Flowception: Temporally Expansive Flow Matching for Video Generation
Abstract: We present Flowception, a novel non-autoregressive and variable-length video generation framework. Flowception learns a probability path that interleaves discrete frame insertions with continuous frame denoising. Compared to autoregressive methods, Flowception alleviates error accumulation/drift as the frame insertion mechanism during sampling serves as an efficient compression mechanism to handle long-term context. Compared to full-sequence flows, our method reduces FLOPs for training three-fold, while also being more amenable to local attention variants, and allowing to learn the length of videos jointly with their content. Quantitative experimental results show improved FVD and VBench metrics over autoregressive and full-sequence baselines, which is further validated with qualitative results. Finally, by learning to insert and denoise frames in a sequence, Flowception seamlessly integrates different tasks such as image-to-video generation and video interpolation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Flowception: A simple explanation for teens
What is this paper about?
This paper introduces Flowception, a new way for computers to make videos. It can start from a single image, a few images, or even a short video, and then create a longer, smooth video. The big idea is to both clean up frames and add new frames in between—kind of like sketching the main moments of a flipbook first, then filling in the gaps.
What questions are the researchers trying to answer?
- Can we make high-quality videos without the usual problems of step-by-step (left-to-right) video generation, where small mistakes snowball over time?
- Can we generate videos of any length without needing to fix the number of frames ahead of time?
- Can one model naturally handle different tasks like image-to-video, video interpolation (filling gaps between frames), and video-to-video editing?
- Can we do this more efficiently (faster/cheaper) than existing methods?
How does Flowception work? (In simple terms)
Think of creating a flipbook:
- Traditional step-by-step methods draw page 1, then page 2, then page 3, and so on. If you mess up page 2, every later page might look worse.
- Full-sequence methods try to draw all pages at once, which can produce great results but is slow and can’t easily stream frames as they’re ready.
Flowception mixes the best of both:
- It keeps improving the frames it already has (like polishing a sketch).
- At the same time, it decides where to insert new frames to make motion smooth and natural.
Here’s the basic loop:
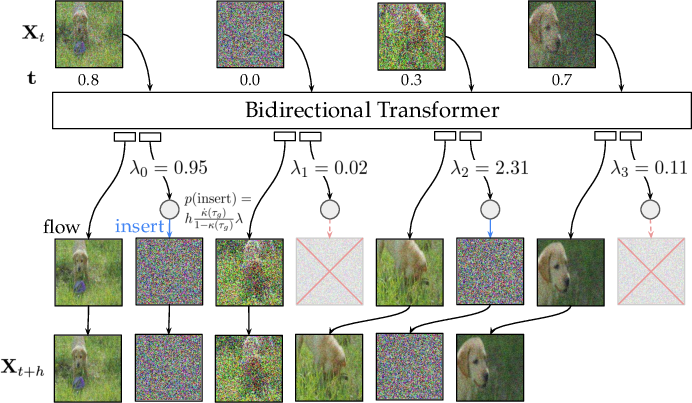
- Every frame has its own “progress meter” from 0 to 1. At 0, it’s very noisy (like a messy static-filled image); at 1, it’s clean and finished.
- At each step, the model does two things: 1) It predicts how to “push” each existing frame toward a clearer version (this is called a velocity—think of it like nudge directions for pixels). 2) It decides where to add a new frame next (this is called an insertion rate—like deciding where in the flipbook to add another page).
Key ideas explained:
- Denoising/Flow matching: Start from noise and steadily shape it into a realistic frame. Imagine sculpting a statue from a block of stone by continuously shaving off what you don’t need.
- Insertion: Instead of always adding the next frame at the end, Flowception can add a frame anywhere it will help the video look smoother and more natural.
- Per-frame timing: Each frame moves toward “finished” at its own speed. This makes it flexible—you can add frames at any time and refine them alongside others.
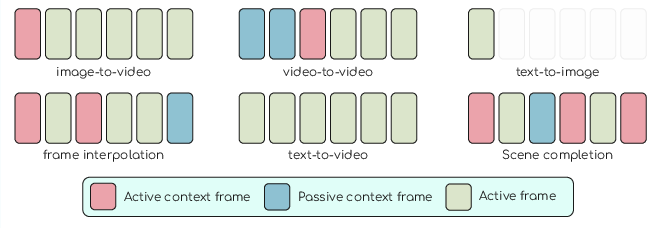
Because it can add and refine frames in any order, Flowception naturally supports:
- Image-to-video: Start with one image and grow a video from it.
- Video interpolation: Given a few spaced-out frames, fill in the missing ones smoothly.
- Video-to-video or scene completion: Improve or extend an existing video.
What did they test and find?
The team tested Flowception on several datasets:
- Tai-Chi-HD (people doing tai chi)
- RealEstate10K (indoor and outdoor scenes)
- Kinetics-600 (many kinds of human actions)
They compared Flowception to:
- Full-sequence models (everything denoised together)
- Autoregressive models (frame-by-frame, left-to-right)
What they found:
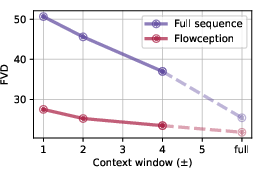
- Quality: Flowception often matched or beat other methods on standard video metrics like FVD and VBench (which check things like image quality, smooth motion, consistent backgrounds/subjects).
- Fewer errors over time: Because frames can still be refined after new ones are added, small mistakes don’t snowball like they do in strict left-to-right approaches.
- Flexibility: It handles different tasks without changing the model—just tell it which input frames are “active” (where it’s allowed to insert new frames) and which are “passive” (no insertions next to them).
- Efficiency: On average, training needed about 3× fewer compute-heavy attention operations than the full-sequence approach, and sampling (generation) was also cheaper. Early in generation, only a few frames are visible, so it’s faster to process.
A neat observation:
- Flowception tends to insert “farther apart” frames early (setting the big motion), then later fills in the smaller gaps. That’s like sketching the key poses first, then adding the in-between drawings to make motion smooth.
Why does this matter?
- Better long videos: It avoids the “domino effect” of errors that plague left-to-right video generators.
- Works for many tasks: The same model can do image-to-video, video interpolation, and more, just by choosing where it’s allowed to insert frames.
- More efficient: It can be cheaper to train and run than methods that process all frames at once.
- More control: You can guide how many frames to add and where, which helps make videos smoother or longer as needed.
In short, Flowception is like a smarter flipbook artist: it plans the big moves, fills in gaps where needed, and keeps polishing frames throughout, leading to smoother, higher-quality videos without being locked into a rigid order or length.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Theoretical guarantees of the coupled ODE–jump process: rigorous proof of consistency and convergence to the data distribution, and formal justification of the insertion probability scaling factor beyond the high-level supplementary derivation.
- Scheduler design and learning: evaluation of non-linear, content-adaptive, or learnable schedules; analysis of schedule–quality–efficiency trade-offs; robustness when the training and inference schedules differ.
- Insertion rate modeling: testing alternatives to the Poisson assumption (e.g., Negative Binomial for overdispersion), calibration of rate predictions, and sensitivity to the exponential activation (e.g., stability, gradient behavior).
- Time conditioning of insertions: impact of explicitly conditioning insertion rates on global time (the current design ignores ) on control, stability, and alignment with the desired visible-frame fraction.
- Choice and adaptation of the number of starting frames (): systematic study of its effect on quality, motion, and efficiency; methods to learn or adapt per task or content.
- Initialization prior for newly inserted frames: assessing correlated or conditional priors (e.g., neighbor-informed noise) versus unit Gaussian to improve temporal coherence and reduce artifacts.
- Streaming viability: empirical measurement of end-to-end latency and user-perceived streaming quality; policies for freezing/displaying frames during ongoing denoising; impact of frame mutability on streamed content.
- Robustness across sampling budgets: comprehensive quality–NFE (number of function evaluations) curves versus AR (with/without KV caching) and full-sequence baselines, including stability and failure patterns at low NFEs.
- Long-horizon scalability: experiments on minute-long videos (thousands of frames) and higher FPS, including memory scaling, throughput, and degradation modes over very long sequences.
- Text-to-video evaluation: quantitative prompt-fidelity benchmarks (e.g., T2V metrics), error analysis of text alignment under variable-length insertions, and interactions between rate guidance and prompt adherence.
- Dataset breadth and resolution: evaluation on more diverse, open-domain datasets at higher resolutions (e.g., 512/1024), and sensitivity to domain shift beyond Tai-Chi-HD and RealEstate10K.
- Baseline comparability: controlled comparisons to external state-of-the-art systems (e.g., Wan, MovieGen, Open-Sora), with matched training budgets, autoencoders, and architectural choices; disclosure of full training hyperparameters.
- Attention scope analysis: formal and empirical study of why Flowception tolerates small local windows better than full-sequence models; stress tests on tasks requiring extreme long-range temporal dependencies.
- Training distribution alignment: validation that extended-time training truly matches the inference distribution for non-linear or learned schedulers; quantification of mismatch effects on insertion calibration and denoising.
- Multi-head training interactions: analysis of interference between velocity and insertion heads, loss weighting strategies, and training curricula to avoid one head dominating or destabilizing the other.
- Explicit control over video length and per-gap density: mechanisms to target total length or frame counts between context frames; conditional training on length; evaluation of controllability and precision.
- Active vs passive context frames at training: curricula that include mixed active/passive conditioning; systematic evaluation on video-to-video, scene completion, and multi-anchor interpolation; conflict resolution when contexts disagree.
- Beyond insertions: extending the framework to deletions, retiming (tempo changes), or reordering edits; enabling content-aware editing of previously generated frames without breaking coherence.
- Autoencoder dependence: quantifying the impact of the LTX latent downsampling, and the decoder’s validity-mask modification on reconstruction bias, artifacts, and temporal consistency; comparisons with alternative VAEs/tokenizers.
- Resource reporting: detailed measurements of wall-clock time, GPU memory, FLOPs, and throughput for training and sampling, including attention window sizes and KV caching baselines under matched conditions.
- Solver and discretization choices: sensitivity analyses for step size , adaptive integrators, error control, and alternate time discretizations; policies for early stopping when some frames reach sooner.
- Guidance mechanisms for insertion: principled methods to balance motion smoothness, dynamic degree, and video length (beyond CFG); adaptive per-scene guidance schedules; theory linking guidance scales to insertion statistics.
- Failure-mode diagnostics: systematic identification and mitigation of under-insertion (choppy transitions) and over-insertion (blur/drift), including metrics, detectors, and corrective sampling or training strategies.
- Generation order: quantification of the emergent coarse-to-fine ordering, its content dependence, and methods to control or learn generation order policies for specific tasks.
- Reproducibility: public release of code, training recipes, and non-proprietary datasets; documentation of seeds and hyperparameters; ablation depth sufficient for independent replication.
- Safety and ethics: analysis of potential misuse, content filtering, and societal impacts of variable-length video generation; guidelines for responsible deployment and evaluation.
Practical Applications
Below are actionable applications of the Flowception framework, organized by near-term deployability and longer-term potential. Each item notes relevant sectors, concrete use cases, plausible tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Media/Entertainment — Keyframe-driven video synthesis and extension
- Use case: Turn a single image or a small set of reference frames into coherent video clips (image-to-video, video-to-video, scene completion) for adverts, storyboards, social content, and previsualization.
- Tools/workflows: “AnchorFrames” editor that lets creators select active vs passive context frames; insertion-rate guidance as a “pacing” knob; export to Premiere/After Effects via a plugin.
- Assumptions/dependencies: Model trained on domain-relevant data; current models are ~2.1B parameters and operate at 256p latent resolution; LTX-Video or similar tokenizer required.
- Post-production — Video interpolation and retiming
- Use case: Smooth slow motion; fill missing frames between key shots; bridge micro jump-cuts; stabilize choppy footage without specifying exact frame counts.
- Tools/workflows: “Smart Interpolator” node in NLEs; automatic gap filling using Flowception’s learned insertion head; per-frame time conditioning to preserve continuity.
- Assumptions/dependencies: Quality depends on dataset domain (e.g., RealEstate10K vs Tai-Chi-HD); requires decoder mask propagation to avoid padding artifacts.
- Media Restoration/Archival — Frame recovery and continuity smoothing
- Use case: Reconstruct missing frames in damaged film reels; consistent motion interpolation across long sequences without cascade errors.
- Tools/workflows: Restoration pipelines that treat known frames as passive anchors and allow insertions only where needed; rate guidance to reduce under-insertion.
- Assumptions/dependencies: Domain-adapted training (old film scans); provenance/watermarking for restored content.
- Software/AI Infrastructure — Cost-efficient training and inference for video generation
- Use case: Reduce training and sampling FLOPs vs full-sequence models; replace AR pipelines where causal masking and KV caching still accumulate exposure bias.
- Tools/workflows: Adoption of Flowception’s interleaved insertion–denoising and local attention windows; per-frame AdaLN conditioning; velocity + rate dual-head architecture; configurable linear scheduler κ(t).
- Assumptions/dependencies: Availability of compute (GPU clusters); integration into MMDiT-style pipelines; benefits measured at 256p may differ at higher resolutions.
- Robotics and AV Perception — Synthetic data augmentation
- Use case: Generate long-horizon video scenarios from sparse frames to augment training of perception models (e.g., rare edge cases, weather conditions).
- Tools/workflows: Scenario composer that selects passive anchors (start/end states) and lets Flowception interpolate trajectories; domain-specific fine-tunes.
- Assumptions/dependencies: Domain gap handling; labels for synthetic data; careful validation to avoid negative transfer.
- Live and Social Platforms — Progressive generation for previews
- Use case: Show frames as they reach full denoising (ti=1) for “instant preview” of content while longer sequences continue to render.
- Tools/workflows: Streaming sampler that exposes per-frame readiness; user-adjustable insertion guidance to control clip length on-the-fly.
- Assumptions/dependencies: UI/latency engineering; scheduler tuning for responsiveness; display only fully denoised frames.
- Education — Rapid animation from diagrams or lab snapshots
- Use case: Convert static teaching materials into short explanatory clips; interpolate between lab experiment states to highlight dynamics.
- Tools/workflows: LMS plugin that imports key frames and auto-generates in-between sequences; classroom “pacing” presets for insertion guidance.
- Assumptions/dependencies: Proper dataset alignment (domain adaptation); content provenance for assessment contexts.
- Daily Life — Smartphone features for clip extension and slow motion
- Use case: Extend short captures into longer loops; smooth low-light or shaky footage; create cinemagraph-style effects from a single photo.
- Tools/workflows: Mobile app “Video Extender” with modes for I2V, interpolation, and pacing; on-device distilled model or cloud inference.
- Assumptions/dependencies: On-device constraints may require model distillation and low-NFE robustness; privacy constraints for cloud use.
- Policy and Trust — Watermarking and provenance in generative video
- Use case: Embed provenance tags when generating or interpolating frames; flag interpolated regions for transparency.
- Tools/workflows: Integration of watermarking in the video autoencoder; “inserted-frame map” metadata shipping with assets.
- Assumptions/dependencies: Standards adoption; legal/compliance alignment; minimal quality impact from watermarking.
Long-Term Applications
- Communications/Networking — Generative video compression and error concealment
- Use case: Transmit sparse keyframes and reconstruct intermediate frames with Flowception at the receiver; conceal packet losses by inserting plausible frames.
- Tools/workflows: Codec that co-optimizes keyframe cadence with insertion-rate scheduler; receiver-side learned rate head for adaptive reconstruction.
- Assumptions/dependencies: Standards and hardware acceleration; robust handling of fast motion; security/privacy considerations.
- Media/Entertainment — Long-form text-to-video streaming with interactive pacing
- Use case: Live, minutes-long generation guided by script segments, where users add anchors and adjust insertion guidance (“tempo”) mid-stream.
- Tools/workflows: LLM + Flowception co-pilot that plans anchor frames and updates pacing; bi-directional attention across evolving context without causal constraints.
- Assumptions/dependencies: Scalability to higher resolutions and durations; tight latency management; guardrails for content safety.
- Advanced Post-production — Any-order editing with semantic constraints
- Use case: Insert or replace frames non-sequentially to correct continuity, enforce story beats, or preserve actor/subject consistency across scenes.
- Tools/workflows: “Any-Order Editor” that exposes active/passive frame controls and learned insertion priorities; semantic locking for subjects/backgrounds.
- Assumptions/dependencies: Strong identity and background consistency models; UI to visualize per-frame time and insertion maps.
- Robotics/Autonomy — World-model training with variable-length generative rollouts
- Use case: Train policies using synthetic, coherent long-horizon video trajectories that can be flexibly extended or densified as needed.
- Tools/workflows: Data-generation stack that adapts the κ(t) scheduler to task horizons; coupling with dynamics priors and evaluation against real-world datasets.
- Assumptions/dependencies: Safety validation; handling of compounding model bias; transfer learning pipelines.
- Healthcare — Clinically validated medical video reconstruction (ultrasound, endoscopy)
- Use case: Interpolate missing frames, stabilize motion, and enhance continuity for diagnostic workflows.
- Tools/workflows: PACS-integrated interpolation module with strict provenance and clinician-in-the-loop review; domain-specific fine-tunes and QA.
- Assumptions/dependencies: Regulatory approval, clinical trials, bias and safety audits; domain-specific tokenizers and training.
- Education/Science Communication — Script-to-visual pipelines at scale
- Use case: Generate educational sequences from instructor-selected anchors; auto-adjust pacing for cognitive load and retention.
- Tools/workflows: Curriculum-aware scheduler templates; alignment with learning objectives via guided insertion rates.
- Assumptions/dependencies: Pedagogical validation; accessibility standards (captions, alt-text); content provenance.
- Security and Policy — Standards for generative streaming and detection
- Use case: Define protocols for signaling generated/interpolated frames; detection tools for insertions in forensic analysis.
- Tools/workflows: “Insertion Map” standard as sidecar metadata; public APIs to verify provenance; watermark-aware tooling for platforms.
- Assumptions/dependencies: Multi-stakeholder coordination; international policy alignment; minimal friction for adoption.
- Software/AI Ecosystem — Specialized hardware and SDKs for variable-length generative video
- Use case: Accelerate interleaved insertion–denoising with local attention; expose per-frame time conditioning in SDKs.
- Tools/workflows: Runtime libraries for ODE–jump processes; schedule-aware memory planners; hardware support for attention windowing.
- Assumptions/dependencies: Vendor support; benchmarking and best-practice guides; evolution beyond 256p to HD/4K.
- Energy/Sustainability — Lower compute carbon footprint for video generation
- Use case: Replace full-sequence diffusion with Flowception in production pipelines to cut FLOPs (≈3× in training, ≈1.5× at sampling reported).
- Tools/workflows: Cost-aware schedulers; green-ops dashboards tracking FLOP reductions and power usage.
- Assumptions/dependencies: Similar gains at higher resolutions; reliable reporting; model efficiency improvements (distillation, MoE).
Notes on feasibility across applications:
- Performance and quality are sensitive to training data and domain; generalization beyond the paper’s datasets (Tai-Chi-HD, RealEstate10K, Kinetics-600) requires fine-tuning.
- Current models operate at latent 256p; HD/4K deployment will need tokenizer and architecture scaling, and may change compute profiles.
- For streaming-like experiences, only fully denoised frames (ti=1) should be displayed; latency depends on scheduler, step size, and NFE budget.
- Responsible deployment requires watermarking/provenance and safety checks to mitigate misuse (e.g., deepfakes).
- On-device use likely needs distillation and efficient local attention; cloud inference raises privacy and cost considerations.
Glossary
- AdaLN: Adaptive layer normalization modulation used to condition transformer layers; here adapted per frame. "we change the AdaLN~\cite{Peebles2022DiT} modulation to operate on a per-frame basis."
- Autoregressive (AR) generation: Sequence modeling that generates frames sequentially, conditioning on previously generated frames. "temporal autoregressive (AR) generation produces frames (or blocks of frames) sequentially in a left-to-right order~\cite{genie, song2025historyguidedvideodiffusion}."
- Bidirectional attention: Attention mechanism where tokens can attend to both past and future positions, enabling error correction. "Full-sequence models benefit from bidirectional attention, enabling the model to correct errors during de-noising and achieving superior generation quality."
- Causal attention mask: Attention mask restricting tokens to attend only to past context; enables caching but reduces expressiveness. "AR methods typically use a causal attention mask which limits the expressiveness of the models."
- Classifier-free guidance (CFG): Conditioning technique combining conditional and unconditional predictions to steer generation. "Classifier-free guidance (CFG) is commonly used to achieve better prompt alignment and image quality in diffusion and flow models~\cite{ho2021classifierfree}."
- CLIP features: Representations from the CLIP model used for conditioning and mitigating drift. "using CLIP features of the anchor frame rather than the last generated frame to mitigate drift across clips."
- DiT (Diffusion Transformer): Transformer architecture tailored for diffusion/flow generative models. "Our architecture builds on the popular DiT diffusion transformer architecture~\cite{Peebles2022DiT}."
- Edit Flow: Framework for discrete edit operations (insert/delete) within flow-based generative modeling. "We propose a natural combination of the continuous Flow Matching~\citep{lipman2023flow} and the discrete Edit Flow~\citep{havasi2025edit} frameworks."
- Exposure bias: Train-test mismatch where models are trained on ground-truth context but infer on self-generated outputs, causing error accumulation. "these AR approaches suffer from critical exposure bias \cite{zhang2025framepack,bengio15nips}."
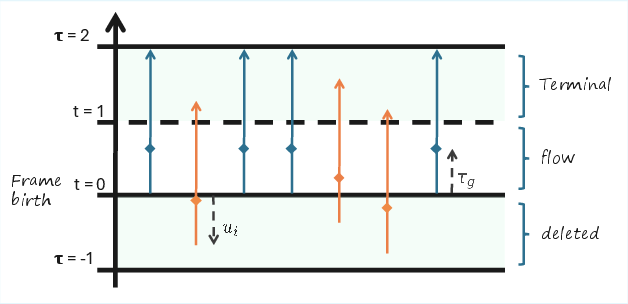
- Extended time values: Time variables τ that extend beyond [0,1] to model insertion and denoising phases. "Extended time values are denoted and can take values outside of the interval ."
- FLOPs: Floating-point operations; a measure of computational cost. "We present an efficiency analysis showing an average of FLOPs reduction during training and ( during sampling) w.r.t full-sequence model."
- Flow Matching: Generative technique learning velocity fields to transport a noise distribution to data along a continuous path. "interleaves two processes throughout sampling: (i) continuous flow matching denoising of existing frames."
- Fréchet Video Distance (FVD): Video quality metric measuring distributional distance in a learned feature space. "we find that, beyond being a more flexible framework, Flowception leads to comparable or better performance than full-sequence and autoregressive paradigms under the same compute budget, with consistent improvements in terms of FVD and VBench metrics."
- Global time value: Scalar control variable governing when insertions are allowed and scheduling over the generation process. "we introduce a global time value which starts at and frame insertions are only allowed while ."
- Hierarchical insertion scheme: Baseline strategy that inserts frames by repeatedly splitting the largest gaps. "using a ``hierarchical'' scheme where we iteratively insert them in the middle of the largest interval in where no frame has been inserted yet."
- KV caching: Reusing key/value tensors across autoregressive steps to accelerate attention computation during inference. "to enable KV caching, without which sampling from AR models becomes prohibitively expensive."
- LTX autoencoder: Video latent autoencoder with spatial and temporal downsampling used for efficient training/inference. "We use the LTX autoencoder~\cite{HaCohen2024LTXVideo}, which has a spatial downsampling factor of 32 and temporal downsampling factor of 8."
- Masked diffusion mechanism: Diffusion approach that applies masks to selectively reuse information from inputs. "with a masked diffusion mechanism that selectively reuses information from the given frame to reduce appearance drift over long horizons."
- MMDiT: Multi-modal DiT attention setup enabling joint attention over text and visual tokens. "We enable full bidirectional attention between frames and optionally concatenated text tokens in an MMDiT~\cite{sd3} fashion."
- NFEs (Number of Function Evaluations): Count of solver steps in continuous-time samplers; lower NFEs imply faster sampling. "Flowception shows comparable sampling cost with more robustness under low NFEs."
- ODE–jump process: Hybrid stochastic process combining continuous ODE flows with discrete jump (insertion) events. "This yields a coupled ODEâjump process over variable-length sequences and supports {\it any-order, any-length} generation by design."
- OneFlow: Related framework with interleaved operations; here guiding the choice to not time-condition insertion rates. "This closely follows the design choice of OneFlow~\cite{nguyen2025oneflowconcurrentmixedmodalinterleaved} where insertion rates are not conditioned on time."
- Poisson distribution: Probability distribution modeling counts; used to supervise predicted insertion counts. "the loss for training the insertion output , which predicts the number of missing frames, is given by the negative log-likelihood of the Poisson distribution."
- Scheduler κ(t): Monotonic function of global time that governs the probability of frames being visible/inserted over time. "We impose a distribution on the fraction of visible frames based on a monotonic scheduler that is a function of the global time value, with , ."
- SNR (Signal-to-Noise Ratio): Measure of signal strength relative to noise; 0-SNR indicates pure noise initialization. "The insertion operation inserts a 0-SNR frame which will then be denoised following the flow matching framework."
- TI2V (Text-Image-to-Video): Generation setting where both text and an image condition the video synthesis. "ART-V~\cite{artv} instead performs frame-wise autoregressive generation in a text-image-to-video (TI2V) setting."
- Unit Gaussian prior: Standard normal distribution used to initialize newly inserted frames. "initialized with a sample from a unit Gaussian prior distribution."
- Velocity field: Per-frame vector field predicted by the model that drives denoising along the learned flow. "the model predicts, for each frame , a velocity field and an insertion rate ."
- VideoROPE (Video Rotary Position Embedding): Rotary positional embedding method tailored for video tokens. "Positional embeddings follow the VideoROPE method~\cite{wei2025videorope}."
- VBench: Benchmark suite of video metrics evaluating quality, consistency, motion, and dynamics. "we rely on the standard FVD metric~\cite{unterthiner2019fvd}, computed with respect to a subset of 5k videos from the training set, as well as selected metrics from VBench~\cite{huang2024vbench}."
Collections
Sign up for free to add this paper to one or more collections.

