Hallo-Live: Real-Time Streaming Joint Audio-Video Avatar Generation with Asynchronous Dual-Stream and Human-Centric Preference Distillation
Abstract: Real-time text-driven joint audio-video avatar generation requires jointly synthesizing portrait video and speech with high fidelity and precise synchronization, yet existing audio-visual diffusion models remain too slow for interactive use and often degrade noticeably after aggressive acceleration. We present Hallo-Live, a streaming framework for joint audio-visual avatar generation that combines asynchronous dual-stream diffusion with human-centric preference-guided distillation. To reduce articulation lag in causal generation, we introduce Future-Expanding Attention, which allows each video block to access synchronous audio together with a short horizon of future phonetic cues. To mitigate the quality loss of few-step distillation, we further propose Human-Centric Preference-Guided DMD (HP-DMD), which reweights training samples using rewards from visual fidelity, speech naturalness, and audio-visual synchronization. On two NVIDIA H200 GPUs, Hallo-Live runs at 20.38 FPS with 0.94 seconds latency, yielding 16.0x higher throughput and 99.3x lower latency than the teacher model Ovi. Despite this speedup, it retains strong generation quality, reaching comparable VideoAlign overall score and Sync Confidence score while outperforming other accelerated baselines in the overall quality-efficiency trade-off. Qualitative results further show robust generalization across photorealistic, multi-speaker, and stylized scenarios. To the best of our knowledge, Hallo-Live is the first framework to combine streaming dual-stream diffusion with preference-guided distillation for real-time, text-driven audio-visual generation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Hallo-Live, a system that can create a talking avatar in real time from text. The avatar isn’t just moving its lips—it speaks and shows a video of a face that matches the speech, with the lips and expressions timed correctly. The big challenge is to do this fast enough for live use (like a video call or streaming) while keeping the video and audio high quality and well synchronized.
What questions were the researchers trying to answer?
The authors focused on two main questions:
- How can we make a talking avatar generate video and speech together in real time, without the lips lagging behind the audio?
- How can we speed up the model a lot without losing visual quality, natural-sounding speech, or tight lip-sync?
How did they do it?
They combined two ideas to make the system both fast and good-looking.
Making lips move on time: “Future-Expanding Attention”
Imagine you’re reading a script out loud—your mouth starts forming sounds just before you say them. To capture that, the model’s video part gets to “peek” a tiny bit into the upcoming audio. Think of it like a singer in a band who listens half a beat ahead to stay perfectly in time.
- In normal “causal” systems, the video can only use past and current audio, which can make lips look late.
- Hallo-Live lets the video glance at a short slice of the near-future audio (just a small window), enough to anticipate mouth shapes while still working in a live, streaming way.
- This “Future-Expanding Attention” keeps the system fast but improves lip-sync, because the video has the slight preview it needs.
Keeping quality while speeding up: “Human-Centric Preference-Guided Distillation”
Training big models to run fast can make them blurrier or less natural. To avoid that, the authors use a “teacher–student” setup:
- The “teacher” is a strong but slow model. The “student” learns to imitate it but with far fewer steps, so it’s much faster.
- Instead of treating every example equally, the student pays more attention to high-quality examples. The paper uses “rewards” that measure:
- Visual fidelity (how good the video looks),
- Speech naturalness (how pleasant and clear the audio is),
- Audio–video synchronization (how well lips match the words).
- The student is trained to prefer outputs that score well on these human-centric measures. That way, speeding up doesn’t ruin the look or sound.
In simpler terms: the student learns from the teacher, but weights its learning toward examples people would prefer—sharp video, natural speech, and perfect lip-sync.
What did they find?
Here are the key results the authors report:
- Real-time performance: On two NVIDIA H200 GPUs, Hallo-Live runs at about 20 frames per second (FPS) with under 1 second of delay (0.94s latency). That’s fast enough for live interactions.
- Big speedup: Compared to the teacher model (called Ovi), Hallo-Live is about 16 times faster and starts nearly 100 times sooner (much lower latency).
- Quality preserved: Even with the speed boost, Hallo-Live keeps strong visual quality and good lip-sync. It scores close to the teacher on overall video quality and synchronization, and better than other fast baselines.
- Versatility: It works across different styles—photorealistic faces, multiple speakers, and even cartoon-like characters.
Why is this impressive? Usually, when you make models faster, you lose detail or timing. This system keeps a solid balance between speed and quality.
Why does it matter?
Hallo-Live is a step toward truly interactive talking avatars you can use in real time—for tutoring, customer support, games, livestreams, or creative tools. Because it’s fast and keeps lips synced with speech, conversations feel more natural and less robotic. The approach (peeking slightly into future audio and training with human-centered rewards) could help other live generative systems too.
Looking ahead, the authors mention improving longer conversations, adding more body and camera control, and making it work on cheaper hardware. If those goals are met, high-quality, real-time avatars could become widely available and useful in everyday apps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances real-time text-driven joint audio–video avatar generation, but several aspects remain missing, uncertain, or underexplored:
- Data realism and distribution shift: Training relies on synthetic audio–video generated by the Ovi teacher from a curated prompt pool, with prompts filtered by automated metrics (Sync Confidence, WER). It is unclear how the model performs on real human recordings, in-the-wild speech, and diverse camera/lighting conditions, or how synthetic-teacher bias affects generalization.
- Lack of human evaluations: All quality, synchronization, and speech naturalness assessments are automated; no subjective user studies (e.g., MOS for audio, pairwise visual preference, perceived lip-sync latency) are reported to validate perceptual quality and user acceptance.
- Reward circularity and overfitting: HP-DMD uses VideoAlign, AudioBox, and SyncNet both as training rewards and as evaluation metrics, risking reward overfitting and metric gaming. There is no cross-metric validation (e.g., alternative lip-sync metrics, human raters, or unseen reward models) to verify true generalization.
- Reward model robustness and bias: The reliability of VideoAlign/AudioBox/SyncNet across languages, accents, demographics, stylizations (e.g., cartoons), and camera/body compositions is not characterized, nor are their failure modes and calibration (e.g., correlation with human judgments).
- Reward weighting stability: The paper shows sensitivity to the reward coefficient β in single-reward settings but does not explore multi-reward weighting strategies (e.g., β-vectors, adaptive or curriculum schedules), variance reduction, or stabilization techniques to prevent reward hacking and mode collapse in HP-DMD.
- Long-horizon streaming stability: The approach’s behavior over extended conversations (minutes to hours) is not evaluated—uncertainties include temporal drift, compounding errors, identity drift, KV-cache growth and eviction strategies, and synchronization stability over long streams.
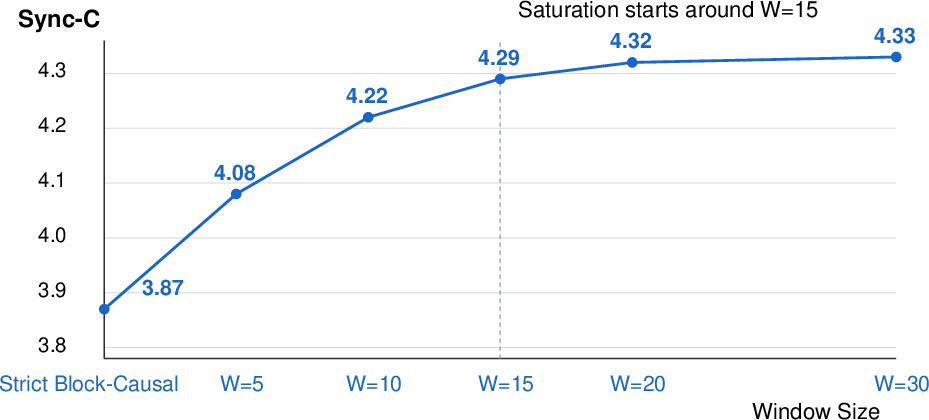
- Look-ahead vs. latency trade-offs: Future-Expanding Attention introduces a look-ahead that implies latency; though “one-block” latency is claimed, ablations vary W up to 30 without quantifying end-to-end latency, compute/memory costs, or perceptual trade-offs of larger windows under real-time constraints.
- Provisional audio mismatch: The method conditions video on a provisional future audio block that is later refreshed. The frequency and magnitude of mismatches between provisional and committed audio—and their perceptual impact (e.g., anticipatory lip motions that do not match finalized phonemes)—are not measured or mitigated.
- Synchronization granularity: Sync is reported with SyncNet confidence; explicit temporal offset/error distributions (e.g., milliseconds lead/lag) and phoneme-level alignment accuracy are not analyzed, making it hard to quantify perceived timing fidelity.
- Multispeaker handling: While qualitative multi-speaker examples are shown, there is no evaluation of turn-taking, speaker diarization, overlapping speech, or explicit speaker identity control (voice timbre, consistency across turns).
- Expressive prosody and emotion control: The system’s ability to realize nuanced prosody/emotion, lexical stress, and expressive timing from text, and their coupling with facial/body expressions, is not evaluated or controlled.
- Language and accent coverage: Performance across non-English languages, code-switching, accents, and cross-lingual TTS alignment is not reported; CLAP/WER may not capture multilingual intelligibility or accent robustness.
- Body and camera motion control: Although half-/full-body cases are shown, there is no quantitative evaluation of upper-body gesture naturalness, pose stability, camera movement control, or occlusion robustness.
- Edge and low-cost hardware deployment: Results are reported on two NVIDIA H200 GPUs; feasibility on single consumer GPUs, edge devices, or mobile (including memory footprint, quantization, and throughput/latency under constrained compute) is not characterized.
- Efficiency-compute trade-offs: The computational overhead of Future-Expanding Attention (e.g., extra denoising of future audio blocks), KV-cache memory scaling, and throughput under different window sizes and sequence lengths are not profiled.
- Teacher dependence and portability: The approach is initialized and validated with the Ovi teacher; it is unclear how well the method transfers to other architectures (e.g., MoE, single-stream, different codecs) or weaker/stronger teachers, and how teacher quality caps student performance.
- Generalization beyond talking-head: Robustness to non-portrait scenes, dynamic backgrounds, multi-person frames, complex interactions with objects, and strong head rotations or profile views is not systematically tested.
- Robustness to speech rate and coarticulation extremes: Performance under very fast speech, disfluencies, long pauses, or atypical coarticulation patterns is not evaluated; the future-context window that best handles such cases is unknown.
- Audio quality details: Beyond AudioBox and TTS metrics, stability of speaker identity, continuity (breaths, pauses), noise artifacts, and prosodic consistency across long sequences are not analyzed.
- Failure case analysis: The paper does not document typical failure modes (e.g., lip jitter, identity flicker, drift under long prompts, TTS mispronunciations) or conditions under which asynchronous conditioning breaks down.
- Dataset transparency and reproducibility: The prompt generation/selection pipeline (LLM rewrites, filtering criteria) may introduce selection bias; the absence of a standardized public benchmark for T2AV complicates reproducible comparison.
- Safety, ethics, and misuse: Risks related to deepfakes, voice cloning, unauthorized identity synthesis, and watermarking or provenance are not addressed; no safeguards or detection mechanisms are discussed.
- Control interfaces: The paper does not detail mechanisms for user control of voice timbre, emotion, speaking rate, gesture intensity, or camera composition, nor how text prompts map to such controls in a predictable manner.
- Theoretical grounding of HP-DMD: Formal guarantees or convergence properties of reward-tilted distribution matching in multi-modal, streaming settings are not provided; the bias–variance trade-off of batch-wise standardization and importance weights is not analyzed.
- Metric coverage gaps: VideoAlign lacks explicit measures for identity consistency over time, and the human-centric portrait metrics (Anat., Clo., Id.) may not fully capture temporal artifacts; broader and more sensitive metrics could reveal unobserved degradations.
- Handling partial or streaming text: The method assumes a known text prompt; real-time conversational inputs arrive incrementally. How the system adapts to partial/updated text while preserving synchronization and naturalness remains open.
- Integration with external TTS/ASR: The architecture’s compatibility with different TTS backbones, latency budgets when coupled with external ASR/NLP modules, and robustness to transcription errors are not explored.
- Licensing and data governance: The legal status and licensing of teacher-generated training data, and implications for downstream model use, are not discussed.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging Hallo-Live’s real-time, text-driven joint audio-video generation, Future-Expanding Attention for anticipatory lip motion, and human-centric preference-guided distillation (HP-DMD) for quality retention.
- Real-time customer support avatars
- Sectors: software, customer service, retail, telecom
- Tools/products/workflows:
- WebRTC-enabled “live agent” widget that takes LLM-generated text and renders synchronized A/V avatars at ~20 FPS
- Contact-center integrations (Genesys, Five9, Zendesk) with a gRPC/REST Hallo-Live microservice and KV-cache-based streaming
- OBS/NDI plugins for embedding avatars in live support streams
- Assumptions/dependencies: two high-end GPUs (e.g., H200s) for advertised latency; disclosure and consent policies; content moderation to prevent hallucinated or unsafe responses; QoS for low-latency networking; language/accent coverage consistent with training data
- Script-to-video presenters for marketing and internal comms
- Sectors: marketing, enterprise communications, media
- Tools/products/workflows:
- “Studio” tool to convert copy decks into presenter videos with adjustable styles (photorealistic to cartoon)
- Batch rendering pipeline using prompt templates; brand-safe avatar libraries
- Assumptions/dependencies: brand/identity governance policies; VisualAlign-optimized styles may need human QA; legal clearance for likeness use
- E-learning tutors and training avatars
- Sectors: education, corporate training, HR-tech
- Tools/products/workflows:
- LMS plugins (Moodle, Canvas) that render course scripts as synchronized talking-head videos
- Scenario-based training with multi-speaker interactions driven by prompt orchestration
- Assumptions/dependencies: curriculum-aligned scripts; inclusive voice/face options; accessibility compliance (captions, transcripts); GPU inference or managed service
- Media automation: anchors, explainers, and fillers
- Sectors: media, broadcast, creator economy
- Tools/products/workflows:
- News explainer auto-generation from structured briefs; “standby anchor” fill-ins for breaking news
- OBS integration for live-to-tape workflows; real-time preview for producers
- Assumptions/dependencies: editorial approval chains; watermarking/disclosure of synthetic content; topic safety review
- Localization and dubbing with matched lip motion
- Sectors: media localization, education, enterprise comms
- Tools/products/workflows:
- Script translation + style prompts -> Hallo-Live for target-language A/V with anticipatory lip cues
- QA tool that flags SyncNet and WER anomalies for manual fixes
- Assumptions/dependencies: target LLM coverage and TTS intelligibility; legal/ethical use of identities; throughput sizing for batch jobs
- Conversational kiosks and in-store assistants
- Sectors: retail, hospitality, banking, transport
- Tools/products/workflows:
- On-prem inference node serving a greeting/FAQ avatar; fallback to cloud for overflow
- Workflow: ASR/LLM for intent -> text prompt -> A/V avatar response with <1 s latency
- Assumptions/dependencies: hardware footprint on-site; privacy (no raw audio/video leaves premises if regulated); failover modes
- Developer SDK for real-time avatars
- Sectors: software, platforms, devtools
- Tools/products/workflows:
- SDK wrapping streaming dual-stream diffusion with KV caching; configurable look-ahead window W and reward weights
- Sample pipelines (Python/TypeScript) for quick integration into apps
- Assumptions/dependencies: driver and CUDA versions; GPU memory constraints; reward-model checkpoints (SyncNet, VideoAlign, AudioBox)
- Virtual instructors and campus services
- Sectors: higher education, ed-tech
- Tools/products/workflows:
- “Course concierge” avatar providing course info, office hours, safety guidelines
- Syllabus-to-video conversion with stylized avatars
- Assumptions/dependencies: institutional policies on synthetic media disclosure; bias/fairness audits for voices/appearances
- Accessible content generation
- Sectors: public sector, NGOs, daily life
- Tools/products/workflows:
- Text-to-avatar for people with speech impairments; scripted announcements for public information
- Companion feature that renders personal notes/emails as spoken videos
- Assumptions/dependencies: user consent and data protection; culturally appropriate styles/voices; device compatibility
- NPC dialog and live events in games
- Sectors: gaming, XR/VR
- Tools/products/workflows:
- Real-time narrative systems: LLM -> avatar A/V with lip-sync for dynamic NPCs
- In-game panels or commentators using multi-speaker mode
- Assumptions/dependencies: GPU budget on client/edge; content profanity filters; blendshape/rig integration if needed
- Telepresence avatars for meetings
- Sectors: enterprise software, collaboration
- Tools/products/workflows:
- “Camera-off” mode rendering a branded avatar from live chat input for privacy-conscious users
- Plug-ins for Zoom/Teams that stream Hallo-Live output as a virtual camera
- Assumptions/dependencies: policies on virtual identities; look-ahead latency (~1 block) acceptable in live conversation; caption synchronization
- Research baselines and evaluation
- Sectors: academia, R&D labs
- Tools/products/workflows:
- Public code/models as a baseline for streaming multimodal diffusion and preference-guided distillation
- Benchmark suites integrating SyncNet/VideoAlign/AudioBox for reproducible studies
- Assumptions/dependencies: license terms; compute availability; benchmark variance across datasets
Long-Term Applications
The following applications require further research, engineering, or scaling (e.g., better multilingual coverage, lower-cost hardware, extended control).
- Low-cost and on-device real-time avatars
- Sectors: mobile, embedded systems, consumer devices
- Tools/products/workflows:
- Quantized or distilled variants for laptops, edge boxes, and high-end phones
- Hybrid client-cloud streaming where KV-cache and select layers run locally
- Assumptions/dependencies: aggressive compression without losing sync; memory-efficient KV caching; thermal/power constraints
- Multilingual, accent-robust, and emotive avatars
- Sectors: global media, education, customer service
- Tools/products/workflows:
- Training with broader speech corpora for accents/prosody; controllable emotion sliders
- Preference models expanded beyond SyncNet/AudioBox to capture emotion and cultural norms
- Assumptions/dependencies: rights-cleared datasets; reward model generalization; subjective evaluation protocols
- Live cross-lingual translation with lip-aware dubbing
- Sectors: conferencing, live events, diplomacy
- Tools/products/workflows:
- ASR + MT + text prompts -> Hallo-Live for target-language A/V synchronized to speaker timing
- Adaptive look-ahead and alignment to preserve speaker cadence
- Assumptions/dependencies: accurate live ASR/MT; latency budgets; failure handling and disclosure
- Standards and governance for synthetic presenters
- Sectors: policy, compliance, platforms
- Tools/products/workflows:
- Watermarking and provenance (e.g., C2PA-like signals) embedded in audio/video streams
- Platform-level policies for disclosure, consent, and deepfake misuse safeguards
- Assumptions/dependencies: cross-industry agreement; robust watermarking that survives transcoding; enforceability
- Digital human front-ends for robotics and service agents
- Sectors: robotics, healthcare, hospitality
- Tools/products/workflows:
- Robotic UIs that use avatars to communicate instructions empathetically
- Co-design with motion systems (gaze, gesture) synchronized to speech
- Assumptions/dependencies: HRI safety; synchronization with physical actuators; reliability in noisy environments
- Rich controllability: camera, body, environment
- Sectors: film/TV, virtual production, XR
- Tools/products/workflows:
- Promptable camera moves, body poses, and scene transitions; timeline editors with token-level control
- Integration with 3D engines for hybrid 2D/3D productions
- Assumptions/dependencies: model extensions beyond head-and-shoulders; expanded reward models for cinematography
- Personalized and rights-managed avatar marketplaces
- Sectors: creator economy, advertising, entertainment
- Tools/products/workflows:
- Licensed likeness avatars (actors, influencers); contracts and revenue shares
- Tooling for safe personalization (voice clones, face styles) with consent gating
- Assumptions/dependencies: legal frameworks for likeness/IP; robust identity protection; misuse detection
- Healthcare and therapeutic companions
- Sectors: digital health, mental health
- Tools/products/workflows:
- CBT/psychoeducation delivered by consistent, empathetic avatars
- Clinical scripting with human oversight; session recordings with provenance
- Assumptions/dependencies: clinical validation; HIPAA/GDPR compliance; bias and safety evaluations
- Education at scale with adaptive tutors
- Sectors: ed-tech, public education
- Tools/products/workflows:
- Real-time, personalized lesson delivery with knowledge tracing and prompt adaptation
- Multi-speaker classroom simulations and roleplays
- Assumptions/dependencies: pedagogy-aligned reward functions; alignment with curricula; equity and access considerations
- Industry benchmarks and multimodal reward learning
- Sectors: academia, AI research, standards bodies
- Tools/products/workflows:
- New datasets and reward models that jointly optimize visual, acoustic, and alignment metrics
- Open protocols for evaluating lip-sync, prosody, identity preservation, and user preference
- Assumptions/dependencies: community adoption; reproducibility; minimizing reward hacking
- Privacy-preserving telepresence and identity shielding
- Sectors: enterprise, public sector, daily life
- Tools/products/workflows:
- “Avatarization” of live speech/text that hides the user’s face/voice with secure on-device rendering
- Policy controls for when and how avatars can replace real video in formal contexts
- Assumptions/dependencies: strong authentication; organizational policies; social acceptance
- Safety toolchains for synthetic A/V
- Sectors: platforms, regulators, trust & safety
- Tools/products/workflows:
- Detectors and monitors tuned to streaming avatars (real-time watermark verification, content filters)
- Incident response playbooks for misuse (impersonation, disinformation)
- Assumptions/dependencies: low false-positive detectors; shared threat intel; continuous model updates
Notes on key dependencies and feasibility constraints across applications
- Compute: Reported real-time performance (20.38 FPS, ~0.94 s latency) is measured on two NVIDIA H200 GPUs; scaling to commodity hardware will require further optimization.
- Latency design: Future-Expanding Attention introduces a short look-ahead; acceptable in many interactions but may need tuning for ultra-low-latency live use.
- Reward-model biases: HP-DMD depends on SyncNet, VideoAlign, and AudioBox; domain/language shifts may reduce reliability and can bias optimization if not recalibrated.
- Language and style coverage: Generalization to new languages, accents, and cultural styles depends on training data and may require fine-tuning.
- Legal/ethical: Likeness rights, disclosure/watermarking, data protection, and content moderation are prerequisites for production deployments.
- Networking and reliability: Interactive use requires stable, low-latency links and robust fallback modes; KV-cache management and streaming pipelines must be engineered for uptime and observability.
Glossary
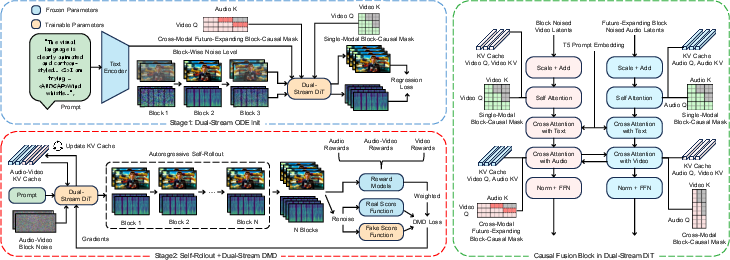
- Asynchronous Dual-Stream Diffusion: A streaming generation scheme where audio and video branches denoise with different temporal scopes, letting audio look ahead while video commits block-by-block. "We realize asynchronous dual-stream diffusion by advancing the video and audio branches with different temporal scopes at each streaming step."
- Audio-visual synchronization: The temporal alignment between generated speech and corresponding mouth/facial movements in video. "visual fidelity, speech naturalness, and audio-visual synchronization."
- AudioBox: A reward/evaluation model assessing perceptual quality of synthesized speech. "AudioBox \cite{tjandra2025meta}, which evaluates the perceptual quality of synthesized speech."
- Autoregressive self-rollout: Training/inference procedure where the model conditions on its own previously generated outputs to simulate streaming generation. "Stage II performs autoregressive self-rollout with an audio-video KV cache and optimizes the generated trajectory with reward-weighted dual-stream DMD."
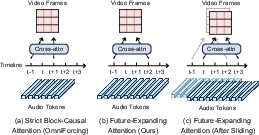
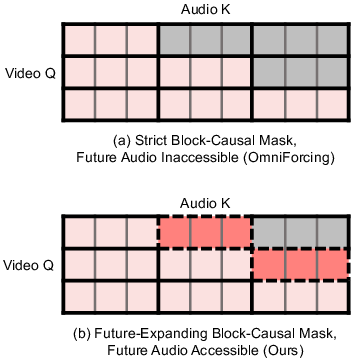
- Block-Causal Attention: An attention masking scheme that restricts each block to attend only to current and past blocks, enforcing causality in streaming. "a common baseline (shown in Figure~\ref{fig:attention}~(a)) is the strict block-causal attention."
- Causal fusion block: A dual-stream DiT block that fuses audio and video under causal masks via self-, cross-text, and cross-modal attention. "Each causal fusion block in the dual-stream DiT consists of single-modal block-causal self-attention, text cross-attention, and cross-modal attention between the video and audio streams"
- CLAP score: A metric derived from Contrastive Language-Audio Pretraining that measures text–audio alignment. "we additionally report CLAP score and word error rate (WER)"
- Cross-modal attention: Attention operations that let one modality (e.g., video) attend to representations from another (e.g., audio). "cross-modal attention between the video and audio streams"
- Distribution Matching Distillation (DMD): A distillation method that aligns the student’s generative distribution to a teacher’s manifold for fast sampling. "DMD~\cite{yin2024one} provides a robust framework for accelerating diffusion models by aligning the studentâs generative distribution with a pre-trained teacher's manifold."
- Fully Sharded Data Parallel (FSDP): A distributed training technique that shards model states across devices to scale large models efficiently. "Training is conducted on 16 GPUs with Fully Sharded Data Parallel (FSDP)"
- Future-Expanding Attention: An attention strategy that reveals a short horizon of future audio to video queries to enable anticipatory lip motion under causality. "we introduce Future-Expanding Attention, which allows each video block to attend to synchronous audio together with a short look-ahead region."
- Future-Expanding Block-Causal Mask: A cross-modal visibility mask that selectively exposes a limited look-ahead region of audio to video queries during training and streaming. "The Future-Expanding Block-Causal Mask with a look-ahead window measured in video frames is defined as"
- Human-Centric Preference-Guided DMD (HP-DMD): A reward-weighted distillation approach that biases learning toward samples with better visual fidelity, speech naturalness, and sync. "we propose human-centric preference-guided DMD (HP-DMD), which reduces the quality loss caused by aggressive acceleration."
- KV cache: Cached key–value tensors from past attention steps to enable efficient causal decoding in streaming transformers. "the model maintains a rolling audio-video KV cache over committed history to support efficient causal generation."
- Latent diffusion: Diffusion modeling performed in a compressed latent space for efficiency and quality. "Recent advances in latent diffusion and multimodal generation"
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert subnetworks to increase capacity. "MOVA~\cite{team2026mova} employs a Mixture-of-Experts (MoE) architecture"
- Modality-aware classifier-free guidance: A guidance technique that conditions and scales signals per modality to improve cross-modal alignment. "LTX-2~\cite{hacohen2026ltx} utilizes the modality-aware classifier-free guidance mechanism for improved audio-video alignment."
- ODE initialization: An initialization stage that aligns the student to the teacher’s denoising trajectory under an ODE-based schedule with causal masks. "the block-causal masks are utilized in Stage I ODE initialization"
- Rotary positional encoding: A positional embedding method that encodes relative position information via rotations in attention. "transformer-based diffusion architectures rooted in self-attention and rotary positional encoding"
- Self-forcing: A technique to convert bidirectional models to causal ones by training with their own generated context. "OmniForcing \cite{su2026omniforcing} utilizes Self-forcing technique \cite{huang2025self} to transform a bidirectional joint audio-video model into a causal model"
- Stitching of experts (SoE): A strategy that combines outputs/skills of multiple expert models across modalities. "UniVerse-1~\cite{wang2025universe} leverages a stitching of experts (SoE) approach"
- Stop-gradient: An operation that prevents gradients from flowing through part of the computation to stabilize objectives. "where denotes stop-gradient."
- SyncNet: A model/metric used to assess lip–audio alignment quality. "a SyncNet-based score \cite{chung2016out}, which measures lip-audio alignment."
- T5: A large text-to-text transformer backbone often used for prompt conditioning. "such as T5 \cite{2020t5}"
- Text-to-Audio-Video (T2AV): The task of generating synchronized audio and video from text prompts. "Quantitative evaluation on the Text-to-Audio-Video (T2AV) task."
- VideoAlign: A reward/evaluation model for video quality, motion quality, and text alignment over time. "VideoAlign \cite{liu2025improving}, which measures visual quality, motion quality, and text alignment."
- Word error rate (WER): A standard metric for speech intelligibility measuring transcription errors. "we additionally report CLAP score and word error rate (WER)"
Collections
Sign up for free to add this paper to one or more collections.