Video Analysis and Generation via a Semantic Progress Function
Abstract: Transformations produced by image and video generation models often evolve in a highly non-linear manner: long stretches where the content barely changes are followed by sudden, abrupt semantic jumps. To analyze and correct this behavior, we introduce a Semantic Progress Function, a one-dimensional representation that captures how the meaning of a given sequence evolves over time. For each frame, we compute distances between semantic embeddings and fit a smooth curve that reflects the cumulative semantic shift across the sequence. Departures of this curve from a straight line reveal uneven semantic pacing. Building on this insight, we propose a semantic linearization procedure that reparameterizes (or retimes) the sequence so that semantic change unfolds at a constant rate, yielding smoother and more coherent transitions. Beyond linearization, our framework provides a model-agnostic foundation for identifying temporal irregularities, comparing semantic pacing across different generators, and steering both generated and real-world video sequences toward arbitrary target pacing.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
This paper is about making videos look smoother and more natural when they show something changing over time, like an object morphing into another. Sometimes, videos made by computers can change really quickly in one part and then slowly in another, making them look jerky or unnatural. This paper introduces a cool new way to fix that!
What's the Big Idea?
Imagine you're watching a video where a bead slowly turns into a bee. In some computer-generated videos, the bead might stay a bead for a long time, then suddenly, in just a few frames, poof! it's a bee. This paper's main goal is to make these kinds of transformations happen at a steady, even pace, so it looks like a smooth, magical change rather than a sudden jump.
What Problems Are They Trying to Solve?
The researchers wanted to figure out how to:
- Measure "meaning" change: How can we tell if the meaning or what's happening in a video frame is changing a lot or a little? They wanted a way to put a number on this "semantic progress."
- Spot the jerky parts: Once they could measure meaning change, they wanted to identify exactly where in a video the change was happening too fast or too slow.
- Smooth things out: After finding the jerky parts, they needed a way to automatically adjust the video so the rate of meaning change became constant. Think of it like evening out a bumpy road so your car drives smoothly.
- Work with different videos: They wanted their method to work for videos created by different computer programs, and even for videos from real life (like movies!).
How Did They Do It? (Their Secret Sauce)
The clever trick they came up with is called the "Semantic Progress Function" (SPF). Here's how it works, step-by-step, with some simple analogies:
- Breaking down frames into "meaning cards": Imagine each frame of a video (like a single picture) is given a special "meaning card" by a super-smart AI. This AI reads the picture and writes down a detailed description of what it sees, but not in words – it's more like a secret code of numbers that represents the meaning (they call these
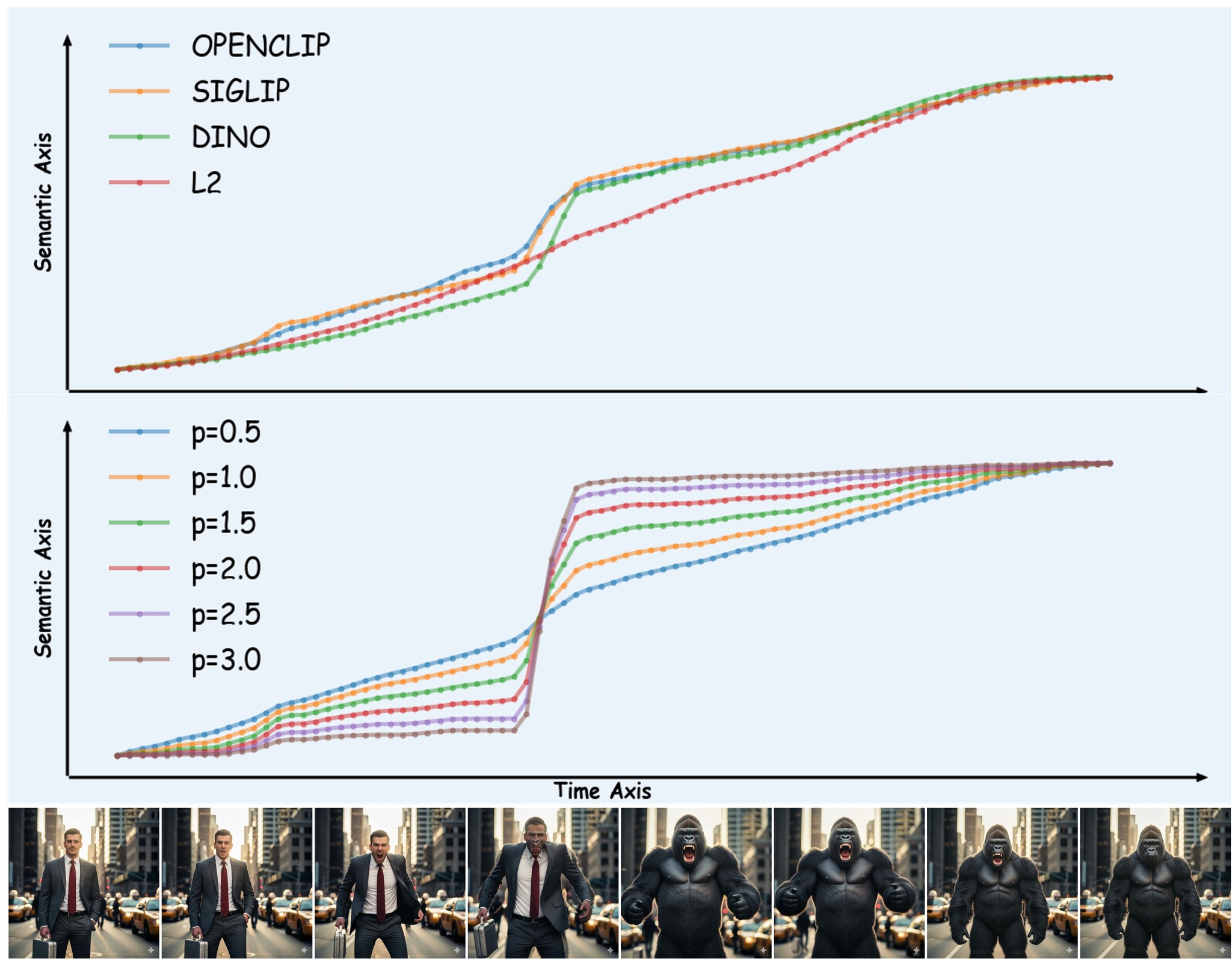
semantic embeddings). The paper uses a specific AI model calledSigLIPfor this, which is good at understanding image meanings. - Measuring "meaning distance": Next, they compare the "meaning cards" of nearby frames. If two frames are very similar (like two pictures of the same bead that\'s barely moved), their "meaning distance" is small. If one frame shows a bead and the next shows half a bee, the "meaning distance" is big! They calculate this by using a mathematical trick that measures how far apart these secret codes are, like finding the angle between two lines ().
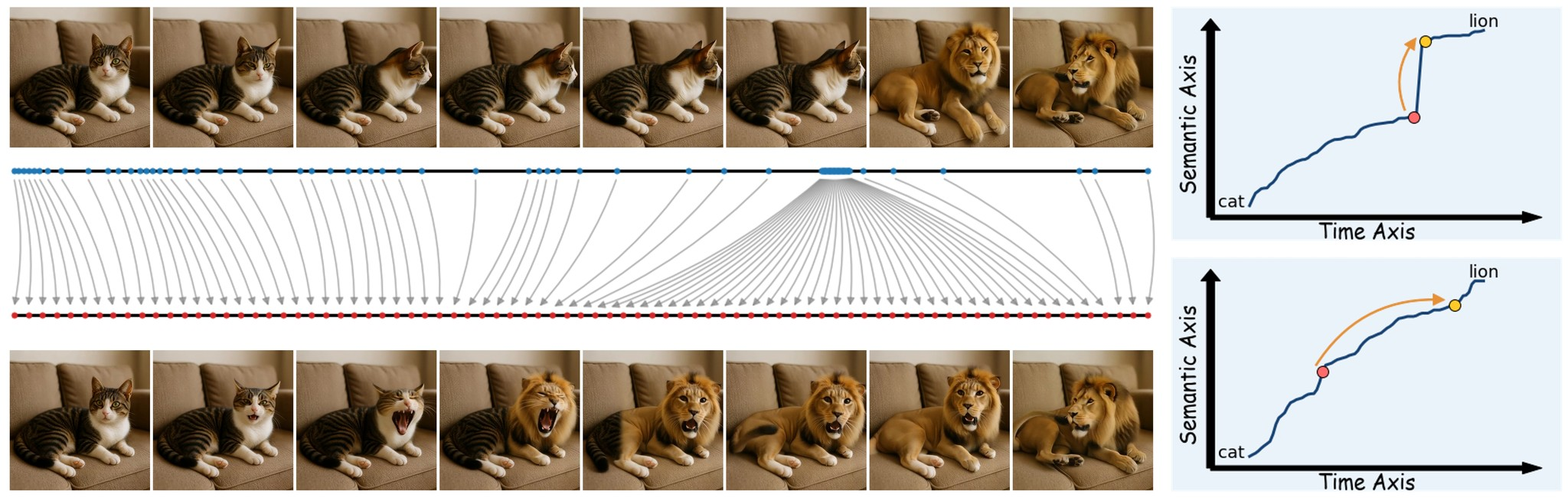
- Building the "progress graph": They then add up all these tiny "meaning distances" frame by frame to create a graph, like a timeline. This graph, the Semantic Progress Function (SPF), shows how much the meaning has changed cumulatively since the beginning of the video. If the line on this graph is flat, nothing much is changing. If it shoots up steeply, a big change just happened. If it's a perfectly straight line, the meaning is changing at a perfectly steady pace!
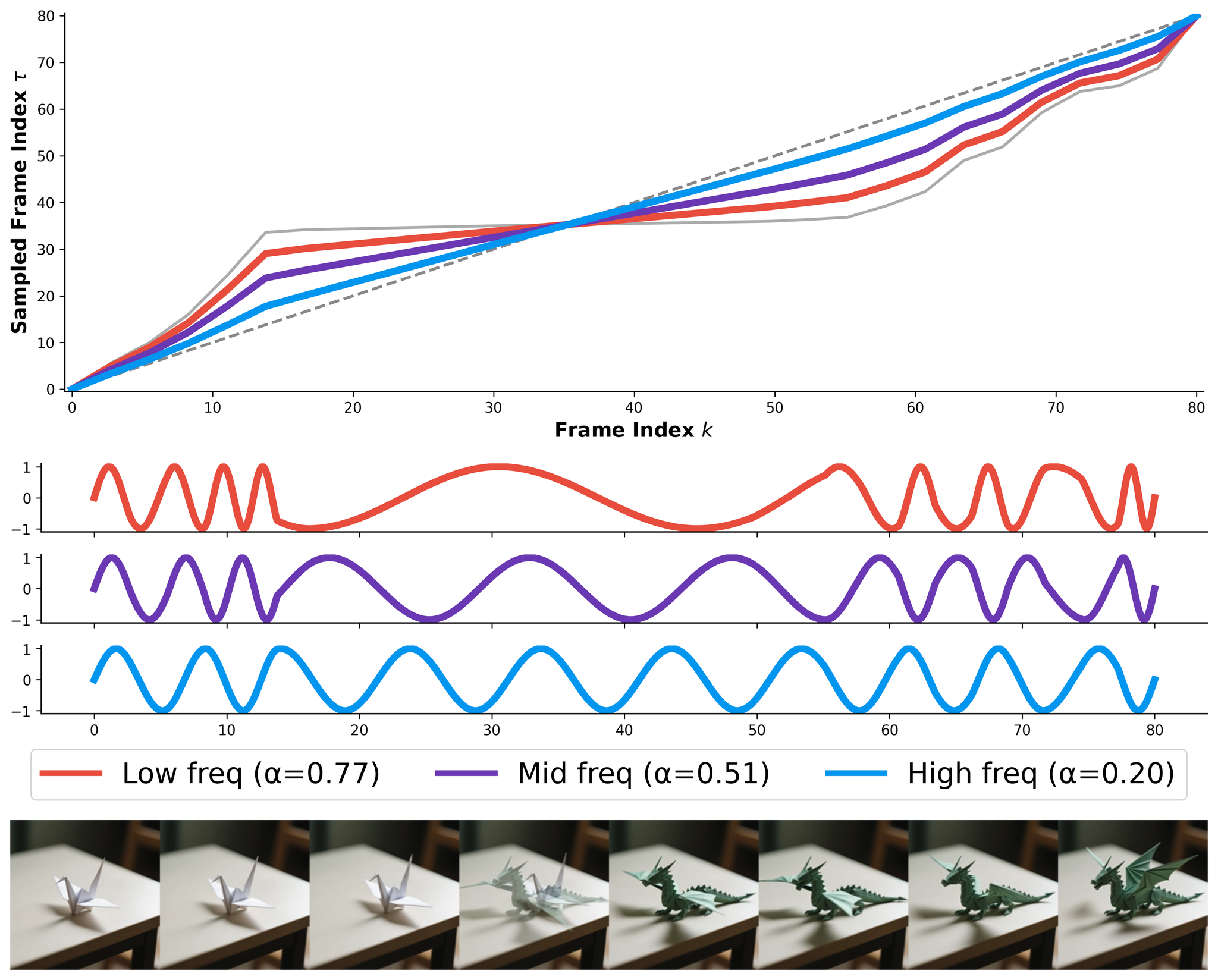
- Smoothing the bumpy road (Semantic Linearization): If their SPF graph isn't a straight line, it means the video isn't changing meaning smoothly. So, they figure out how to "re-time" the video.
- For computer-generated videos: They essentially tell the video-making AI, "Hey, this part changed too fast. Slow it down by adding more frames here. And this part changed too slowly, so speed it up by taking out some frames." They do this by cleverly adjusting the "time signals" (called
Rotary Position EmbeddingsorRoPE) that the AI uses to understand time. It's like having a stretching and shrinking rubber band for the video's timeline. They even adjust how much to stretch or shrink different "layers" of the video to keep everything looking natural. - For existing videos (like from a movie): This is a bit different. They first break the video into different sections based on the SPF graph (where the meaning changes at a somewhat steady pace). Then, for each section, they use a clever AI model to re-generate the clip, making sure the beginning and end of that section are still the same, but the transformation between them is now smooth and evenly paced according to the new SPF.
- For computer-generated videos: They essentially tell the video-making AI, "Hey, this part changed too fast. Slow it down by adding more frames here. And this part changed too slowly, so speed it up by taking out some frames." They do this by cleverly adjusting the "time signals" (called
What Did They Find Out?
The main findings are pretty awesome:
- The SPF works! It accurately measures how meaning changes in a video, much like a speedometer for semantic evolution. They proved this with simple test videos (like a rotating spot) where they knew exactly how fast the "meaning" should be changing.
- Smoother videos are better videos! By using their method to "linearize" the SPF (make it a straight line), they could make computer-generated transformations much smoother and more pleasant to watch. The "strawberry morphing into a bird" example shows how their method avoids blurry, ghost-like artifacts that other methods produce.
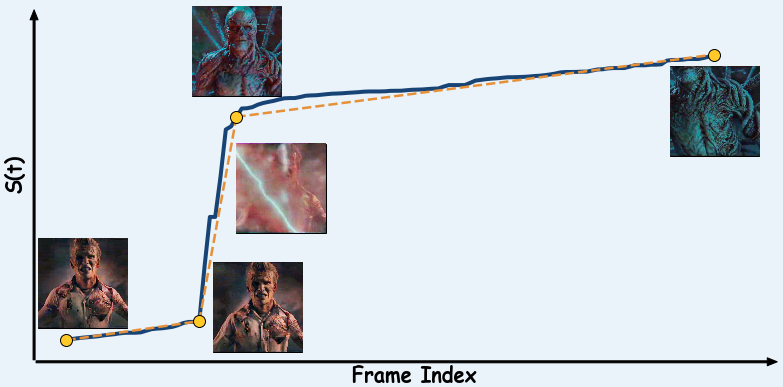
- It works on real movies too! They successfully applied their technique to a scene from "Stranger Things" where a character transforms (Vecna). The original scene had sudden, lightning-fast changes that could be jarring. Their method made the transformation much more gradual and natural-looking, revealing smooth intermediate stages.
- Quality is maintained: Importantly, the smoothing process didn't make the videos look worse in terms of graphics quality or motion. The numbers showed that the retimed videos were just as good as the originals in overall look and movement.
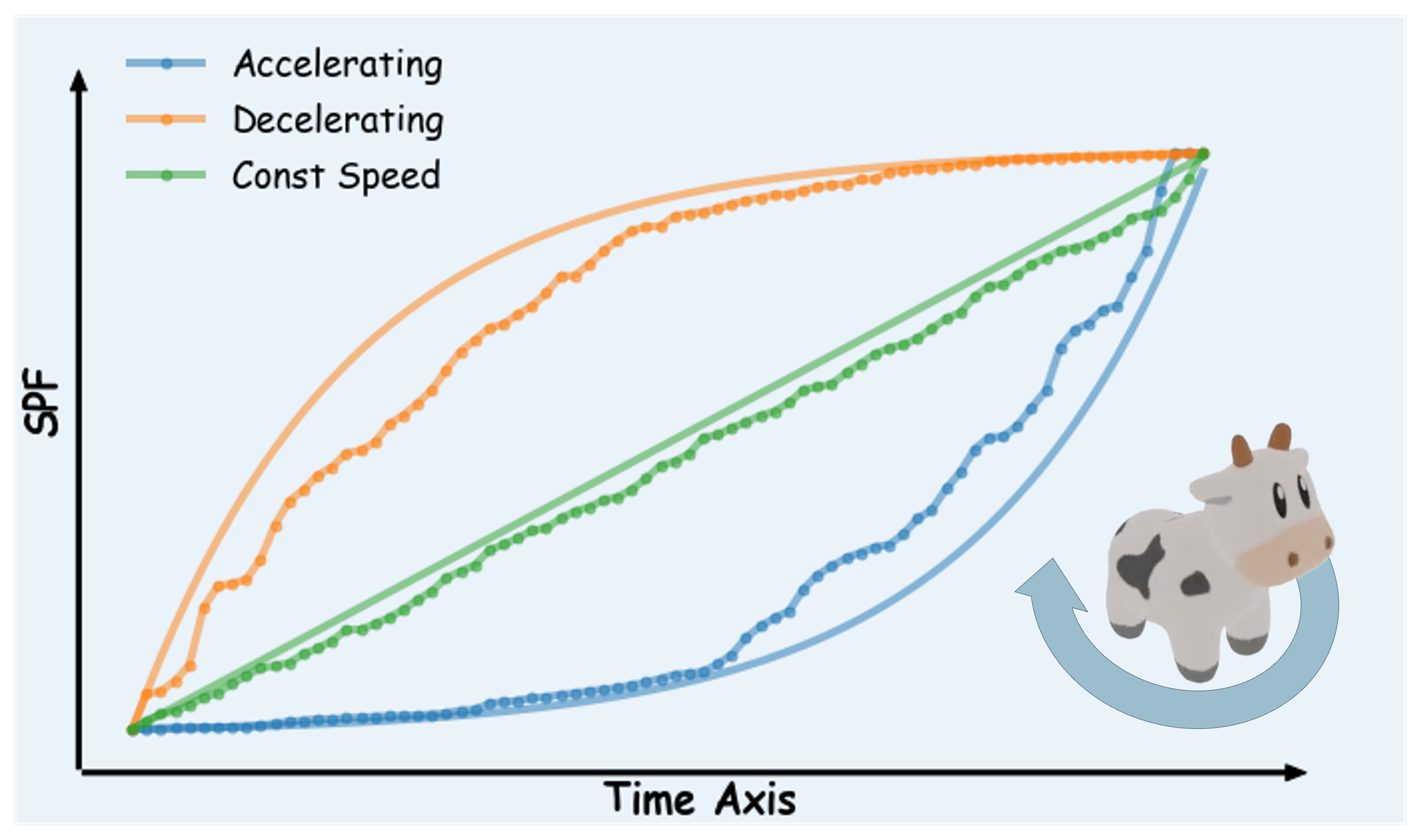
- You can change the pace deliberately: While they focused on making the pace constant, the SPF also lets you make things change faster or slower in specific ways, like an "exponential" speed-up or slow-down, shown with the sun appearing in a frame.
Why Is This Important?
This research is a big deal for anyone making or watching videos, especially those made by computers:
- Better AI-generated content: It helps AI models create more convincing and pleasing special effects, animations, and transitions. Imagine perfectly smooth morphs in movies or video games!
- More control for artists: Video creators can now have better control over how a transformation unfolds, making it easier to achieve their artistic vision without sudden, uncontrolled changes.
- Analyzing videos: It provides a new tool to understand and analyze how transformations happen in any video, whether it's generated or real. This could help identify interesting moments or improve how we summarize videos.
- Future AI training: By creating uniformly paced videos, this framework could also help train future AI models to naturally generate smoother transformations from the start.
In short, this paper gives us a powerful new way to understand and control the invisible flow of "meaning" in videos, making computer-generated transformations look much more magical and real.
Knowledge Gaps
The paper "Video Analysis and Generation via a Semantic Progress Function" introduces a novel Semantic Progress Function (SPF) to analyze and control semantic evolution in video sequences. While the SPF offers a valuable tool for identifying, measuring, and linearizing semantic pacing, the following knowledge gaps, limitations, and open questions remain unresolved in the presented work.
Methodological and Technical Open Questions
- Disentangling Camera Motion/Lighting from Semantic Change: The paper acknowledges that "rapid camera motion, strong lighting changes, or large non-semantic appearance variations that affect the embedding space" can influence the SPF, making it reflect perceptual change rather than pure semantic evolution. Future work needs to explore robust methods to disentangle these confounding factors from genuine semantic shifts to ensure the SPF solely captures meaning evolution. This could involve incorporating motion compensation, lighting normalization, or scene flow analysis prior to embedding computation.
- Robustness to Diverse Semantic Embedders: While the paper compares four embedders and selects SigLIP, a more extensive analysis of the SPF's sensitivity and performance across a broader range of semantic embedding models (e.g., specialized domain-specific embeddings, self-supervised methods trained on different modalities) is needed. Understanding how different embedding spaces impact the SPF's accuracy and granularity in various video contexts is a critical open question.
- Generalizability of Iterative Refinement and Distribution Shift: The iterative refinement process for retiming generated videos "progressively shifts temporal embeddings away from their trained distribution, which may degrade output quality if too many iterations are applied." The paper does not specify the threshold beyond which quality degrades or offer a principled method for mitigating this distribution shift. Future research could investigate adaptive iteration schemes, regularization techniques for temporal embedding warping, or methods to fine-tune generative models with knowledge of this warping for improved robustness.
- Optimizing Distance Power for Diverse Applications: The paper notes that increasing the distance power (via ) acts as a contrast modulator for the semantic curve and that yields superior segmentation for existing videos, while is a typical default. A systematic study is needed to understand the optimal selection of for different video types, semantic content, and downstream tasks. This could involve an automated hyperparameter tuning mechanism or a more detailed analysis of how influences the sensitivity of the SPF to subtle and abrupt changes.
- Handling Long-Term Semantic Dependencies: The SPF construction restricts pairwise distance computation to frames where for computational efficiency and to emphasize local temporal structure. This local focus might limit the SPF's ability to capture very gradual, long-term semantic changes or global narrative arcs in longer videos where semantic shifts unfold subtly over hundreds or thousands of frames. Exploring methods to incorporate broader temporal dependencies without significant computational overhead is an open question.
- Formalizing "Abrupt Jumps" and "Smooth Transitions": While the paper visually identifies "abrupt jumps" and "smooth transitions" in the SPF, a formal, quantitative definition for these characteristics is not provided. Developing metrics to quantify the degree of abruptness or smoothness—perhaps using local curvature or derivative analysis of the SPF—would enhance the analytical power of the framework.
- Benchmarking Non-Linear Retiming Against Other Dynamic Trajectory Models: The paper demonstrates non-linear retiming with exponential curves. A comprehensive evaluation of the SPF's capabilities for arbitrary non-linear pacing, possibly comparing it against other methods for controlling temporal dynamics (e.g., dynamic time warping, curriculum learning for temporal progression), would be beneficial.
Applications and Broader Impact Limitations
- Application to Highly Abstract or Non-Visual Semantic Changes: The SPF relies on visual semantic embeddings. Its applicability to videos where semantic changes are highly abstract, symbolic, or primarily auditory (e.g., a conceptual shift in a documentary, or a change in musical genre in a music video) is not explored. Future work could investigate integrating multimodal embeddings or symbolic representations for such scenarios.
- User Controllability for Fine-Grained Pacing: While the framework enables "arbitrary target pacing," the interface for users to define these arbitrary pacing functions is not discussed. Developing intuitive user interfaces or higher-level semantic controls (e.g., "slow down the hero's transformation," "accelerate the scene transition") based on the SPF would enhance practical utility.
- Cross-Model Comparison for "Semantic Stability": The SPF provides a "model-agnostic foundation for identifying temporal irregularities, comparing semantic pacing across different generators." While the paper qualitatively compares linearization results from different models (Wan2.2, LTX-2), a quantitative framework for comparing the inherent semantic stability or natural pacing consistency of different generative models using the SPF has not been fully explored. This could involve developing a "semantic rhythm" metric for generative models.
- Ethical Implications of Semantic Retiming: Manipulating the perceived temporal flow of real-world or generated videos, even for "linearization," could have ethical implications, particularly in journalistic or documentary contexts where altering the original pacing might misrepresent events. The paper does not discuss these potential ethical considerations.
- Integration with Existing Video Editing Workflows: The paper presents SPF as a diagnostic and corrective tool. Exploring how SPF and its derived retiming capabilities can be seamlessly integrated into professional video editing software or creative pipelines (e.g., as a plugin that suggests pacing adjustments) would be a worthwhile practical expansion.
Practical Applications
Immediate Applications
Below are actionable, sector-linked uses that can be deployed now, leveraging the paper’s Semantic Progress Function (SPF) analysis and ReTime generation/retiming methods.
- VFX, Film, and TV Post-Production
- Use case: Smooth, predictable morphs and transitions between key visual states; redistribute abrupt, lighting-driven changes into gradual evolutions.
- Tools/workflows:
- “Semantic Time Remapper” plugin for NLEs/compositors (Premiere, After Effects, Resolve, Nuke) that computes SPF, shows a Linearity Score, and auto-retimes using segmented regeneration or model-integrated RoPE warping.
- Shot QC panel that flags abrupt semantic jumps and proposes retime schedules.
- Dependencies/assumptions:
- Access to a video model with first–last frame or keyframe conditioning (e.g., Wan, LTX-Video/LTX-2) for regeneration, or access to the model’s temporal positional embeddings (RoPE) for inference-time warping.
- GPU resources for regeneration; SPF depends on vision embeddings (e.g., SigLIP). Strong camera/lighting changes may mislead semantics.
- Advertising, Marketing, and E-Commerce
- Use case: Evenly paced product reveals, logo morphs, and cinematic packshots; A/B test transitions using the SPF-based Linearity Score; ensure brand transitions meet platform pacing guidelines.
- Tools/workflows:
- Creative ops “Pace Inspector” that reports SPF curves, suggests retime presets (linear, ease-in/out, exponential), and batch-applies them to ad variants.
- Asset preflight checks that reject clips with excessive semantic jumps.
- Dependencies/assumptions:
- Integration with in-house or third-party T2V/video-editing models; prompt/keyframe conditioning must match brand assets.
- Embedding choice should align with the visual domain to avoid misranking due to lighting/camera motion.
- Social Media and Creator Tools
- Use case: One-click “constant-pace morph” for shorts/reels (before–after, style transitions, slideshow-to-video).
- Tools/workflows:
- Mobile app feature: SPF Analyze → pick target pacing curve → regenerate or resample via keyframes.
- Dependencies/assumptions:
- Compute budget on-device or in cloud; fair-use of model APIs; content moderation requirements.
- Game Development and In-Engine Cinematics
- Use case: Consistent pacing for cutscenes and in-engine transitions (e.g., character transformations, environment reveals).
- Tools/workflows:
- DCC integration to export SPF-derived retime curves applied to timeline tracks; if using generative video assets, apply RoPE warping during inference.
- Dependencies/assumptions:
- Engine support for timeline retiming; access to the underlying generator for inference-time warping if videos are synthesized.
- Audio-Video Co-Generation (where supported)
- Use case: Maintain AV sync while linearizing semantics in models like LTX-2 that generate audio and video jointly.
- Tools/workflows:
- Retiming schedules applied to temporal embeddings ensure generated audio follows the linearized visual pace automatically.
- Dependencies/assumptions:
- Requires a model that ties audio to the same temporal coordinates (e.g., shared positional embeddings); otherwise, external audio must be retimed.
- Academic and Industrial Model Evaluation
- Use case: Model-agnostic benchmarking of temporal semantics (SPF curve, Linearity Score); regression tests for pacing stability across model versions.
- Tools/workflows:
- “SPF Analyzer” CLI/API: computes progress curves, line charts, and scalar metrics; batch reports for different generators/prompts.
- Dependencies/assumptions:
- Reliable semantic embedding (SigLIP/CLIP/DINO); consistent preprocessing across test sets.
- Instructional/Education Content
- Use case: Evenly paced visual transformations in how-to and explainer videos; highlight where major conceptual changes occur.
- Tools/workflows:
- Auto keyframe extraction at equal semantic intervals for slide/video syncing; simple “semantic waypoint” markers on timelines.
- Dependencies/assumptions:
- Domain-appropriate embeddings (general models may not capture niche concepts); optional manual review for pedagogy.
- Robotics and Process Monitoring (vision-based)
- Use case: Track progress of visually evident tasks (assembly stage transitions, object state changes) and trigger alerts when progress stalls or jumps.
- Tools/workflows:
- On-edge SPF monitoring service that computes progress curves in a sliding window and raises events against expected pace profiles.
- Dependencies/assumptions:
- Stable camera, lighting, and pose; embeddings must reflect task-relevant state changes (may need domain tuning).
- Video Summarization and Thumbnailing
- Use case: Extract keyframes at equal semantic increments; generate thumbnails representing distinct stages of change.
- Tools/workflows:
- SPF-driven segmenter (segmented least squares) that returns boundaries and representative frames for summaries, previews, and storyboards.
- Dependencies/assumptions:
- Embedding stability under camera/lighting shifts; optional motion stabilization to improve robustness.
Long-Term Applications
These opportunities will benefit from further research, scaling, or productization beyond the current method.
- Training-Time Pace Control for Generative Models
- Use case: Train “edit strength–controlled” or constant-pace video generators by supervising with SPF signals or linearized morphs as training data.
- Potential products:
- Generators with a “semantic speed” slider; schedule-aware diffusion objectives that penalize non-linear progress.
- Dependencies/assumptions:
- Differentiable or curriculum-based integration of SPF; synthetic datasets of linearized morphs; careful alignment of embeddings and training objectives.
- Multi-Dimensional Progress Control (Identity/Style/Geometry)
- Use case: Disentangle and independently pace different semantic factors (e.g., preserve identity while accelerating style change).
- Potential products:
- Authoring UIs with separate progress curves per factor; per-factor retiming in video editors.
- Dependencies/assumptions:
- Factorized embeddings or supervised disentanglement; robust factor separation across frames.
- Motion-Aware and Domain-Specific Embeddings
- Use case: Improve robustness in dynamic scenes; deploy in specialized domains (e.g., sports, industrial inspection, medical).
- Potential products:
- Task-specific SPF backends (e.g., surgery phase embeddings, factory line stage embeddings) for monitoring and training.
- Dependencies/assumptions:
- Collect labeled domain data; integrate optical flow or temporal encoders; validate semantics vs. appearance variance.
- Real-Time or On-Device Retiming for AR/VR
- Use case: Apply semantic pacing control in immersive content pipelines to reduce discomfort from abrupt transitions and improve narrative flow.
- Potential products:
- Headset-side “semantic timewarp” middleware that adjusts transitions in live experiences.
- Dependencies/assumptions:
- Low-latency embeddings and inference; hardware acceleration; careful UX evaluation to avoid temporal artifacts.
- Standards, Policy, and Governance for Generative Media
- Use case: Establish pacing metrics for quality/accessibility guidelines (e.g., limit abrupt semantic jumps in ads or kid-focused media).
- Potential products:
- Open benchmarks and certification tests using SPF and Linearity Scores; compliance dashboards for platforms and advertisers.
- Dependencies/assumptions:
- Consensus on semantic pacing norms; transparency from tool vendors; versioning of metrics.
- Content Search, Retrieval, and Analytics
- Use case: Index large video corpora by semantic pace; query “where does transformation X start/peak/end?”; detect non-linear narratives.
- Potential products:
- Search APIs that return timeline segments based on progress thresholds; editorial analytics on pacing across a catalog.
- Dependencies/assumptions:
- Scalable embedding computation; metadata pipelines; robust handling of camera and appearance changes.
- Adaptive Compression and Streaming by Semantic Pace
- Use case: Allocate bitrate or frame rate dynamically to regions with high semantic change; improve perceptual quality at constant bandwidth.
- Potential products:
- “Semantic-VBR” encoders that use SPF to drive GOP structure and QP schedules.
- Dependencies/assumptions:
- Integration with codec control loops; real-time SPF estimation; validation of QoE gains.
- Advanced Robotics, Autonomy, and Digital Twins
- Use case: Use progress profiles for multi-step task verification, exception handling, and operator HCI (predictive timelines in dashboards).
- Potential products:
- Progress-aware supervisors that compare live SPF to expected templates; alarm systems for divergence.
- Dependencies/assumptions:
- Robust vision semantics under varying conditions; alignment between visual progress and task ground truth.
- Healthcare and Scientific Workflows (with specialized embeddings)
- Use case: Phase-aware pacing in didactic surgical videos or lab protocols; highlight semantic checkpoints for trainees.
- Potential products:
- Training content generators with controlled pace; auto-segmentation and feedback tools.
- Dependencies/assumptions:
- Clinically validated, domain-specific embeddings; strict privacy/compliance; careful definition of “semantic progress” in medical contexts.
Notes on Feasibility and Key Dependencies
- Embedding reliability: SPF quality depends on image/video embeddings (e.g., SigLIP, CLIP). Camera motion, lighting, and appearance shifts can confound “semantics.” For critical use, add motion compensation, local weighting (already used), or domain-tuned encoders.
- Access to generators: Inference-time RoPE warping requires access to the model’s temporal position encodings. If unavailable, use segmented regeneration via first–last or keyframe conditioning.
- Compute and latency: Regeneration adds GPU cost and latency; batch workflows and segment-level processing mitigate runtime for longer videos.
- Stability trade-offs: Excessive positional warping or too many refinement iterations can deviate from training distributions and degrade visual fidelity; schedules and iteration counts should be capped and validated.
- Audio alignment: Guaranteed only when the model ties audio to the same temporal coordinates; otherwise, external time-stretching or re-synthesis is needed.
- Legal/ethical: Adherence to model licenses, content rights, and platform policies; ensure accessibility and avoid inducing discomfort with aggressive retimes.
Glossary
Here is an alphabetical list of advanced domain-specific terms from the paper that an undergraduate computer science student might not know:
- Attention Control Mechanisms: Techniques used in deep learning models, particularly in diffusion models, to direct the model's focus to specific parts of the input data (e.g., image regions or semantic features) during the generation process, influencing the output. "DiffMorpher~\cite{zhang2023diffmorpher} and FreeMorph~\cite{cao2025freemorph} employ techniques such as LoRA-based fine-tuning and attention control mechanisms to ensure smooth semantic transitions without the need for extensive training on specific concept pairs."
- Bilateral Filter: A non-linear, edge-preserving smoothing filter that replaces the intensity of each pixel with a weighted average of intensity values from its neighborhood, where the weights depend on both spatial distance and intensity difference. "This parameter calibrates the semantic embeddings, which often preserve relative rank rather than absolute perceptual magnitude, analogous to a bilateral filter."
- Contrastive Learning: A machine learning approach where a model learns by comparing similar and dissimilar pairs of data points, pushing representations of similar items closer and dissimilar items further apart in an embedding space. "Specifically, we evaluate four representations: OpenCLIP (ViT-based contrastive), SigLIP (sigmoid loss contrastive), DINO (self-supervised), and a pixel-level baseline using distance."
- Cross-Attention Maps: Mechanisms within transformer models, often used in multimodal contexts (like text-to-video), that allow one modality (e.g., text prompt) to influence the processing of another modality (e.g., video frames) by assigning different weights to different parts of the input. "Techniques like TempoControl~\cite{schiber2025tempocontrol} introduce temporal attention guidance, which explicitly manipulates cross-attention maps to align specific video frames with distinct parts of the text prompt."
- Diffusion Denoising Process: The iterative process in diffusion models where random noise is gradually removed from an input to refine it into a coherent image or video, typically transitioning from coarse structure to fine details. "The diffusion denoising process transitions from coarse structure (high noise) to fine details (low noise)."
- Diffusion Models: A class of generative models that learn to reverse a diffusion process, gradually transforming noise into data (images, videos, etc.), often producing high-quality and diverse outputs. "Most recently, Diffusion Models have become the state-of-the-art for morphing."
- Feature-Based Image Metamorphosis: A classical image morphing technique that relies on user-defined features (e.g., line segments or points) to establish correspondence between two images, which are then warped and blended to create a transition. "Feature-Based Image Metamorphosis~\cite{beier1992feature} utilized line segments to define correspondence fields, though they often required laborious manual annotation."
- First-Last Frame Conditioning: A technique in video generative models where the generation of a video sequence is constrained by specific start and end frames, guiding the model to produce a coherent transition between these two points. "A critical capability for morphing applications within VDMs is "first-last frame" conditioning, as seen in models like Wan~\cite{wan2025} and LTX-Video~\cite{HaCohen2024LTXVideo}."
- Generative Adversarial Networks (GANs): A class of deep learning models consisting of two neural networks, a generator and a discriminator, that compete against each other to generate realistic data. "Generative Adversarial Networks (GANs), such as StyleGAN, demonstrated that traversing the latent space of a generator could yield smooth image sequences \cite{karras2019style}."
- Latent Space Interpolation: The process of generating intermediate data points by moving along a path within the learned compressed representation (latent space) of a generative model, often resulting in smooth transitions between different outputs. "The advent of Deep Learning shifted the paradigm from geometric warping to latent space interpolation."
- LoRA-based Fine-tuning (Low-Rank Adaptation): A parameter-efficient fine-tuning technique for large pre-trained models, where a small number of new low-rank matrices are added to the model's layers and trained, rather than updating all original model parameters. "DiffMorpher~\cite{zhang2023diffmorpher} and FreeMorph~\cite{cao2025freemorph} employ techniques such as LoRA-based fine-tuning and attention control mechanisms to ensure smooth semantic transitions without the need for extensive training on specific concept pairs."
- Moving Least Squares (MLS): A method used for interpolating or approximating functions from a set of scattered data points, commonly applied in graphics for deformations and image warping due to its ability to produce smooth mappings. "Moving Least Squares (MLS)~\cite{schaefer2006image} eventually became a gold standard for deformation, producing smooth mappings from sparse control points."
- One-Dimensional Trajectory: A representation of movement or evolution along a single axis or dimension, often used to simplify complex, high-dimensional processes for analysis. "By reducing a complex transformation to a one-dimensional semantic trajectory, the proposed framework makes it possible to explicitly measure semantic pacing, identify abrupt transitions, and compare temporal behavior across different generative processes in a model-agnostic manner."
- Pixel2style2pixel (pSp) Encoders: An encoder type developed for StyleGANs that maps real images into the GAN's latent space, enabling the manipulation and editing of real images using the StyleGAN's capabilities. "To apply these capabilities to real images, inversion techniques such as deep generative priors and pixel2style2pixel (pSp)~\cite{richardson2021encoding, tov2021designing, alaluf2021restyle} encoders were developed to project images into the GAN latent space for manipulation."
- Positional Embeddings: Vectors added to the input embeddings in transformer models to provide information about the position of tokens in a sequence, allowing the model to understand order and sequence structure. "We therefore regenerate the sequence with an explicit retiming mechanism that warps the model’s temporal positional encodings according to the measured progress curve, allocating more temporal capacity to semantically dense regions and less to stable ones."
- Reparameterize: To change the underlying parametrization of a function or a sequence while preserving its essential properties, often done to achieve a desired behavior (e.g., constant rate of change). "Building on this analysis, we propose semantic linearization, a method that reparameterizes the sequence so that semantic progress increases at a constant rate."
- Rotary Positional Embeddings (RoPE): A type of positional encoding for transformer models that applies frequency-dependent rotations to query and key vectors, allowing for flexible and efficient encoding of relative position information. "Modern video diffusion transformers such as Wan~\cite{wan2025} employ Rotary Position Embeddings~\cite{su2023roformerenhancedtransformerrotary} along the temporal axis."
- Segmented Least Squares: A method for fitting a series of line segments to data points, minimizing the sum of squared errors within each segment while potentially applying a penalty for the number of segments, useful for identifying piecewise linear trends. "Given the semantic progress function over discrete frames , we apply segmented least squares to partition into contiguous, approximately linear segments such that..."
- Self-Supervised Learning: A type of machine learning where the model learns from data that is automatically labeled from the input itself, often by predicting missing parts or transformations of the input, without explicit human annotations. "Specifically, we evaluate four representations: OpenCLIP (ViT-based contrastive), SigLIP (sigmoid loss contrastive), DINO (self-supervised), and a pixel-level baseline using distance."
- Semantic Embeddings: Numerical representations (vectors) of the meaning or semantic content of data (like images or text) in a high-dimensional space, where semantically similar items are represented by points that are close to each other. "For each frame, we compute distances between semantic embeddings and fit a smooth curve that reflects the cumulative semantic shift across the sequence."
- Spatial Transformer Network (STN): A neural network module that can perform spatial transformations (e.g., scaling, rotation, translation) on data within a larger deep learning architecture, allowing for invariant feature learning. "Works focusing on perceptual constraints and Spatial Transformer Network (STN) alignment further refined these transitions~\cite{fish2020image}."
- Time Embedding Intervention: The act of directly manipulating or "warping" the temporal positional embeddings used by a generative model during inference, typically to alter the pacing or timing of the generated sequence. "We begin by comparing our method against baseline retiming strategies, demonstrating the advantages of time embedding intervention."
- VAE (Variational Autoencoder): A type of generative model that learns a compressed, probabilistic representation (latent space) of data, capable of generating new data points by sampling from this latent space. "For models using 4 temporal compression (e.g., Wan's VAE), latent step 1 corresponds to frame 1, while latent step () corresponds to the center of frames , i.e., frame index $4i - 1.5$."
- VBench: A benchmark or evaluation framework designed to assess the quality and performance of video generation models using a suite of quantitative metrics. "We assess this using VBench~\cite{ji2024t2vbench} quality metrics, with quantitative results summarized in Table~\ref{tab:vbench_regen}."
Collections
Sign up for free to add this paper to one or more collections.