- The paper introduces a dual-channel fusion framework that unifies token (instinct) and verbalized (reflection) confidences for better reliability in MLLMs.
- It identifies and quantifies the misalignment between instinct and reflection signals using a monotonic RBF kernel and cross-channel consistency metrics.
- Experimental results show that the fusion method significantly reduces Expected Calibration Error (ECE) and improves risk-coverage trade-offs across diverse models.
Instinct vs. Reflection: Unifying Token and Verbalized Confidence in Multimodal Large Models
Introduction
The reliability of Multimodal LLMs (MLLMs) necessitates robust confidence estimation that reflects model certainty with respect to perception and reasoning tasks. While prior works target text-only LLMs—predominantly utilizing computationally intensive paradigms such as self-consistency sampling or logit-based direct extraction—the multimodal domain remains underexplored, both methodologically and in terms of unified evaluation. This paper elucidates a fundamental misalignment in MLLMs: the frequent decoupling of implicit token-level (instinctive) confidence and explicit verbalized (reflective) self-assessments. Addressing this, the authors propose a dual-channel, monotone confidence fusion framework for calibrated reliability estimation compatible with both open- and closed-source models (2604.17274).
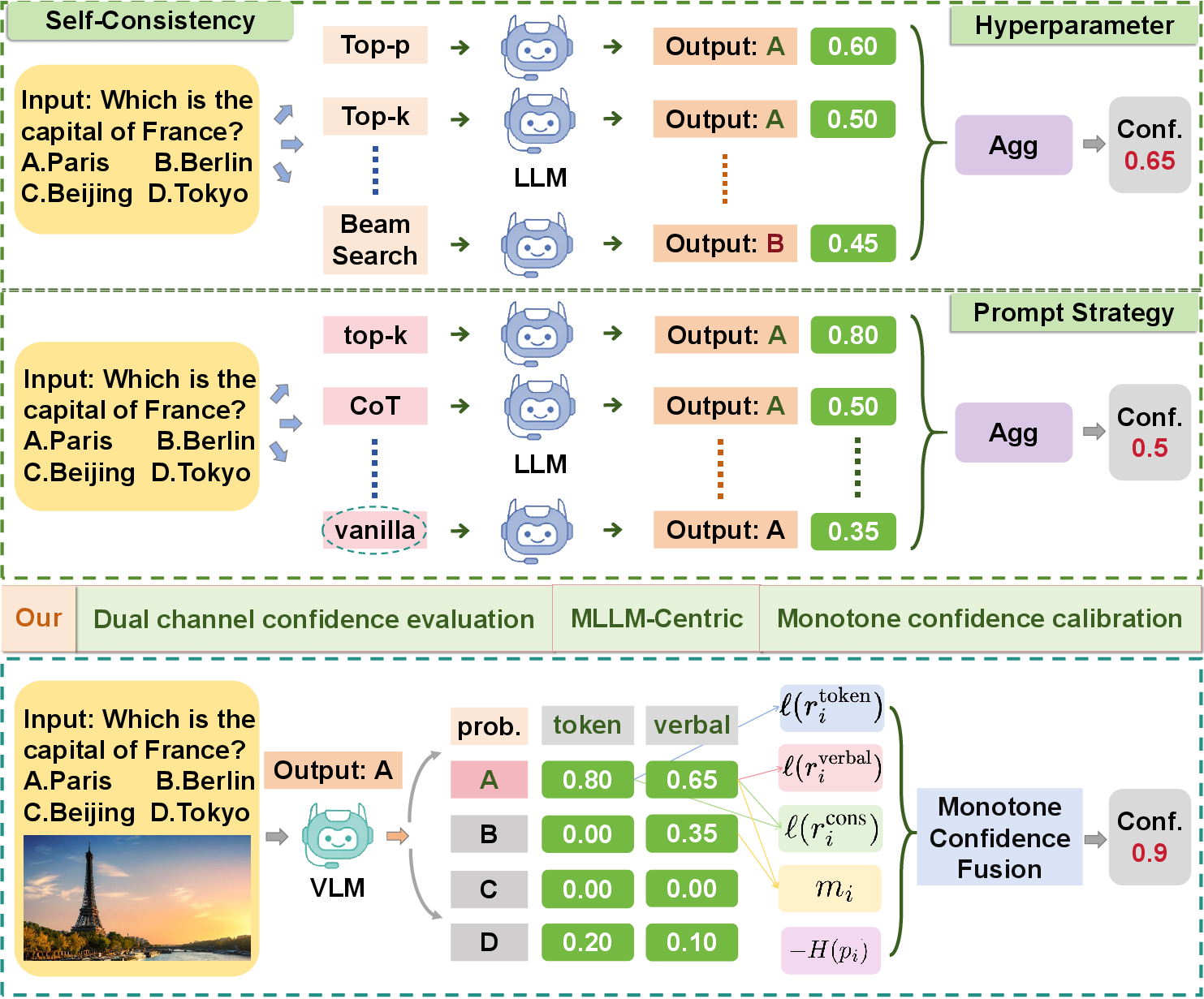
Figure 1: Comparison of paradigms—prior self-consistency sampling (top/middle) versus the proposed dual-channel MLLM framework yielding single-pass instinct and reflection signals.
Dual-Channel Confidence: Instinct and Reflection
Token Confidence (Instinct)
Token-level confidence, representative of aleatoric uncertainty, is extracted by querying the normalized log-probability of each candidate option at the constrained answer-token position. For a K-way VQA instance, the model's support distribution pi∈ΔK−1 reflects its instantaneous, model-internal belief about each discrete outcome, as determined by the softmax over candidate logits.
Verbalized Confidence (Reflection)
Verbalized (self-assessed) confidence is extracted by prompting the model to explicitly assign a numeric probability to each option, capturing epistemic uncertainty via structured, easily parsable templates. These confidences si∈[0,1]K often violate normalization, reflecting ambiguity or model ignorance—a phenomenon not captured by token probabilities.
Cross-Channel Consistency
The paper identifies that for MLLMs these two channels are frequently misaligned (instinct–reflection misalignment), yielding cases where token confidence is low but verbalized certainty is high or vice versa. Quantifying their discrepancy with a monotonic RBF kernel yields a cross-channel agreement metric, informative for reliability, especially under distribution shift and adversarial input.
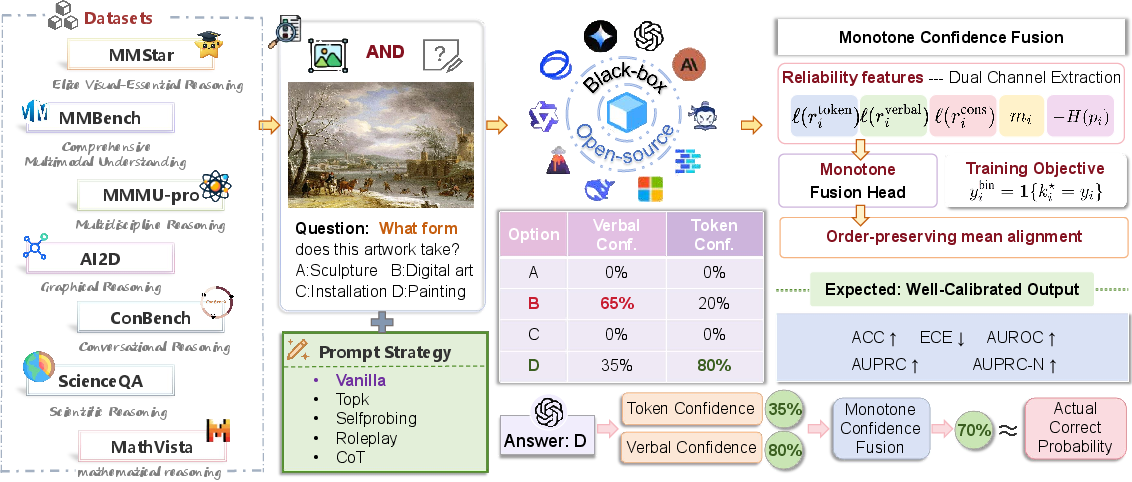
Figure 2: Schematic overview—instinct and reflection signals combined with cross-channel consistency integrate into a monotone fusion head followed by order-preserving mean alignment, yielding calibrated confidence estimates.
Monotone Confidence Fusion Framework
The authors propose a compact reliability descriptor for each prediction: a five-dimensional feature capturing (1) token confidence (log-odds transformed), (2) verbalized confidence (log-odds), (3) cross-channel consistency (log-odds), (4) top-2 option margin, and (5) negative entropy. A nonnegativity-constrained, coordinate-wise monotone logistic head maps these features, wired by the inductive bias that greater reliability cues should not decrease the predicted correctness probability.
Order-preserving mean alignment—a post-hoc bias correction step—ensures that predicted means match empirical accuracy, correcting for systematic calibration offset while preserving instance ranking (critical for risk-coverage trade-offs).
Experiments and Numerical Findings
A diverse set of MLLMs, spanning open- and closed-source and multiple modern architectures (InternVL, Qwen, Phi, GPT-4o, etc.), are benchmarked across six established multimodal MCQA datasets (MMBench, MMStar, ConBench, ScienceQA, AI2D, MMMU-Pro).
The authors conduct systematic analyses of calibration error (ECE), discriminative ability (AUROC, AUPRC, AUPRC-N), and risk-coverage, explicitly contrasting single-channel and fused multi-channel confidence estimation.
Token vs. Verbalized Confidence under Complexity
Token confidence achieves strong calibration (ECE < 5%) and ranking (AUROC > 90%) on knowledge-sufficient tasks (e.g., ScienceQA), but degrades sharply as logical complexity increases—overconfidence and inverse correlation between confidence and accuracy manifest in benchmarks such as MMMU-Pro and ConBench. Verbalized confidence exhibits high variance across models; open-source models display catastrophic failures (ECE > 40%, AUPRC-N < 0), while closed-source models are more stable but not immune.
Case Analysis
Comprehensive qualitative case studies reveal prominent phenomena:
- Verbal-Internal Disconnect (VID): Token and verbalized signals diverge, sometimes dramatically, leading to hallucinated certainty or under-confidence.
- Under-Confident Correct (UCC): Correct predictions with high internal support but anomalously low verbalized probability.
- Over-Confident Wrong (OCW): Hallucinated verbal certainty for incorrect predictions, sometimes against a backdrop of low token confidence.
- Well-Calibrated Correct/Wrong (WCC/WCW): Alignment between correctness and calibrated certainty or uncertainty.
Figure 3: ECE and AUROC using verbalized confidence—closed- and open-source models, across six datasets, exhibit large calibration and ranking gaps.
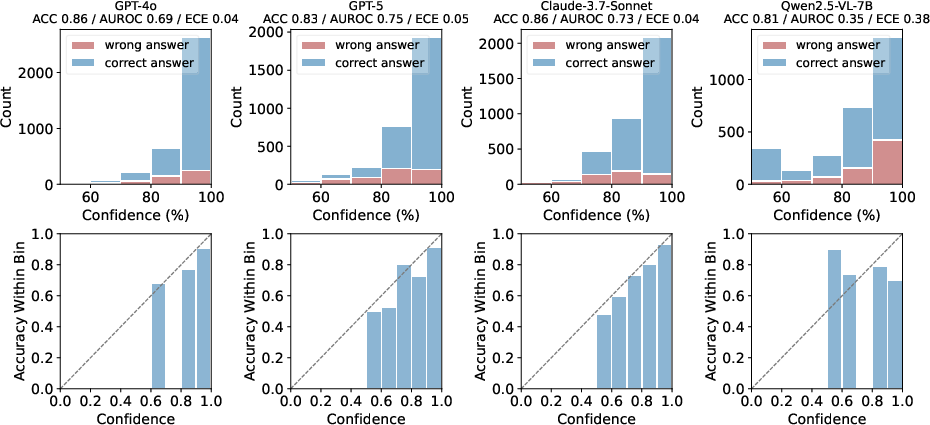
Figure 4: Confidence histograms and reliability diagrams—closed-source models concentrate high confidence on correct answers and maintain alignment with reliability; open-source models tend to be confidently wrong.
The monotone fusion framework consistently reduces ECE over both baselines, with the most substantial gains observed in challenging settings (e.g., a 39.5 reduction in ECE for InternVL3.5-8B on MMMU-Pro). However, improvements in AUROC or AUPRC-N are model- and dataset-sensitive; sometimes, fusion introduces noise to instances where a single channel is robust.
Risk-coverage curves demonstrate the framework's importance for selective prediction policies in safety-critical applications, especially by admitting or abstaining based on calibrated reliability. Temperature scaling provides minor and inconsistent improvements, confirming that robust calibration requires structural fusion rather than tuning generation hyperparameters.
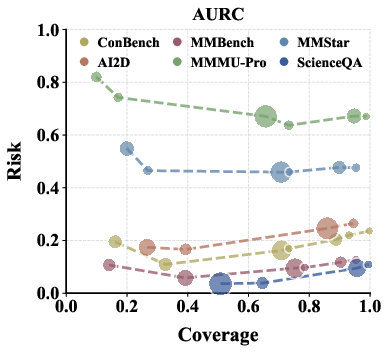
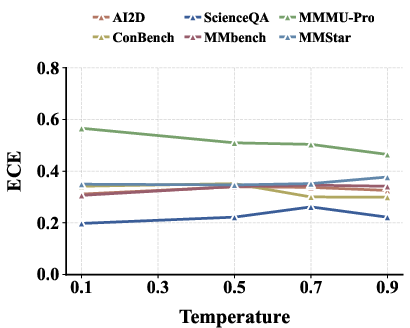
Figure 5: (Left) Risk-coverage curves demonstrate selective reliability for GPT-4o; (Right) ECE as a function of temperature shows limited impact on calibration across datasets.
Prompting Strategies
The authors perform an extensive ablation over prompting strategies (e.g., vanilla verbalization, self-probing, role-play, chain-of-thought, confidence intervals), demonstrating that prompt engineering alone cannot resolve intrinsic calibration problems, and that MLLM architectures and fusion remain the core determinants of reliability.
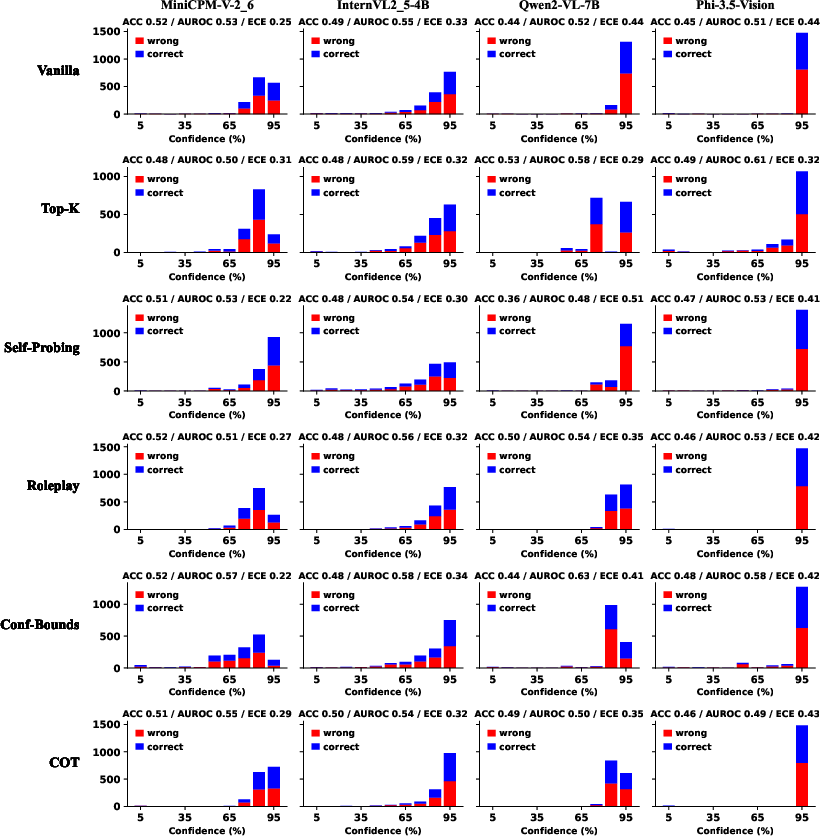
Figure 6: Confidence histograms across models and prompting strategies—most MLLMs are persistently overconfident, especially in open-source models irrespective of template complexity.
Theoretical Considerations and Model Interpretability
The formulation is general—when limited to token confidence it recovers Platt and temperature scaling, while the monotonic fusion head offers feature attribution for reliability cues, with coordinate-wise monotonicity guaranteeing interpretability and mitigation of overfitting negative weights. Order-preserving mean alignment ensures global calibration without perturbing instance order, critical for robust deployment.
Conclusion
This study exposes the systematic misalignment between instinctive (token) and reflective (verbalized) confidence in MLLMs. The proposed monotone fusion framework robustly unifies these discrepant signals, enhancing calibration and selective reliability. Empirical results across benchmarks and models validate dual-channel fusion as a prerequisite for trustworthy MLLM deployment, superseding single-channel and prompt-engineering paradigms. These findings underscore the necessity for future MLLM architectures to integrate intrinsic uncertainty alignment and advance towards reliable, risk-aware AI.
References
For the methodology, results, and further context, see "Instinct vs. Reflection: Unifying Token and Verbalized Confidence in Multimodal Large Models" (2604.17274).