- The paper introduces a Self-Correcting Bidirectional Distillation strategy that resolves latency and motion coherence tradeoffs in audio-driven avatar synthesis.
- It leverages a 14B diffusion transformer with multi-step self-correction and aggressive inference optimizations, achieving a 23× reduction in training cost and 32 FPS performance.
- The method ensures robust error correction and multimodal conditioning, setting new benchmarks for real-time, infinite-duration digital human synthesis.
SoulX-LiveTalk: Bidirectional Streaming Distillation for Real-Time Audio-Driven Avatars
Introduction
SoulX-LiveTalk presents a 14B-parameter diffusion transformer (DiT) framework engineered for high-fidelity, real-time infinite streaming of audio-driven avatars. The system addresses longstanding conflicts in digital human synthesis: achieving low-latency interactive generation without compromising visual and motion coherence. Contrasting prevailing unidirectional approaches that sacrifice spatiotemporal attention or model capacity for speed, SoulX-LiveTalk leverages a Self-Correcting Bidirectional Distillation strategy, maintaining bidirectional attention intra-chunk and introducing robust mechanisms for error propagation control.

Figure 1: SoulX-LiveTalk delivers a ∼23× reduction in training cost, 3× lower start-up latency, and ∼1.6× higher frame rate than competing systems, supporting applications such as video telephony and live streaming.
Framework Architecture and Distillation Methodology
The SoulX-LiveTalk pipeline comprises two principal stages: Latency-Aware Spatiotemporal Adaptation and Self-Correcting Bidirectional Distillation. The model architecture is based on WAN2.1-I2V-14B and InfiniteTalk, utilizing a 3D VAE for latent compression, DiT blocks with 3D Attention, and multi-modality conditioning via audio, text, and reference imagery.
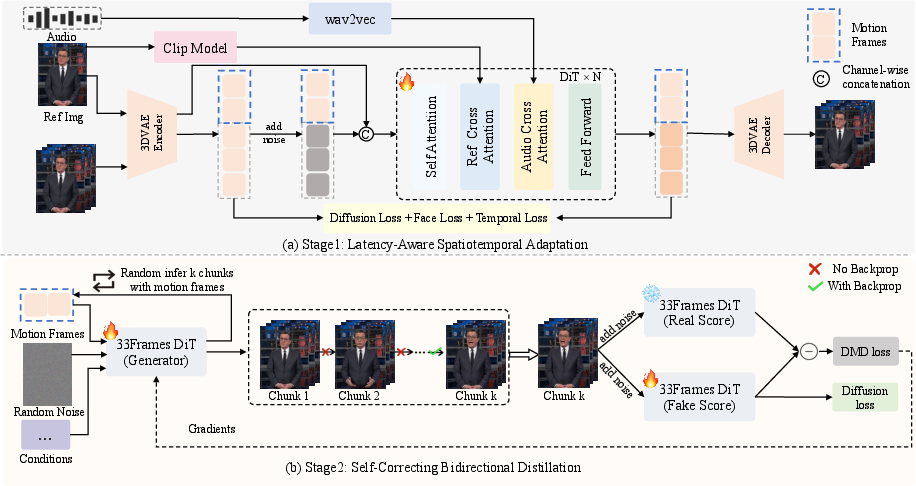
Figure 2: Framework overview—Stage 1 adapts to low spatial/temporal settings for real-time performance; Stage 2 introduces Self-Correcting Bidirectional Distillation aligning student and teacher distributions via autoregressive multi-chunk synthesis.
Bidirectional attention is retained within chunks, permitting local spatiotemporal context integration and greater coherence, diverging from conventional student-teacher distillation architecture misalignments that degrade motion dynamism and detail. The distillation phase eliminates classifier-free guidance, streamlining training and inference for rapid adaptation to real-time requirements. A Multi-step Retrospective Self-Correction mechanism simulates long-horizon error accumulation and recovery, with chunk generation length K stochastically sampled for robustness and training efficiency.
Inference Acceleration and System Implementation
To enable real-time streaming with a 14B parameter model, SoulX-LiveTalk implements a full-stack acceleration suite. Hybrid Sequence Parallelism synergizes Ulysses and Ring Attention to distribute attention workload, yielding substantial speedup. Kernel-level optimization via FlashAttention3 exploits NVIDIA Hopper architecture, reducing attention latency by 20% compared to previous kernels.
3D VAE bottlenecks are addressed using slicing-based parallelism inspired by LightX2V, accelerating encoding/decoding by roughly fivefold. Torch.compile is deployed for graph-level fusion, aggressive memory optimization, and hardware utilization maximization. These efforts result in sub-second total pipeline latency.
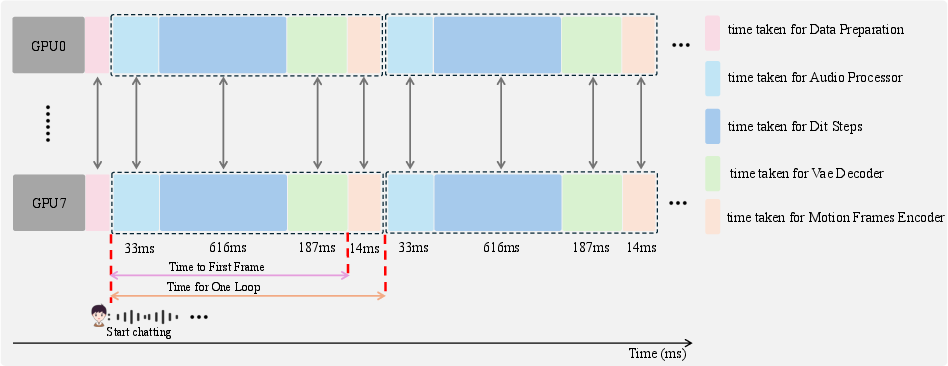
Figure 3: Inference latency breakdown on 8 NVIDIA H800 GPUs highlights bottleneck elimination via sequence and spatial parallelism plus compiler optimizations.
Experimental Evaluation
Quantitative Results
On the TalkBench benchmarks, SoulX-LiveTalk establishes state-of-the-art scores in image quality (IQA = 4.79), aesthetics (ASE = 3.51), and lip-sync precision (Sync-C = 1.47), achieving fluid 32 FPS throughput on an 8 × H800 cluster. For long-form videos, synchronization retention remains sustainable (Sync-C = 1.61) without substantial temporal drift. Competing methods, such as Ditto—which inpaints static faces—report marginally higher background/subject consistency but at the expense of full-body dynamics, which SoulX-LiveTalk robustly generates.
Visual Fidelity and Robustness

Figure 4: Visual comparison—SoulX-LiveTalk eliminates motion artifacts and hand distortions prominent in Ditto, EchoMimic-v3, and InfiniteTalk, maintaining sharp detail and expressiveness.
Long-term evaluation demonstrates negligible error accumulation or identity drift across infinite-duration streaming:

Figure 5: SoulX-LiveTalk preserves geometric and detail consistency over 1,000 seconds, outperforming baselines suffering from collapse and blurring.
Lip-sync analysis on Mandarin phonemes confirms precise mouth geometry alignment with ground truth, highlighting effective multimodal conditioning:

Figure 6: Lip-sync precision—SoulX-LiveTalk achieves fidelity in mouth aperture and phonemic shape, unlike baselines which exhibit distortion and desynchronization.
Ablation Studies
Multi-step self-correction and stochastic chunk scheduling enhance model robustness and training efficiency (Sync-C increases from 1.12 with single-chunk to 1.61 with randomized chunk strategy). Conditioning on student-predicted motion latents with noise injection (rather than ground truth) further boosts quality (ASE = 3.51, IQA = 4.79), reducing discrepancies between training and inference distributions.
Implications and Future Directions
SoulX-LiveTalk demonstrates that high-fidelity, infinite-duration, audio-driven avatar synthesis is feasible under real-time constraints on commodity multi-GPU clusters. The bidirectional attention framework and efficient distillation pipeline eliminate prevailing tradeoffs in streaming avatar generation, suggesting new baselines for interactive digital humans in telepresence, entertainment, and education.
The imminent challenge is to transition such architectures from large-scale hardware dependencies towards consumer-grade deployment. Investigating pruning, quantization, and even more efficient attention mechanisms remain natural progressions for future work. Ethically, the emergence of realistic, endless digital humans intensifies demands for transparent watermarking and forgery detection, as addressed in the associated statement.
Conclusion
SoulX-LiveTalk sets a new technical benchmark in real-time, infinite video streaming of audio-driven avatars. Through bidirectional streaming distillation, multi-step self-correction, and aggressive inference optimization, the framework synthesizes full-body, lifelike motion and visual fidelity with sub-second latency and sustained long-horizon stability. These advances open new opportunities for scalable, interactive avatar deployment, offering a foundation for further research in model efficiency, hardware adaptation, and responsible synthesis.

