Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Abstract: The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
First 10 authors:









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Hunyuan3D Studio, an AI “assembly line” that can turn a simple idea—like a text description or a single picture—into a full, game-ready 3D model. It doesn’t just make a pretty shape. It also does the technical steps artists usually spend hours on (cleaning the mesh, making UVs, creating textures, and setting up bones for animation) so the result can drop into game engines like Unity or Unreal with minimal extra work.
What questions does it try to answer?
- Can AI create high-quality 3D models that are not only nice to look at but also technically ready for real-time games?
- Can the whole process—from concept art to final, optimized 3D asset—be automated and controlled in one easy system?
- Can this speed up game development and make 3D creation easier for more people (not just experts)?
How did they do it?
The system works like a careful, step-by-step factory line. Each stage adds something important before passing the model along to the next stage. Here’s the pipeline in everyday terms:
- Concept images and style control
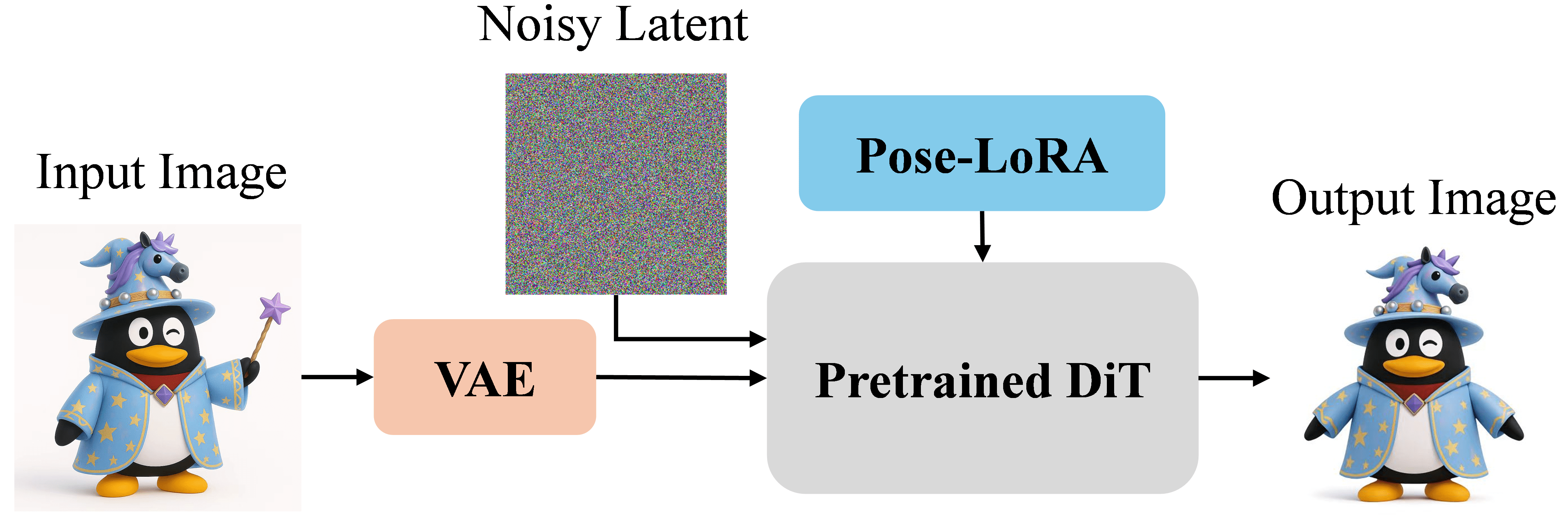
- Think of this like “filters” and posing tools. You give the system a text prompt or an image. It can restyle your image to match a game art style and standardize character pose (like switching to a common “A-pose” so later steps—like animation—are easier).
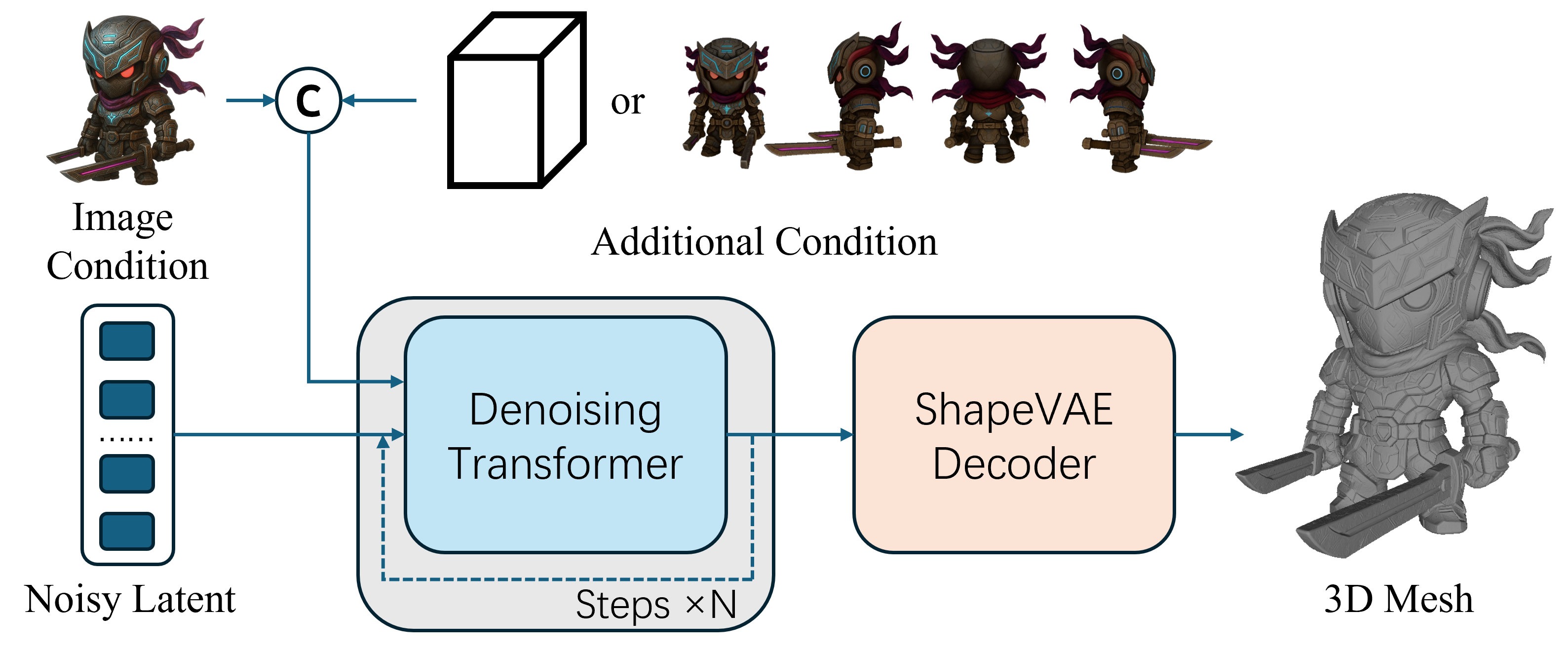
- Building the 3D shape (geometry)
- The AI looks at your image(s) and builds the object in 3D. It uses advanced “diffusion” models (imagine starting with a noisy blob and gradually sharpening it into a clean shape).
- You can guide size and proportions with a simple 3D box (like saying “fit the object inside this shoebox”).
- It can also generate extra views (front, side, back) from one image to understand the object better—like turning a statue to see all angles.
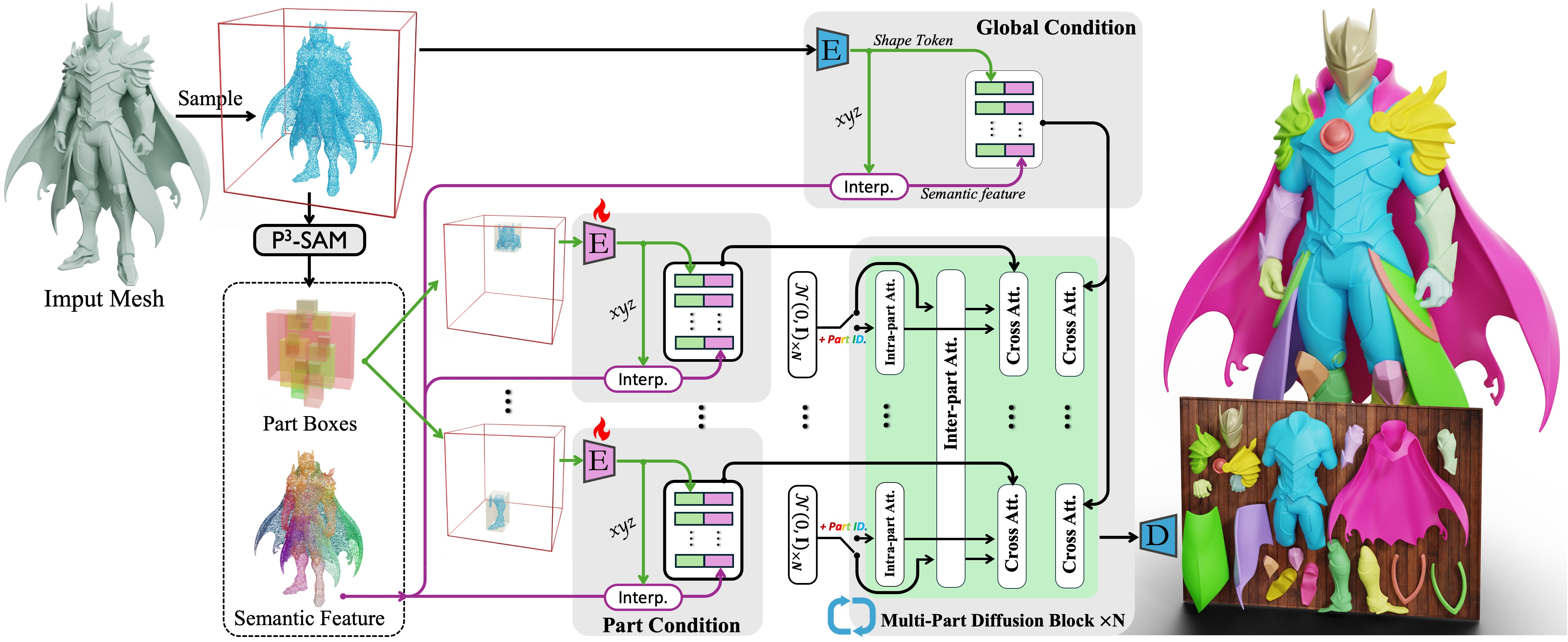
- Splitting into parts (part-level generation)
- Many objects are made of meaningful pieces (e.g., a chair: legs, seat, back; a robot: arms, torso, head). The system automatically detects and separates these parts so they’re easier to edit, texture, or animate later—like snapping a model into LEGO-like sections.
- Making a clean, game-ready mesh (polygon generation)
- Raw AI shapes can be “messy clay”—too dense and hard to work with. This stage “retopologizes” the model: it rebuilds the shape using fewer, better-placed polygons so it deforms nicely when animated and runs fast in games. Think: turning a scribbled sketch into clean line art.
- UV unwrapping with meaning (semantic UV)
- UVs are like cutting and flattening an orange peel so you can paint on it. The system predicts smart “cut lines” the way an expert would, grouping similar materials and using texture space efficiently. That means higher texture quality and fewer ugly seams.
- Texture creation and editing (PBR textures)
- PBR textures control how surfaces behave under light (metal vs. wood vs. skin). The AI can generate realistic texture sets (color, roughness, metalness, etc.) from your text or image, and you can refine them with simple language commands.
- Auto rigging for animation
- The system adds an internal “skeleton” (joints and bones) and sets how the surface moves with those bones. That makes the asset ready to animate in standard game engines.
Behind the scenes, all these modules share information through a unified “asset graph.” That means if you change something high-level (like overall size or style), the rest of the pipeline adjusts automatically without redoing everything from scratch.
What did they find?
- The system can turn a single concept (text or image) into a complete, polished 3D asset that meets strict, practical game requirements.
- The models look good and run efficiently:
- Cleaner meshes with fewer vertices and better edge flow (good for animation).
- Smarter UVs that reduce stretching and waste less texture space.
- High-quality, physically based textures that look realistic in real-time.
- The part-level tools produce editable, semantically meaningful pieces, which helps with customization and animation.
- Compared to previous methods, their modules (for parts, polygons, and UV seams) generally perform better on standard tests, producing:
- More accurate part splits,
- Better mesh topology (fewer errors, more complete and connected surfaces),
- More artist-like UV seams with lower distortion.
Why this matters: These steps—retopology, UVs, textures, rigging—usually take a lot of expert time. Automating them well saves weeks and opens 3D creation to smaller teams and beginners.
What’s the impact?
- Faster game development: Teams can go from idea to in-engine assets much quicker, speeding up prototyping and iteration.
- Lower barrier to entry: Non-experts can create production-quality 3D models without mastering many specialized tools.
- Consistent quality: Because the pipeline handles technical details, assets are more likely to “just work” in Unity/Unreal.
- Flexible creativity: Since parts are editable and the style is controllable, artists can experiment more and refine quickly.
Simple caveats and future directions:
- Very complex or unusual designs may still need a human touch for final polish.
- Expanding to full scenes, crowds, or highly dynamic objects could be the next step.
- Deeper integration with game engines and more interactive controls would make the workflow even smoother.
In short, Hunyuan3D Studio is like an all-in-one AI workshop that turns your ideas into game-ready 3D assets—clean, efficient, and beautiful—while saving a lot of time and effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues and concrete opportunities for future research arising from the paper.
- End-to-end validation in game engines is missing: there are no quantitative metrics on engine-side performance (frame time, draw calls, texture memory, streaming behavior, shader permutations) across Unity/Unreal, nor measurements under platform budgets (PC/console/mobile). Action: benchmark generated assets in representative scenes with LODs, lightmaps, and instancing.
- Asset “game-readiness” is asserted but not operationalized: the paper does not report standardized technical quality metrics (manifoldness, non-manifold edge/vertex ratios, self-intersection rate, genus/connected components, water-tightness, triangle/vertex counts, average/median face aspect ratio). Action: publish an asset QA suite and thresholds per category.
- No end-to-end latency and throughput reporting: time and compute per asset across modules, interactive editing latency, and failure/rollback rates are absent. Action: profile and report module-wise and pipeline-wise runtimes under different hardware budgets.
- Geometry conditional generation lacks robustness analysis: failure modes for occlusions, cluttered backgrounds, image noise, extreme foreshortening, and category shifts (organic vs. mechanical) are not quantified. Action: controlled stress tests and error taxonomy.
- Reliance on generated multi-view images introduces compounding error without calibration: identity drift, multi-view consistency, and artifact propagation into 3D are unmeasured. Action: measure multi-view consistency (e.g., feature alignment across views, silhouette/normal consistency) and their downstream 3D impact.
- Bounding-box conditioning strategy is under-specified: effect of training-time misalignments on fidelity and user control is not quantified; sensitivity to box aspect ratios, axis offsets, and scale errors is unknown. Action: perturbation studies and user-in-the-loop box editing experiments.
- Pose standardization lacks quantitative identity preservation: no metrics for subject consistency (face identity, clothing details) post A-pose normalization, background/prop removal accuracy, or robustness to extreme poses. Action: identity embedding similarity, segmentation IoU, and occlusion-dependent success rates.
- Part segmentation dataset quality is unverified: the 3.7M auto-annotated meshes lack label accuracy estimates, noise characterization, category coverage, and public availability for replication. Action: publish sampling procedures, label noise audits, per-class quality reports, and a reproducible annotation pipeline.
- P3-SAM automatic prompting via FPS may miss thin/small parts: there is no sensitivity analysis for prompt density, NMS thresholds, and part granularity vs. recall of fine components. Action: adaptive prompt sampling tuned to curvature/thin structures and threshold ablation.
- Segmentation and decomposition under non-manifold, scanned, or noisy meshes are not evaluated: Toys4K is used for UV benchmarks but part segmentation/decomposition behaviors on real-world problematic meshes remain unknown. Action: evaluate on non-manifold and noisy scans with specific metrics (part recall, over-/under-segmentation).
- X-Part semantics and structural coherence lack articulation-aware evaluation: internal structures, articulated joints, hierarchical part relations, and assembly constraints are not assessed. Action: benchmark on articulated datasets (e.g., PartNet-Mobility) and report joint localization accuracy, part connectivity and kinematic validity.
- Control via bounding boxes for X-Part is underspecified: how box placement errors affect part boundaries and semantic correctness is unknown, especially for occluded or partially visible parts. Action: systematic bounding-box perturbation and confidence estimation for part decomposition.
- PolyGen does not guarantee manifold/watertight topology: there are no explicit constraints or post-processes to prevent self-intersections, cracks, T-junctions, and non-manifold edges; metrics are not reported. Action: add topological validators and publish topology health metrics (boundary edge ratio, component count, self-intersection rate).
- PolyGen tokenization (BPT) may bias toward high-degree vertices and tri-only meshes: generalization to quad-dominant meshes, mixed tri/quad assets, subdivision surfaces, and CAD-like topology is unexplored. Action: extend tokenization to quad/patch representations and evaluate on CAD benchmarks.
- Preference metrics used in M-DPO are heuristic and under-defined: precise definitions of Topology Score, Boundary Edge Ratio, and how HD is computed for meshes are missing; threshold sensitivities and stability are not analyzed. Action: formalize metrics, run threshold ablations, and compare M-DPO to RL/self-training baselines.
- No quantitative comparison of PolyGen against strong SOTA on large-scale, high-complexity meshes: visuals are shown, but standardized metrics (mesh completeness, topology health, geometric deviation) and statistical significance across diverse categories are missing. Action: create a rigorous benchmark with numeric outcomes.
- UV seam generation focuses on distortion only: packing efficiency, island count, island area variance, texel density uniformity, seam length, overlap rate, and UDIM support are not measured. Action: add packing metrics and multi-channel UV (e.g., lightmap UV2) evaluations.
- Semantic UV claims “group surfaces by material type” but material classification is unreported: there is no pipeline description or quantitative verification for semantic grouping or texel density control. Action: integrate material tagging/classification and evaluate grouping accuracy and texel density targets per material class.
- Texture synthesis lacks PBR physical correctness evaluation: energy conservation, plausible BRDF parameter ranges, channel consistency (albedo/normal/roughness/metallic/AO/emissive), and cross-view consistency are not assessed. Action: measure material parameter distributions vs. measured datasets, check normal-albedo coherence, and validate shader outputs.
- Texture-editing control via language is not validated: controllability granularity, edit locality, preservation of prior details, and edit-to-render correspondence are not benchmarked. Action: user study and edit consistency metrics (before/after map diffs and render deltas).
- Animation/rigging module is largely unspecified: joint detection, skeleton topology, auto-skinning quality, retargeting, deformation under standard motion sets, and support for non-humanoids/mechanicals are not described or evaluated. Action: report quantitative rig quality (skinning error, volume preservation), skeleton correctness, and motion test outcomes.
- Deformation-aware edge flow claims are not backed by metrics: there is no evidence on edge flow aligned with principal curvature or improved deformation quality vs. baselines. Action: curvature alignment metrics and deformation error under canonical deformations.
- LOD generation and collision mesh creation are omitted: game-ready assets typically require LOD tiers and simplified physics colliders; pipeline coverage and quality are not discussed. Action: add automatic LOD/collider modules and evaluate impact on performance and physics accuracy.
- Engine material model compatibility is not validated: differences between Unreal (Metal/Rough) and Unity (Spec/Gloss variants), tangent-space conventions, mip/anisotropy settings, and color space management (linear vs. sRGB) are not documented. Action: cross-engine material export tests with render parity metrics.
- Error propagation across modules is not analyzed: how upstream errors (pose, multi-view drift, segmentation noise) affect downstream geometry, topology, UV, texture, and rig quality is unknown. Action: cascade error analysis and module-level robustness to upstream noise.
- Data provenance, licensing, and style/IP safety are not addressed: training data sources (3.7M meshes, images, textures) and safeguards against style appropriation, copyrighted content reproduction, and NSFW/unsafe outputs are unspecified. Action: document datasets, licenses, implement style filters and content safety detectors.
- Reproducibility is limited: many components rely on proprietary models; code, weights, datasets, and hyperparameters are not released. Action: provide open benchmarks, partial open-sourcing, and standardized interfaces to enable replication.
- Scalability and resource constraints are unclear: training uses 64 H20 GPUs; inference-time hardware requirements, memory footprints, and performance degradation under constrained hardware are unreported. Action: publish inference resource profiles and lightweight model variants.
- Category coverage and OOD generalization are not characterized: performance across asset types (characters, props, weapons, vehicles, foliage, architecture) and rare categories is unmeasured. Action: per-category benchmarks with failure analyses.
- Non-manifold and artist-grade mesh handling remains partially validated: while UV experiments include Toys4K, segmentation/decomposition/topology generation under artist-created non-manifold meshes are not comprehensively tested. Action: add artist-grade datasets across modules with targeted metrics.
- Integration with DCC tools (Blender/Maya/Houdini) is not described: naming conventions, hierarchy, vertex groups, material slots, and editability within standard tools are unspecified. Action: document DCC round-trip workflows and editability metrics.
- Safety and bias considerations for image/texture generation are missing: hallucination of biased content, NSFW filters, and geographical/style biases are not discussed. Action: introduce safety classifiers, bias audits, and opt-out mechanisms.
- User controllability across the pipeline is not formally evaluated: how high-level controls (text prompts, style, bounding boxes, seam length) translate into predictable outputs is unquantified. Action: controllability response curves and user studies for predictability.
- Multi-language and domain-specific prompts are not tested: prompt handling across languages and specialized art direction vocabularies (e.g., technical art terms) is unknown. Action: cross-language prompt evaluations and domain lexicon support.
- Baking and map generation from high- to low-poly meshes are not covered: normal/AO/curvature maps from high-poly sources and consistency with generated topology are not discussed. Action: add baking pipeline and consistency checks.
- Advanced materials (clearcoat, anisotropy, subsurface scattering, transmission) are not addressed: generation and validation of these parameters for modern PBR workflows are missing. Action: extend texture/material generation to advanced BRDFs and evaluate physically.
- Physics-ready assets (cloth/hair simulation, rigid bodies) are not supported: exporting physics properties and simulation-ready constraints are not discussed. Action: integrate physics parameterization and test in engine solvers.
- Dataset for multi-view image LoRA is under-specified: dataset size, category distribution, and annotation quality for multi-view conditioning are not provided. Action: publish dataset stats and assess diversity and bias.
- UV lightmap channel support is unclear: pipeline support for secondary UV channels optimized for light baking and their distortion/packing metrics are not reported. Action: add UV2 generation and evaluate lightmap bake quality.
- Versioning and provenance of generated assets are not covered: traceability of asset components (geometry, UV, textures, rig) through edits/revisions is missing. Action: implement and evaluate asset graph metadata/version control.
- Failure recovery and reversibility are not demonstrated: while reversibility is claimed, concrete mechanisms (incremental recomputation policies, dependency tracking) and empirical benefits are not shown. Action: measure recompute savings and correctness of incremental edits.
- Quantitative reporting gaps and placeholders exist: some tables contain “wait” placeholders and lack complete numeric results, undermining claims. Action: finalize and publish complete quantitative comparisons with statistical significance.
Collections
Sign up for free to add this paper to one or more collections.