller queries.
They evaluated TxAgent using CURE-Bench datasets with different question styles:
- Multiple-choice (MC): Pick the best answer from four options.
- Open-ended (OE): Write a free-text answer.
- Open-ended multiple-choice (OE-MC): First write an answer, then use it to pick from multiple choices.
Main Findings and Why They Matter
Here are the main results, explained simply:
- Better retrieval leads to better answers: When the AI picks the right tool and fetches the right information, its accuracy improves. Mistakes in tool choice or poorly formatted requests cause errors later.
- DailyMed makes a big difference: Adding the DailyMed tool helped TxAgent access complete and up-to-date drug labels, which boosted performance in the challenge.
- Dense retrievers generally outperformed sparse ones: Methods that match meaning (dense) did better than exact word matching (sparse), especially because tool descriptions are short.
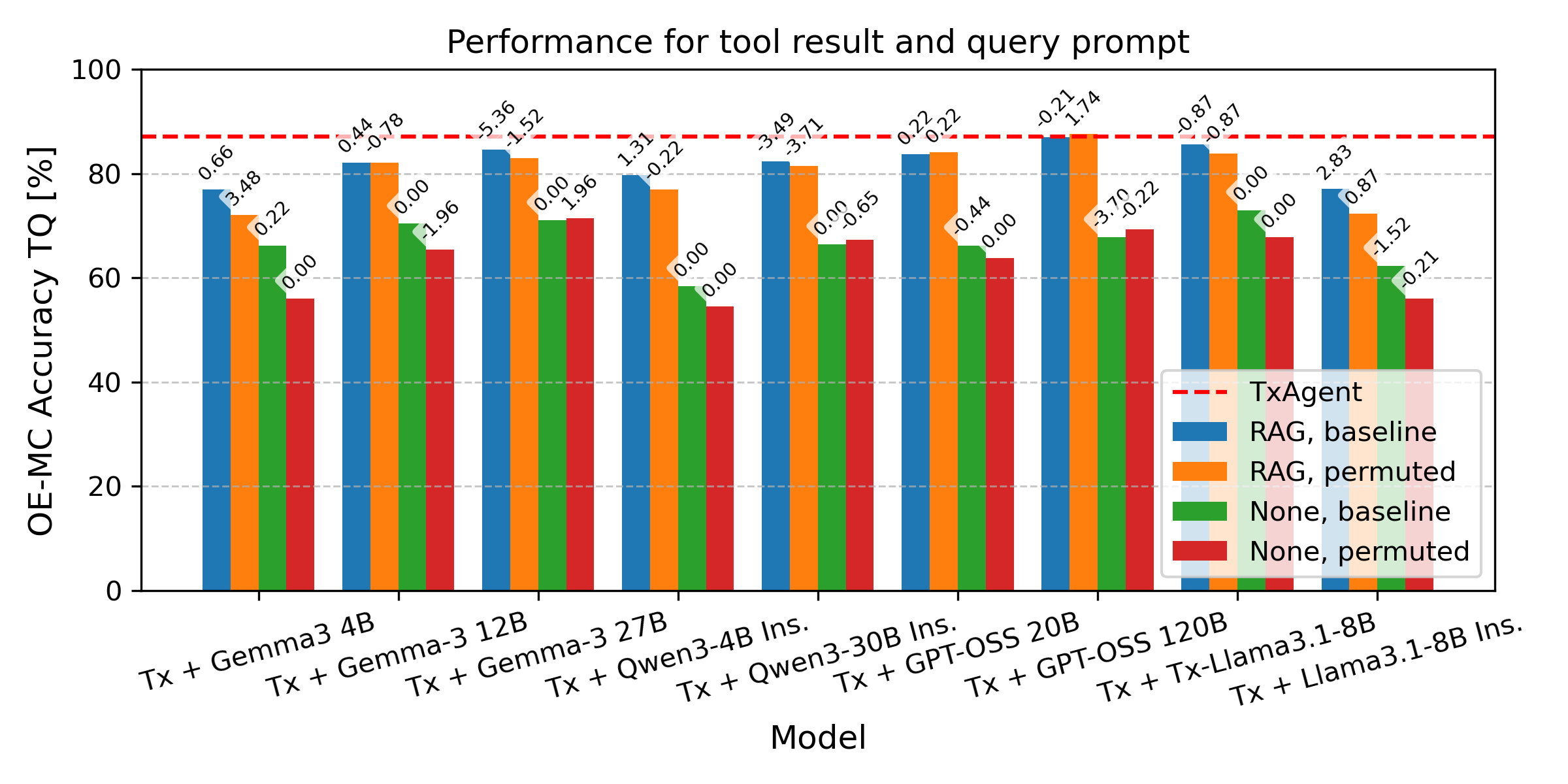
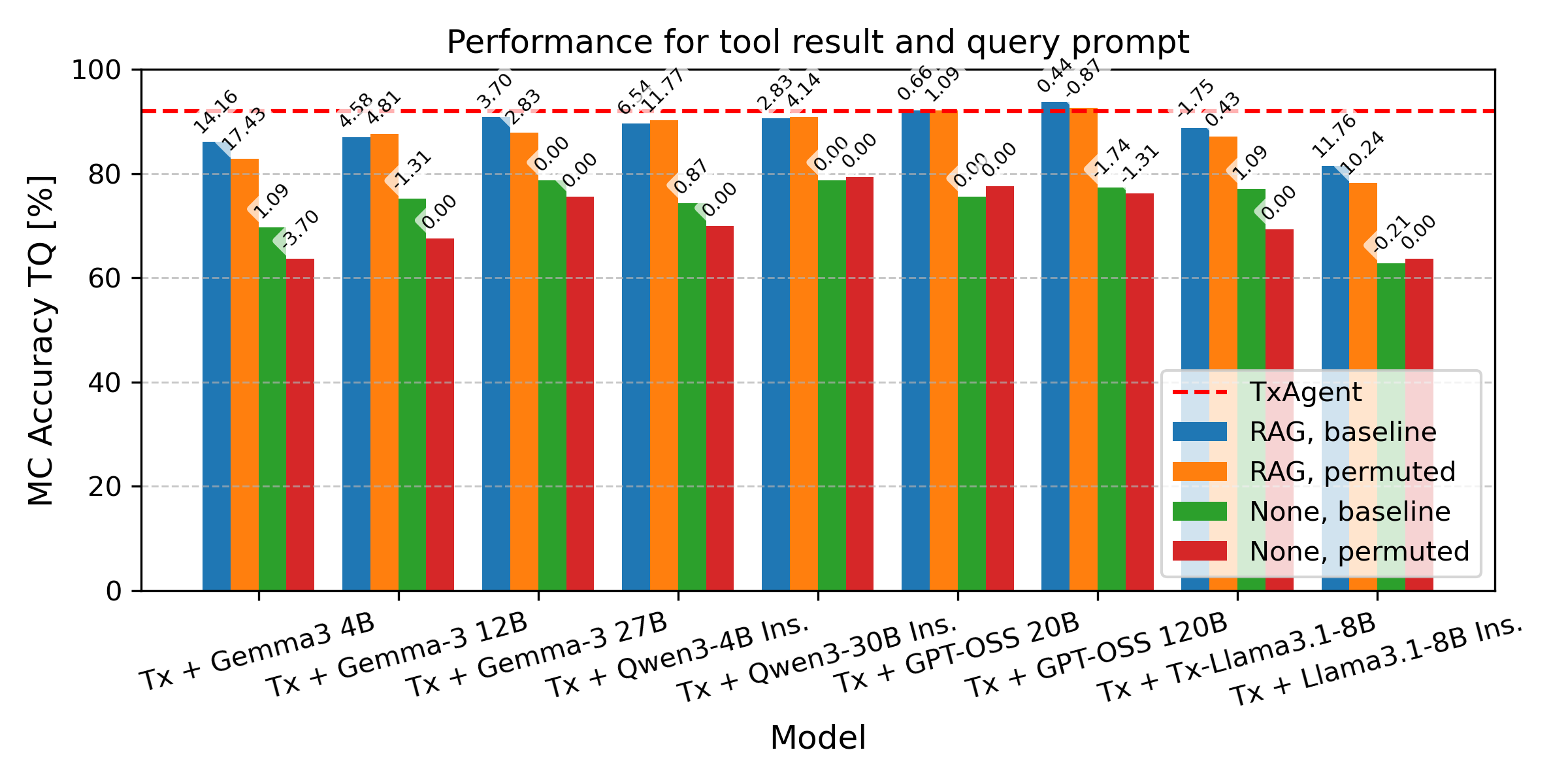
- Context helps models, even smaller ones: Providing the right retrieved information improved accuracy across different AI models. Smaller models (like Gemma3-4B and Qwen3-4B) performed well when they had good, relevant context, suggesting cost-effective systems are possible.
- Fine-tuning matters: The fine-tuned version of TxAgent’s LLM used the retrieved context more effectively than the same model without fine-tuning.
- Safety and reasoning trace are crucial: Medical AI isn’t just about getting the final answer right. The path to that answer—tools used, data retrieved, and the chain of reasoning—must also be correct and trustworthy.
Implications and Impact
This work shows how to build safer, smarter medical AI systems:
- By teaching AI to carefully choose and use the right medical tools, we can reduce errors and improve trust in its recommendations.
- Adding complete, authoritative sources like DailyMed helps the AI give more reliable answers using the latest information.
- Even smaller, cheaper models can perform well if they’re given good, targeted information—opening the door to more affordable medical AI.
- Evaluating not just the final answer, but also the steps taken and tools used, is essential for medical safety.
Limitations: Using big, detailed sources like DailyMed can increase the amount of text the AI must process, which may require more computing power. Future work could balance detailed information with efficiency, and further improve how the AI selects and formats tool calls.
Overall, the paper points toward medical AI that is more transparent, accurate, and safe—an important step toward tools that can genuinely help doctors and patients in real-world care.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, uncertainties, and omissions that future work could address to strengthen the paper’s claims and the TxAgent framework.
- Clinical validation is absent: no evaluation with real patient cases, EHR data, or prospective clinician-in-the-loop studies to assess safety, harm prevention, and clinical utility.
- Safety and reasoning metrics underreported: the paper references CURE-Bench’s tool-usage and reasoning-validity metrics with expert review but reports mainly accuracy; there is no quantitative analysis of tool-call correctness, stepwise reasoning fidelity, or safety guardrail effectiveness.
- Open-ended (OE) tasks are not evaluated: results are presented for MC and OE-MC only, leaving OE performance, generative quality, and factual precision unassessed.
- Error taxonomy is missing: recurring issues (wrong tool selection, misformatted parameters, failed calls) are mentioned but not systematically categorized, quantified, or linked to root causes and fix rates.
- Parameter schema handling is weak: no mechanism for schema-aware decoding, function signature enforcement, or automatic validation/correction of tool call parameters; retries and recovery strategies are not evaluated.
- Tool description design is unexplored: ToolUniverse descriptions are short (one–two sentences); the effect of description length, specificity, and structured metadata on top-k selection accuracy is not ablated.
- Fixed top-k=10 retrieval is unexamined: no study of adaptive k, confidence-based selection, multi-stage reranking, or supervised tool classification versus cosine similarity for tool choice.
- DailyMed integration trade-offs are not quantified: token usage, context window pressure, latency, throughput, and compute cost (with/without SPL summarization) are not measured; no ablation by question type or tool-usage frequency.
- Knowledge conflict resolution is unaddressed: the system can pull from openFDA, DailyMed, OpenTargets, and Monarch, but there is no strategy to detect, reconcile, or prioritize conflicting information.
- Robustness to API failures and versioning is untested: outages, rate limits, schema changes, and data updates are not simulated; no fallbacks, caching, or degradation behaviors are specified or measured.
- Prompt sensitivity and stability are unclear: the agentic prompt reportedly harmed other LLMs, yet TxAgent’s own sensitivity to prompt structure, instruction variants, and tool-call trace formatting is not studied.
- Reproducibility gaps: “sample run” contexts are reused without reporting seeds, variance, or run-to-run stability; no statistical significance tests, confidence intervals, or error bars accompany accuracy claims.
- Retriever comparison lacks detail: exact retrievers tested, embedding models, hyperparameters, latency distributions, and retrieval quality metrics (e.g., recall@k, MRR) are not reported; runtime variability is noted but not quantified.
- Fine-tuning specifics are opaque: training data, objectives, and release status for the Qwen2-1.5B tool retriever and Llama-3.1-8B fine-tuning are not provided; no ablations disentangle gains from fine-tuning versus retrieval changes.
- Termination policy and planning are not optimized: the agent decides when to stop, but there is no formalized stopping criterion, budget-aware planning, or analysis of ToolRAG cycle count versus accuracy/cost.
- Coverage and gap analysis of ToolUniverse is missing: which therapeutic tasks, drug classes, patient subgroups, or guideline domains are underrepresented (or overrepresented) is unknown.
- Fairness and subgroup performance are unexamined: no analysis across patient populations (e.g., pregnancy, pediatrics, comorbidities), disease areas, or question subtypes beyond MC vs OE-MC.
- Cost–performance trade-offs are not measured: smaller models (e.g., Gemma3-4B, Qwen3-4B) perform well with retrieval, but there is no systematic accounting of inference cost, memory footprint, or throughput versus accuracy.
- OE-MC intermediate reasoning quality is unchecked: the open-ended answer used to select MC options is not evaluated for factuality or faithfulness; only final option accuracy is measured.
- Tool-call failure handling is underdeveloped: there is no evaluation of automatic retries, error parsing, or guided recovery (e.g., schema correction, alternative tool fallback) when calls fail.
- SPL content ingestion lacks summarization strategies: there is no investigation of section-level prioritization, selective retrieval, or automatic summarization to control context size while preserving clinical salience.
- Generalization scope is limited: results are restricted to the competition validation set; no cross-dataset or cross-institution tests, multilingual settings, or domain transfer (e.g., diagnostics, procedures) are reported.
- Human evaluation of clinical reasoning is missing: beyond automated accuracy, there is no expert audit of reasoning traces for clinical correctness, guideline concordance, or potential harms.
- Ambiguities in model naming and baselines: “GPT-OSS” and the roster of compared LLMs are insufficiently specified (versions, parameter counts, checkpoints), hindering comparability and reproducibility.
- Open-science artifacts are unclear: code, trained weights, datasets for fine-tuning, and experiment scripts are not enumerated or linked; it is unclear what is required to replicate the full pipeline end-to-end.
Practical Applications
Immediate Applications
The following items can be deployed today using the paper’s demonstrated methods (agentic tool-calling with ToolUniverse, improved tool retrieval, and DailyMed integration) and evaluation practices (token-level reasoning and tool-usage audits).
- EHR-integrated clinical decision support for medication safety (Healthcare): Use TxAgent-style ToolRAG to automatically fetch current SPL content from DailyMed and FDA/OpenFDA to answer context-specific queries (e.g., pregnancy/lactation contraindications, renal/hepatic dosing, drug-drug interactions) with auditable reasoning traces; workflows include order-entry checks and discharge medication review. Assumptions/dependencies: Reliable API access to DailyMed/FDA, local validation with formulary rules, clinician-in-the-loop oversight, governance and logging for auditability.
- Pharmacy “medication review copilot” at dispense (Healthcare): Support pharmacists in pre-dispense safety checks (e.g., adverse effects, duplications, contraindicated combinations), provide succinct label summaries, and document tool-call and token-level traces for quality assurance. Assumptions/dependencies: Integration with pharmacy information systems, alert fatigue mitigation, monitored deployment with feedback loops.
- Point-of-care drug label summarizer (Healthcare): Deliver concise, human-readable SPL sections (e.g., boxed warnings, dosage and administration, use in specific populations) on demand, leveraging DailyMed’s structured narrative and the improved tool-selection pipeline. Assumptions/dependencies: Up-to-date SPL indexing, context-window management, guardrails for summarization fidelity.
- Telemedicine and rural clinic medication triage (Healthcare): Deploy small LLMs (e.g., Gemma3-4B, Qwen3-4B) in RAG mode to answer medication safety queries with fixed retrieval, reducing compute costs while maintaining traceable outputs. Assumptions/dependencies: Stable connectivity to medical APIs, caching strategies for low-bandwidth environments, clear escalation pathways to clinicians.
- Procurement and safety evaluation of clinical AI using CURE-Bench-like metrics (Policy/Healthcare): Adopt the challenge’s evaluation protocol to vet vendor systems on answer correctness, tool use, and reasoning quality; require function-call logs and token-level traces in RFPs. Assumptions/dependencies: Organizational policy updates, availability of test sets and human review capacity, alignment with regulatory guidance.
- ToolRAG SDK for biomedical connectors (Software/Healthcare IT): Package the paper’s retrieval and tool-selection approach (including DailyMed integration and function description curation) as a developer kit to add/maintain connectors to FDA, OpenTargets, Monarch, and internal medical knowledge bases. Assumptions/dependencies: API reliability, versioning/tagging of tool descriptions, ongoing curation of tool semantics.
- Audit and compliance pipeline for agentic medical reasoning (Healthcare/Policy/Software): Log function invocations, parameters, and token-level reasoning steps to support safety audits, post-hoc review, and incident analysis. Assumptions/dependencies: Secure logging, PHI handling and HIPAA/GDPR compliance, role-based access controls, retention policies.
- Medical education and training aids (Education/Healthcare): Use the agentic workflow and reasoning trace to teach students/residents how to ground recommendations in authoritative sources and to understand tool orchestration and failure modes (e.g., parameter formatting errors, wrong tool selection). Assumptions/dependencies: Instructor oversight, curated cases, clarity about model limitations.
- Patient-facing medication information assistant (Daily life/Healthcare): Offer consumer-friendly, label-grounded answers to common questions (e.g., OTC interactions, pregnancy risks), with automatic retrieval from DailyMed and clear disclaimers plus escalation to clinical care when needed. Assumptions/dependencies: Robust disclaimers, safety triage rules, content moderation, accessibility and literacy considerations.
- Label change monitoring and formulary impact alerts (Healthcare/Policy): Continuously surface SPL updates from DailyMed to Pharmacy & Therapeutics committees and clinical content teams; summarize changes and link to impacted policies or order sets. Assumptions/dependencies: Change-detection workflows, governance for policy updates, notification channels.
Long-Term Applications
These items require further research, scaling, cross-system integration, regulatory alignment, or expanded datasets/tools before widespread deployment.
- Autonomous therapeutic planning agent integrated with EHR (Healthcare/Software): Move from point queries to multi-step care planning (e.g., selecting regimens across comorbidities, monitoring labs, adapting to new findings) with verifiable tool orchestration and safety guardrails. Assumptions/dependencies: Deep EHR integration (orders, labs, allergies), rigorous clinical validation, fail-safe overrides, certification.
- Pharmacovigilance augmentation with agentic workflows (Healthcare/Policy/Pharma): Combine label-grounded reasoning with real-world data to predict adverse events, detect safety signals, and prepare regulatory reports, using auditable tool-call traces. Assumptions/dependencies: Access to high-quality clinical/claims data, causality models, cross-institution data sharing and privacy protections.
- Personalized medication optimization (Healthcare/Precision medicine): Integrate patient-specific features (genomics, phenotypes via Monarch/OpenTargets) to tailor dosing/choices and predict risks; incorporate dynamic updates from biomedical knowledge graphs. Assumptions/dependencies: Data harmonization, robust phenotype-genotype interpretation tools, clinical trial evidence thresholds.
- Safety certification standards for agentic medical AI (Policy/Regulatory): Institutionalize token-level reasoning and tool-usage metrics as part of certification/approval workflows; define minimum benchmarks for tool accuracy, trace completeness, and error recovery. Assumptions/dependencies: Multi-stakeholder consensus, regulator capacity, standardized test suites and audit criteria.
- Enterprise “ToolUniverse” marketplaces for healthcare (Healthcare IT/Software): Curate, version, and govern plug-and-play biomedical tools with semantic descriptions that enable safe autodiscovery/selection by agents. Assumptions/dependencies: Vendor interoperability, security reviews, provenance and version control, robust monitoring.
- Cross-domain agentic decision support (Energy/Finance/Robotics/Software): Generalize the tool-calling RAG paradigm to specialized domains (grid operations, risk management, automated QA for robotics) with domain-specific tool registries and audit trails. Assumptions/dependencies: High-quality domain APIs and simulators, sector safety frameworks, adaptation of evaluation metrics beyond healthcare.
- Low-resource and edge deployments for global health (Healthcare/Public health): Cache SPL and essential tools locally; run small models with fixed-retrieval pipelines for offline decision support in clinics with intermittent connectivity. Assumptions/dependencies: Local data stores, update synchronization protocols, battery/compute constraints, clinician training.
- Large-scale training datasets with tool-call supervision (Academia/Software): Build open datasets of therapeutic questions with gold tool-call traces and token-level reasoning to refine retrievers and reduce failure modes (wrong tool, bad parameters). Assumptions/dependencies: Annotation standards, funding for labeling, ethical data sharing, community governance.
- Clinical trial matching with treatment safety overlays (Healthcare/Research): Retrieve inclusion/exclusion criteria and reconcile them with patient medications/conditions via agentic reasoning to automate trial eligibility checks. Assumptions/dependencies: Structured trial registries, accurate patient data integration, legal/ethical safeguards.
- Proactive regulatory dashboards for label and AI-use monitoring (Policy/Regulatory): Provide regulators with live views of SPL changes, downstream clinical content impacts, and AI system behavior (tool-call patterns, failure rates) to inform guidance updates. Assumptions/dependencies: Data-sharing agreements, standardized reporting pipelines, capacity for expert review.
Glossary
- Adaptive retrieval: Retrieval strategy that adjusts which documents or tools to query based on evolving task context or model feedback. "Additional performance improvements have been achieved through RAG-solutions by including additional components to guide or judge the retrieval process through additional retrieval rounds, self-reflection, or adaptive retrieval."
- Adverse-effect prediction: Estimating or identifying potential negative side effects of treatments or drugs. "Tasks such as drug recommendation, treatment planning, and adverse-effect prediction demand robust, multi-step reasoning grounded in reliable biomedical knowledge."
- Agentic AI: AI systems that autonomously plan, select, and execute actions (e.g., tool calls) to achieve goals via iterative reasoning. "Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG)."
- Agentic Tool-Augmented Reasoning: A benchmarking track evaluating AI agents’ reasoning with explicit tool use and supervision signals. "The Agentic Tool-Augmented Reasoning track of the CURE-Bench NeurIPS 2025 Challenge establishes a rigorous framework for evaluating these capabilities."
- BM25: A classical sparse retrieval algorithm that scores documents based on term frequency and inverse document frequency. "The sparse retriever BM25 struggles to retrieve the correct function names due to its reliance on exact word matches and the limited context of function descriptions."
- Biomedical toolchains: Integrated sequences of tools and resources used to access and process biomedical data for reasoning tasks. "Recent advances in agentic AI and retrieval-augmented generation (RAG) have introduced new opportunities for building systems that can navigate complex biomedical toolchains."
- Comorbid conditions: Co-occurring medical conditions that can complicate diagnosis and treatment decisions. "Clinicians routinely integrate heterogeneous information on patient characteristics, disease pathophysiology, comorbid conditions and the pharmacological properties of candidate treatments."
- Context window: The maximum amount of textual information an LLM can consider at once. "Consequently, it may retrieve information that would otherwise require several ToolUniverse function calls, potentially leading to larger context windows and increased computational overhead."
- Cosine similarity: A measure of similarity between two vectors, often used to match queries with function descriptions. "Qwen2-1.5B compares the rewritten question to ToolUniverse function descriptions and returns the top- tool names based on cosine similarity."
- DailyMed: A database providing authoritative, up-to-date drug labeling information from the U.S. National Library of Medicine. "We enhanced TxAgent's pharmacological data capabilities by integrating the DailyMed database into the ToolUniverse framework."
- Dense retriever: A neural retrieval model that encodes queries and documents into dense vectors for semantic matching. "Dense retrievers perform similarly, albeit with higher runtime variability."
- Encoder–decoder pipeline: An architecture where an encoder processes input into representations and a decoder generates outputs, here fine-tuned for tool selection. "TxAgent uses a finetuned encoderâdecoder pipeline in which Llama3.1-8B rewrites the question, while Qwen2-1.5B compares the rewritten question to ToolUniverse function descriptions and returns the top- tool names based on cosine similarity."
- FDA Drug API: Programmatic access point to FDA drug data, enabling queries for regulated drug information. "TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse), integrating FDA Drug API, OpenTargets, and Monarch resources to ensure access to current therapeutic information."
- Hallucinations: Fabricated or incorrect outputs generated by LLMs absent grounding in reliable sources. "SotA LLM's factual errors are reduced by enhancing the LLM prompt with additional query-based retrieved information, reducing hallucinations through including up-to-date information."
- Llama-3.1-8B: A specific LLM variant used and fine-tuned within TxAgent for therapeutic reasoning. "TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse)."
- Monarch ontologies: Structured vocabularies and relationships from the Monarch Initiative used for integrating biomedical knowledge. "a unified suite of biomedical resources integrating FDA drug data, OpenTargets associations, and Monarch ontologies."
- OpenTargets: A resource linking genes, diseases, and therapies to support target identification and validation. "a unified suite of biomedical resources integrating FDA drug data, OpenTargets associations, and Monarch ontologies."
- openFDA: FDA’s open data platform offering granular drug query endpoints for programmatic access. "While TxAgent's existing openFDA tools facilitate granular queries and metadata retrieval, they often do so at the expense of contextual depth."
- Parametric knowledge: Information stored within an LLM’s parameters, as opposed to externally retrieved content. "Rather than relying solely on parametric knowledge, agentic approaches iteratively retrieve, evaluate, and integrate external information sources through orchestrated tool use."
- Pathophysiology: The functional changes associated with disease processes that inform clinical decision-making. "Clinicians routinely integrate heterogeneous information on patient characteristics, disease pathophysiology, comorbid conditions and the pharmacological properties of candidate treatments."
- Pharmacological agents: Drugs or compounds used therapeutically that interact with biological systems. "Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions among patient characteristics, disease processes, and pharmacological agents."
- Qwen2-1.5B: A compact LLM variant fine-tuned to act as a retriever selecting tools based on semantic similarity. "Qwen2-1.5B returns the most promising function calls back to Llama3.1-8B for tool selection."
- Reasoning trace: The sequence of intermediate steps and justifications an AI system produces during problem-solving. "medical contexts impose stringent constraints on verifiability and errors in either the reasoning trace or the sequence of tool calls can propagate to clinically significant mistakes."
- Retrieval-augmented generation (RAG): A method where models augment generation with information retrieved from external sources. "Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG)."
- Reranking: Reordering retrieved candidates based on additional signals or feedback to improve relevance. "However, the total number of tokens to rerank remains negligible, since each function is described by only up to two sentences."
- Self-reflection: A process where a model critiques or revises its own outputs to improve retrieval or reasoning. "Additional performance improvements have been achieved through RAG-solutions by including additional components to guide or judge the retrieval process through additional retrieval rounds, self-reflection, or adaptive retrieval."
- Sparse retriever: A retrieval approach relying on exact or lexical matches between query terms and document terms. "sparse retrievers excel in capturing lexical tasks while dense retrievers excel in semantic tasks."
- Structured Product Labeling (SPL): Standardized FDA format for drug labels containing authoritative clinical information. "the DailyMed tool integration grants TxAgent direct access to authoritative Structured Product Labeling (SPL), ensuring the retrieval of complete, version-controlled clinical narratives."
- Therapeutic decision-making: The clinical process of selecting appropriate treatments based on patient and disease factors. "Therapeutic decision-making in clinical medicine presents a demanding environment for artificial intelligence."
- Token-level reasoning: Evaluation or supervision that considers individual generated tokens to assess reasoning quality. "These considerations motivate evaluation protocols treating token-level reasoning and tool-usage behaviors as explicit supervision signals."
- Tool-calling: The practice of invoking external functions or APIs from within an AI workflow to obtain information or perform computations. "In this section, we describe the context of tool-calling for context enhancement, and clarify how this process differs from retrieval-augmented generation."
- ToolRAG: TxAgent’s mechanism for selecting relevant tools by matching rewritten queries to tool descriptions. "In TxAgent, this process is called: ToolRAG."
- ToolUniverse: A unified suite of biomedical tools and data sources integrated for agentic reasoning. "ToolUniverse, a unified suite of biomedical resources integrating FDA drug data, OpenTargets associations, and Monarch ontologies."
- Top-k retrieval: Selecting the k most relevant items (e.g., tools) based on a scoring function. "returns the top- tool names based on cosine similarity."
- Verifiability: The requirement that outputs and intermediate steps can be checked against reliable sources. "medical contexts impose stringent constraints on verifiability and errors in either the reasoning trace or the sequence of tool calls can propagate to clinically significant mistakes."
- Version-controlled clinical narratives: Drug label texts managed with explicit versions to ensure traceable, authoritative updates. "ensuring the retrieval of complete, version-controlled clinical narratives."
Collections
Sign up for free to add this paper to one or more collections.