- The paper presents a pipeline-centric taxonomy that evaluates 3D generative methods for the full asset lifecycle, aiming for production-ready results.
- It reviews various representations and generative paradigms, detailing the impact on topology, UV mapping, PBR materials, and engine compatibility.
- It identifies critical dataset gaps and evaluation shortcomings that currently hinder the deployment of fully interactive and realistic 3D assets.
Toward Production-Ready 3D Asset Generation for Interactive Worlds
Introduction and Motivation
The paper "From Visual Synthesis to Interactive Worlds: Toward Production-Ready 3D Asset Generation" (2604.23629) provides a comprehensive survey on the evolution of 3D generative modeling, focusing on the transition from visually plausible asset creation to production-grade content deployable in real-time interactive environments. Unlike prior surveys which are organized by algorithmic families, this work adopts a pipeline-centric taxonomy, scrutinizing each stage of the asset lifecycle against industry requirements for topology, UV parameterization, physically based materials (PBR), rigging, and scene-level interactivity. The analysis encompasses three asset tiers—general objects, characters, and scenes—and identifies the persistent "assetization bottleneck" that prevents current generative systems from achieving true production readiness.
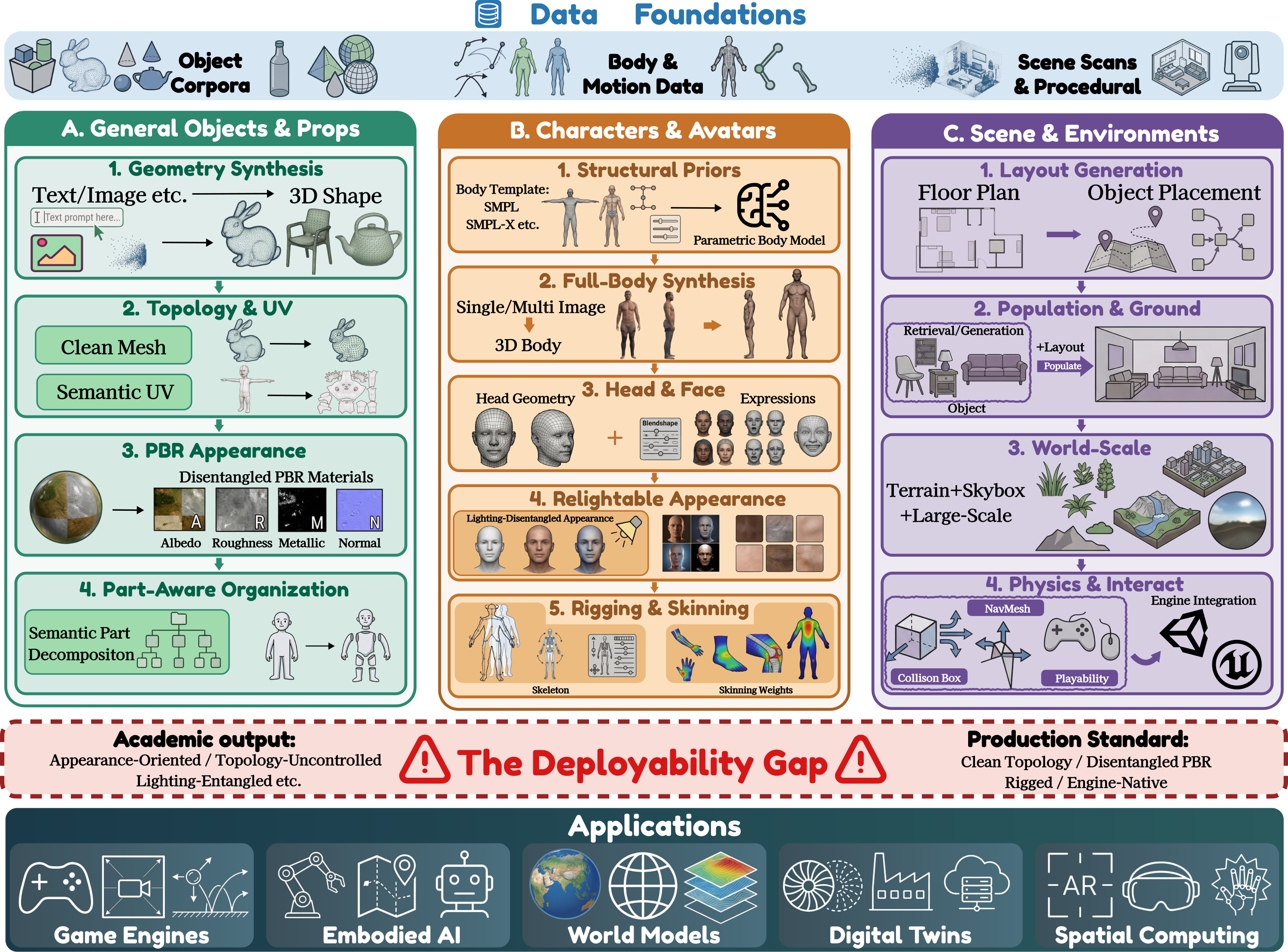
Figure 1: Pipeline-centric taxonomy bridging 3D synthesis and production-ready assets, delineating workflow stages and asset categories across a "bridge" separating academic visual fidelity and production requirements.
Method Taxonomies and Representational Foundations
A key contribution is the two-dimensional taxonomic structure spanning five branches: 3D representations, data foundations, geometry synthesis, appearance generation, and character/avatar/scene modeling. Principal representations include point clouds, voxel grids, meshes, neural radiance fields (NeRFs), implicit surfaces (SDFs), and hybrid embeddings such as mesh-anchored 3D Gaussian splatting. The survey details how representation choice dictates downstream controllability, topology regularity, animation compatibility, and game engine performance. Generative paradigms—variational autoencoding (VAE), adversarial (GAN, AR), diffusion, feed-forward, and latent flow—are reviewed for their impact on fidelity and deployment viability.
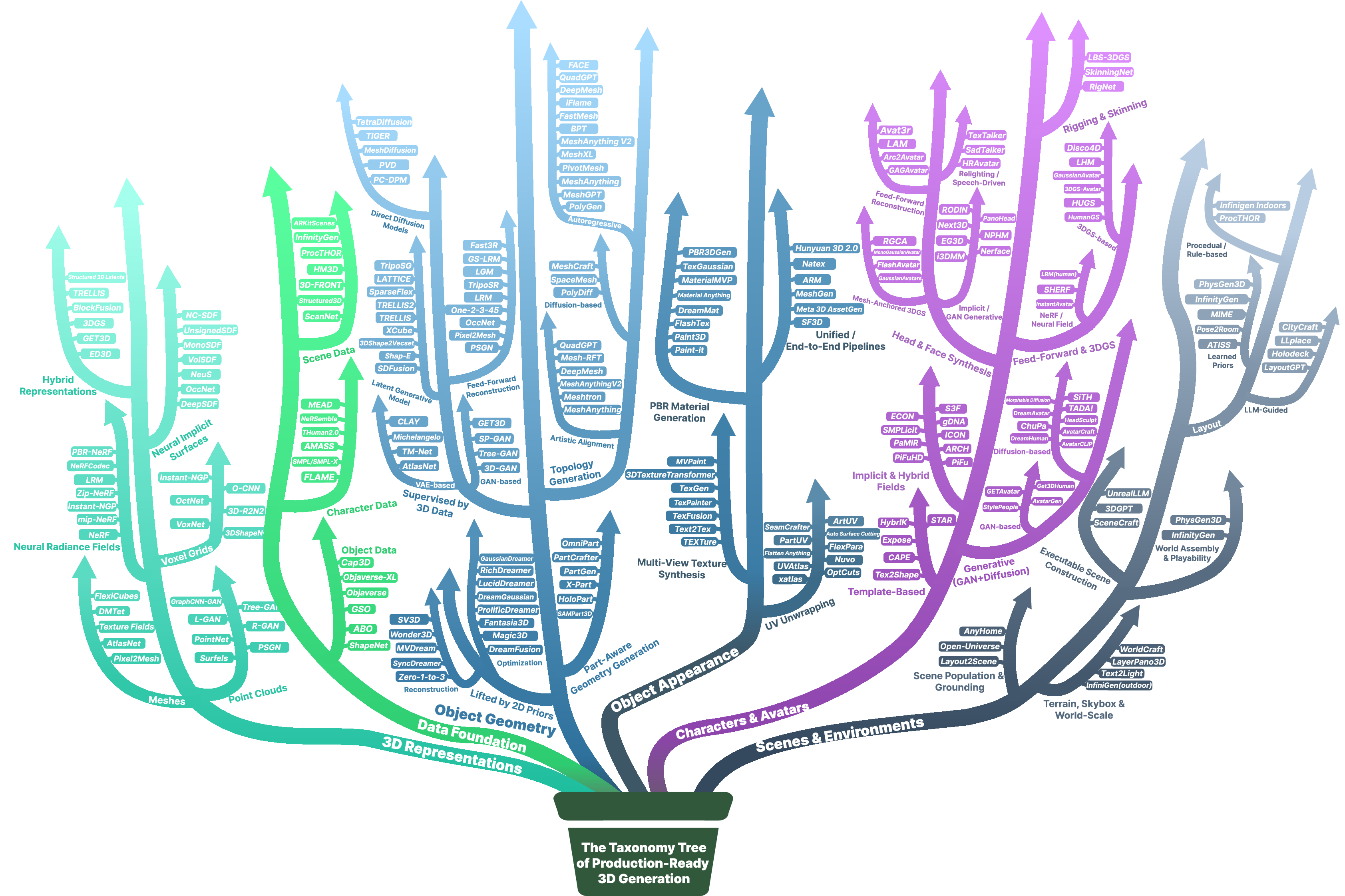
Figure 2: Method taxonomy tree—five survey branches, representative methods as leaves, illustrating the scope and modularity of production-ready 3D generative research.
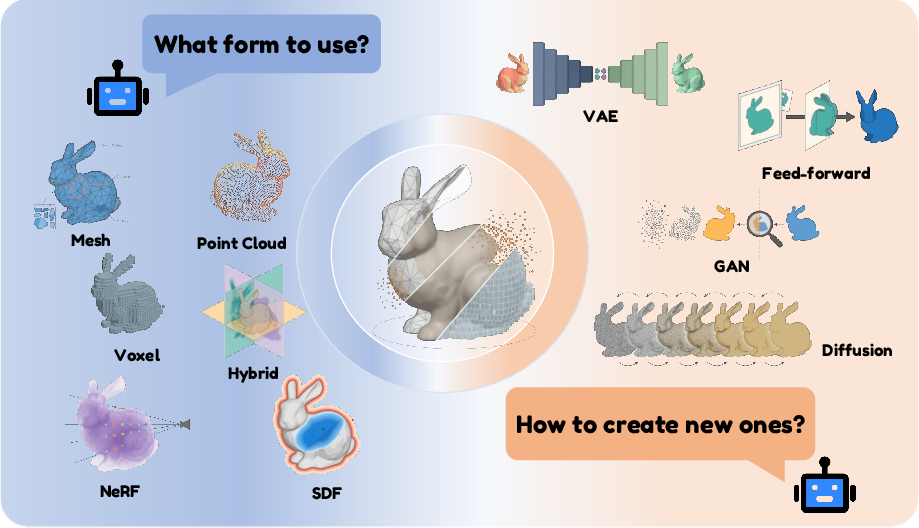
Figure 3: Taxonomy of 3D shape representations and generative modeling paradigms mapping physical, neural, and hybrid forms to learning objectives.
Data Foundations and Structural Gaps
The survey systematically profiles dataset landscapes across objects, characters, and scenes, distinguishing curated CAD repositories (ShapeNet, ModelNet, ABC), internet-scale aggregation (Objaverse, Objaverse-XL), PBR-complete small-scale sets (GSO, ABO), and real-world scene benchmarks (ScanNet++, Matterport3D). Scene-level corpora encompass synthesized (Structured3D, Hypersim) and procedural (ProcTHOR, Infinigen Indoors) environments. Four critical gaps emerge: (1) absence of topology-quality supervision in large datasets, (2) incomplete PBR material annotations, (3) lack of cross-asset style/scale coherence, and (4) missing standardized game-readiness benchmarks. These limitations directly constrain model training and controllable asset generation.
General Object and Prop Generation: Pipeline Analysis
Geometry generation methods are divided into 2D-prior-driven approaches (score distillation, multi-view diffusion) and 3D-data-supervised paradigms (GAN, VAE, diffusion, latent flow, feed-forward). Autoregressive and flow-based mesh generators are advancing toward direct topology synthesis, yet output mesh validity and artist-aligned edge loops remain a challenge. Representative feed-forward models (LRM, TripoSR, InstantMesh) achieve rapid single-image-to-3D reconstructions, while latent generative models (TRELLIS.2, SparseFlex, MeshCraft, TripoSG) scale spatial priors across billions of parameters for high-fidelity asset creation.

Figure 4: Single-image 3D reconstruction results on identical input—comparison of open-source models (TRELLIS.2, SF3D, InstantMesh, TripoSG) vs. closed-source commercial systems (Rodin Gen 1.5, Tripo V2.5, Hunyuan3D 3.1, Meshy 5), illustrating geometry and surface quality variance.
Topology generation remains a bottleneck, with indirect remeshing algorithms (InstantMesh, QuadriFlow) unable to ensure deformation-aware structure. Direct autoregressive (MeshGPT, PolyGen, MeshAnything) and diffusion-based approaches (Polydiff, MeshCraft, SpaceMesh) are improving edge flow and connectivity, especially with reinforcement-aligned artist preferences. Appearance generation now goes beyond texture painting, targeting UV unwrapping (ArtUV, PartUV, SF3D), chart packing, and physically disentangled PBR materials (Paint3D, MaterialMVP, SF3D). Multi-view-consistent, UV-aware, and relightable material synthesis are becoming standard production objectives.
Character and Avatar Generation: Toward Engine-Native Avatars
For characters, the survey emphasizes the need for parametric rig compatibility and nuanced surface detail. Full-body synthesis employs SMPL/SMPL-X priors (Tex2Shape, CAPE, TADA!), implicit fields (PIFu, ICON, ECON), GAN/diffusion pipelines (AvatarGen, DreamHuman, TADA!), and feed-forward real-time models (LHM, HumanGS, InstantAvatar). Deformable 3D Gaussian Splatting is increasingly favored for animatable, high-fidelity avatars (Disco4D, OmniAvatar, HunyuanVideo-Avatar).
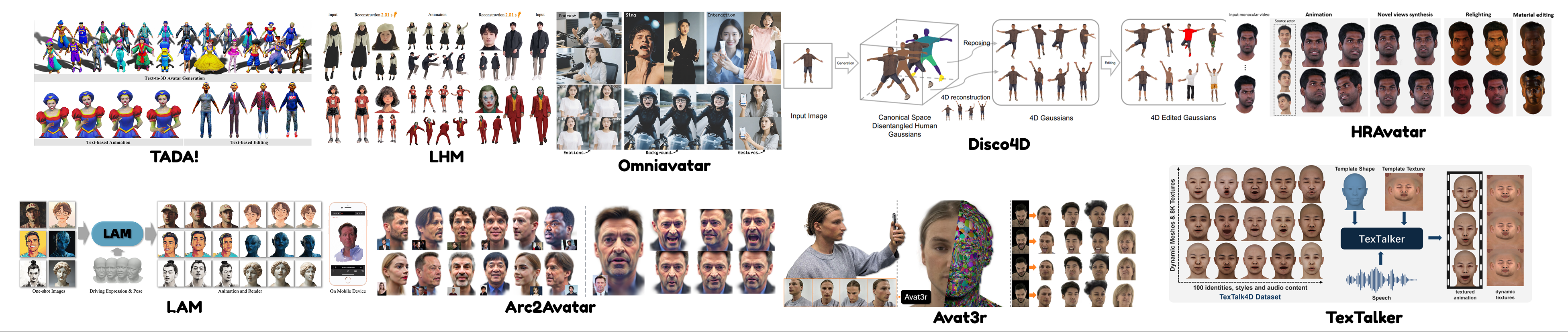
Figure 5: Character and avatar generation methods (2024--2025), showcasing full-body synthesis models and head/face generation, including feed-forward, Gaussian, and speech-driven animation pipelines.
Head and face synthesis is raised to a distinct problem with mesh-anchored Gaussians (FlashAvatar, HRAvatar, LAM) supporting blendshape animation and physically based relighting. Automatic rigging (RigNet, SkinningNet, DeePSD) bridges static generation to articulated animation, extending blendshape and skinning compatibility to arbitrary topologies and garment variants. Recent 3DGS models (LAM, HRAvatar) integrate learnable LBS matrices for direct engine import.
Scene and Environment Generation: Layout, Grounding, and Playability
Scene synthesis evolves from layout planning (ATISS, ProcTHOR, Holodeck) through retrieval-based population (AnyHome, Open-Universe), executable scripting (SceneCraft, UnrealLLM), to terrain and world-scale assembly (Infinigen Indoors, CityCraft, WorldCraft). Physics-aware objectives (PhyScene, PhysGen3D) increasingly enforce interactivity and stability, integrating layout diffusion with short simulation rollouts. Language-driven authoring interfaces (Holodeck, LayoutGPT, SceneCraft) couple intent specification with structured representations for engine export and iterative revision.
Evaluation Protocols, Metrics, and Benchmark Limitations
Current evaluation protocols are inadequate for deployment. Point cloud and perceptual metrics (CD, EMD, FID, CLIP) only assess appearance or geometric fidelity, neglecting topology validity, UV chart efficiency, PBR channel separation, rig robustness, and engine import success. Scene-level metrics for navigability, physical plausibility, and agent interaction are rare, often relegated to internal benchmarks or unreported. The absence of unified production-readiness benchmarks hinders systematic comparison and progress in assetization quality.
Open Challenges and Theoretical Implications
The survey delineates the following open directions:
- Data quality and diversity: No dataset provides full-scale, production-grade annotation (topology, UV, PBR, rig, language).
- Interactive controllability: Iterative asset editing, part-aware generation, and scene revision are still nascent.
- End-to-end assetization: The assetization bottleneck persists, as current systems fail to output directly deployable assets without manual intervention.
- Physical grounding: Most models lack explicit mass, friction, or articulation semantics essential for embodied AI and physics-based simulation.
- World model integration: Structured 3D serves as foundational infrastructure for simulation, digital twins, spatial computing, and emergent world models.
- Scale and efficiency: World-scale generation requires hierarchical, streaming, and memory-aware architectures.
- Societal and ethical concerns: Dataset provenance, ownership, deepfakes, and reproducibility are major community priorities as open-weight models migrate toward proprietary APIs.
Conclusion
This survey provides the most detailed mapping of the production pipeline in 3D generative research, establishing the asset lifecycle—from data, geometry, topology, UV, PBR, rig, to scenes—as a central organizing principle. The persistent gap between visual quality and deployment readiness is argued to be a structural bottleneck not solvable by algorithmic advances alone. Game engines and simulation platforms exert strict constraints on asset structure, interoperability, and usability, which most generative systems still neglect. Future research must focus on end-to-end, pipeline-integrated architectures that synthesize fully deployable assets from high-level specifications, thus establishing 3D generation as the infrastructure for intelligent, embodied, and interactive worlds.