Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation
Abstract: Talking head generation creates lifelike avatars from static portraits for virtual communication and content creation. However, current models do not yet convey the feeling of truly interactive communication, often generating one-way responses that lack emotional engagement. We identify two key challenges toward truly interactive avatars: generating motion in real-time under causal constraints and learning expressive, vibrant reactions without additional labeled data. To address these challenges, we propose Avatar Forcing, a new framework for interactive head avatar generation that models real-time user-avatar interactions through diffusion forcing. This design allows the avatar to process real-time multimodal inputs, including the user's audio and motion, with low latency for instant reactions to both verbal and non-verbal cues such as speech, nods, and laughter. Furthermore, we introduce a direct preference optimization method that leverages synthetic losing samples constructed by dropping user conditions, enabling label-free learning of expressive interaction. Experimental results demonstrate that our framework enables real-time interaction with low latency (approximately 500ms), achieving 6.8X speedup compared to the baseline, and produces reactive and expressive avatar motion, which is preferred over 80% against the baseline.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation”
Overview
This paper introduces “Avatar Forcing,” a new way to make a talking head avatar (a face that speaks and moves on screen) feel more like a real person in a live conversation. Instead of only moving its lips to match audio, this avatar can react instantly to you—nodding, smiling, making eye contact—based on what you say and how you move. The goal is to make virtual chats feel more natural, engaging, and human-like.
Key Questions the Paper Tries to Answer
Here are the main problems the researchers wanted to solve:
- How can an avatar react in real time, with very low delay, to both your voice and your facial/head movements?
- How can the avatar learn to be expressive (smiling, nodding, showing attention) without needing lots of special labels or hand-made examples?
How It Works (Methods), in Simple Terms
The system has three big ideas. Think of it like building a super-responsive digital “conversation partner.”
1) Real-time motion generation (so it responds fast)
- Everyday analogy: Imagine you’re drawing a flipbook animation. You don’t have the whole story yet; you draw each new frame using what happened in the previous frames, plus a tiny peek ahead to keep things smooth. That’s “causal” generation—it doesn’t wait for the future; it reacts now.
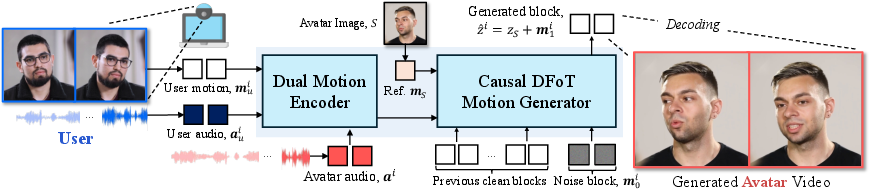
- The paper uses a technique called “diffusion forcing.” In simple terms, the model makes a quick, rough guess for the next bit of movement, then repeatedly improves that guess using only past information. This keeps the avatar’s reactions fast and timely.
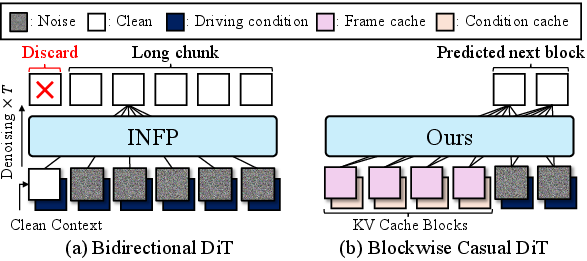
- To avoid lag, the model uses “KV caching,” which is like short-term memory that stores useful info from recent frames so it doesn’t recalculate everything from scratch. This reduces latency to about 0.5 seconds, which feels nearly instant.
2) Understanding multimodal signals (it listens and watches you)
- The avatar pays attention to:
- Your voice (what and how you speak),
- Your face and head movements (non-verbal cues: nods, smiles),
- The avatar’s own audio (what it needs to say).
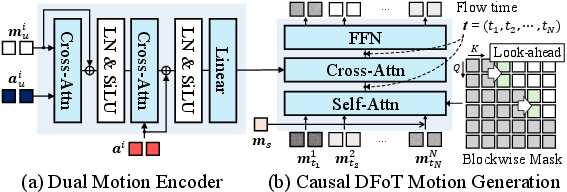
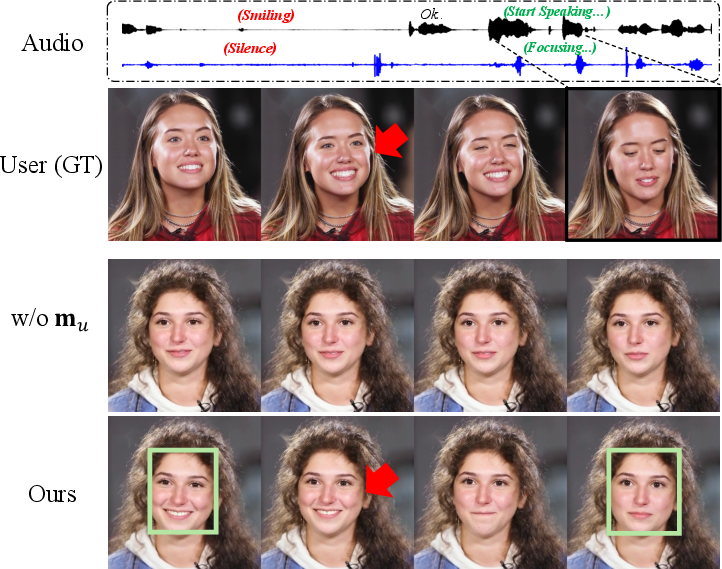
- A “Dual Motion Encoder” blends these signals together, like a mixing board for sound and video. It aligns your movements with your speech and connects that to what the avatar should do or say. This helps the avatar respond appropriately to both verbal and non-verbal cues.
3) Learning to be expressive without extra labels
- Everyday analogy: Think of teaching by comparison—showing a good example and a less-good example so the model learns what people prefer.
- The authors use “Direct Preference Optimization (DPO),” a method that improves the model by comparing pairs:
- A “preferred” motion (expressive, natural behavior from real videos),
- A “less preferred” motion (a dull reaction that ignores the user’s cues, like a simple audio-only talking model).
- By training the avatar to favor the preferred examples, it learns to be more responsive and expressive—without needing special labels like “this is a smile” or “this is a nod.”
Main Findings and Why They’re Important
Below is a short summary of what changed and why it matters:
- Much lower delay: About 0.5 seconds of latency, which is fast enough to feel real-time (around 6.8× faster than a strong baseline system).
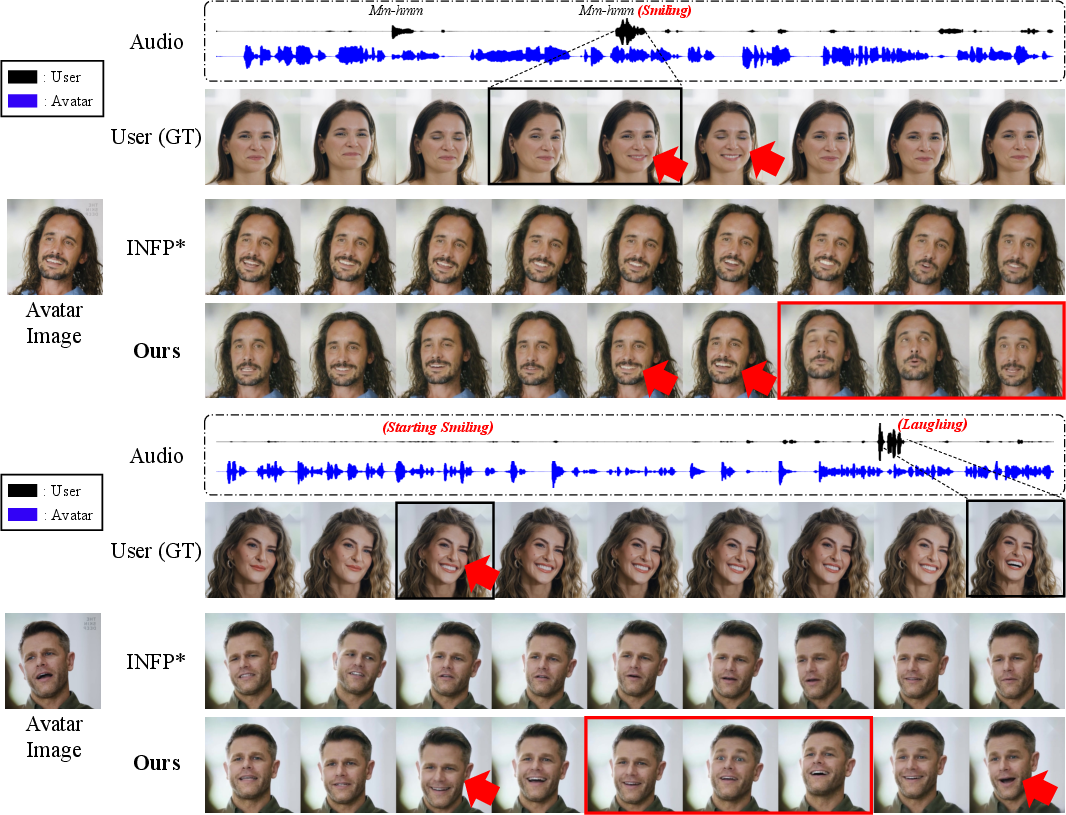
- More reactive and expressive: The avatar naturally mirrors your expressions (for example, it smiles after you smile) and shows attentive listening (nods, focused gaze).
- People prefer it: In human tests, over 80% of participants chose this system over the baseline for overall interaction quality.
- Quality stays high: Visual quality and lip-sync remain competitive with top talking head models, so it looks good and sounds aligned.
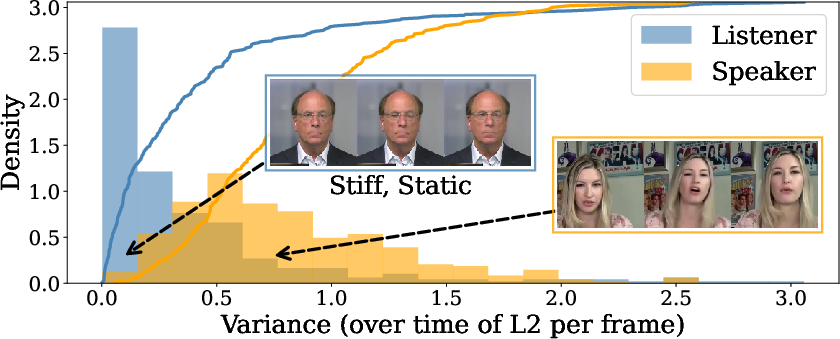
- Better listening behavior: On listening-focused tests, it produces more synchronized, varied, and natural reactions than previous methods.
Why This Matters (Impact and Uses)
This work makes virtual avatars feel more alive and responsive, which can improve:
- Online learning and tutoring (teachers or guides that react and encourage students),
- Customer support or virtual hosts (better engagement and empathy),
- Entertainment and social apps (interactive characters that feel present),
- Accessibility (avatars that make communication clearer and more engaging).
It also hints at the future of human–AI communication: systems that don’t just talk at you but genuinely interact with you—responding to both what you say and how you feel. As with any powerful media technology, it’s important to use it responsibly, especially when it comes to deepfakes, consent, and authenticity.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future researchers:
- End-to-end latency and system-level benchmarking: The reported ≈500 ms latency assumes pre-extracted audio features; there is no measurement including audio feature extraction, face tracking/cropping, motion encoding/decoding, and network I/O on commodity hardware (laptops, mobile, webRTC), nor analysis of speed–quality trade-offs (NFEs, guidance scale) under real streaming constraints.
- Look-ahead causality at inference: The “look-ahead” causal mask allows attention to limited future frames, but it is unclear how this operates at inference without future data; quantify any training–inference mismatch, its effect on jitter, and the latency/quality impact of l and B across conditions.
- Long-horizon stability: No analysis of error accumulation or drift in KV-cached blockwise rollouts over long conversations; study cache size M, attention windowing, and failure modes (temporal instability, identity drift) beyond the short clips reported.
- Robustness to real-world variability: Test under occlusions, large head rotations, rapid gestures, facial accessories (glasses/masks), lighting changes, camera motion, and variable frame rates; characterize failure cases and robustness strategies (data augmentation, adaptive encoders).
- Audio separation reliability: The pipeline depends on visual-grounded speech separation (IIANet); quantify performance degradation when separation fails (overlapping speech, noisy environments, off-screen speakers) and its impact on reactiveness metrics.
- Multilingual and accent diversity: Wav2Vec2.0 features are used, but there is no evaluation across languages, accents, speech rates, or code-switching; assess generalization to non-English conversations and low-resource languages.
- Non-verbal signal breadth: The model only uses head motion and audio; investigate incorporating eye gaze, blink patterns, micro-expressions, and hand/upper-body cues to improve engagement and realism.
- Turn-taking and conversational control: Avatar audio is externally provided; there is no mechanism for the avatar to decide when to speak vs listen, or to manage interruptions and backchannels; explore integrating turn-taking detection and end-to-end content generation.
- Personalization and style adaptation: No method for adapting reactiveness/expressiveness to a user’s conversational style, cultural norms, or preferences (e.g., more/less nodding); develop few-shot or online adaptation while maintaining stability.
- Explicit behavior control: Provide high-level controls (e.g., “smile intensity,” “eye contact,” “nod frequency”) and study how to steer behaviors with text or semantic cues without breaking causal real-time constraints.
- Preference optimization design: The DPO pairs use ground-truth motion as “preferred” and audio-only samples as “less-preferred,” which may bias learning; compare alternative negative samples (e.g., dropped user-motion/audio, shuffled cues), multi-objective DPO, and the effects of β and λ on lip-sync and realism.
- Human preference data: The study uses 22 participants; expand to larger, diverse cohorts, report statistical significance, and release standardized preference datasets/tasks for reproducible interactive-avatar evaluation.
- Expressiveness metrics: SID and Var capture diversity but not appropriateness or subtlety; develop metrics for non-verbal alignment (gaze, timing of nods/smiles), affective congruence, and listener engagement beyond rPCC-exp/pose.
- Fairness and demographic coverage: No analysis of performance across skin tones, ages, genders, and cultural expressiveness norms; audit for bias and propose mitigation (balanced datasets, fairness-aware objectives).
- Dataset breadth and scale: Training/evaluation focus on RealTalk, ViCo, and a small HDTF subset (50 videos); quantify scaling effects, cross-domain generalization (e.g., live streaming, podcasts), and create standardized dyadic benchmarks with turn-taking annotations.
- Visual artifacts and identity stability: FID/FVD are reported, but artifacts under extreme poses and identity preservation over long sequences (CSIM drift) are not analyzed; investigate identity conditioning and temporal consistency mechanisms.
- Integration with 3D representations: The approach relies on motion latents; assess benefits of explicit 3D face models (3DMM/gaze) for controllability, occlusion handling, and camera-motion robustness.
- Adaptive scheduling and solvers: Explore learned/adaptive ODE solvers, distillation or rectified flows to reduce NFEs without quality loss, and dynamic block sizes/attention windows for latency-sensitive settings.
- Generalization to multi-party settings: The method targets dyadic interactions; extend to group conversations with speaker diarization, concurrent cues from multiple users, and selective attention.
- Failure mode cataloging: Systematically document and quantify common failure modes (overreacting to weak cues, delayed reactions, smile mis-timing, frozen listener behavior) and propose diagnostic tests.
- Comparability to prior work: INFP is reproduced (no official code); establish standardized protocols, shared splits, and open-source baselines to ensure fair comparisons across interactive-avatar models.
- Privacy, security, and misuse: The paper defers ethical considerations to the appendix; concretely address user consent, biometric data handling, watermarking/traceability, and safeguards against impersonation or deepfake misuse in real-time deployments.
- Energy and resource footprint: Report memory and compute costs of KV caching and motion decoding, and evaluate feasibility on edge devices (mobile, AR headsets) under power constraints.
- Content sensitivity and affect: Without semantic understanding, the avatar may smile or nod inappropriately (e.g., during distressing content); study semantic/affective coupling to avoid socially incongruent reactions.
- Open-sourcing and reproducibility: Critical components (latent auto-encoder retraining, DPO details, metrics code) are deferred to appendices; until code/models are released, reproducibility and exact hyperparameter settings remain open.
Practical Applications
Overview
Below are practical, real-world applications derived from the paper’s findings and innovations in Avatar Forcing—namely low-latency causal diffusion forcing, Dual Motion Encoder for multimodal alignment, KV caching with look-ahead causal attention for streaming, and preference optimization (DPO) for expressiveness. Each application is categorized, linked to relevant sectors, outlines potential tools/products/workflows, and notes assumptions or dependencies that affect feasibility.
Immediate Applications
These applications can be deployed now with current capabilities (≈500 ms latency, real-time multimodal response, expressive motion via DPO).
- Real-time avatar overlay for video conferencing (privacy-preserving presence)
- Sector: software, enterprise, education
- Tools/Products/Workflows: “Avatar Forcing” virtual camera plugin for Zoom/Teams/Meet; identity latent swap to a stylized persona; KV-cached streaming pipeline for low-latency mirroring of user expressions/head motion while speaking
- Assumptions/Dependencies: reliable webcam/mic; decent lighting and frontal face view; GPU/accelerator or cloud inference; user consent/compliance for synthetic presence; watermarking to prevent impersonation concerns
- Livestream co-host and VTuber automation (engaging, reactive avatars)
- Sector: media/entertainment, creator economy
- Tools/Products/Workflows: OBS/Streamlabs plugin; dual-mode co-host that mirrors streamer’s non-verbal cues and delivers scripted/LLM-driven avatar audio; DPO “expressiveness” tuners
- Assumptions/Dependencies: stable upstream bandwidth; integration with TTS/LLM; moderated content filters; brand safety controls
- Customer support “digital human” for web/app kiosks (expressive, empathic front-end)
- Sector: finance, retail, telecommunications, public services
- Tools/Products/Workflows: web SDK to embed an avatar that reacts to customer voice and gaze; pipeline: ASR → LLM dialogue → TTS avatar audio → real-time reactive head avatar
- Assumptions/Dependencies: access to user camera/audio (opt-in); privacy disclosures; latency budgets; fallback to audio-only if user video unavailable; cultural sensitivity and accessibility guidelines
- Interactive e-learning instructor/tutor (non-verbal alignment for engagement)
- Sector: education
- Tools/Products/Workflows: LMS plugins where the avatar nods, smiles, and adjusts focus in sync with student cues; “office hours” assistants; scripted content with reactive visuals
- Assumptions/Dependencies: student video availability; classroom privacy policies; content watermarking; device performance in school settings
- Telepresence for internal meetings with anonymization (reduce camera fatigue, standardize presence)
- Sector: enterprise/HR
- Tools/Products/Workflows: corporate “presence masks” that map employee motion onto approved avatars; persona libraries per team; KV caching for smooth transitions
- Assumptions/Dependencies: employee consent; legal review for synthetic presence in regulated industries; identity verification and watermarking
- Marketing/brand ambassadors on websites (consistent persona with reactive motion)
- Sector: marketing/advertising
- Tools/Products/Workflows: brand-avatar SDK for landing pages; campaign workflows with DPO-tuned expressiveness per brand style; A/B testing with engagement analytics (rPCC as internal metric)
- Assumptions/Dependencies: brand governance policies; multilingual TTS; performance budgets for mobile visitors; accessibility compliance (captions, alt modes)
- Retail and facility reception kiosks (greeting + triage)
- Sector: retail, hospitality, transportation
- Tools/Products/Workflows: in-store kiosk avatars responding to user speech and facial cues; integration with booking/queue systems
- Assumptions/Dependencies: camera placement at appropriate height; noise handling; user acceptance; on-device compute or edge servers
- Creator tool for dubbed and narrated content (emotion-preserving overlays)
- Sector: media/localization
- Tools/Products/Workflows: post-production pipeline where avatar audio (original or translated TTS) drives lip sync and avatar mirrors non-verbal cues; quick edits with motion-latent manipulation
- Assumptions/Dependencies: source-language emotion retention; rights to transform likeness; QC for cultural appropriateness
- Accessibility and social comfort features (camera-shy users)
- Sector: accessibility, daily life
- Tools/Products/Workflows: consumer apps that let users appear as avatars mirroring their expressions while reducing personal exposure; “confidence layer” for presentations
- Assumptions/Dependencies: simple UX for calibration; robust expression tracking for glasses/occlusions; explicit disclosure to audiences that an avatar is used
- Research toolkit for studying non-verbal communication (label-free expressiveness alignment)
- Sector: academia
- Tools/Products/Workflows: open-source “Avatar Forcing” models with DPO to analyze how different preference pairs affect expressiveness/reactiveness; benchmarking rPCC/Var/SID metrics
- Assumptions/Dependencies: release of code/models; IRB compliance for user studies; datasets with consent and diverse demographics
- Real-time avatar SDK for developers (streaming, KV caching, look-ahead attention)
- Sector: software
- Tools/Products/Workflows: APIs/SDKs exposing motion-latent generation, KV cache management, condition encoding for user audio/motion; reference plugins for browsers and Unity/Unreal
- Assumptions/Dependencies: developer documentation; GPU-backed endpoints; model cards and safety usage notes
- Role-play and interview practice coaches
- Sector: HR, education, coaching
- Tools/Products/Workflows: scenario-based apps where the avatar exhibits realistic listening behaviors (nods, gaze) and provides feedback; DPO-tuned “persona styles”
- Assumptions/Dependencies: bias audits (e.g., age/gender/race); clear disclaimers; integration with analytics and feedback modules
Long-Term Applications
These require further research, scaling, validation, or development (e.g., mobile optimization, clinical trials, regulatory frameworks, expanded modalities).
- Clinically validated empathic telehealth avatars
- Sector: healthcare
- Tools/Products/Workflows: HIPAA-compliant virtual clinicians/therapists with calibrated non-verbal responses; session recording with audit trails; expressiveness tuned for patient comfort
- Assumptions/Dependencies: clinical studies to measure outcomes; robust handling of edge cases (affect disorders); strict privacy/security; medical device/healthcare regulation compliance
- Social robots and service robots with expressive screen faces
- Sector: robotics, hospitality
- Tools/Products/Workflows: embedded head avatars that mirror user cues in real time; on-device inference with quantized models and accelerators; multi-sensor fusion (gaze/pose)
- Assumptions/Dependencies: hardware acceleration; thermal/power constraints; robust tracking under motion/occlusion; safety certifications
- AR/VR telepresence and mixed-reality “synthetic presence”
- Sector: XR, enterprise collaboration
- Tools/Products/Workflows: avatars mapped into virtual spaces with synchronized non-verbal cues; cross-platform SDKs (OpenXR) using motion latents; emotion-preserving translation overlays
- Assumptions/Dependencies: headset sensors for facial tracking; latency budgets for shared environments; standardized identity/watermark protocols
- Full-body conversational avatars (beyond head)
- Sector: media/entertainment, education, robotics
- Tools/Products/Workflows: extension of motion latents to shoulders/gestures/posture; causal diffusion for body dynamics with look-ahead attention across joints; multimodal user-condition encoders
- Assumptions/Dependencies: diverse motion datasets; pose capture beyond face; collision/physical plausibility; higher compute budgets
- Multilingual, cross-cultural expressiveness calibration
- Sector: global services, localization
- Tools/Products/Workflows: DPO with region-specific preference pairs; policy-defined persona guidelines; automatic “expressiveness normalization” per culture
- Assumptions/Dependencies: culturally representative datasets; human-in-the-loop review; avoidance of stereotyping; governance frameworks
- Real-time emotion-aware translation with non-verbal transfer
- Sector: communications, public services
- Tools/Products/Workflows: pipeline that translates speech while preserving prosody and maps emotion to avatar reactions; adaptive tuning for formality
- Assumptions/Dependencies: high-quality prosody-preserving TTS; multilingual ASR/MT; ethical policies for emotion manipulation (transparency)
- Mobile/on-device inference for consumer apps
- Sector: mobile software, daily life
- Tools/Products/Workflows: optimized models (distillation/quantization) for smartphones; hardware acceleration (NPU/GPU); fallback low-power modes
- Assumptions/Dependencies: resource-constrained architectures; battery considerations; privacy-preserving on-device processing; adaptive bitrate streaming
- Multi-party, multi-camera meeting avatars (group dynamics)
- Sector: enterprise collaboration, education
- Tools/Products/Workflows: avatars reacting to several participants’ cues; attention allocation models; dynamic condition mixing across speakers/listeners
- Assumptions/Dependencies: multi-person tracking; role detection; fairness (equal visibility); latency scaling and bandwidth management
- Standardized watermarking, provenance, and disclosure for synthetic presence
- Sector: policy/regulation, platforms
- Tools/Products/Workflows: cryptographic watermarking at motion-latent or render stage; “synthetic presence” badges; platform policies and detection tools
- Assumptions/Dependencies: industry standards; interoperable watermark schemes; regulation and platform enforcement; user education
- Behavioral analytics for engagement and well-being (with strong safeguards)
- Sector: academia, product analytics
- Tools/Products/Workflows: aggregated rPCC/Var/SID metrics to study engagement; dashboards for instructors/support agents; opt-in data governance
- Assumptions/Dependencies: privacy-first instrumentation; IRB/ethical approvals; de-identification; strict limits on surveillance or manipulative use
- Enterprise knowledge agents with expressive avatars
- Sector: software, enterprise IT
- Tools/Products/Workflows: LLM-driven assistants surfaced as avatars with adaptive non-verbal behaviors; persona management; domain-specific DPO fine-tuning pipelines
- Assumptions/Dependencies: secure integration with enterprise data; latency SLAs; controllability APIs; safety and compliance audits
Notes on Feasibility and Dependencies
- Compute and latency: Achieving ≈500 ms end-to-end requires either local GPUs/accelerators or low-latency cloud inference; KV caching and look-ahead attention help, but network jitter can increase perceived delay.
- Sensing quality: Reliable face tracking and expression capture depend on camera placement, lighting, occlusions (glasses/masks), and user movement.
- Pipeline integration: Many applications need ASR/LLM/TTS components to drive avatar audio; quality of prosody and timing affects realism.
- Safety and ethics: Watermarking/disclosure, consent mechanisms, deepfake misuse mitigation, demographic fairness audits, and cultural sensitivity are essential to deployment.
- Legal/regulatory: Sector-specific constraints (healthcare/finance) require compliance frameworks, data protection controls, and clear governance for synthetic identity/presence.
- Dataset diversity: Expressiveness calibration and generalization benefit from diverse, representative training data; domain adaptation may be needed across cultures, age groups, and languages.
Glossary
- 1D RoPE (Rotary Positional Embeddings): A positional encoding method that injects relative position information into attention using rotations in complex space; here used in 1D form for sequences. "1D RoPE~\citep{rope}"
- 3D morphable models (3DMM): Parametric 3D face models that represent identity and expression, often used to control facial geometry and expressions. "leverages 3D morphable models (3DMM)~\citep{bfm} as an intermediate representation for the non-verbal facial expression."
- Adam optimizer: A widely used stochastic optimization algorithm combining momentum and adaptive learning rates. "We use the Adam optimizer~\citep{adam} with a learning rate of "
- autoregressive model: A model that predicts the next output conditioned on previous outputs and inputs, step by step over time. "This can be formulated as an autoregressive model as follows:"
- bidirectional DiT: A Diffusion Transformer variant with bidirectional attention over time, requiring access to both past and future context. "(a) Bidirectional DiT used in INFP~\citep{infp} requires access to the entire temporal window for motion generation."
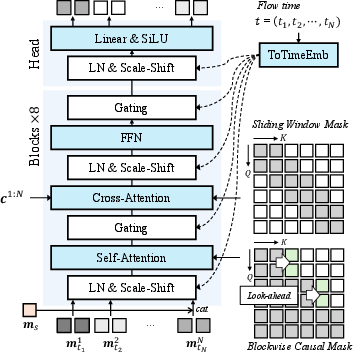
- blockwise causal structure: An attention layout that allows bidirectional attention within blocks while enforcing causal (past-to-future) constraints across blocks. "blockwise causal structure~\citep{causvid, ar_wo_vq}"
- blockwise look-ahead causal mask: An attention mask that permits limited peeking into future frames across blocks to smooth transitions while maintaining overall causality. "blockwise look-ahead causal mask "
- causal diffusion forcing: A sequential diffusion-based generation setup that enforces causality, enabling real-time, low-latency autoregressive sampling. "causal diffusion forcing~\citep{diffusion_forcing, causvid, streamdit}"
- classifier-free guidance: A technique to trade off fidelity and adherence to conditions during diffusion sampling by interpolating conditional and unconditional scores. "classifier-free guidance~\citep{classifier_free} scale of 2"
- cosine similarity of identity embeddings (CSIM): A metric measuring identity preservation by cosine similarity between face embeddings. "cosine similarity of identity embeddings (CSIM)~\citep{arcface}"
- cross-attention layer: An attention mechanism that attends from one sequence (e.g., avatar) to another (e.g., user signals) to fuse information. "aligns them through a cross-attention layer, which captures the holistic user motion."
- DiffusionDPO: An extension of Direct Preference Optimization to diffusion models using diffusion likelihoods for preference alignment. "DiffusionDPO~\citep{wallace2024diffusiondpo} extends DPO to diffusion models"
- diffusion forcing: A diffusion-based alternative to teacher forcing that predicts the next token conditioned on noisy past tokens for causal sequence generation. "Diffusion forcing~\citep{diffusion_forcing} stands out as an efficient sequential generative model"
- diffusion forcing transformer (DFoT): A transformer architecture tailored for diffusion forcing with causal/blockwise attention for sequential generation. "we adopt the diffusion forcing transformer (DFoT)~\citep{historydiffusion} with a blockwise causal structure"
- Direct Preference Optimization (DPO): A method to align models with preferences using pairwise comparisons without learning a separate reward model. "Direct Preference Optimization (DPO)~\citep{rafailov2023dpo} aligns a model with human preferences without explicitly training a reward model."
- dyadic motion generation: Modeling interactive behaviors of two participants (speaker and listener) in conversation. "dyadic motion generation~\citep{dim, infp, arig}"
- evidence lower bound (ELBO): A variational objective often used for likelihood-based training; here referenced as part of preference optimization for diffusion models. "enabling preference optimization using the evidence lower bound."
- Euler solver: A simple numerical ODE solver used to integrate the model’s vector field during sampling. "we use 10 NFEs with the Euler solver"
- flow matching: A training framework that learns a vector field to transport data between simple and complex distributions, related to continuous diffusion models. "we follow the noise scheduler of flow matching~\citep{cfm}"
- Frechet distance (FD): A distributional distance metric (here used for expression and pose) measuring similarity between generated and real features. "We measure Frechet distance (FD) for the expression and pose"
- Frechet Inception Distance (FID): A metric assessing image realism by comparing feature distributions of generated and real images. "Frechet inception distance (FID)~\citep{fid}"
- Frechet Video Distance (FVD): A metric assessing video realism/temporal coherence by comparing distributions of video features. "Frechet video distance (FVD)~\citep{fvd}"
- key-value (KV) caching: Reusing the attention keys/values from past tokens to speed up autoregressive inference. "reusing past information through key-value (KV) caching."
- lip sync error distance and confidence (LSE-C and LSE-D): Automatic metrics quantifying lip-speech alignment quality. "lip sync error distance and confidence (LSE-C and LSE-D)"
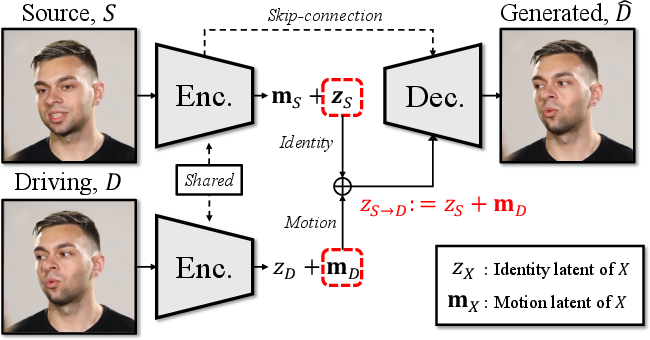
- motion latent auto-encoder: An auto-encoder that maps images to a latent space decomposing identity and motion for head avatar control. "we employ the motion latent auto-encoder from \citet{float}."
- motion latent space: A learned latent representation space capturing head motion and facial expressions, separate from identity. "motion latent space~\citep{megaportrait}"
- Number of Function Evaluations (NFEs): The count of ODE function evaluations used during sampler integration, affecting speed/quality. "we use 10 NFEs with the Euler solver"
- ODE timesteps: Discretized time points used by ODE solvers during diffusion/flow sampling. "ODE timesteps "
- Reinforcement Learning from Human Feedback (RLHF): A framework aligning models to human preferences using feedback, often via preference pairs. "Reinforcement Learning from Human Feedback (RLHF)~\citep{ouyang2022training}"
- residual Pearson correlation coefficients (rPCC): Correlation metrics (after removing confounds) measuring synchronization between user and avatar motions. "residual Pearson correlation coefficients (rPCC) on facial expression (rPCC-exp) and head pose (rPCC-pose)"
- Similarity Index for diversity (SID): A metric estimating the diversity/variety of generated motions. "Similarity Index for diversity (SID)~\citep{l2l}"
- sliding-window attention mask: An attention constraint restricting conditioning to a local temporal window for smoothness and efficiency. "sliding-window attention mask of size $2l$ along the time axis"
- teacher forcing: A training strategy where the model is conditioned on ground-truth previous tokens instead of its own predictions. "Diffusion forcing reformulates conventional teacher forcing in terms of diffusion models"
- vector field model: A function predicting the velocity/drift from noisy to clean latents in flow/diffusion frameworks. "modeled using a vector field model ."
- Wav2Vec2.0: A self-supervised speech representation model used to extract multi-scale audio features. "Wav2Vec2.0~\citep{wav2vec2}"
Collections
Sign up for free to add this paper to one or more collections.