Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
Abstract: Claude Code is an agentic coding tool that can run shell commands, edit files, and call external services on behalf of the user. This study describes its comprehensive architecture by analyzing the publicly available TypeScript source code and further comparing it with OpenClaw, an independent open-source AI agent system that answers many of the same design questions from a different deployment context. Our analysis identifies five human values, philosophies, and needs that motivate the architecture (human decision authority, safety and security, reliable execution, capability amplification, and contextual adaptability) and traces them through thirteen design principles to specific implementation choices. The core of the system is a simple while-loop that calls the model, runs tools, and repeats. Most of the code, however, lives in the systems around this loop: a permission system with seven modes and an ML-based classifier, a five-layer compaction pipeline for context management, four extensibility mechanisms (MCP, plugins, skills, and hooks), a subagent delegation mechanism with worktree isolation, and append-oriented session storage. A comparison with OpenClaw, a multi-channel personal assistant gateway, shows that the same recurring design questions produce different architectural answers when the deployment context changes: from per-action safety classification to perimeter-level access control, from a single CLI loop to an embedded runtime within a gateway control plane, and from context-window extensions to gateway-wide capability registration. We finally identify six open design directions for future agent systems, grounded in recent empirical, architectural, and policy literature.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper takes a “peek under the hood” of Claude Code, an AI helper that can write and fix code by itself. Instead of just guessing what Claude Code does from the outside, the authors read its publicly available TypeScript code to explain how it actually works. They also compare it to another open-source system called OpenClaw to show how different design choices appear when the product is used in a different way.
In short: the paper explains how a modern coding agent is built, why it’s built that way, and what this means for future AI helpers.
What questions the paper tries to answer
The authors focus on simple-but-important questions every AI coding helper must face:
- How much freedom should the AI have, and how do humans stay in control?
- How can the system stay safe and avoid doing harmful things?
- How does the agent keep track of what’s going on when there’s only so much it can “remember” at once?
- How can people plug in their own tools and customize the agent?
- How can the agent split work into parts and ask “mini-helpers” (subagents) to assist?
- What changes when the same ideas are used in different products, like a gateway assistant (OpenClaw) instead of a coding tool?
How the researchers studied it
Instead of running big experiments, the authors used three simple approaches:
- Code reading: They analyzed the publicly available Claude Code source (TypeScript) to map design choices—what parts exist, how they connect, and why.
- Design principles: They identified five human values that seem to shape the system (like safety and user control) and traced those values into 13 design principles that show up in the code.
- Comparison: They compared Claude Code to OpenClaw, an open-source agent system, to see how the same questions can lead to different designs depending on where and how the agent is used.
They also walk through a concrete example—“Fix the failing test in auth.test.ts”—to show how the system behaves step by step.
The main ideas and why they matter
The heart of the system is a simple loop
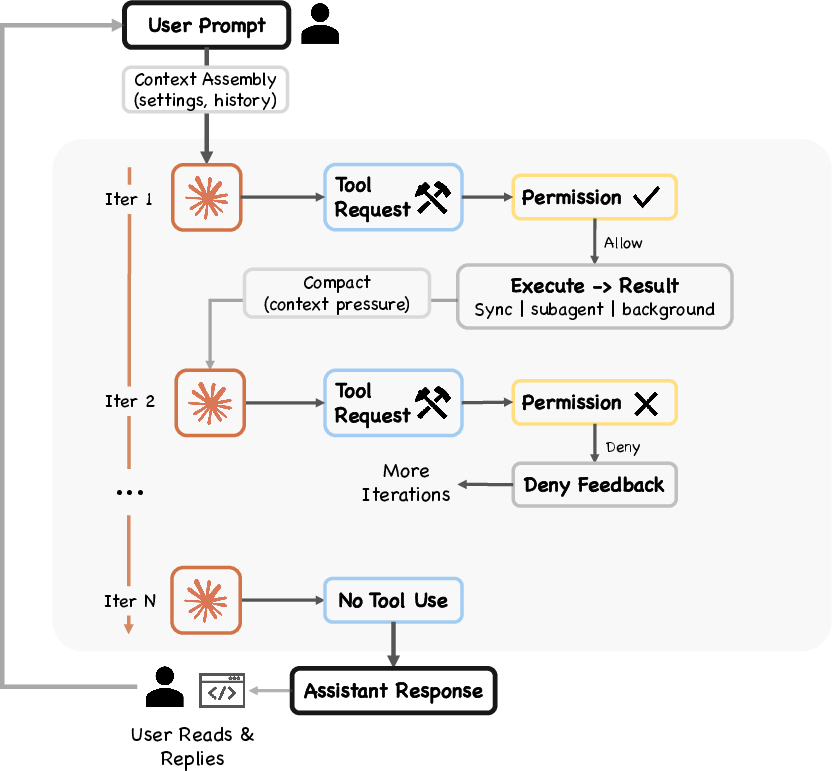
Claude Code runs a basic repeat cycle (a “while loop”): think → try a tool → look at results → repeat until done. This is like a student who plans a step, does it, checks the result, and keeps going.
Why it matters: Simple loops are reliable and easy to debug. Most of the “smarts” come from the model’s reasoning and the strong support systems wrapped around this loop.
Five human values guide the design
The system’s architecture reflects five core values:
- Human decision authority: People stay in charge. Claude asks for permission for sensitive actions and shows what it’s doing.
- Safety and security: Multiple layers of protection stop bad or risky actions.
- Reliable execution: The agent tries to do what you meant and checks its work.
- Capability amplification: It helps you do more than you could alone.
- Contextual adaptability: It adapts to your project, tools, and preferences.
These values are turned into 13 hands-on design principles (for example, “deny first, ask later” for permissions, and “treat attention/memory space as scarce and manage it carefully”).
Safety works like layered security at an airport
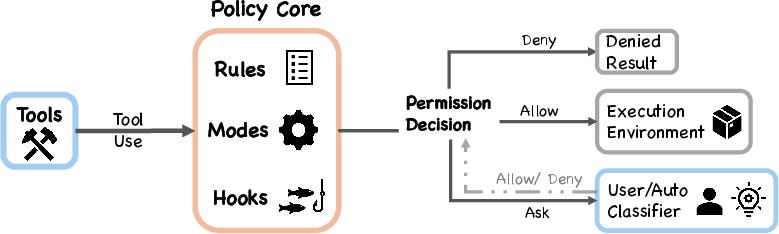
Permissions are “deny first, escalate to human.” There are several independent safety layers—rules, a machine-learning safety classifier, optional shell sandboxing, and hooks that can intercept actions. If any layer says “no,” the action is blocked.
Why it matters: Defense-in-depth reduces the chance of a single failure causing trouble. It also builds trust: users can see and control what the agent is allowed to do.
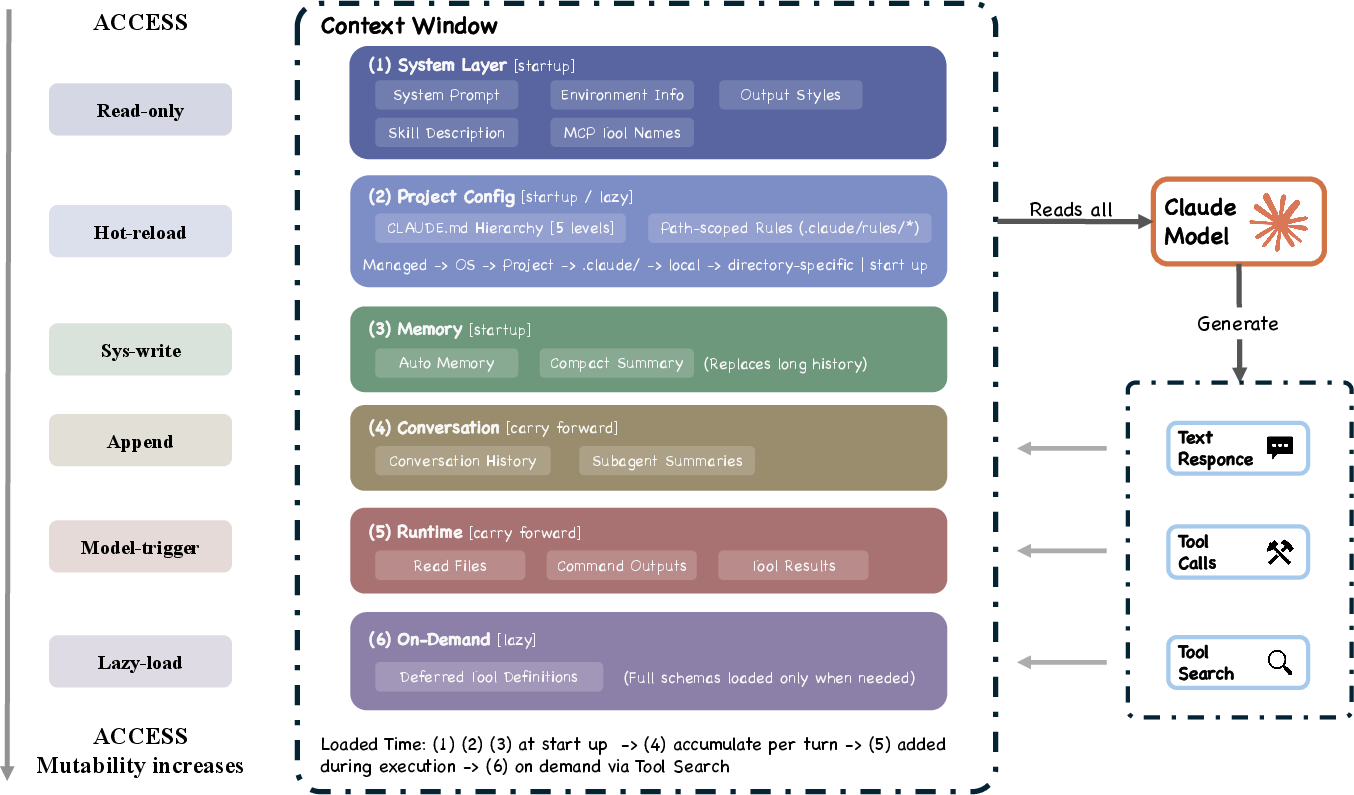
“Context window” is treated like a backpack with limited space
AI models can only “see” a limited amount of information at once (their context window). Claude Code uses a five-step “compaction” pipeline to fit more useful info into that space:
- Trim oversized tool outputs
- Snip old details over time
- Micro-compact to handle overhead
- Collapse very long histories into summaries
- Auto-compact as a last resort using semantic compression
It also avoids loading unnecessary instructions until needed and limits how much subagent chatter flows back to the main chat.
Why it matters: Good memory management keeps the agent focused and accurate over long tasks.
Extensibility: many ways to plug things in
The system isn’t locked down. You can extend it through MCP (a protocol for tools), plugins, skills, and lifecycle hooks. These options sit at different “context costs”—some are lightweight, others more powerful but heavier.
Why it matters: People and teams can tune the agent to their tools and workflows without breaking the core system.
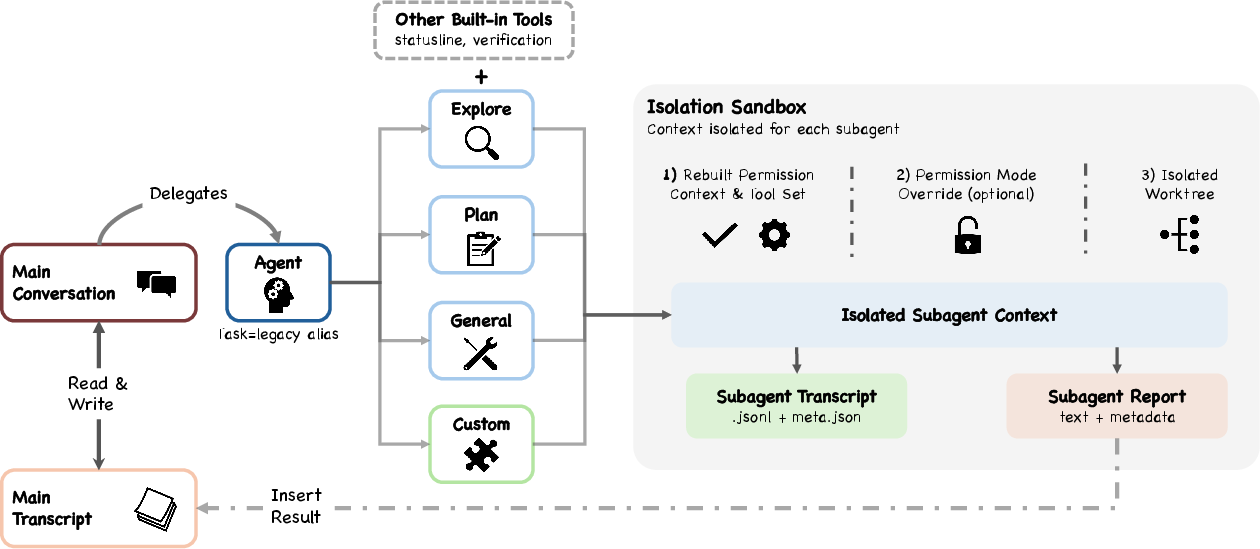
Subagents: small helpers with boundaries
The main agent can spawn subagents (like specialized helpers) that work in isolation and then return a short summary, not their full conversation.
Why it matters: This prevents memory overload and keeps responsibilities clear, while still letting the agent divide and conquer tasks.
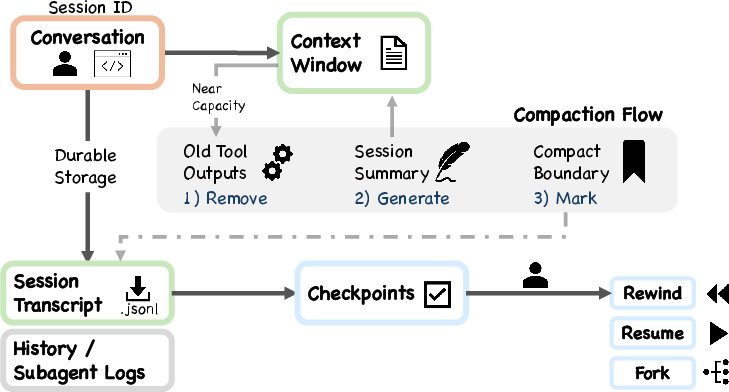
Append-only logs: a diary you don’t edit
The agent keeps append-only session files (like a running diary). It records what happened, which helps with resuming work, auditing actions, and understanding past decisions.
Why it matters: Durable, transparent history supports reliability and accountability.
Same questions, different answers: Claude Code vs. OpenClaw
When the deployment context changes, design choices change too. The paper shows that:
- Safety: Claude Code often checks each action; OpenClaw leans toward gateway-level access control (like a perimeter fence).
- Runtime: Claude Code centers on a single CLI loop; OpenClaw embeds the agent inside a gateway that connects many channels.
- Capabilities: Claude Code carefully packs context; OpenClaw emphasizes registering capabilities across the whole gateway.
Why it matters: There’s no one “right” architecture—what’s best depends on where the agent lives and what it’s for.
Open questions for the future
The authors call out six areas for future work, such as:
- Better ways to see and evaluate what agents are doing (observability).
- Smarter memory and learning across sessions.
- Clearer boundaries between the model’s reasoning and the system’s execution.
- Handling longer, more complex tasks over time (horizon scaling).
- Governance and policy tools for responsible use.
- Measuring whether agents help or hurt long-term human skill growth.
They also note a concern: if people rely too much on AI, their own skills might fade. Claude Code boosts short-term productivity, but it has fewer features aimed at preserving long-term human understanding.
Why this is important
- For users: It explains how modern coding agents keep you in control, stay safe, and still speed you up.
- For builders: It offers a map of design choices and trade-offs—how to handle permissions, memory limits, extensions, and subagents.
- For researchers and policy makers: It highlights the values behind the tech and where future improvement is needed—especially for safety, trust, and human skill development.
Simple takeaway
Claude Code is like a careful, helpful apprentice: it works in small steps, asks permission for risky things, keeps a tidy log of what it did, and adapts to your tools. The paper shows how this is achieved in code and why those choices matter—and it points the way toward even safer, smarter, and more human-centered AI agents in the future.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper offers a detailed, source-level architectural analysis of Claude Code and a qualitative contrast to OpenClaw. However, multiple areas remain underexplored or empirically unvalidated. Future research could address the following gaps:
- Empirical safety evaluation: Quantify false-positive/false-negative rates of the auto-mode classifier and the deny-first permission system across benign, ambiguous, and adversarial scenarios; release an open evaluation harness and red-teaming datasets for reproducibility.
- Layered-safety interactions: Analyze how the seven safety layers compose in practice (ordering, redundancy, masking effects, and failure modes), including conflicts between hooks, permission rules, sandboxing, and classifier outcomes.
- Sandboxing efficacy and bypasses: Systematically test shell sandbox constraints against realistic attack vectors (path traversal, symlink races, env var poisoning, subprocess escapes, toolchain exploits), and measure residual risk on different OSes.
- Hook and extensibility attack surface: Map and test the security boundary of hooks, skills, plugins, and MCP servers (supply-chain risks, privilege escalation, cross-plugin interference), and propose least-privilege capability schemas and isolation patterns.
- MCP trust and interop: Establish trust models and permission negotiation protocols for MCP servers (origin attestation, capability scoping, revocation), and evaluate interoperation with heterogeneous agent ecosystems beyond MCP.
- Permission UX and habituation: Measure the cognitive load and habituation dynamics of permission prompts under different modes; test UI/UX designs that improve calibration without increasing friction (e.g., risk-tiered prompts, reversible-by-default flows).
- Trust trajectory management: Develop quantitative models of trust evolution (calibration, over-trust, under-trust) and interventions that keep trust aligned with true risk as autonomy increases over long-term use.
- Long-term human capability preservation: Design and evaluate mechanisms that explicitly sustain developer understanding and supervision skills (e.g., self-explanation checkpoints, “teach-back” prompts, codebase health nudges, evaluative separation of generation vs review).
- Observability–evaluation gap: Define standardized telemetry and evaluation signals (tool success semantics, side effects, invariants, postconditions) to bridge streaming-level observability with task-level quality and safety metrics.
- Context compaction trade-offs: Quantify the impact of each compaction layer (budget reduction, snip, microcompact, collapse, auto-compact) on accuracy, latency, and hallucinations; develop adaptive, learned policies for when and how to compact.
- Memory and persistence limits: Evaluate the append-only JSONL approach at scale (storage growth, retrieval latency, PII exposure, tamper-evidence), and test cross-session memory strategies (promotion, decay, summarization quality) for codebase coherence.
- Permission state across resume/fork: Study the safety/usability trade-offs of not restoring session-scoped permissions on resume; propose principled restoration policies (with provenance, expiry, and risk-tiering) and measure user impact.
- Subagent orchestration and isolation: Measure how summary-only returns affect parent reasoning, debuggability, and failure propagation; explore scheduling, coordination patterns, and verification of subagent outputs under isolation constraints.
- Determining the right harness boundary: Identify task regimes where minimal scaffolding underperforms explicit planners/graphs/tree-search; develop adaptive harness selection that toggles between reactive loops and structured orchestration.
- Performance and cost envelopes: Provide quantitative benchmarks for latency, throughput, token spend, and tool concurrency under realistic workloads; investigate dynamic budgeting policies (early-exit heuristics, multi-model routing, effort control).
- Capability coverage and tool idempotence: Audit built-in and MCP tools for coverage gaps, side effects, idempotence, and transactional semantics; introduce safeguards (dry-run modes, two-phase commits, invariants) for stateful operations.
- Comparative, controlled evaluation vs OpenClaw: Move beyond qualitative contrast to controlled experiments that isolate deployment-context variables and quantify trade-offs (safety, autonomy, context efficiency, extensibility overhead).
- Horizon scaling and checkpointing: Develop mechanisms for very long-horizon tasks (explicit goals/subgoals, milestones, verifiers, resumable checkpoints) and evaluate their effects on reliability and cost.
- Governance and policy lifecycle: Specify machine-enforceable, versioned policy artifacts (provenance, diffing, rollback), and test policy update workflows (staging, canarying) under regulatory constraints and audit requirements.
- Privacy and compliance: Assess data-minimization, encryption-at-rest/in-transit, retention, and access control for transcripts, histories, and sidechains; provide compliance-ready configurations and audit logging guarantees.
- Model updates and compatibility: Investigate schema evolution and backward compatibility for tools, hooks, and MCP interfaces under model changes (context sizes, tool-use formats, thinking settings); propose robust migration strategies.
- Generalizability and completeness of evidence: Validate that the analyzed source snapshot reflects production behavior (feature parity, configuration drift); document coverage gaps and divergences, and provide a protocol for continuous re-analysis as the codebase evolves.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s identified design choices (deny‑first safety posture, layered permissioning with an ML auto‑mode classifier, a five‑layer context compaction pipeline, MCP/plugins/skills/hooks extensibility, isolated subagent orchestration, and append‑only session storage).
- Software development (enterprise): Secure agentic coding assistant in IDEs and CLI
- What: Use the unified query loop, deny‑first permission system, shell sandboxing, and append‑only JSONL logs to let agents run tests, edit files, and refactor code with auditable trails.
- Tools/workflows: IDE plugin + CLI harness; permission modes with human escalation; PreToolUse hooks for policy; session viewers for audit.
- Assumptions/dependencies: Capable LLM with tool‑use; OS‑level sandboxing; policy configuration; developer buy‑in to review/approve prompts.
- CI triage and repair bot (software/DevOps)
- What: Headless CLI/SDK agent triggered by CI to reproduce failing tests, collect logs, propose patches, and open PRs within a deny‑first, reversible‑action‑first policy.
- Tools/workflows: Streaming tool executor for faster multi‑tool runs; per‑tool output budgets; subagent “workers” scoped to individual tests with sidechain transcripts.
- Assumptions/dependencies: CI integration; protected branches; pre‑configured permission modes and auto‑mode classifier thresholds.
- DevOps task runner with reversibility‑weighted oversight (software/IT)
- What: Automate routine shell operations (log collection, config reads) with light oversight while requiring explicit approval for state‑changing commands (deployments, migrations).
- Tools/workflows: Shell tool + sandbox; permission rules that distinguish read‑only vs write actions; hooks that auto‑deny high‑risk scopes.
- Assumptions/dependencies: Accurate action classification; well‑tuned policy rules; secure secrets handling outside the model.
- Internal tool orchestration via MCP (software/productivity)
- What: Connect to JIRA/GitHub/Slack or in‑house systems using MCP; let the agent coordinate issues, comments, and code reviews under layered policy enforcement.
- Tools/workflows: MCP servers for services; tool pre‑filters; deferred tool schemas to control context; coordinator hooks for batch approvals.
- Assumptions/dependencies: MCP server availability; service tokens/SSO; agreed access scopes per environment.
- Prompt‑injection‑resistant browsing and fetches (security/software)
- What: Use tool pre‑filtering, deny‑first evaluation, and hooks to sanitize and constrain web fetches and content ingestion.
- Tools/workflows: Fetch/Browser tools with strict allow lists; PreToolUse hooks stripping dangerous parameters; auto‑mode classifier for suspicious requests.
- Assumptions/dependencies: Up‑to‑date allow/deny policies; robust URL/domain scoping; monitoring for model drift.
- Transparent project memory and configuration (education/software)
- What: Manage agent instructions with CLAUDE.md hierarchy and directory‑specific files so students/teams can see and version control “what the agent knows.”
- Tools/workflows: File‑based memory; lazy loading of nested instructions; course/project templates that include baseline CLAUDE.md.
- Assumptions/dependencies: Team discipline to keep CLAUDE.md reviewed; VCS integration; model reliability with long instructions.
- Reproducible HCI/SE studies of agent behavior (academia)
- What: Use append‑only transcripts, sidechain subagent logs, and compaction summaries to reproduce and analyze agent sessions in experiments.
- Tools/workflows: Session storage viewers; metrics on auto‑approve trajectories; replay harnesses using stored JSONL.
- Assumptions/dependencies: Consent and privacy controls; storage management for logs; stable schema versions.
- Safety policy “as code” pilots (policy/IT governance)
- What: Externalize permissions and hooks so security teams can version and test policy changes without forking the agent codebase.
- Tools/workflows: Rule sets in config; staging vs production modes; automated tests that simulate dangerous tool requests.
- Assumptions/dependencies: Clear risk taxonomy; cross‑functional review; CI for policy bundles.
- Local “auto‑mode within bounds” for individual developers (daily life/software)
- What: Enable a graduated trust spectrum that auto‑approves clearly reversible actions (search, read, test) while prompting for edits or shell writes.
- Tools/workflows: Auto‑mode ML classifier; reversible‑action rules; quick UI prompts; per‑session non‑restored elevated permissions.
- Assumptions/dependencies: Reasonable classifier precision; user comprehension of modes; safe defaults after resume.
- Plugin/skill marketplaces for agent extension (software ecosystem)
- What: Distribute MCP servers and low‑context‑cost “skills” to add tools (e.g., database readers, documentation miners) without bloating prompts.
- Tools/workflows: Skills registry; ToolSearch with deferred schemas; hooks for onboarding checks.
- Assumptions/dependencies: Extension vetting; signature/identity of providers; dependency isolation.
Long-Term Applications
These applications require further research, scaling, standardization, or ecosystem maturity (e.g., more accurate classifiers, broader MCP adoption, improved observability, and refined governance).
- Autonomous CI/CD with evaluators in the loop (software/DevOps)
- What: Agent plans, tests, and deploys changes end‑to‑end, with evaluators and deny‑first gates at promotion points; rollback and audit are append‑only.
- Dependencies: Strong evaluator‑optimizer patterns; higher‑fidelity sandboxes; formalized risk tiers; org‑wide IAM and policy-as-code.
- Large‑scale multi‑agent refactoring (software)
- What: Orchestrator spawns isolated subagents (per module/service) with sidechain logs and summary‑only returns to refactor sprawling codebases.
- Dependencies: Horizon scaling and cross‑session coherence; conflict resolution across subagents; advanced context collapse and summarization quality.
- Organization‑wide, cross‑session memory and governance (software/IT)
- What: Persistent, curated memory across projects with retention policies, provenance, and human checkpoints to preserve codebase coherence over months.
- Dependencies: New UX for memory management; robust RAG over audited stores; policies for retention/PII; evaluation against “capability preservation” metrics.
- Sector‑regulated agent operations (healthcare, finance, gov)
- What: Apply deny‑first, layered safety and append‑only audits to clinical admin, claims processing, or trading support bots that integrate via MCP.
- Dependencies: Certification frameworks; domain policy packs; higher bar for sandboxing/segmentation; incident response playbooks.
- Agentic IDEs with native policy and observability (software tools)
- What: IDEs embed permission modes, hooks, compaction visualizers, and action diffs to make agent decisions legible and governable by teams.
- Dependencies: Standards for permission APIs; interoperability with language servers; scalable UI for high‑volume telemetry.
- Standardization and compliance for agent safety (policy/standards)
- What: Regulatory or industry standards mandate deny‑first defaults, separation of reasoning/enforcement, and durable audit trails for agentic systems.
- Dependencies: Consensus on baseline controls; conformance test suites; alignment with privacy and cybersecurity frameworks.
- Autonomous IT operations with perimeter controls (IT/operations)
- What: Agents handle patching, backups, and incident triage under perimeter‑level access control rather than per‑action prompts, with escalation paths.
- Dependencies: Robust boundary enforcement; high‑precision action classification; integration with SIEM/SOAR; human‑override UX.
- Robotics and physical process control with layered safeguards (robotics/industry)
- What: Port the deny‑first, multi‑layer safety stack and isolated subagents to physical task planning and execution (e.g., warehouse or maintenance bots).
- Dependencies: Verified low‑level controllers; strict sandbox equivalents (simulation/digital twins); real‑time override; liability frameworks.
- Classroom and workforce upskilling against “capability atrophy” (education/policy)
- What: Curricula and tools that surface agent reasoning, require human evaluation, and track comprehension to mitigate long‑term skill erosion.
- Dependencies: Instrumentation that couples agent output with assessment; longitudinal studies; incentives for deliberate practice.
- Cross‑channel personal assistant gateways (consumer productivity)
- What: Gateway architectures (cf. OpenClaw contrast) that embed the loop within a control plane, register capabilities globally, and enforce perimeter‑level access for email, calendars, and files.
- Dependencies: Unified capability registry; identity and consent flows; device and app adapters; privacy‑preserving data handling.
- Live observability and evaluation tooling for agents (software/ML ops)
- What: Tools to visualize compaction, permission decisions, and subagent orchestration; attach evaluators that score safety and quality in real time.
- Dependencies: Streaming telemetry standards; privacy/redaction; robust evaluator models; organizational processes to act on signals.
Glossary
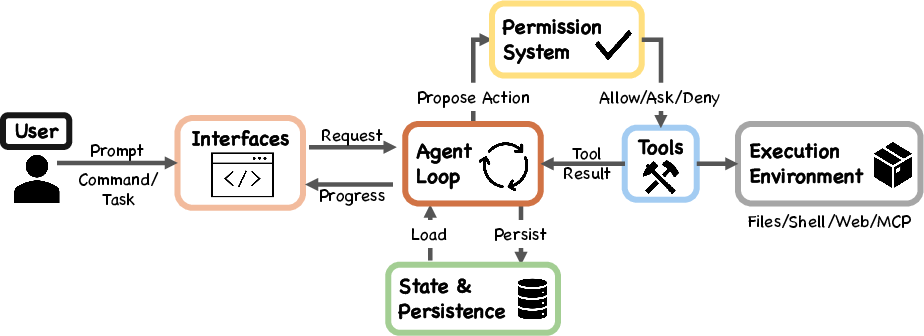
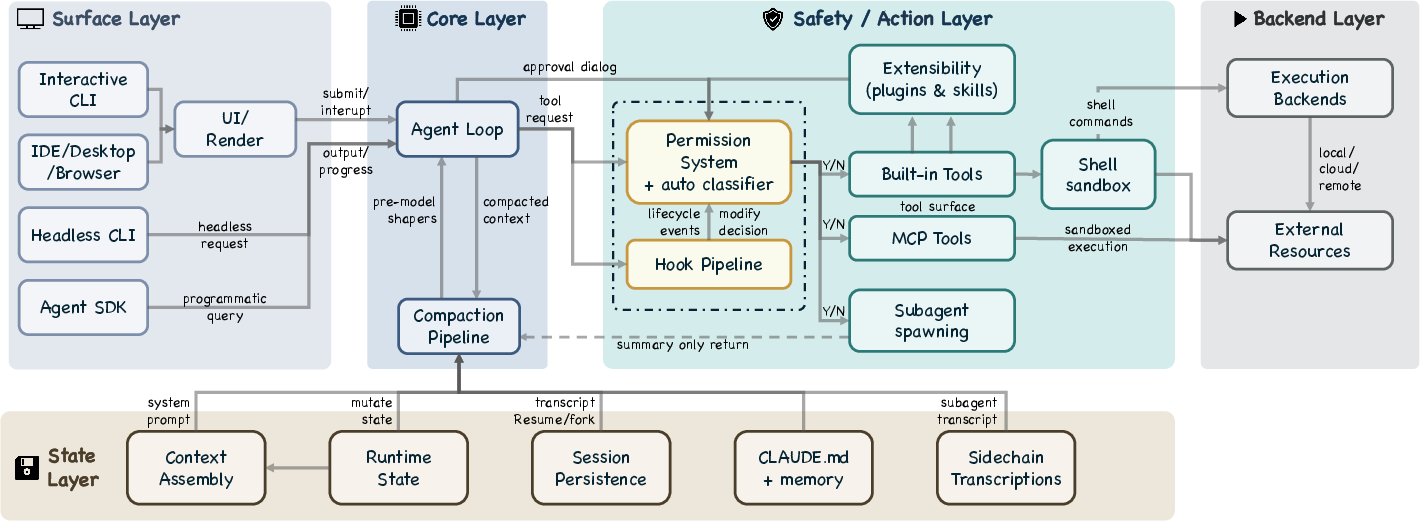
- agent loop: The iterative control cycle that assembles context, calls the model, routes tool requests through safety checks, executes approved tools, and repeats. "All entry surfaces converge on the same agent loop."
- agentic coding tool: A coding assistant that autonomously plans and executes actions (e.g., running commands, editing files) to achieve user goals. "Claude Code is an agentic coding tool that can run shell commands, edit files, and call external services on behalf of the user."
- Agent SDK: A programmatic interface for integrating and controlling the agent from external applications or services. "The Agent SDK emits typed events via async generators."
- append-oriented session storage: A persistence model that records session history by appending entries rather than mutating past state, aiding auditability and recovery. "append-oriented session storage"
- auto-mode ML classifier: A machine-learning component that evaluates the safety of tool-use requests when automatic approvals are enabled. "auto-mode ML classifier"
- budget reduction: A compaction strategy that caps or trims oversized tool outputs before model calls to manage context pressure. "Budget reduction targets individual tool outputs that overflow size limits."
- CLAUDE.md: A user-visible, file-based configuration and memory system that provides hierarchical, version-controllable instructions for the agent. "The CLAUDE.md + memory subsystem provides a four-level instruction hierarchy"
- compaction pipeline: A multi-stage sequence of context-reduction techniques applied before each model call to fit within the context window. "a five-layer compaction pipeline for context management"
- context collapse: A compaction technique that summarizes long histories into shorter representations to preserve essential information. "Context collapse manages very long histories."
- context window: The maximum token budget the model can attend to in a single call, treated as the binding resource constraint. "the context window (200K for older models, 1M for the Claude 4.6 series)"
- defense in depth: A safety posture that uses multiple independent, overlapping mechanisms so any single layer can block unsafe actions. "defense in depth with layered mechanisms"
- deny-first rule evaluation: A permission policy in which deny rules override ask and allow rules, with unrecognized actions escalated to humans. "Deny-first rule evaluation (#1{permissions.ts})"
- externalized programmable policy: Safety and permission logic expressed via external configuration and lifecycle hooks rather than being hardcoded, enabling flexible governance. "externalized programmable policy"
- gateway control plane: The centralized management layer of a gateway system into which an agent runtime can be embedded. "embedded runtime within a gateway control plane"
- graduated trust spectrum: A permission model that offers multiple levels of autonomy and oversight, allowing users to move along a continuum of trust. "Graduated trust spectrum"
- hook-based interception: A mechanism where lifecycle hooks can observe, modify, or block actions (e.g., tool invocations) before they execute. "Hook-based interception (#1{types/hooks.ts})"
- isolated subagent boundaries: Architectural boundaries ensuring subagents run with separate context and permissions, limiting blast radius and context bloat. "isolated subagent boundaries"
- MCP: A protocol-based extensibility mechanism that exposes tools and services to the agent via server connections. "MCP server connections"
- microcompact: A compaction stage that reduces overhead (e.g., cache-related) by aggressively tightening message content before a model call. "Microcompact reacts to cache overhead."
- minimal scaffolding with maximal operational harness: A design principle favoring a simple control loop and strong execution infrastructure over complex orchestration logic. "minimal scaffolding with maximal operational harness"
- orchestrator-workers pattern: An agent workflow where a central orchestrator delegates tasks to worker subagents and aggregates results. "primarily uses the orchestrator-workers pattern for subagent delegation"
- perimeter-level access control: A security approach that enforces access policies at the system boundary rather than via per-action approvals. "perimeter-level access control"
- principal hierarchy: An authority structure that specifies who has ultimate control, ordered from organization to operators to end users. "principal hierarchy (Anthropic, then operators, then users)"
- ReAct pattern: An interaction pattern where the model alternates between reasoning steps and tool-using actions, with results feeding back into subsequent reasoning. "Claude Code's reactive loop follows the ReAct pattern"
- shell sandboxing: Executing shell commands in a restricted environment that limits filesystem and network access independent of permissions. "Shell sandboxing (#1{shouldUseSandbox.ts})"
- sidechain transcripts: Separate, append-only logs for subagents’ conversations that keep their content out of the parent agent’s context. "Sidechain transcripts (#1{sessionStorage.ts:247})"
- sibling abort controller: A coordination mechanism that cancels concurrent tool executions when one fails, preventing wasteful or unsafe continuation. "Sibling abort controller."
- StreamingToolExecutor: A streaming execution component that begins running tools as soon as tool-use blocks arrive, reducing latency. "The primary path uses #1{StreamingToolExecutor}, which begins executing tools as they stream in from the model response"
- subagent delegation: The practice of spawning child agents to handle subtasks, often returning summaries to conserve context. "a subagent delegation and orchestration mechanism"
- tool_use blocks: Structured messages emitted by the model to request specific tool invocations, which the harness validates and executes. "tool_use blocks"
Collections
Sign up for free to add this paper to one or more collections.