Video-As-Prompt: Unified Semantic Control for Video Generation
Abstract: Unified, generalizable semantic control in video generation remains a critical open challenge. Existing methods either introduce artifacts by enforcing inappropriate pixel-wise priors from structure-based controls, or rely on non-generalizable, condition-specific finetuning or task-specific architectures. We introduce Video-As-Prompt (VAP), a new paradigm that reframes this problem as in-context generation. VAP leverages a reference video as a direct semantic prompt, guiding a frozen Video Diffusion Transformer (DiT) via a plug-and-play Mixture-of-Transformers (MoT) expert. This architecture prevents catastrophic forgetting and is guided by a temporally biased position embedding that eliminates spurious mapping priors for robust context retrieval. To power this approach and catalyze future research, we built VAP-Data, the largest dataset for semantic-controlled video generation with over 100K paired videos across 100 semantic conditions. As a single unified model, VAP sets a new state-of-the-art for open-source methods, achieving a 38.7% user preference rate that rivals leading condition-specific commercial models. VAP's strong zero-shot generalization and support for various downstream applications mark a significant advance toward general-purpose, controllable video generation.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
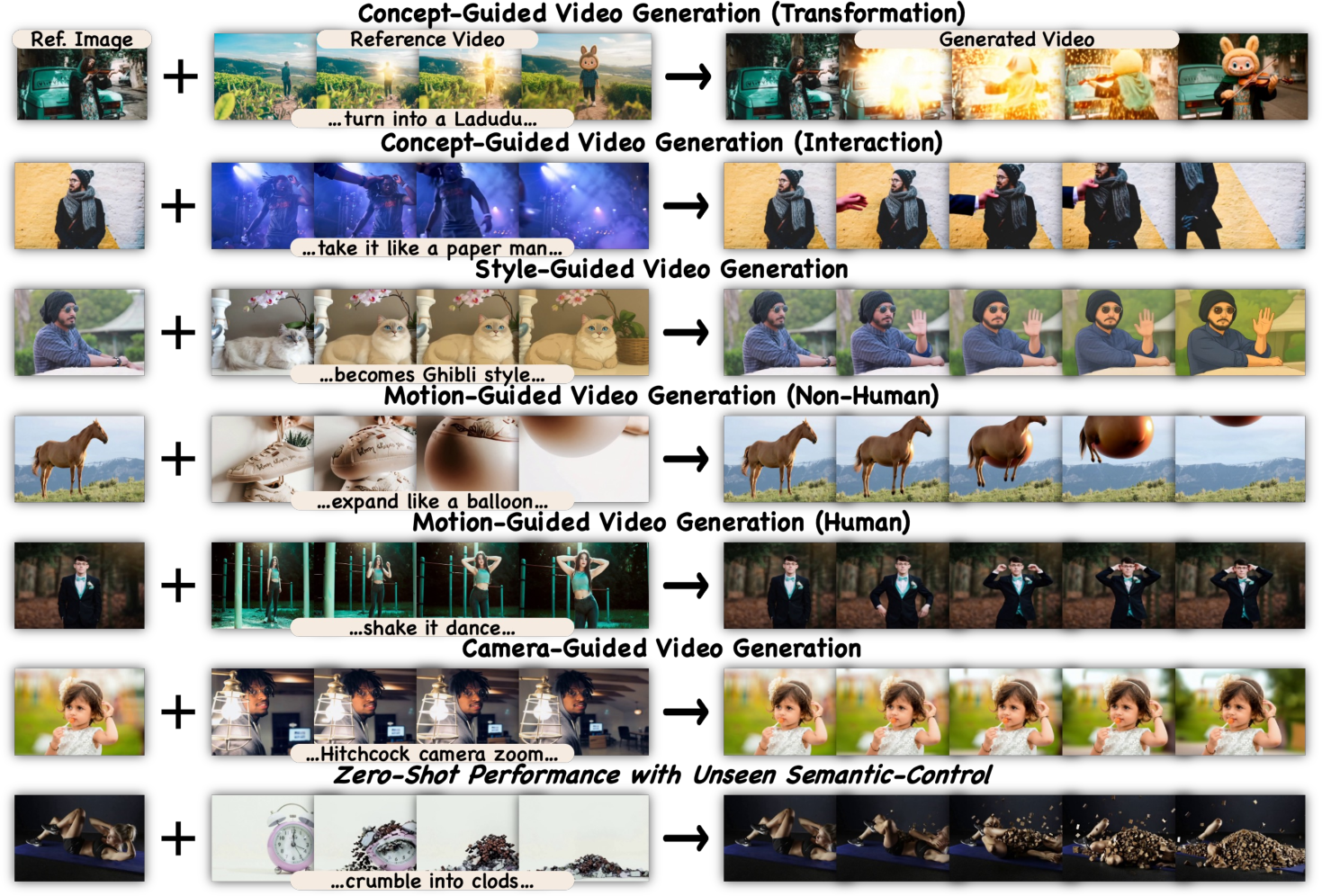
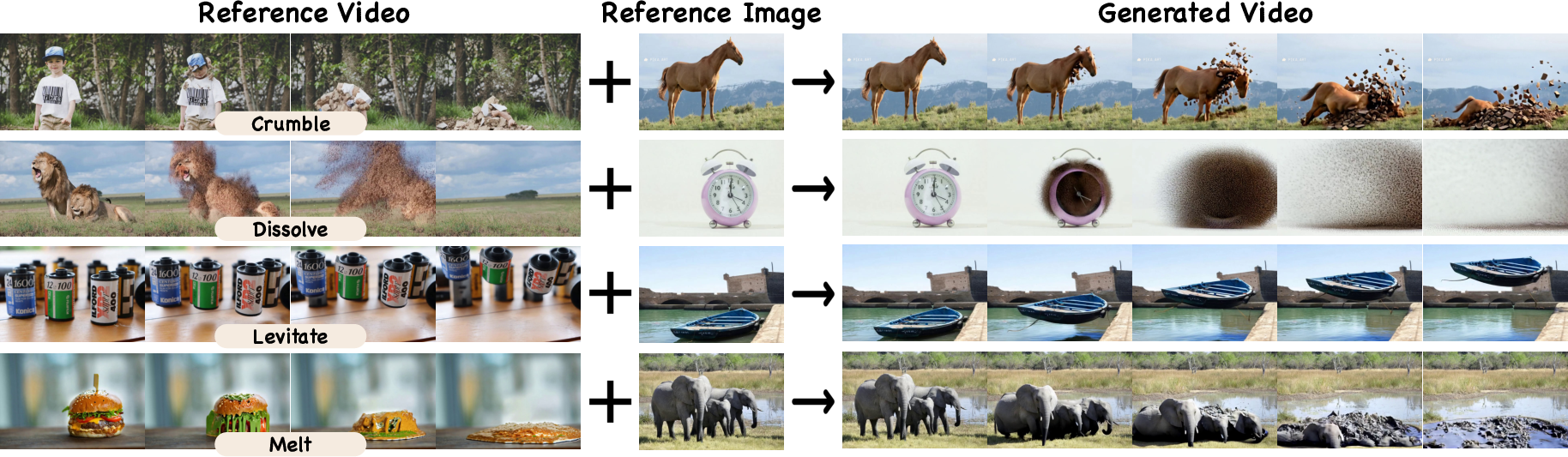
This paper introduces a new way to control what AI-made videos look like, move like, and feel like. It’s called Video-As-Prompt (VAP). Instead of giving the AI special, tightly matched inputs like depth maps or poses (which line up pixel-by-pixel with the output), VAP lets you show the AI a short “example video” with the style or motion you want. The AI then uses that example as a prompt—like showing a demo to an artist—and creates a new video that follows the same idea but fits your new scene or subject.
What questions does the paper try to answer?
The paper focuses on five simple questions:
- How can we control videos by “meaning” (style, idea, motion, camera moves) rather than exact pixel-by-pixel instructions?
- Can one single model handle many kinds of control (concept, style, motion, camera) without custom parts for each task?
- How can we guide a big video model without making it forget its original skills?
- Can the model handle new, unseen examples it wasn’t trained on (“zero-shot”)?
- What kind of data do we need to make this work well?
How does the method work? (Explained simply)
Key idea: Use a video as a prompt
Imagine you want to make a video of your cat dancing like a person in a TikTok clip. With VAP, you give the AI:
- A reference video (the TikTok dance)
- A target description (e.g., “a cat dancing in the kitchen”)
- The starting image or frame of your target video (the cat in your kitchen)
The AI learns the “semantic” part—the idea or style—from the reference and applies it to your target, without copying details like the person’s exact body or background.
The main engine: Video Diffusion Transformer (DiT)
A diffusion model is like a sculptor that starts with random noise and gradually “carves out” a video that matches your prompt. A transformer is the brain that decides how pieces of the video relate. Put together, a Video Diffusion Transformer (DiT) is a powerful video maker.
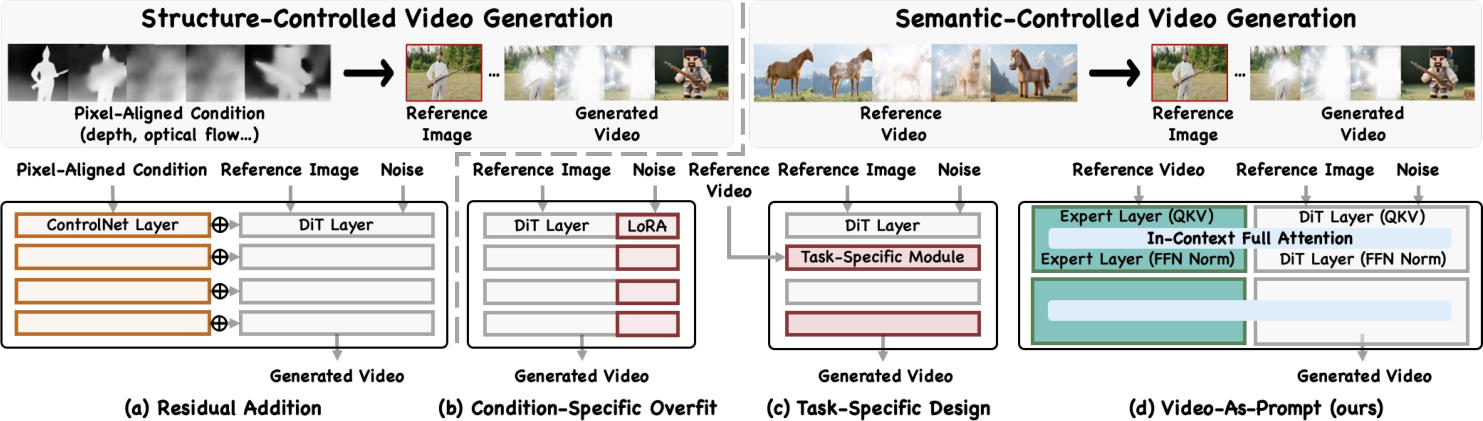
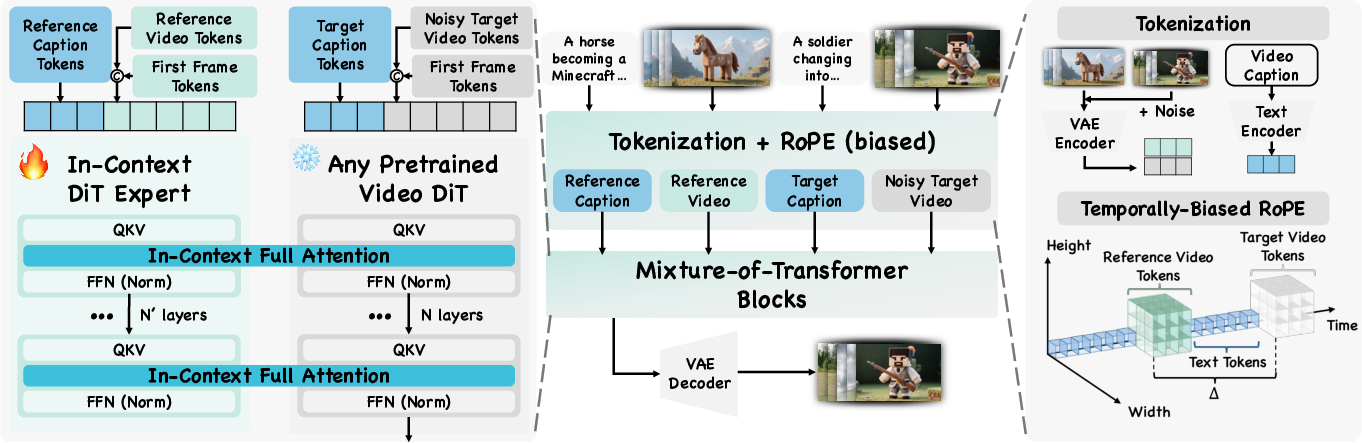
Preventing forgetting: A helper expert (Mixture-of-Transformers, or MoT)
Big models can “forget” old skills if you fine-tune them too much—this is called catastrophic forgetting. To avoid this:
- VAP keeps the main video model “frozen” (unchanged).
- It adds a parallel, trainable helper transformer (the “expert”) that reads your reference video and captions.
- The expert and the frozen model talk to each other at every layer, sharing attention. Think of it like the original artist painting while a coach whispers guidance based on the example video.
Position hints: Temporally biased RoPE
Transformers care about the order and position of things. RoPE (Rotary Position Embedding) is a way to tell the model “where” each piece of the video is in space and time.
- Problem: If the model thinks the reference and target videos line up pixel-by-pixel (same positions), it may try to copy details, causing weird artifacts.
- Fix: VAP shifts the reference video’s time positions so the model clearly knows “this comes before” and is just an example, not a pixel match. Spatial positions stay the same so the model can still learn how style or motion changes over space.
A big dataset to train on: VAP-Data
To make this work broadly, the authors built a large dataset:
- Over 100,000 paired videos
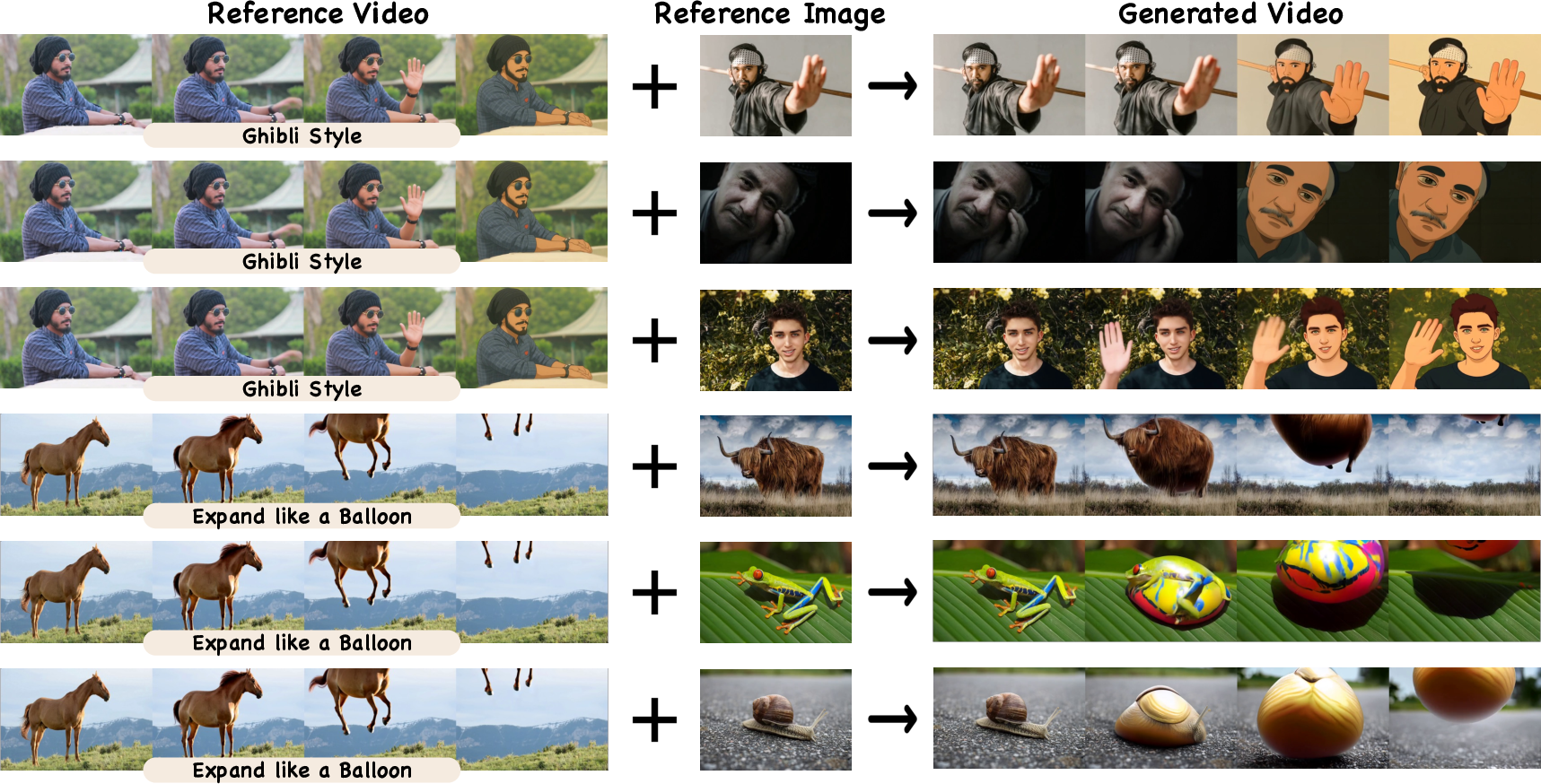
- 100 different “semantic” controls, grouped into four types: concept (like turning a person into a paper figure), style (e.g., Ghibli or Minecraft look), motion (e.g., ballooning or a specific dance), and camera moves (e.g., zooms and pans)
What did they find, and why does it matter?
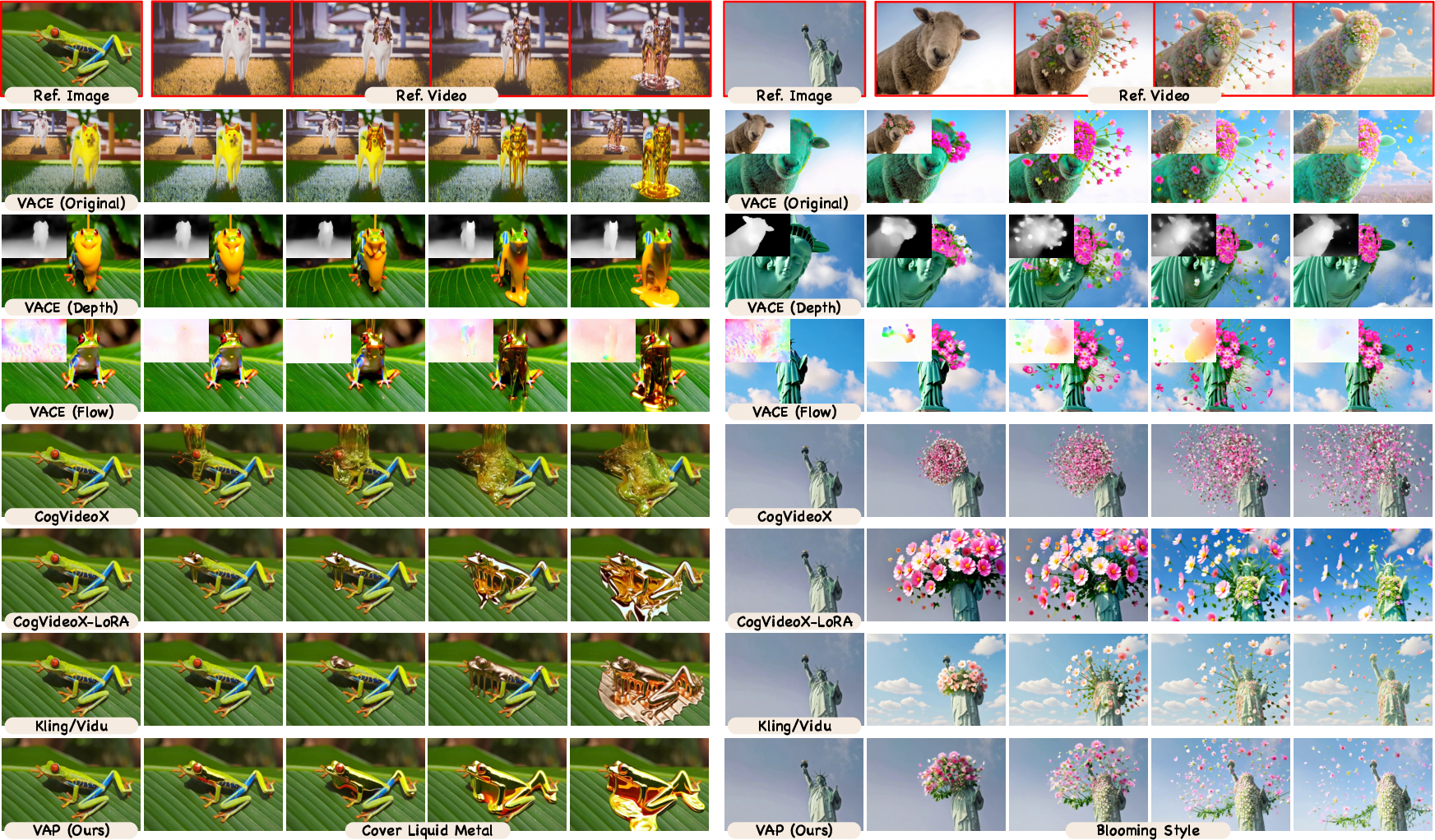
The researchers tested VAP against several baselines:
- Structure-controlled methods (which expect pixel-aligned inputs, like depth or optical flow)
- Per-condition fine-tuned models (custom-trained for each single style or task)
- Commercial models (closed-source systems built for specific conditions)
Key results:
- VAP, as one unified model, performed better than open-source baselines across quality and alignment measures.
- In a user study, VAP achieved a 38.7% preference rate, comparable to leading commercial systems, even though those are specialized for each condition.
- VAP handled “zero-shot” cases—new examples it wasn’t trained on—by applying the idea from the reference prompt to new scenes.
- The temporally biased RoPE and the MoT expert made the system more stable, reduced copying artifacts, and improved alignment with the intended style or motion.
Why it matters:
- It shows you can control videos by showing an example video, not just by giving perfect, pixel-aligned inputs or training a new model for each stylistic task.
- It moves video generation closer to how people think and work—“make it like this”—rather than “match this exact map.”
What could this change in the future?
This approach could:
- Make creative tools simpler: You can guide a video’s style or motion by just supplying a short example.
- Help filmmakers, artists, and educators quickly prototype visual effects, camera moves, or animation styles.
- Reduce the need for many specialized models—one system can handle many semantic controls.
- Improve generalization: Because it learns to use examples in-context, it can often work on new, unseen styles or motions.
Simple caveats and next steps:
- The dataset includes many synthetic examples from other generators, which may carry their biases or artifacts. More real-world, diverse data would help.
- Captions and reference choices matter. If descriptions are unclear or the subjects don’t match well, quality can drop. Better instruction-style prompts may improve control.
- Ethical use is important: such systems should not be used for impersonation, harmful content, or misinformation. The authors propose research-only use and content filters.
In short: VAP shows a practical, unified way to control video generation by using a video as the prompt—like showing a live demo—and it works across many kinds of “semantic” controls with strong generalization and competitive quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following points unresolved and open for future investigation:
- Data realism and provenance: VAP-Data is largely synthetic and derived from commercial visual-effects templates and community LoRAs; quantify and correct for template-induced stylistic biases, artifacts, and conceptual constraints, and evaluate on (or build) real, paired semantic-control datasets.
- Semantic coverage and taxonomy: Only 100 conditions across four categories (concept, style, motion, camera) are included; define a broader, principled taxonomy of semantic controls (including compositional and fine-grained semantics) and measure coverage and generalization across it.
- Zero-shot generalization breadth: Zero-shot results are shown qualitatively on a handful of unseen conditions; systematically quantify zero-shot performance across diverse, out-of-distribution semantics, adversarial references, and fully novel condition types.
- Robustness to reference quality: Sensitivity to noisy, short, low-resolution, occluded, or domain-shifted reference videos is not quantified; evaluate robustness and develop mechanisms (e.g., confidence-weighted guidance) for imperfect references.
- Caption dependency and failure modes: The method relies on both reference and target captions but provides limited analysis of sensitivity to inaccurate or mismatched descriptions; compare standard captions vs. instruction-style prompts and disentangle text vs. video contributions to control.
- Control strength and tunability: There is no explicit knob to modulate the intensity of semantic transfer; design and evaluate mechanisms (e.g., attention mixing weights, gating, schedule-based blending) to dial control strength and support partial or subtle transfers.
- Spatial/temporal localization: VAP applies global semantic control; investigate region- or time-localized control (e.g., masks, segment-level attention routing) to confine semantic transfer to user-specified areas or intervals.
- Positional embedding design space: The temporally biased RoPE uses a fixed offset Δ; explore adaptive or learnable offsets, multi-axis biases, and alternative PE schemes, and characterize trade-offs across video lengths and resolutions.
- Long-duration and streaming generation: Experiments are limited to ~49 frames; evaluate performance and stability on ultra-long videos, streaming generation, and memory-aware chunking, including how in-context retrieval behaves over long temporal horizons.
- Multi-prompt composition: The framework focuses on a single reference video; extend to compositional control with multiple prompts (e.g., style + motion + camera) and study interference, blending strategies, and user controllability.
- MoT architecture choices: The expert uses full attention Q/K/V concatenation without routing or gating; benchmark alternatives (e.g., sparse attention, learned routers, expert selection, layer placement strategies) and characterize compute–quality trade-offs.
- Catastrophic forgetting measurement: The claim that MoT avoids forgetting is not rigorously quantified; evaluate backbone task fidelity before/after training on original benchmarks and measure retention of non-controlled generation capabilities.
- Scalability and data–compute trade-offs: Scaling results are limited; derive empirical scaling laws (data size, expert size, training steps) and report training/inference cost curves, stability, and efficiency optimizations.
- Cross-architecture generality: Only two DiT backbones (CogVideoX-I2V-5B and Wan2.1-I2V-14B) are tested; validate portability to other architectures (e.g., Conv-based, LDM variants) and quantify how expert size/layer distribution affects transferability.
- Motion and camera fidelity metrics: Current metrics (dynamic degree, motion smoothness) are coarse; incorporate task-specific measures (e.g., optical-flow similarity, skeleton alignment, camera trajectory estimation) with ground-truth or pseudo-GT.
- Semantic alignment evaluation reliability: Automated scoring uses a closed-source LLM (Gemini-2.5-pro); assess the reliability, variance, and bias of LLM-based evaluators, and triangulate with larger, blinded human studies and task-specific quantitative metrics.
- User study scale and rigor: The user study involves 20 raters without detailed protocol reporting (blinding, randomization, inter-rater reliability); expand to larger cohorts, reproducible protocols, and report statistical significance.
- Baseline completeness and fairness: Comparisons omit other unified semantic-control baselines (e.g., LoRA MoE, retrieval-based controllers) and may not equalize compute/data across methods; broaden baselines and ensure fair, reproducible training settings.
- Generalization to additional modalities and controls: Audio-driven motion, physics/scene constraints, 3D-aware controls, and multi-view consistency are not explored; extend VAP to multimodal prompts and evaluate cross-modal transfer.
- Failure mode taxonomy: Anecdotal limitations (e.g., subject mismatch) are noted but not systematically categorized or quantified; compile a failure taxonomy with rates and diagnostic analyses (e.g., attention maps, retrieval saliency).
- Reference length and content selection: The effect of reference video duration, diversity, and first-frame vs. multi-keyframe prompting is not studied; optimize prompt selection strategies and quantify gains.
- Hyperparameter sensitivity: Key settings (Δ offset, guidance scale, ODE steps, attention configurations) lack sensitivity analyses; map performance landscapes and provide robust default ranges.
- Inference latency and memory footprint: The added expert (~5B params) increases compute; report end-to-end latency, memory, and throughput, and explore distillation or parameter-efficient variants.
- Theoretical understanding of in-context video control: The paper offers limited explanation of why in-context prompting works in video DiTs; develop theoretical or empirical analyses (e.g., probing attention patterns, prompt–target token interactions).
- Dataset licensing and IP risks: VAP-Data sources include outputs from commercial models and community LoRAs; clarify licensing, IP compliance, and release status, and propose dataset curation guidelines to mitigate legal/ethical risks.
- Safety and misuse measurement: While mitigations are described, empirical assessments (e.g., identity transfer strength, deepfake detectability, watermarking effectiveness) are absent; build safety benchmarks and evaluation protocols.
- Train/test leakage checks: Procedures ensuring no semantic template leakage between train and test splits are not detailed; implement and report leakage audits and contamination controls.
- Reproducibility details: Many training/inference details (VAE configurations, patching schemes, exact expert layer placement, tokenizer settings) are relegated to appendices or absent; provide complete, executable recipes and ablation coverage.
Practical Applications
Immediate Applications
The following items can be deployed with today’s foundation models and the paper’s VAP architecture and dataset, assuming access to a suitable Video DiT backbone, moderate GPU resources, and adherence to ethical use.
- VFX style and concept transfer for post-production — apply a reference video’s style (e.g., Ghibli, Minecraft) or concept effects (e.g., “liquid metal cover,” “paper man”) onto new footage without pixel alignment.
- Sectors: media and entertainment, advertising.
- Tools/products/workflows: VAP plug‑in for After Effects/Nuke/Blender; batch stylization pipeline where editors choose a reference video + captions and generate stylized takes for multiple shots.
- Assumptions/dependencies: rights to use the reference video; fast GPU inference; caption quality to disambiguate the target semantics; watermarking and AUP-compliant usage.
- Motion imitation across subjects — transfer dance, gesture, or object motion from a reference video to different actors or layouts (e.g., “shake‑it dance” applied to a product video).
- Sectors: social media, marketing, creator tools.
- Tools/products/workflows: mobile app or web studio with “Reference Motion” slot; one‑click motion transfer for UGC campaigns; batch generation for A/B testing.
- Assumptions/dependencies: reliable person/scene encoding from the base DiT; content moderation; handling occlusions and multi‑subject scenes.
- Camera motion replication and previz — reproduce dolly zoom, push/pull, tilt/pan from reference footage for new scenes to standardize camera grammar across shots.
- Sectors: film/TV production, virtual production.
- Tools/products/workflows: VAP “Camera‑as‑Prompt” module in previs tools; shot libraries of camera moves captured as video prompts; integration into storyboarding timelines.
- Assumptions/dependencies: accurate temporal biasing (RoPE) configured; consistent frame rate/length; editorial review to avoid unwanted layout copying.
- Rapid multi‑variant ad creatives — generate style/motion/camera‑controlled variants at scale for personalization and regional localization.
- Sectors: advertising, e‑commerce.
- Tools/products/workflows: VAP API behind creative CMS; automated pipelines that apply different reference prompts to the same base asset; semantic alignment QA step.
- Assumptions/dependencies: GPU quotas and cost control; legal review of stylization (brand/IP constraints); LLM‑based semantic alignment scorer for automated checks.
- Game cinematic and cutscene generation — produce short videos with consistent art direction and motion using reference prompts for seasonal events or updates.
- Sectors: gaming.
- Tools/products/workflows: VAP service connected to Unreal/Unity asset managers; “Art Bible” compiled as reference‑video library; batch generation for in‑engine playback.
- Assumptions/dependencies: license for stylistic references; integration with engine codecs; temporal coherence across sequences.
- Classroom demonstrations for film and animation — illustrate camera grammars, styles, and motion motifs by reapplying reference prompts to different subjects.
- Sectors: education.
- Tools/products/workflows: lightweight VAP workstation install for film schools; curated reference prompt packs aligned to lesson plans.
- Assumptions/dependencies: compute availability; local content filters; pedagogical captions tuned to the intended semantic.
- Research baselines and benchmarks — use VAP and VAP‑Data to study in‑context semantic control, MoT training stability, and RoPE biasing.
- Sectors: academia, applied ML labs.
- Tools/products/workflows: reproducible code + dataset to benchmark new control strategies; ablation suites for adapters, position embeddings, and expert placement.
- Assumptions/dependencies: acceptance of synthetic/data‑derived biases in VAP‑Data; access to 5B‑class models or smaller distilled variants.
- Creative localization workflows — convert house style into region‑specific looks while preserving motion and camera intent.
- Sectors: media localization.
- Tools/products/workflows: VAP style prompt libraries mapped to locale; caption templates for semantic intent (“keep camera language, change texture palette”).
- Assumptions/dependencies: consistent text prompts; legal/IP constraints; human‑in‑the‑loop QC.
- Storyboarding and iterative previz — generate quick animated boards by referencing motion/camera clips and applying them to simple subject images.
- Sectors: production design, advertising.
- Tools/products/workflows: VAP Previz Workbench (reference prompt + subject image + target caption → short animatic); rapid iteration cycles.
- Assumptions/dependencies: enough temporal length for establishing shots; caption clarity; editorial guardrails.
- Consumer creator apps for stylized home videos — let users emulate trending looks and motions by choosing a reference clip.
- Sectors: consumer software, social platforms.
- Tools/products/workflows: mobile app with on‑device/offload inference; watermarking; opt‑in consent cues for identity‑like transformations.
- Assumptions/dependencies: model compression/quantization; robust safety filters; frictionless UX for selecting reference clips.
- Trust & Safety sandboxing for platforms — generate controlled edge‑case videos (styles, motions, cameras) to stress‑test moderation rules and detector models.
- Sectors: platform policy, trust & safety.
- Tools/products/workflows: T&S lab uses VAP to synthesize borderline content per policy taxonomy; LLM‑based semantic alignment scoring for audit trails.
- Assumptions/dependencies: careful AUP governance; detector retraining pipelines; provenance/watermarking enabled by default.
- Dataset use as a training/evaluation resource — employ VAP‑Data to pretrain/control adapters or evaluate semantic alignment metrics across tasks.
- Sectors: tooling, research.
- Tools/products/workflows: curated splits per semantic category (concept/style/motion/camera); benchmark harnesses with CLIP + aesthetic + alignment metrics.
- Assumptions/dependencies: awareness of template‑source biases; complement with real‑world footage for external validity.
Long-Term Applications
These items likely require further research, scaling, real‑data collection, or system engineering (distillation, latency optimization, safeguards).
- Real‑time, general‑purpose controllable video editor — unify semantic and structure controls for live scrubbing, with millisecond‑level latency.
- Sectors: creative software.
- Tools/products/workflows: VAP‑enabled NLE with low‑latency expert; mixed‑precision inference; caching of prompt embeddings.
- Assumptions/dependencies: model distillation to sub‑1B parameters; GPU/ASIC acceleration; robust streaming attention.
- Live broadcast and streaming effects — apply motion/style/camera prompts on live feeds for sports or events.
- Sectors: media streaming, AR.
- Tools/products/workflows: VAP edge service; operator UI to select prompts in real time; latency‑aware scheduling.
- Assumptions/dependencies: hardware acceleration; strict content filters; resilience to motion blur and occlusions.
- Multimodal controls (audio/3D/trajectory‑as‑prompt) — extend video‑as‑prompt to include audio cues or explicit 3D camera paths and motion graphs.
- Sectors: multimodal AI, virtual production.
- Tools/products/workflows: joint encoders for audio/3D; MoT experts per modality; unified prompt composition.
- Assumptions/dependencies: new datasets with aligned audio/3D semantics; training stability with multiple experts.
- Personalized, consented digital doubles — maintain consistent persona style/motions across content while enforcing provenance/watermarking.
- Sectors: creator economy, studio IP.
- Tools/products/workflows: “Persona Pack” built from approved reference footage; policy‑aware watermarking and usage tracking.
- Assumptions/dependencies: explicit consent, IP licensing; strong misuse mitigations; standardized provenance signals.
- Synthetic dataset generation for CV/robotics — produce controllable videos (varying camera/motion/style) to train perception, tracking, and control systems.
- Sectors: robotics, computer vision.
- Tools/products/workflows: VAP generator with programmatic prompt sweeps; synthetic‑to‑real adaptation pipelines; label overlay via simulation.
- Assumptions/dependencies: domain gap analysis; ground truth alignment; safety validation.
- Rehabilitation, sports coaching, and education content — create tailored motion demonstration videos from a patient’s/athlete’s reference, adapted to environment constraints.
- Sectors: healthcare (non‑diagnostic), fitness, education.
- Tools/products/workflows: clinician/coach tools for motion libraries; environment‑specific re‑renders; lesson‑aligned captions.
- Assumptions/dependencies: medical oversight; efficacy and fairness studies; clear disclaimers (no diagnostic claims).
- Standards for provenance and generative governance — inform watermarking, disclosure, and auditing norms for semantic‑controlled video.
- Sectors: public policy, industry consortia.
- Tools/products/workflows: reference implementations of robust watermarks; alignment metrics (as in paper) for audits; datasets for detector training.
- Assumptions/dependencies: multi‑stakeholder coordination; legal frameworks; interoperability across platforms.
- Enterprise “prompt libraries” and governance — institutionalize reusable style/motion/camera prompts with approval workflows and risk scoring.
- Sectors: enterprise media operations.
- Tools/products/workflows: prompt registries with metadata; automated risk checks (semantic alignment, policy tags); lifecycle management.
- Assumptions/dependencies: MLOps maturity; role‑based access; compliance audits.
- Curricula and standardized assessments — build teaching modules and competency tests for semantic video generation using VAP‑Data extensions.
- Sectors: education.
- Tools/products/workflows: accredited courseware; public leaderboards; rubrics based on semantic alignment and quality metrics.
- Assumptions/dependencies: open licensing; expanded real‑world datasets; instructor training.
- Edge/mobile deployment — bring VAP capabilities to devices via distilled models and efficient VAEs for short clips.
- Sectors: mobile, consumer apps.
- Tools/products/workflows: quantized MoT experts; on‑device caching of prompt latents; hybrid on‑device/cloud rendering.
- Assumptions/dependencies: aggressive compression without quality loss; battery/thermal constraints; network fallback.
Cross‑cutting assumptions and dependencies
- Model access and compute: VAP as described trains a ~5B expert with frozen 5B–14B backbones; immediate deployments may need cloud GPUs, while long‑term goals require distillation/compression.
- Data quality and coverage: VAP‑Data is large but synthetic/derived; expanding to real, diverse footage will improve external validity and fairness.
- Caption fidelity: Semantic control relies on accurate reference/target captions; instruction‑style prompts could further improve alignment.
- Legal/ethical governance: Consent for reference footage, robust watermarking/provenance, and adherence to acceptable‑use policies are essential.
- Integration and latency: Production workflows need SDKs/APIs, editor plug‑ins, caching, and scheduling to meet turnaround times.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization in deep learning. "We use AdamW with learning rate and train for 20k steps on $48$ NVIDIA A100s."
- CLIP: A multimodal model for measuring text–image/video alignment via contrastive embeddings; here used as a text alignment metric. "we measure text alignment with CLIP similarity"
- Classifier-free guidance scale: A sampling hyperparameter in diffusion models that controls the strength of conditioning to improve fidelity at the cost of diversity. "a classifier-free guidance scale $6$ ($5$)"
- Condition-Specific Overfit: A strategy where separate models or adapters are fine-tuned for each condition, which is costly and non-generalizable. "Condition-Specific Overfit"
- Denoising timesteps: The discrete steps taken by a sampler to progressively transform noise into data in diffusion-based generation. "a discrete set of denoising timesteps"
- Flow Matching: A training objective that learns a velocity field to transform noise into data along a continuous path. "Using Flow Matching for illustration"
- Full attention: Attention computed over concatenated query/key/value tensors across branches to enable bidirectional information exchange. "communicate via full attention for synchronous layer-wise reference guidance."
- In-context generation: Conditioning a model on reference tokens within its input sequence so it learns to use examples at inference without parameter updates. "reframes this problem as in-context generation."
- Latent space: A compressed representation space produced by an encoder (e.g., VAE) where generation is performed before decoding to pixels. "encodes Gaussian noise into a latent space"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank updates into existing weights. "LoRAs for each semantic condition"
- Mixture-of-Experts (MoE): An architecture that routes inputs through multiple expert modules; here referenced as LoRA-based experts over conditions. "a LoRA mixture-of-experts for unified generation across multiple semantic conditions"
- Mixture-of-Transformers (MoT): A design that pairs a frozen transformer with a trainable expert transformer that exchanges information for conditioning. "Mixture-of-Transformers (MoT) expert"
- ODE solver: A numerical integrator used to follow the learned velocity field in diffusion sampling to reconstruct data from noise. "uses an ODE solver with a discrete set of denoising timesteps"
- Optical flow: A per-pixel motion field over time; used as a structure control signal in video generation. "optical flow"
- Pixel-aligned condition: A control input (e.g., depth, pose) that aligns spatially and temporally with the target video’s pixels. "under pixel-aligned conditions"
- Pixel-wise mapping prior: The assumption that each pixel in a condition maps directly to a pixel in the output, which can cause artifacts under semantic control. "pixel-wise mapping priors"
- Plug-and-play: A modular component that can be attached to a pre-trained model for new functionality without re-training the backbone. "plug-and-play Mixture-of-Transformers (MoT) expert"
- Residual addition: A feature injection mechanism that adds condition features to backbone activations, commonly used under pixel alignment. "residual addition"
- Rotary Position Embedding (RoPE): A positional encoding method that rotates queries and keys to encode relative positions in transformers. "Rotary Position Embedding (RoPE)"
- Semantic-alignment score: An automatic metric assessing consistency between reference and generated videos’ semantics. "a semantic-alignment score"
- Semantic-controlled video generation: Generating videos guided by shared high-level semantics (concept, style, motion, camera) without pixel alignment. "semantic-controlled video generation"
- Structure-controlled video generation: Generating videos guided by pixel-aligned structural signals (e.g., depth, pose, optical flow). "structure-controlled video generation"
- Temporally biased RoPE: A RoPE variant that shifts reference prompt tokens earlier in time to avoid spurious pixel mapping and improve retrieval. "temporally biased Rotary Position Embedding (RoPE)"
- VAE (Variational Autoencoder): A generative encoder–decoder model that maps videos to latents and back for efficient diffusion. "video VAE encoder"
- VAP-Data: A large paired dataset of reference/target videos across many semantic conditions for training unified semantic control. "we built VAP-Data, the largest dataset for semantic-controlled video generation"
- Video-As-Prompt (VAP): The proposed paradigm that treats a reference video as a direct semantic prompt to control generation. "We introduce Video-As-Prompt (VAP)"
- Video Diffusion Transformer (DiT): A transformer-based diffusion model architecture for high-quality video generation. "Video Diffusion Transformer (DiT)"
- Video prompt: Using a reference video as the conditioning prompt that carries desired semantics to guide generation. "video prompts"
- Zero-shot generalization: The ability of a single model to handle unseen semantic conditions without additional training. "strong zero-shot generalization"
Collections
Sign up for free to add this paper to one or more collections.