StreamAvatar: Streaming Diffusion Models for Real-Time Interactive Human Avatars
Abstract: Real-time, streaming interactive avatars represent a critical yet challenging goal in digital human research. Although diffusion-based human avatar generation methods achieve remarkable success, their non-causal architecture and high computational costs make them unsuitable for streaming. Moreover, existing interactive approaches are typically limited to head-and-shoulder region, limiting their ability to produce gestures and body motions. To address these challenges, we propose a two-stage autoregressive adaptation and acceleration framework that applies autoregressive distillation and adversarial refinement to adapt a high-fidelity human video diffusion model for real-time, interactive streaming. To ensure long-term stability and consistency, we introduce three key components: a Reference Sink, a Reference-Anchored Positional Re-encoding (RAPR) strategy, and a Consistency-Aware Discriminator. Building on this framework, we develop a one-shot, interactive, human avatar model capable of generating both natural talking and listening behaviors with coherent gestures. Extensive experiments demonstrate that our method achieves state-of-the-art performance, surpassing existing approaches in generation quality, real-time efficiency, and interaction naturalness. Project page: https://streamavatar.github.io .








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces StreamAvatar, a system that turns a single photo of a person into a live, talking-and-listening video character (an avatar) that moves naturally and responds in real time to audio. Unlike many older methods that are slow, only show the head and shoulders, or only handle “talking,” StreamAvatar works fast, streams continuously, and shows full-body gestures that look natural during both speaking and listening.
What questions were the researchers trying to answer?
- How can we make high-quality avatar videos stream in real time, instead of generating a whole clip at once?
- How can we keep the avatar stable and consistent (same face, same identity) over long videos without drifting or getting blurry?
- How can an avatar not only talk, but also listen and react naturally (for example, nodding, smiling, or changing posture) to someone else’s audio?
How did they do it?
They used a “teacher–student” strategy plus some clever memory and training tricks. Here’s the idea in simple terms.
Step 1: Train a smart but slow “teacher”
- The team first trains a powerful video model that can create very realistic talking and listening behavior from a reference image and audio.
- This teacher uses a “diffusion” process: imagine starting with a TV full of static and slowly cleaning it up, step by step, until a clear video appears. This looks great but is too slow for live streaming.
Step 2: Distill the teacher into a fast “student”
- The student model learns to do in just a few quick steps what the teacher does in many steps. Think of it like learning shortcuts from a master.
- They also change how the model pays attention over time:
- Bidirectional attention (teacher) = reading an entire book at once. Great for quality, bad for streaming.
- Causal attention (student) = reading left to right, only using what you’ve already seen. Perfect for live, frame-by-frame video.
To make this work well for long videos, they add three key ideas:
- Reference Sink (a sticky note for identity)
- The model keeps a “sticky note” of the original photo in its memory so it never forgets what the person looks like. This reduces “identity drift” (the face changing over time).
- Reference-Anchored Positional Re-encoding (RAPR) (counting steps from home base)
- Models keep track of where each frame is in the sequence. Normally, this can break when videos get long (the model hasn’t seen such long distances in training).
- RAPR fixes this by always “recounting” positions relative to the original photo (home base) and capping how far counts can go. This helps the model keep attention on the original face and stay stable over long streams.
- Efficient memory (KV cache)
- The model keeps a rolling memory window of recent frames so it can stream forever without getting stuck or too slow.
Step 3: Adversarial refinement (a critic improves quality)
- After making the student fast, they polish it using an “AI critic” (a discriminator).
- This critic checks two things:
- Local realism: Do individual frames look real?
- Global consistency: Does the whole video stay consistent with the person’s identity and across time?
- By training the generator against this critic, the video gets sharper (e.g., better hands and teeth) and more stable.
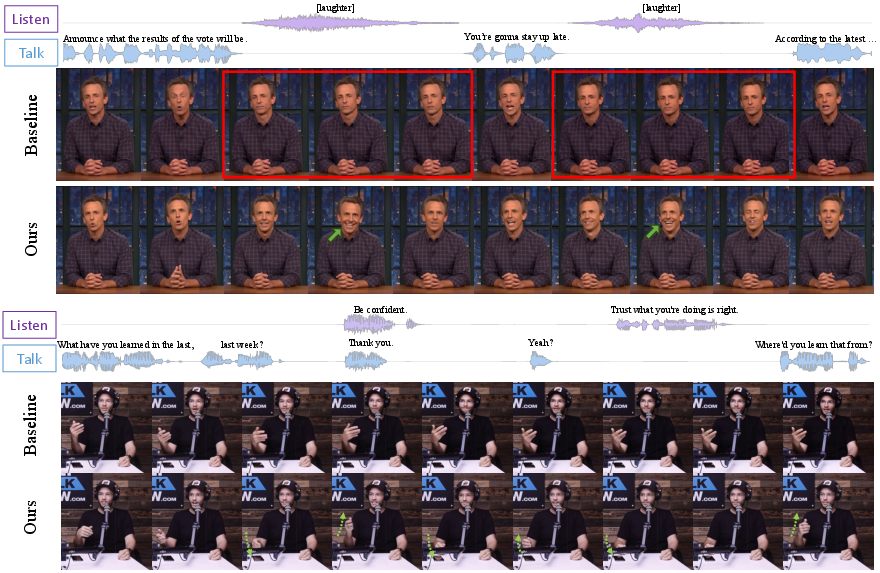
Making the avatar truly interactive (listening as well as talking)
- The system uses an “audio mask” to mark which moments are talking vs. listening. This mask is found using a detector (TalkNet) and does not change the raw audio, so the audio features stay accurate.
- Two special audio modules guide behavior:
- Talking Audio Attention: drives lip sync and expressive gestures while speaking.
- Interact (Listening) Audio Attention: triggers natural reactions while listening (like nodding or changing expression).
- The result: smooth transitions between talking and listening, and full-body gestures that feel natural.
- It’s “one-shot”: you only need one reference image of the person.
What did they find?
- Real-time streaming: The final student model runs with very low delay (about 1.2 seconds), generating high-resolution video in real time.
- High quality with few steps: It needs only 3 diffusion steps (much faster than typical methods) yet keeps strong quality.
- Stable over long videos: Thanks to the Reference Sink and RAPR, the avatar holds a consistent identity and avoids drifting.
- Natural interaction: The avatar not only talks with accurate lip sync, but also listens and reacts to the other person’s audio with believable facial expressions and body gestures.
- Strong performance: In tests, StreamAvatar matched or beat top methods on quality and synchronization—while being much faster. It showed fewer weird artifacts and richer, more expressive movements.
Why this matters:
- Usually, it’s hard to be both fast and good-looking. StreamAvatar achieves both, and it handles listening behavior that most systems ignore.
Why is this important and what could it lead to?
- More natural virtual people: This can power virtual tutors, streamers, customer service agents, and game characters that feel more alive—because they can both speak and listen naturally.
- Better live experiences: Real-time performance means smoother video calls with avatars, live streaming with animated hosts, and interactive assistants that respond quickly and believably.
- Future improvements: The authors note two limitations:
- If parts of the body are hidden for a long time, the model can sometimes be inconsistent when they reappear. A longer-term memory could help.
- Video decoding still takes a lot of time; making that faster would cut delay even more.
In short, StreamAvatar shows a practical path to real-time, full-body, interactive avatars that both talk and listen naturally—fast, stable, and high quality.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Lack of evaluation beyond ~20-second streams: the long-horizon stability of the causal model (with Reference Sink and RAPR) is not tested for minutes-scale or hour-scale interactions; behavior under extreme durations and repeated occlusion/reappearance is unknown.
- RAPR design choices are underexplored: the impact of the cap distance D, chunk size C, and KV window length on identity preservation, attention decay, and long-term stability lacks systematic analysis; comparisons with alternative positional schemes (e.g., ALiBi, learned PE, hybrid RoPE) are missing.
- Reference Sink scope is ad hoc: the decision to keep the first generation chunk alongside the reference frame in the sink is empirical; optimal sink composition, dynamic sink policies, and multi-reference strategies are unexplored.
- Student-forcing on noisy previous chunks: the choice to condition on noisy rather than clean denoised chunks improves speed but lacks theoretical grounding and comprehensive evaluation across diverse motion profiles, speech rates, and identities.
- Adversarial refinement design space: the consistency-aware discriminator architecture (teacher-initialized backbone + Q-Formers) is not ablated; effects of N_Q, query design, feature layers tapped, and alternative global consistency formulations (e.g., contrastive identity losses, cycle consistency) remain open.
- Streaming latency under realistic constraints: reported 1.2s latency on two H800 GPUs does not quantify performance on single consumer GPUs, laptops, mobile devices, or edge hardware; memory footprint and throughput under resource constraints are unknown.
- VAE decoding bottleneck: decoding consumes >50% of runtime; alternatives (faster VAEs, learned upsamplers, partial decoding, lightweight codecs) and their quality–latency trade-offs are not investigated.
- Limited camera and scene diversity: training filters out extreme head orientations and likely favors near-static cameras and cleaner scenes; robustness to camera motion, dynamic backgrounds, lighting changes, and partial occlusions is not assessed.
- Occlusion memory limitations: the model can produce inconsistencies for regions occluded over long spans; explicit long-term memory mechanisms (e.g., recurrent caches, external memory, identity embeddings) are proposed but not implemented or evaluated.
- Multi-person and diarization challenges: the audio mask relies on TalkNet for speaking/listening detection but robustness under overlapping speech, rapid turn-taking, off-screen speakers, or multi-speaker environments is not analyzed; real-time diarization latency and failure modes remain open.
- Listening behavior quality is undermeasured: listening-phase metrics rely on motion variances (LBKV/LHKV/LFKV), which measure “how much” movement but not “appropriateness” (e.g., timing of backchannels, valence-consistent expressions, prosody-aligned reactions); new metrics and human studies are needed.
- Gesture–prosody synchrony: the alignment of beat gestures, head nods, and hand motions to prosodic features is not quantitatively evaluated; standardized audio–gesture synchrony metrics are absent.
- Semantic responsiveness: the avatar does not model sentiment, discourse function (e.g., acknowledgments, hesitations), or content-aware reactions; conditioning on ASR/text, prosody, or emotion labels to drive semantically appropriate listening/talking remains open.
- Loss of text-conditioned control: the model fixes the text prompt and disables text control; integrating text, style, emotion, and gesture-level controls while retaining real-time performance is unexplored.
- One-shot full-body generalization limits: generating coherent full-body motion from a single reference image may fail under clothing changes, unseen body parts, or extreme poses; multi-view/multi-frame references and their benefits are not studied.
- Identity fidelity measurement: identity preservation is asserted qualitatively and via HA scores, but identity similarity (e.g., face embeddings, re-ID metrics) over long sequences is not reported; systematic identity drift quantification is missing.
- Fairness and diversity: performance across genders, ages, skin tones, cultural gestures, and languages is not analyzed; potential biases in SpeakerVid-5M and self-collected data could affect generalization.
- Audio mask reliability and training noise: errors in TalkNet mask labels (especially in noisy or overlapped speech) are not quantified; robustness to label noise and strategies like soft masks or uncertainty-aware conditioning are not explored.
- Turn-taking dynamics: the model switches phases via a binary mask but does not explicitly model conversational turn-taking (prediction of turns, interruptions, overlaps); learning or controlling turn transitions remains open.
- Comparative baselines for full-body listening are limited: evaluation against a talking-only baseline (muted in listening intervals) does not establish state-of-the-art comparisons for unified full-body listening–talking generation due to lack of suitable baselines; community benchmarks are needed.
- Distillation dataset and protocol details: the size/composition of ODE trajectory pairs used for initialization is underspecified; how trajectory diversity (subjects, motions, audio) affects student stability and quality is not studied.
- Chunk boundary artifacts and latency trade-offs: the effects of chunk size C on boundary jitters, motion continuity, lip-sync accuracy, and incremental latency are not systematically characterized; adaptive chunking strategies are unexplored.
- Robustness to audio pathologies: performance under noisy audio, reverberation, bandwidth-limited streams, and streaming packet loss is not evaluated; end-to-end resilience strategies (denoising, robust features) remain open.
- Safety, ethics, and provenance: risks of misuse (deepfakes, impersonation), and mechanisms for watermarking, traceability, consent, and identity verification are not addressed; integration of safety-by-design features is an open direction.
Practical Applications
Practical, real‑world applications of StreamAvatar
Below is an overview of actionable applications derived from the paper’s findings, methods, and innovations (autoregressive distillation for streaming, Reference Sink, RAPR, and consistency‑aware adversarial refinement; one‑shot, full‑body, listen‑and‑talk avatars). Applications are grouped as Immediate (deployable now, with engineering integration) and Long‑Term (requiring further research, scaling, or ecosystem maturity).
Immediate Applications
The following can be productized today with server‑side GPUs and standard speech tech (ASR/TTS/diarization). Each bullet lists sector(s), product/tool ideas, and key dependencies/assumptions.
- Real‑time customer service video agents
- Sectors: software, enterprise CX, finance, telecom, retail, government services
- What: Contact‑center avatars that listen/react to callers with natural gestures and smooth talk‑listen transitions, driven by live audio streams and a reference brand persona
- Tools/products: “Avatar Agent” widget for web/app; WebRTC gateway + StreamAvatar inference; CRM integration; policy/brand preset gestures
- Dependencies/assumptions: Server GPUs (similar to reported 2×H800); speech diarization/VAD to construct talk/listen mask at runtime; content moderation; consent/branding guidelines; latency budget ≈1–2 s; watermarking/disclosure for synthetic media
- Virtual presenters for meetings and webinars
- Sectors: enterprise software, productivity, education
- What: Camera‑off mode with a responsive full‑body avatar; AI co‑presenters that “listen” to participants and gesture appropriately
- Tools/products: Zoom/Teams plugin; OBS/Streamlabs plugin; “Avatar Cam” virtual camera driver; hotkeys for quick pose/preset
- Dependencies/assumptions: WebRTC/NDI pipeline; remote inference; identity and likeness rights; robust audio capture in noisy rooms; IT/security review
- VTubing and live streaming with reactive full‑body avatars
- Sectors: entertainment, creator economy, media
- What: One‑shot avatar from a single reference image; real‑time co‑speech gestures and listener reactions (laughter, nods)
- Tools/products: OBS plugin; “Creator Studio” with avatar presets; emote controls; LLM chat integration for scripted segments
- Dependencies/assumptions: Stable uplink; brand safety tools; GPU costs vs. audience size; IP rights for likeness
- E‑learning tutors and content authoring
- Sectors: education, HR/L&D, health education
- What: Interactive instructor avatars for live classes and instant course videos (script → TTS → avatar), with natural listener reactions in Q&A
- Tools/products: “Avatar Tutor” authoring tool; LMS integration (SCORM/xAPI); templated lesson gestures; multilingual voice swapping
- Dependencies/assumptions: TTS quality; privacy for learner audio; licensing for base models (Wan2.2/Wav2Vec2); disclosure of synthetic lecturers
- Low‑bandwidth telepresence and privacy‑preserving calling
- Sectors: communications, telework, public sector
- What: Audio‑only transmission with avatar regeneration on the receiver side; camera‑shy or privacy‑constrained users
- Tools/products: “Audio‑to‑Avatar” mode in conferencing; enterprise gateway for edge‑to‑cloud processing
- Dependencies/assumptions: User consent for face reference; accurate lip‑sync (already competitive in metrics); policy for deepfake risks
- Marketing and retail kiosks
- Sectors: retail, hospitality, travel, public services
- What: In‑store or kiosk avatars that listen to customers and respond naturally; queue triage and information desks
- Tools/products: Standalone kiosk app; FAQ brain via RAG/LLM; local noise suppression; face‑agnostic brand personas
- Dependencies/assumptions: Robust mic arrays; fallback for noisy environments; uptime SLAs; signage for synthetic content
- Media localization and corporate communications
- Sectors: media/localization, enterprise comms
- What: Script/TTS to video with localized lip‑sync; fill “listening” intervals with natural idle gestures to avoid uncanny stillness
- Tools/products: “Auto‑Dubbing Avatar” pipeline; batch render service; brand asset library
- Dependencies/assumptions: TTS/ASR accuracy per language; legal review for synthetic presenters; watermarking
- Synthetic data generation for gesture and pose research
- Sectors: academia, CV research, robotics perception
- What: Generate labeled full‑body sequences with controllable speaking/listening phases to train/test gesture, hand, and pose estimators
- Tools/products: Dataset generator with CSV/JPEG/HDF5 export; protocol scripts for controlled motion variance (HKV/LHKV/LBKV)
- Dependencies/assumptions: Domain gap to real data; license clarity on generated data usage; reproducible seeds for experiments
- Foundational techniques reusable beyond avatars
- Sectors: software, CV/ML research
- What: Apply Reference Sink and RAPR to stabilize other streaming diffusion/transformer tasks (video, speech, time‑series); use the consistency‑aware discriminator in long‑range AR models
- Tools/products: “Streaming DiT Toolkit” (RAPR, Sink, causal blocks, KV cache API) for PyTorch/Transformers
- Dependencies/assumptions: Access to base DiT/latent VAE; careful RoPE integration; licensing for redistribution
- Accessibility enhancements
- Sectors: public services, education, healthcare
- What: Lip‑synced avatars to support speech‑reading; expressive visual cues for users who prefer non‑camera interaction
- Tools/products: “Assistive Avatar” browser extension for video calls; configurable expressivity
- Dependencies/assumptions: Clear communication about synthetic content; evaluate for actual accessibility gains with user studies
Long‑Term Applications
These require further research, data, optimization, or policy maturation (e.g., on‑device inference, 3D consistency, safety).
- On‑device and edge deployment (AR glasses, mobile)
- Sectors: AR/VR, telecom, consumer devices
- What: Ultra‑low‑latency avatars on wearables/phones for local privacy; mixed reality meeting companions
- Needed advances: Faster/lighter VAE decoding (identified bottleneck), quantization and distillation for mobile NPUs, streaming memory optimizations beyond current KV cache window, robust thermal/power envelopes
- 3D telepresence and robotics embodiment
- Sectors: robotics, telemedicine, telepresence, XR
- What: Multi‑view/3D avatars that preserve identity and listen‑react behaviors; mapping gestures to robot bodies or holograms
- Needed advances: 3D‑consistent diffusion with causal attention, multi‑camera supervision, real‑to‑sim alignment, safety for physical gesturing
- Multi‑party conversational scenes
- Sectors: enterprise comms, education, media
- What: Orchestrate several avatars with accurate diarization, turn‑taking, cross‑talk, and gaze; group dynamics
- Needed advances: Real‑time, robust speaker diarization; fine‑grained talk/listen masks without TalkNet video dependency; gaze and attention control models; scalable causal memory across multiple KV streams
- Sign language and precise gesture generation
- Sectors: accessibility, public services, education
- What: Grammatically correct sign language or domain‑specific hand gestures (e.g., medical demonstrations)
- Needed advances: Task‑specific datasets and evaluation; constraint‑aware generation (linguistic correctness); higher‑resolution hand rendering; alignment with sign glosses
- Emotionally controllable, persona‑consistent agents
- Sectors: healthcare, education, customer care, entertainment
- What: Fine control over affect, persona, and cultural gesture norms; therapeutic or coaching avatars
- Needed advances: Multimodal emotion conditioning; safety guardrails for sensitive contexts; cultural datasets; long‑term memory for identity and style beyond the current rolling window
- Multilingual real‑time translation with expressive avatars
- Sectors: enterprise, travel, public services
- What: Live cross‑lingual calls with target‑language lip‑sync and culturally appropriate gestures; reactive listening in both directions
- Needed advances: Low‑latency ASR→MT→TTS orchestration; prosody transfer; gesture style transfer; evaluation for comprehension and trust
- Privacy‑preserving and compliant deployments
- Sectors: policy, legal, finance, healthcare, public sector
- What: Auditable avatars with watermarking, provenance (C2PA), consent management, deepfake detection interoperability
- Needed advances: Robust watermarking for video diffusion; standardized disclosures; regional compliance toolkits (GDPR/HIPAA/CCPA); red‑teaming for misuse
- Sustainable, cost‑efficient streaming at scale
- Sectors: cloud, telecom, platform providers
- What: Millions of concurrent sessions at acceptable cost/energy
- Needed advances: Model compression; async/partial decoding; shared KV caching strategies; adaptive frame rate/resolution; hardware co‑design
- Long‑horizon consistency and occlusion memory
- Sectors: software, media production
- What: Stable identity and scene content over very long sessions with occlusions or viewpoint changes
- Needed advances: Long‑term memory modules beyond reference sinks (learned episodic memory, retrieval‑augmented caches), training with longer synthetic horizons, occlusion reasoning
- Workflow‑aware creative and production tools
- Sectors: media, advertising, corporate comms
- What: End‑to‑end tools for scripting → gesture planning → multi‑take recording → batch render
- Needed advances: Controllability interfaces (gesture timelines, beat alignment), scene editing, rights management for likeness libraries
Notes on key assumptions and dependencies across applications:
- Compute and latency: Reported real‑time performance (≈1.2 s latency at 720p) used 2×H800 GPUs; server‑side inference is the near‑term path. VAE decoding dominates runtime today.
- Audio conditioning: The paper’s talk/listen masking used TalkNet in training; for deployment, rely on robust VAD/diarization (noisy, multi‑speaker environments) to build masks without needing video.
- Input constraints: One‑shot works best with forward‑facing references; extreme poses and long occlusions can reduce consistency (acknowledged limitation).
- Safety and ethics: Explicit user consent for likeness, watermarking/provenance, content moderation, and anti‑impersonation safeguards are critical.
- Licensing and IP: Respect licenses for Wan2.2 backbone, Wav2Vec2 features, and any pretrained components; establish rights for brand/persona images.
- Network/media stack: WebRTC or similar for streaming, with fallback modes (frame rate/resolution) and bandwidth adaptation; edge gateways for enterprise IT requirements.
These applications leverage the paper’s core advantages: streaming causal diffusion with KV caching, identity stability via Reference Sink, long‑range robustness via RAPR, quality recovery via consistency‑aware adversarial refinement, and truly interactive listen‑and‑talk conditioning for full‑body avatars.
Glossary
- Adversarial refinement: A GAN-based post-training stage used to improve visual quality and temporal consistency after distillation. "In the second stage, we propose an adversarial refinement process to resolve the quality degradation such as distortion and blur caused by distillation, and improve long video consistency."
- Audio Attention: An attention module that injects speaking-related audio cues into the video model to drive co-speech motion. "Audio Attention, which introduces talking cues to drive expressive human motion during speaking segments."
- Audio mask: A binary temporal mask indicating talking vs. listening frames, used to separate and condition distinct behaviors without modifying the raw waveform. "we utilize a talking-listening audio mask to extract distinct talking and listening audio features"
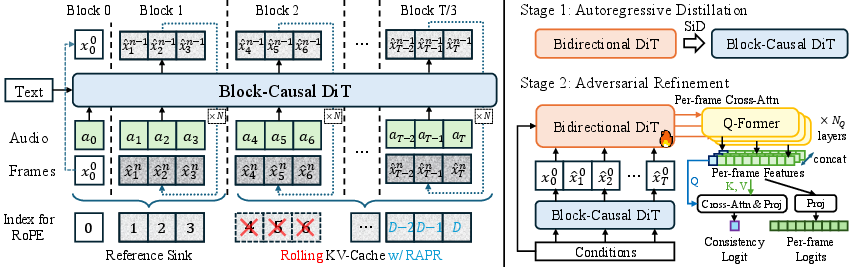
- Autoregressive distillation: Training a causal, few-step student model to mimic a slow bidirectional diffusion teacher for streaming generation. "The first stage performs autoregressive distillation to convert a bidirectional diffusion models into real-time, streaming generator."
- Bidirectional attention: Attention over a full sequence where tokens attend to both past and future, unsuitable for streaming due to non-causal dependencies. "the non-casual bidirectional attention mechanism requires the entire video sequence to be processed at once"
- Block-causal DiT: A Diffusion Transformer whose attention is causal across chunks but bidirectional within each chunk to enable autoregression. "The original bidirectional DiT is first transformed into a block-causal DiT with block size ."
- Block-wise causal attention: An attention scheme that enforces causality between temporal chunks while allowing bidirectional attention inside each chunk. "adapt the attention mechanism of the model from bidirectional attention into block-wise causal attention"
- Consistency-Aware Discriminator: A discriminator that evaluates both per-frame realism and cross-frame identity/temporal consistency. "guided by a Consistency-Aware Discriminator"
- Diffusion Forcing (DF): A distillation technique for autoregressive video diffusion that aligns student and teacher denoising trajectories. "using Diffusion Forcing (DF)~\cite{DiffusionForcing}"
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models, here operating in the video VAE latent space. "The distillation process operates on the Diffusion Transformer (DiT) within the VAE latent space."
- Distribution Matching Distillation (DMD): A distillation method aligning the distribution of student outputs with the teacher’s for improved few-step generation. "and distribution matching distillation (DMD)~\cite{DMD}"
- Fréchet Inception Distance (FID): A metric comparing distributions of generated and real images using deep features. "FID"
- Fréchet Video Distance (FVD): A metric comparing distributions of generated and real videos using spatiotemporal deep features. "FVD"
- Hand Keypoint Variances (HKV): A motion richness metric measuring variance of detected hand keypoints over time. "Hand Keypoint Variances (HKV)~\cite{EchoMimicV2} quantifies gesture dynamics."
- Human Anomaly (HA) score: A metric assessing visual anomalies or distortions in generated humans (body, hands, face). "We also adopt the Human Anomaly (HA) score from VBench-2.0~\cite{VBench-2.0} to assess distortion in body, hands, and faces."
- Interact Audio Attention: An attention module that injects listening-related audio cues to produce reactive non-speaking behaviors. "Interact Audio Attention, which introduces listening cues to generate natural reactive behaviors during listening intervals."
- LBKV: Listening-phase body keypoint variance measuring motion richness during listening segments. "denoted as LBKV, LHKV, and LFKV, respectively."
- LFKV: Listening-phase face keypoint variance measuring facial motion richness during listening segments. "denoted as LBKV, LHKV, and LFKV, respectively."
- LHKV: Listening-phase hand keypoint variance measuring hand motion richness during listening segments. "denoted as LBKV, LHKV, and LFKV, respectively."
- Out-of-distribution (OOD): A mismatch where test-time inputs (e.g., large positional indices) fall outside the training distribution, causing failure. "leading to catastrophic out-of-distribution (OOD) issues."
- Ordinary Differential Equation (ODE) solution pairs: Recorded teacher denoising trajectories used to initialize the student via regression. "to construct a dataset of Ordinary Differential Equation (ODE) solution pairs ."
- Q-Align: An evaluation toolkit providing image quality and aesthetic scores for generated content. "Q-Align~\cite{Q-Align} evaluates image quality (IQA) and aesthetic score (ASE)"
- Q-Formers: Querying Transformer modules that extract per-frame features used by the discriminator. "insert Querying Transformers (Q-Formers)~\cite{BLIP-2} with learnable per-frame queries"
- R1/R2 gradient penalty: Regularization terms for stabilizing GAN training by penalizing gradients on real/fake samples. "and R1/R2 gradient penalty~\cite{Mescheder18Which}"
- Reference Sink: A persistent cache of reference-frame keys/values that are never evicted, preventing identity drift. "a Reference Sink, which enforces persistent attention to the reference frame"
- Reference-Anchored Positional Re-encoding (RAPR): A RoPE re-indexing mechanism that caps distances to the reference and re-anchors positions to stabilize long sequences. "Reference-Anchored Positional Re-encoding (RAPR)"
- Relativistic adversarial loss: A GAN objective that compares realness of real vs. fake samples relatively rather than absolutely. "using a relativistic adversarial loss~\cite{RelativisticLoss}"
- Rolling KV cache: A moving window of key/value tensors used to maintain causal context over long video without unbounded memory. "a rolling KV cache is adopted to store a fixed window of context information."
- Rotary Positional Embedding (RoPE): A positional encoding method applied in attention that rotates query/key vectors by position-dependent phases. "Rotary Positional Embedding (RoPE) \cite{RoPE}"
- Score Identity Distillation (SiD): A distillation approach that trains the student to match the teacher’s score/denoising function. "we apply Score Identity Distillation (SiD)~\cite{SiD} to train the student model"
- Student-forcing: Training the student to condition on its own generated history to reduce train–test mismatch. "we adopt the student-forcing scheme from Self Forcing~\cite{SelfForcing}"
- Variational Autoencoder (VAE) latent space: The compressed latent domain where video frames are encoded/decoded for diffusion. "within the VAE latent space."
- Wav2Vec: A self-supervised audio representation model used to extract robust features for conditioning. "Wav2Vec~\cite{Wav2Vec2} pretraining."
Collections
Sign up for free to add this paper to one or more collections.