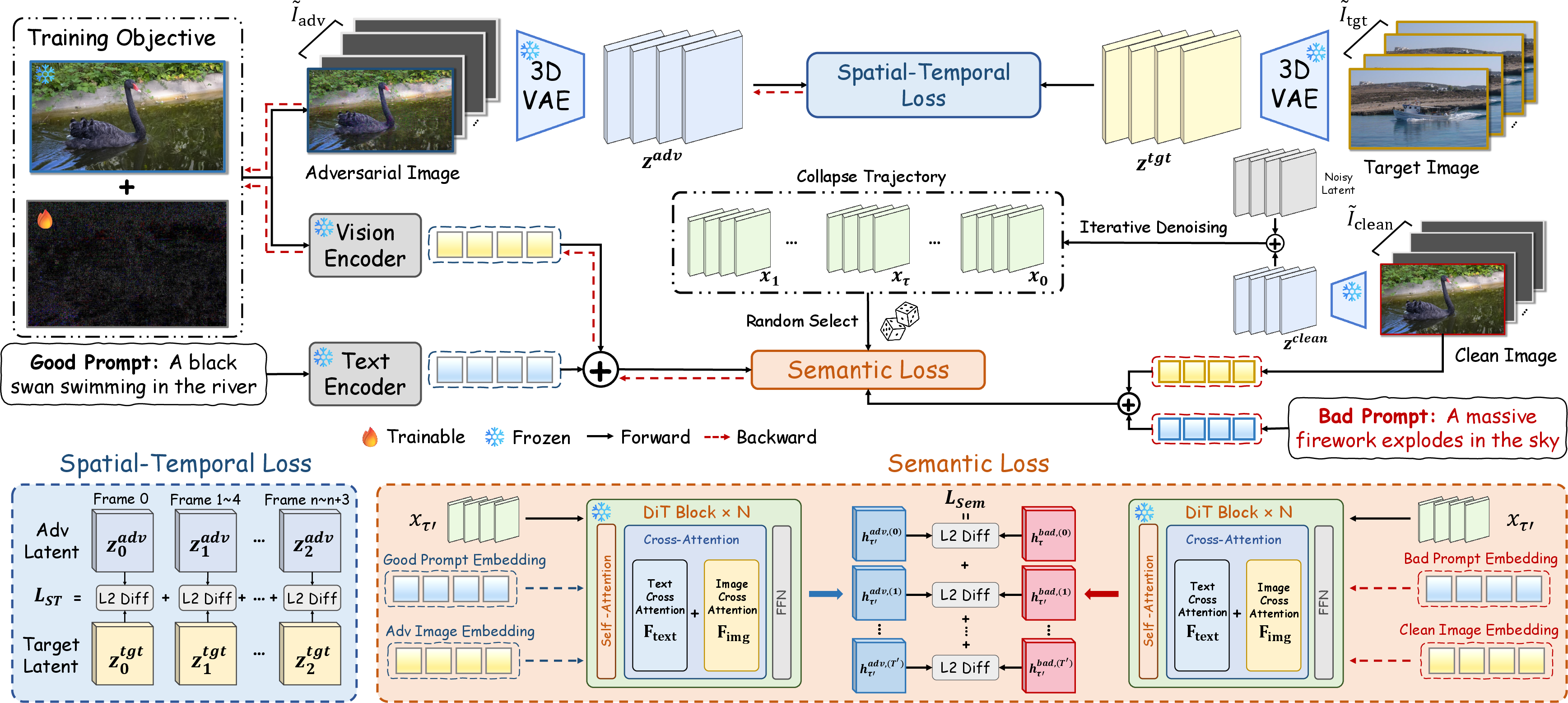
- The paper introduces a dual-objective immunization method that targets both spatial-temporal and semantic streams to induce persistent collapse in video synthesis.
- It employs a temporally balanced loss in the 3D VAE and manipulates semantic representations to override prompt-based alignment, ensuring robust defense.
- Experimental results demonstrate significant degradation in video quality and prompt fidelity compared to prior image-only defenses.
Immune2V: Imperceptible Image Immunization Against Dual-Stream Image-to-Video Generation
Motivation and Problem Analysis
The proliferation of high-fidelity I2V diffusion models enables arbitrary, realistic animation of static images using paired text-prompt conditioning—a double-edged advancement that raises privacy and misuse concerns, especially in the generation of deepfakes. While input-level adversarial perturbations, or “immunization,” have demonstrated efficacy for image-level editing protection, the direct extension of these defenses to I2V pipelines has not achieved persistent or effective results. The paper “Immune2V: Image Immunization Against Dual-Stream Image-to-Video Generation” (2604.10837) interrogates why this is the case by analyzing the architectural and optimization characteristics of modern dual-stream I2V frameworks.
A central finding is that dual-stream I2V architectures—exemplified by recent SOTA models—instantiate both a spatial-temporal pathway (typically a causal 3D VAE) and a semantic conditioning pathway (e.g., via CLIP/T5-based cross-attention) (Figure 1). This composition introduces two defense-resilient bottlenecks: (1) Perturbation attenuation in the spatial-temporal stream, where adversarial signals affecting only the input frame rapidly dissipate and fail to persist across the generated temporal sequence; and (2) Semantic conditioning override, where continuous text-prompt matching actively “heals” the effects of input perturbations, realigning generative trajectories regardless of input-level noise.
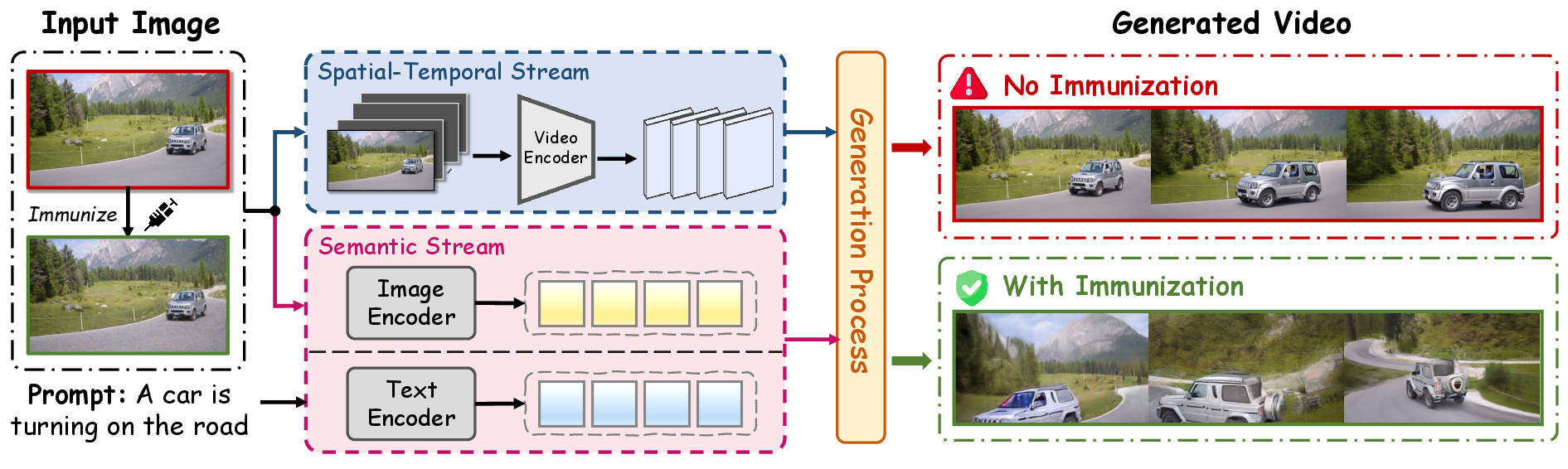
Figure 1: The dual-stream I2V architecture processes an image via spatial-temporal and semantic streams; immunization must target both to induce persistent collapse.
Empirical observations based on gradient analysis and latent distance metrics underscore the magnitude of spatiotemporal attenuation—the influence and optimization signal for later frames diminishes almost to zero if only the image’s first frame is perturbed. Similarly, latent trajectory tracking in the denoising process shows that when a semantically aligned prompt is used, semantic guidance forcibly realigns generative outcomes even if the spatial stream is compromised (Figure 2).
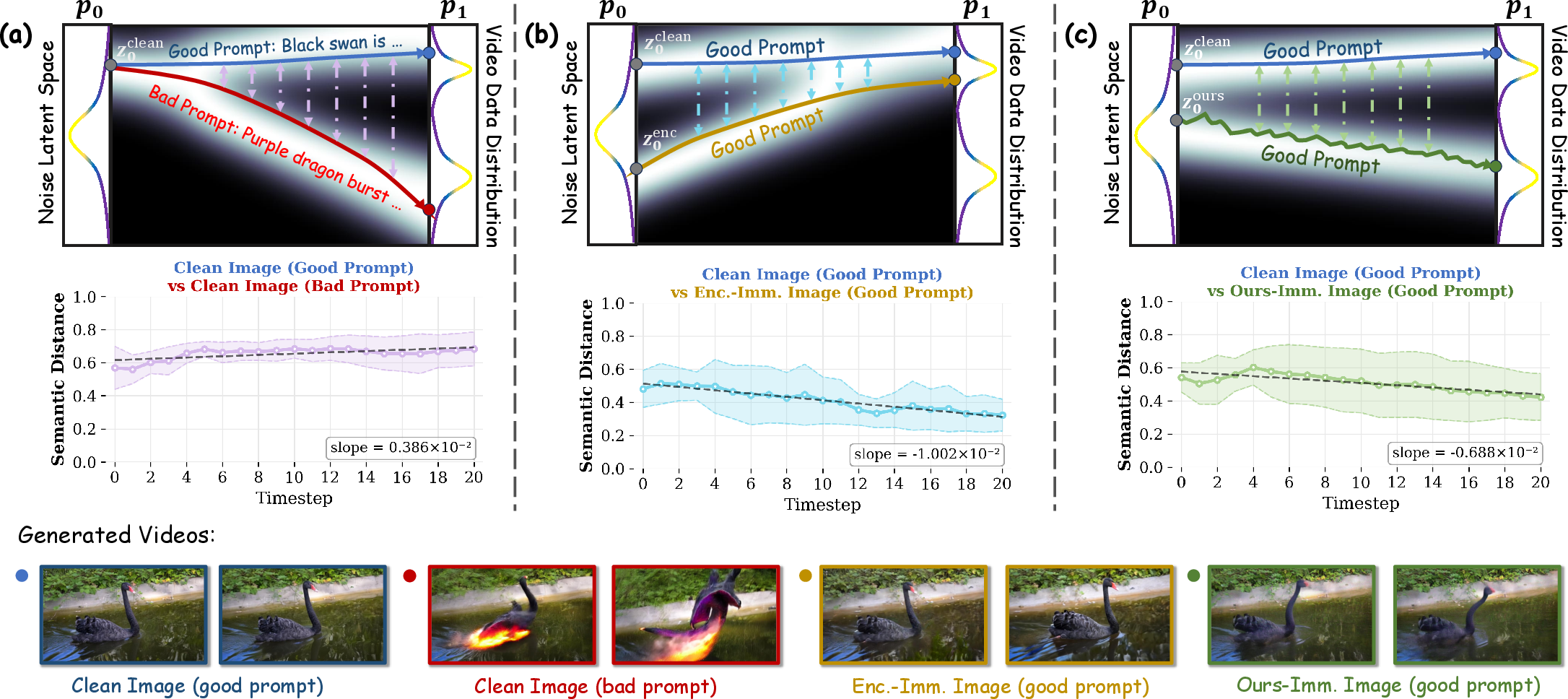
Figure 2: Semantic conditioning can override encoder-level corruption, but Immune2V’s joint optimization dampens semantic realignment.
Methodology: Dual-Stream Joint Optimization with Immune2V
To circumvent the failings of spatial-only or semantic-only immunization, Immune2V introduces a dual-objective optimization targeting both the spatial-temporal encoder and the conditional semantic stream (Figure 3).
Experimental Results and Analysis
The experimental protocol evaluates the resilience of Immune2V-immunized images against SOTA dual-stream I2V generators (Wan, DynamiCrafter, I2VGen-XL). The authors introduce both automated and VLM-based (Gemini) evaluation across video quality, temporal consistency, subject preservation, and motion smoothness metrics, benchmarking against clean inputs, random noise, and adapted image-only immunization (PhotoGuard variants). A broad dataset is synthesized using query+prompt pairs generated for the DAVIS benchmark.
Immune2V achieves the strongest and most persistent degradation in both conditioning fidelity and structural video quality metrics, outperforming prior image-only defenses by wide margins on text-prompt alignment, subject consistency, and motion plausibility—all with minimal perceptual corruption on the initial frame. Ablation studies demonstrate that eliminating either the semantic or spatial component substantially reduces attack efficacy (see Table 1). Increasing the perturbation budget amplifies degradation at the expense of input fidelity, confirming the importance of the selected trade-off.
Qualitative results reveal severe video breakdown, persistent distortion, and loss of motion regularity throughout the sequence, with immunized images yielding videos that fail to synthesize coherent subject or trajectory dynamics (Figures 5 and 6). In contrast, baseline defenses either leave the generative sequence largely unaffected or introduce visually noticeable artifacts only on the first frame.

Figure 4: Qualitative comparisons show that Immune2V consistently produces persistent collapse across video frames, unlike baselines that either fail to affect motion or overly degrade the initial frame only.

Figure 5: Additional qualitative results show persistent, temporally coherent breakdown in the spatial organization and subject consistency of videos generated from immunized images.
Robustness is further confirmed on alternative I2V architectures, and results generalize beyond the original model employed for optimization.
Theoretical and Practical Implications
This analysis establishes that defenses against unauthorized I2V generation require explicit video-aware adversarial mechanisms targeting both the spatial and semantic branches of dual-stream pipelines. Theoretical implications include the identification of model-level bottlenecks that make naive immunization strategies ineffective. Practically, Immune2V equips image owners with a tool to proactively safeguard their static visual data against animation-based abuse—an increasingly relevant threat as diffusion-based I2V models become ubiquitous and more robust.
By demonstrating the resilience of dual-stream architectures and the necessity of joint-space adversarial optimization, this work suggests future I2V protection will require even more sophisticated multi-modal and temporally distributed attack objectives. The effectivity of semantic-pathway manipulation should invite further research into cross-modal adversarial robustness and the design of conditionally robust generative models.
Speculation on Future Developments
Given the ongoing pace of video synthesis research, prospective developments may include: (1) generalized immunization frameworks that transfer across unseen architectures and text-prompt distributions; (2) robustifying dual-stream pipelines by introducing regularizers aware of adversarial immunization signals; and (3) extending immunization to higher-order conditioning, e.g., 3D, multimodal, or event-based I2V systems. The integration of proactive protection mechanisms like Immune2V into public datasets and social platforms may become standard for safeguarding identity and content provenance.
Conclusion
Immune2V systematically exposes and addresses the inherent limitations of input-level defenses in dual-stream I2V models by targeting both spatial-temporal and semantic conditioning pathways with imperceptible joint adversarial noise. It achieves strong, persistent, and video-wide disruption without degrading perceptual input quality, outperforming previous image-level defenses. These findings set a new benchmark for proactive video-level content protection, and outline critical theoretical considerations for future generative model security (2604.10837).